 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOmniDrop: Layer-wise Token Pruning for Omni-modal LLMs via Query-Guidance
May 14, 2026Omni-modal large language models have demonstrated remarkable potential in holistic multimodal understanding; however, the token explosion caused by high-resolution audio and video inputs remains a critical bottleneck for real-time applications and long-form reasoning. Existing omni-modal token compression methods typically prune tokens at the input embedding level, relying on audio-video similarity or temporal co-occurrence as proxies for semantic relevance. In practice, such assumptions are often unreliable. To address this limitation, we propose OmniDrop, a training-free, layer-wise token pruning framework that progressively prunes audiovisual tokens within the LLM decoder layers rather than at the input-level, allowing early layers to preserve sufficient omni-modal information fusion before aggressively removing tokens in deeper layers. We further utilize text queries as guidance for modality-agnostic and task-adaptive token pruning. We also introduce a temporal diversity score that encourages balanced token survival to preserve global temporal context. Experimental results across various audiovisual benchmarks demonstrate that OmniDrop outperforms all baselines by up to 3.58 points while reducing prefill latency by up to 40% and memory usage by up to 14.7%.
LookaheadKV: Fast and Accurate KV Cache Eviction by Glimpsing into the Future without Generation
Mar 11, 2026Transformer-based large language models (LLMs) rely on key-value (KV) caching to avoid redundant computation during autoregressive inference. While this mechanism greatly improves efficiency, the cache size grows linearly with the input sequence length, quickly becoming a bottleneck for long-context tasks. Existing solutions mitigate this problem by evicting prompt KV that are deemed unimportant, guided by estimated importance scores. Notably, a recent line of work proposes to improve eviction quality by "glimpsing into the future", in which a draft generator produces a surrogate future response approximating the target model's true response, and this surrogate is subsequently used to estimate the importance of cached KV more accurately. However, these approaches rely on computationally expensive draft generation, which introduces substantial prefilling overhead and limits their practicality in real-world deployment. To address this challenge, we propose LookaheadKV, a lightweight eviction framework that leverages the strength of surrogate future response without requiring explicit draft generation. LookaheadKV augments transformer layers with parameter-efficient modules trained to predict true importance scores with high accuracy. Our design ensures negligible runtime overhead comparable to existing inexpensive heuristics, while achieving accuracy superior to more costly approximation methods. Extensive experiments on long-context understanding benchmarks, across a wide range of models, demonstrate that our method not only outperforms recent competitive baselines in various long-context understanding tasks, but also reduces the eviction cost by up to 14.5x, leading to significantly faster time-to-first-token. Our code is available at https://github.com/SamsungLabs/LookaheadKV.
On the Importance of a Multi-Scale Calibration for Quantization
Feb 07, 2026Post-training quantization (PTQ) is a cornerstone for efficiently deploying large language models (LLMs), where a small calibration set critically affects quantization performance. However, conventional practices rely on random sequences of fixed length, overlooking the variable-length nature of LLM inputs. Input length directly influences the activation distribution and, consequently, the weight importance captured by the Hessian, which in turn affects quantization outcomes. As a result, Hessian estimates derived from fixed-length calibration may fail to represent the true importance of weights across diverse input scenarios. We propose MaCa (Matryoshka Calibration), a simple yet effective method for length-aware Hessian construction. MaCa (i) incorporates multi-scale sequence length information into Hessian estimation and (ii) regularizes each sequence as an independent sample, yielding a more stable and fruitful Hessian for accurate quantization. Experiments on state-of-the-art LLMs (e.g., Qwen3, Gemma3, LLaMA3) demonstrate that MaCa consistently improves accuracy under low bit quantization, offering a lightweight enhancement compatible with existing PTQ frameworks. To the best of our knowledge, this is the first work to systematically highlight the role of multi-scale calibration in LLM quantization.
TurboBoA: Faster and Exact Attention-aware Quantization without Backpropagation
Feb 04, 2026The rapid growth of large language models (LLMs) has heightened the importance of post-training quantization (PTQ) for reducing memory and computation costs. Among PTQ methods, GPTQ has gained significant attention for its efficiency, enabling billion-scale LLMs to be quantized within a few GPU hours. However, GPTQ's assumption of layer-wise independence leads to severe accuracy drops in low-bit regimes. Recently, BoA improved upon GPTQ by incorporating inter-layer dependencies within attention modules, but its reliance on sequential quantization across all out-channels makes it substantially less efficient. In this paper, we propose TurboBoA, a new backpropagation-free PTQ algorithm that preserves the accuracy benefits of BoA while significantly accelerating the process. The proposed TurboBoA introduces three key innovations: (i) joint quantization of multiple out-channels with a closed-form error compensation rule, which reduces sequential bottlenecks and yields more than a three-fold speedup; (ii) a correction mechanism for errors propagated from preceding quantized layers; and (iii) adaptive grid computation with coordinate descent refinement to maintain alignment during iterative updates. Extensive experiments demonstrate that TurboBoA delivers substantial acceleration over BoA while consistently improving accuracy. When combined with outlier suppression techniques, it achieves state-of-the-art results in both weight-only and weight-activation quantization. The code will be available at https://github.com/SamsungLabs/TurboBoA.
Two-Stage Grid Optimization for Group-wise Quantization of LLMs
Feb 02, 2026Group-wise quantization is an effective strategy for mitigating accuracy degradation in low-bit quantization of large language models (LLMs). Among existing methods, GPTQ has been widely adopted due to its efficiency; however, it neglects input statistics and inter-group correlations when determining group scales, leading to a mismatch with its goal of minimizing layer-wise reconstruction loss. In this work, we propose a two-stage optimization framework for group scales that explicitly minimizes the layer-wise reconstruction loss. In the first stage, performed prior to GPTQ, we initialize each group scale to minimize the group-wise reconstruction loss, thereby incorporating input statistics. In the second stage, we freeze the integer weights obtained via GPTQ and refine the group scales to minimize the layer-wise reconstruction loss. To this end, we employ the coordinate descent algorithm and derive a closed-form update rule, which enables efficient refinement without costly numerical optimization. Notably, our derivation incorporates the quantization errors from preceding layers to prevent error accumulation. Experimental results demonstrate that our method consistently enhances group-wise quantization, achieving higher accuracy with negligible overhead.
Attention-aware Post-training Quantization without Backpropagation
Jun 19, 2024



Quantization is a promising solution for deploying large-scale language models (LLMs) on resource-constrained devices. Existing quantization approaches, however, rely on gradient-based optimization, regardless of it being post-training quantization (PTQ) or quantization-aware training (QAT), which becomes problematic for hyper-scale LLMs with billions of parameters. This overhead can be alleviated via recently proposed backpropagation-free PTQ methods; however, their performance is somewhat limited by their lack of consideration of inter-layer dependencies. In this paper, we thus propose a novel PTQ algorithm that considers inter-layer dependencies without relying on backpropagation. The fundamental concept involved is the development of attention-aware Hessian matrices, which facilitates the consideration of inter-layer dependencies within the attention module. Extensive experiments demonstrate that the proposed algorithm significantly outperforms conventional PTQ methods, particularly for low bit-widths.
Towards Next-Level Post-Training Quantization of Hyper-Scale Transformers
Feb 14, 2024



With the increasing complexity of generative AI models, post-training quantization (PTQ) has emerged as a promising solution for deploying hyper-scale models on edge devices such as mobile devices and TVs. Existing PTQ schemes, however, consume considerable time and resources, which could be a bottleneck in real situations where frequent model updates and multiple hyper-parameter tunings are required. As a cost-effective alternative, one-shot PTQ schemes have been proposed. Still, the performance is somewhat limited because they cannot consider the inter-layer dependency within the attention module, which is a very important feature of Transformers. In this paper, we thus propose a novel PTQ algorithm that balances accuracy and efficiency. The key idea of the proposed algorithm called aespa is to perform quantization layer-wise for efficiency while considering cross-layer dependency to preserve the attention score. Through extensive experiments on various language models and complexity analysis, we demonstrate that aespa is accurate and efficient in quantizing Transformer models.
Genie: Show Me the Data for Quantization
Dec 09, 2022Zero-shot quantization is a promising approach for developing lightweight deep neural networks when data is inaccessible owing to various reasons, including cost and issues related to privacy. By utilizing the learned parameters (statistics) of FP32-pre-trained models, zero-shot quantization schemes focus on generating synthetic data by minimizing the distance between the learned parameters ($\mu$ and $\sigma$) and distributions of intermediate activations. Subsequently, they distill knowledge from the pre-trained model (\textit{teacher}) to the quantized model (\textit{student}) such that the quantized model can be optimized with the synthetic dataset. In general, zero-shot quantization comprises two major elements: synthesizing datasets and quantizing models. However, thus far, zero-shot quantization has primarily been discussed in the context of quantization-aware training methods, which require task-specific losses and long-term optimization as much as retraining. We thus introduce a post-training quantization scheme for zero-shot quantization that produces high-quality quantized networks within a few hours on even half an hour. Furthermore, we propose a framework called \genie~that generates data suited for post-training quantization. With the data synthesized by \genie, we can produce high-quality quantized models without real datasets, which is comparable to few-shot quantization. We also propose a post-training quantization algorithm to enhance the performance of quantized models. By combining them, we can bridge the gap between zero-shot and few-shot quantization while significantly improving the quantization performance compared to that of existing approaches. In other words, we can obtain a unique state-of-the-art zero-shot quantization approach.
Modulating Regularization Frequency for Efficient Compression-Aware Model Training
May 05, 2021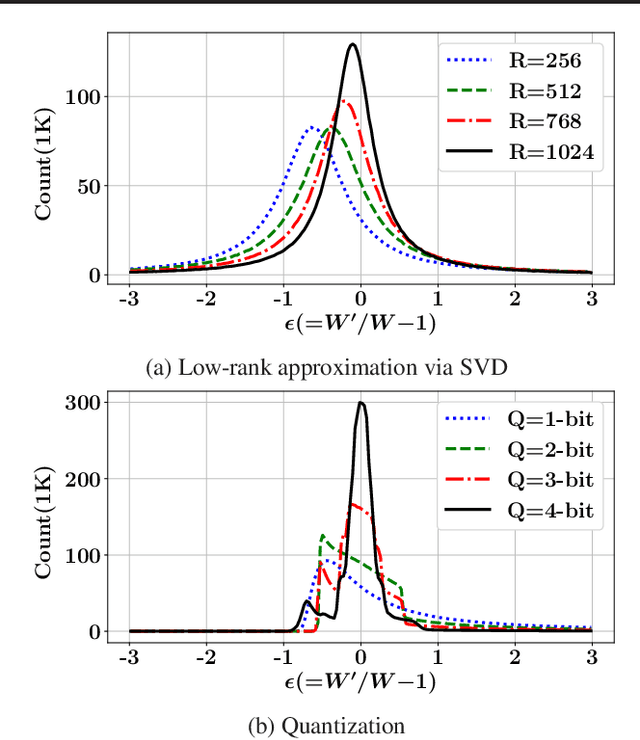
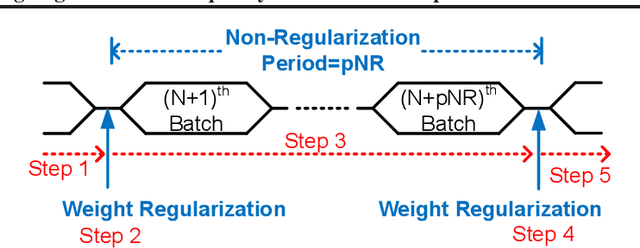

While model compression is increasingly important because of large neural network size, compression-aware training is challenging as it needs sophisticated model modifications and longer training time.In this paper, we introduce regularization frequency (i.e., how often compression is performed during training) as a new regularization technique for a practical and efficient compression-aware training method. For various regularization techniques, such as weight decay and dropout, optimizing the regularization strength is crucial to improve generalization in Deep Neural Networks (DNNs). While model compression also demands the right amount of regularization, the regularization strength incurred by model compression has been controlled only by compression ratio. Throughout various experiments, we show that regularization frequency critically affects the regularization strength of model compression. Combining regularization frequency and compression ratio, the amount of weight updates by model compression per mini-batch can be optimized to achieve the best model accuracy. Modulating regularization frequency is implemented by occasional model compression while conventional compression-aware training is usually performed for every mini-batch.
Sequential Encryption of Sparse Neural Networks Toward Optimum Representation of Irregular Sparsity
May 05, 2021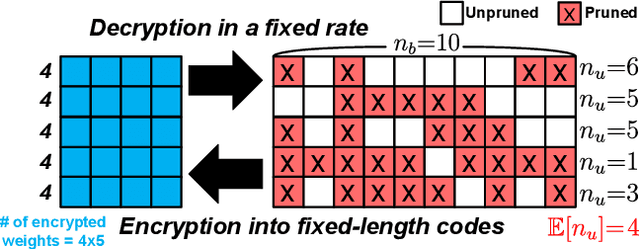
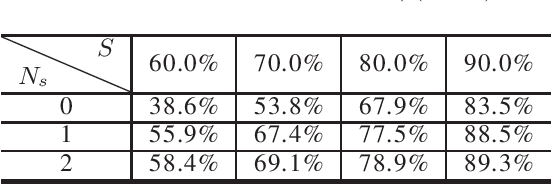
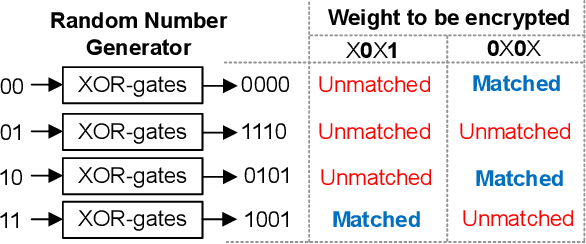
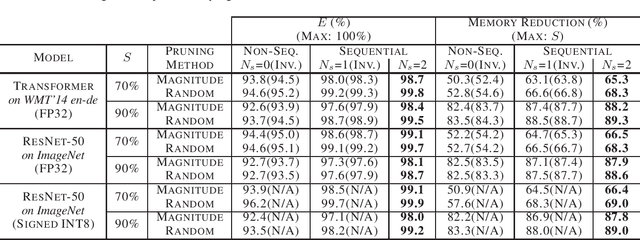
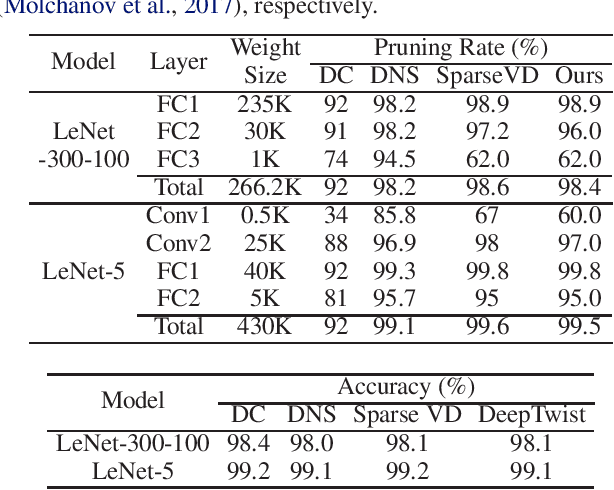
Even though fine-grained pruning techniques achieve a high compression ratio, conventional sparsity representations (such as CSR) associated with irregular sparsity degrade parallelism significantly. Practical pruning methods, thus, usually lower pruning rates (by structured pruning) to improve parallelism. In this paper, we study fixed-to-fixed (lossless) encryption architecture/algorithm to support fine-grained pruning methods such that sparse neural networks can be stored in a highly regular structure. We first estimate the maximum compression ratio of encryption-based compression using entropy. Then, as an effort to push the compression ratio to the theoretical maximum (by entropy), we propose a sequential fixed-to-fixed encryption scheme. We demonstrate that our proposed compression scheme achieves almost the maximum compression ratio for the Transformer and ResNet-50 pruned by various fine-grained pruning methods.