 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOV-Stitcher: A Global Context-Aware Framework for Training-Free Open-Vocabulary Semantic Segmentation
Apr 09, 2026Training-free open-vocabulary semantic segmentation(TF-OVSS) has recently attracted attention for its ability to perform dense prediction by leveraging the pretrained knowledge of large vision and vision-language models, without requiring additional training. However, due to the limited input resolution of these pretrained encoders, existing TF-OVSS methods commonly adopt a sliding-window strategy that processes cropped sub-images independently. While effective for managing high-resolution inputs, this approach prevents global attention over the full image, leading to fragmented feature representations and limited contextual reasoning. We propose OV-Stitcher, a training-free framework that addresses this limitation by stitching fragmented sub-image features directly within the final encoder block. By reconstructing attention representations from fragmented sub-image features, OV-Stitcher enables global attention within the final encoder block, producing coherent context aggregation and spatially consistent, semantically aligned segmentation maps. Extensive evaluations across eight benchmarks demonstrate that OV-Stitcher establishes a scalable and effective solution for open-vocabulary segmentation, achieving a notable improvement in mean Intersection over Union(mIoU) from 48.7 to 50.7 compared with prior training-free baselines.
RecycleLoRA: Rank-Revealing QR-Based Dual-LoRA Subspace Adaptation for Domain Generalized Semantic Segmentation
Mar 30, 2026Domain Generalized Semantic Segmentation (DGSS) aims to maintain robust performance across unseen target domains. Vision Foundation Models (VFMs) offer rich multi-domain knowledge that can enhance generalization. However, strategies for actively exploiting the rich subspace structures within VFMs remain under-explored, with many existing methods focusing primarily on preserving pre-trained knowledge. Furthermore, their LoRA components often suffer from limited representational diversity and inefficient parameter utilization. We propose RecycleLoRA, which addresses both challenges by employing Rank-Revealing QR Decomposition (RRQR) to systematically exploit VFM's subspace structures and enhance LoRA's representational richness. Our main adapter leverages minor subspace directions identified by RRQR to learn diverse and independent features, achieving competitive performance even when used alone. We further introduce a sub adapter that carefully refines major directions with minimal adjustments, providing complementary improvements to the main adapter's strong baseline performance. This design enables the dual adapters to learn distinct representations without requiring additional regularization losses. Our systematic exploitation of pre-trained subspace structures through RRQR-based initialization leads to superior domain generalization performance. RecycleLoRA achieves state-of-the-art performance on both synthetic-to-real generalization and real-to-real generalization tasks without complex architectures or additional inference latency.
DFX: A Low-latency Multi-FPGA Appliance for Accelerating Transformer-based Text Generation
Sep 22, 2022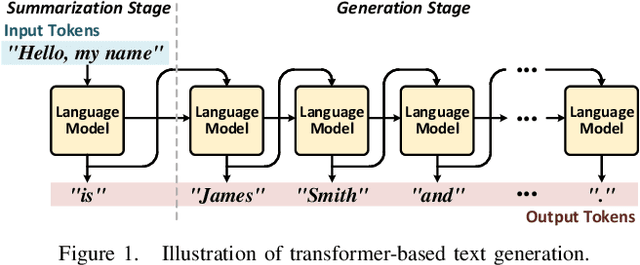
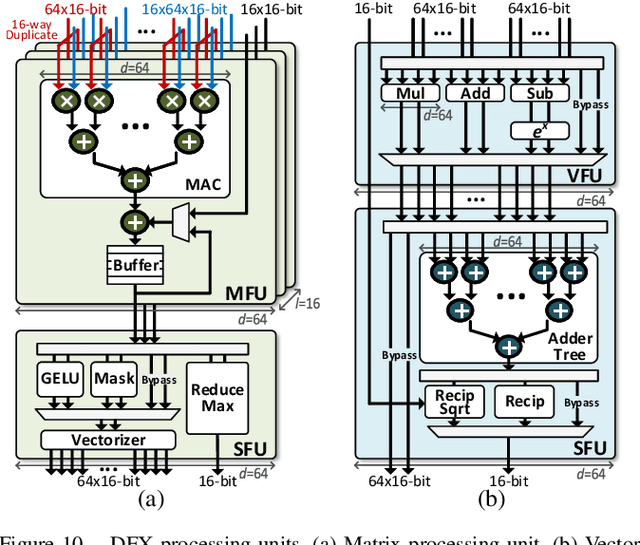
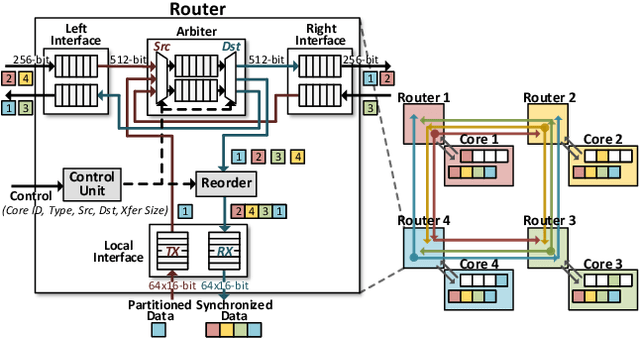
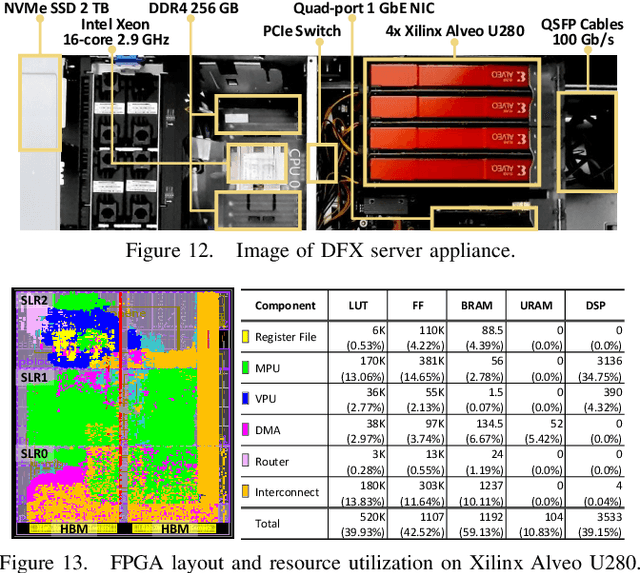
Transformer is a deep learning language model widely used for natural language processing (NLP) services in datacenters. Among transformer models, Generative Pre-trained Transformer (GPT) has achieved remarkable performance in text generation, or natural language generation (NLG), which needs the processing of a large input context in the summarization stage, followed by the generation stage that produces a single word at a time. The conventional platforms such as GPU are specialized for the parallel processing of large inputs in the summarization stage, but their performance significantly degrades in the generation stage due to its sequential characteristic. Therefore, an efficient hardware platform is required to address the high latency caused by the sequential characteristic of text generation. In this paper, we present DFX, a multi-FPGA acceleration appliance that executes GPT-2 model inference end-to-end with low latency and high throughput in both summarization and generation stages. DFX uses model parallelism and optimized dataflow that is model-and-hardware-aware for fast simultaneous workload execution among devices. Its compute cores operate on custom instructions and provide GPT-2 operations end-to-end. We implement the proposed hardware architecture on four Xilinx Alveo U280 FPGAs and utilize all of the channels of the high bandwidth memory (HBM) and the maximum number of compute resources for high hardware efficiency. DFX achieves 5.58x speedup and 3.99x energy efficiency over four NVIDIA V100 GPUs on the modern GPT-2 model. DFX is also 8.21x more cost-effective than the GPU appliance, suggesting that it is a promising solution for text generation workloads in cloud datacenters.