 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFCM-RDpA: TSK Fuzzy Regression Model Construction Using Fuzzy C-Means Clustering, Regularization, DropRule, and Powerball AdaBelief
Nov 30, 2020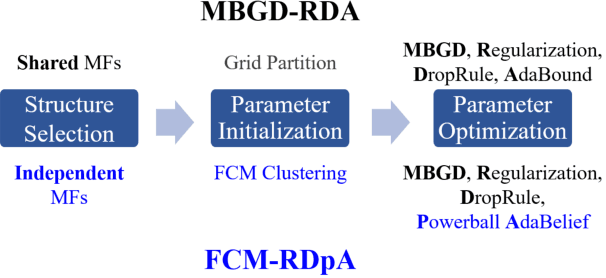
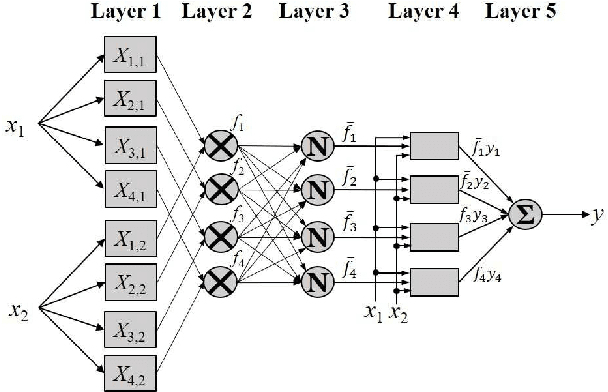
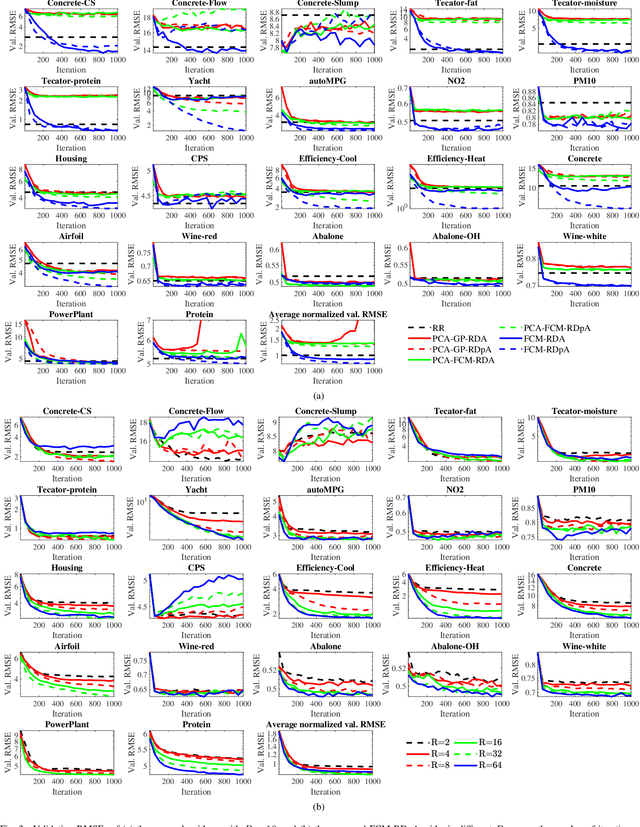
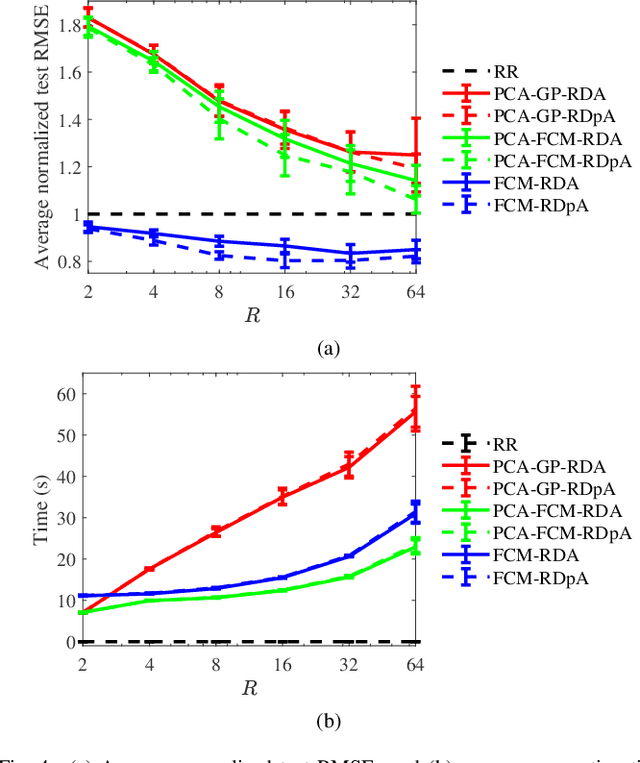
To effectively optimize Takagi-Sugeno-Kang (TSK) fuzzy systems for regression problems, a mini-batch gradient descent with regularization, DropRule, and AdaBound (MBGD-RDA) algorithm was recently proposed. This paper further proposes FCM-RDpA, which improves MBGD-RDA by replacing the grid partition approach in rule initialization by fuzzy c-means clustering, and AdaBound by Powerball AdaBelief, which integrates recently proposed Powerball gradient and AdaBelief to further expedite and stabilize parameter optimization. Extensive experiments on 22 regression datasets with various sizes and dimensionalities validated the superiority of FCM-RDpA over MBGD-RDA, especially when the feature dimensionality is higher. We also propose an additional approach, FCM-RDpAx, that further improves FCM-RDpA by using augmented features in both the antecedents and consequents of the rules.
EEG-Based Brain-Computer Interfaces Are Vulnerable to Backdoor Attacks
Oct 30, 2020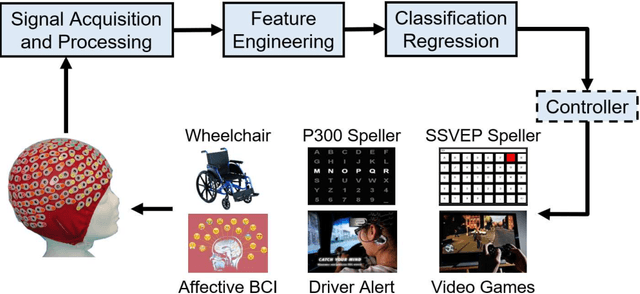
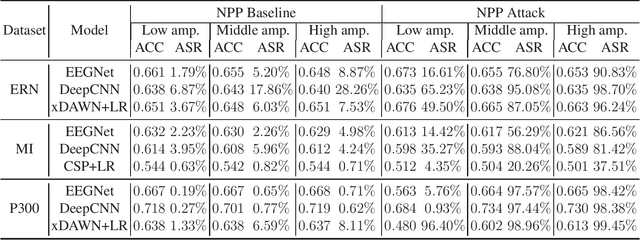
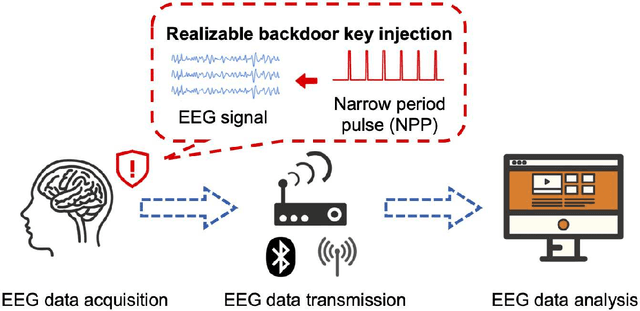
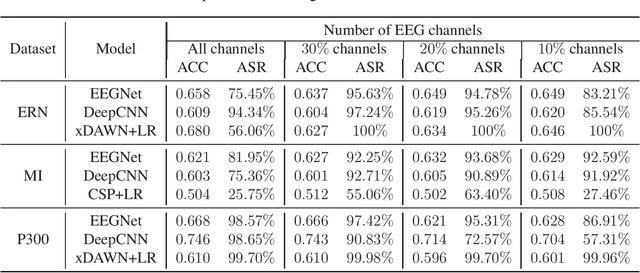
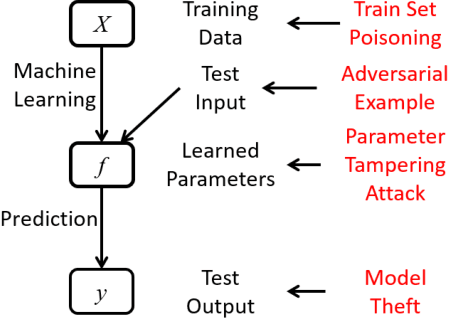
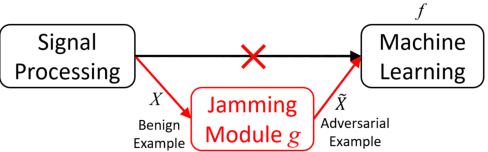
Research and development of electroencephalogram (EEG) based brain-computer interfaces (BCIs) have advanced rapidly, partly due to the wide adoption of sophisticated machine learning approaches for decoding the EEG signals. However, recent studies have shown that machine learning algorithms are vulnerable to adversarial attacks, e.g., the attacker can add tiny adversarial perturbations to a test sample to fool the model, or poison the training data to insert a secret backdoor. Previous research has shown that adversarial attacks are also possible for EEG-based BCIs. However, only adversarial perturbations have been considered, and the approaches are theoretically sound but very difficult to implement in practice. This article proposes to use narrow period pulse for poisoning attack of EEG-based BCIs, which is more feasible in practice and has never been considered before. One can create dangerous backdoors in the machine learning model by injecting poisoning samples into the training set. Test samples with the backdoor key will then be classified into the target class specified by the attacker. What most distinguishes our approach from previous ones is that the backdoor key does not need to be synchronized with the EEG trials, making it very easy to implement. The effectiveness and robustness of the backdoor attack approach is demonstrated, highlighting a critical security concern for EEG-based BCIs.
Overcoming Negative Transfer: A Survey
Sep 02, 2020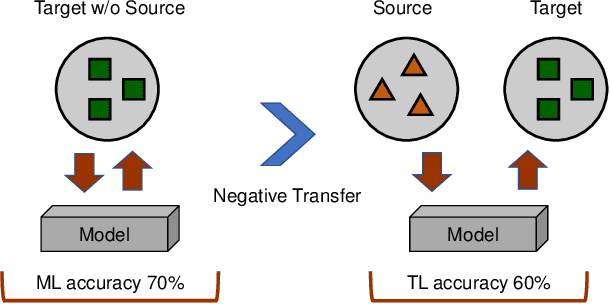
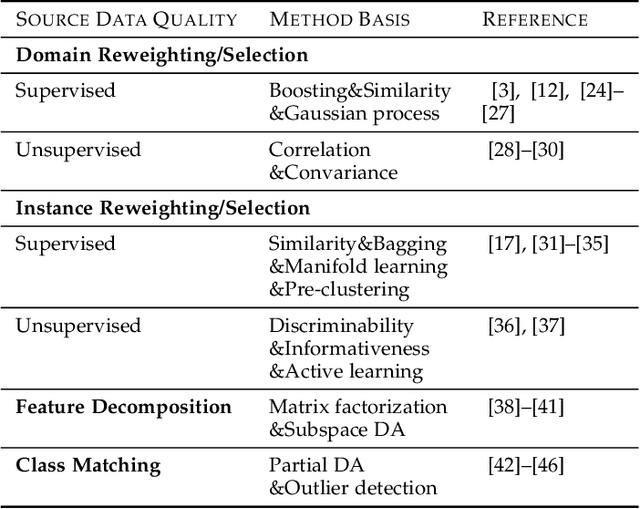
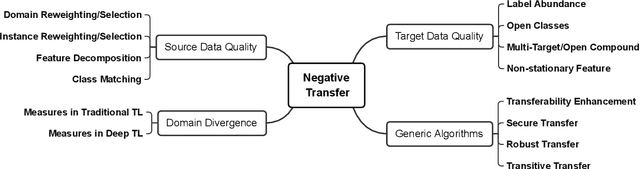
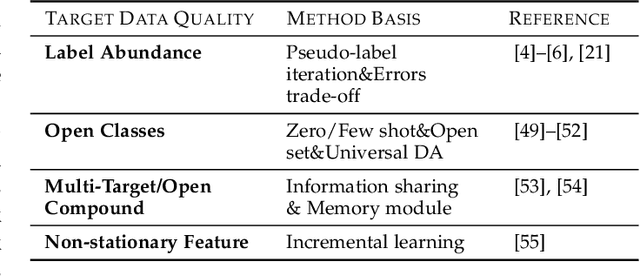
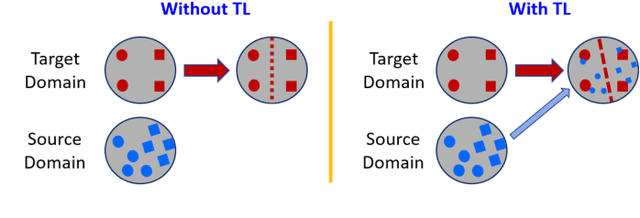
Transfer learning aims to help the target task with little or no training data by leveraging knowledge from one or multi-related auxiliary tasks. In practice, the success of transfer learning is not always guaranteed, negative transfer is a long-standing problem in transfer learning literature, which has been well recognized within the transfer learning community. How to overcome negative transfer has been studied for a long time and has raised increasing attention in recent years. Thus, it is both necessary and challenging to comprehensively review the relevant researches. This survey attempts to analyze the factors related to negative transfer and summarizes the theories and advances of overcoming negative transfer from four crucial aspects: source data quality, target data quality, domain divergence and generic algorithms, which may provide the readers an insight into the current research status and ideas. Additionally, we provided some general guidelines on how to detect and overcome negative transfer on real data, including the negative transfer detection, datasets, baselines, and general routines. The survey provides researchers a framework for better understanding and identifying the research status, fundamental questions, open challenges and future directions of the field.
Transfer Learning for Brain-Computer Interfaces: A Complete Pipeline
Jul 03, 2020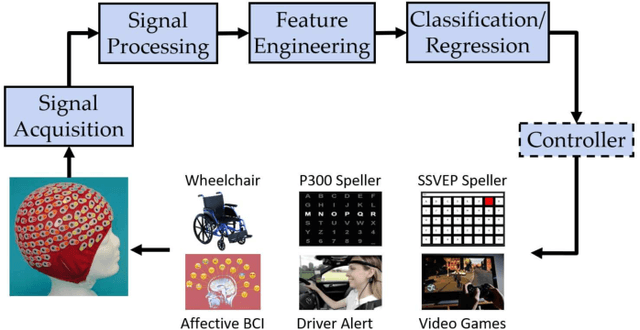
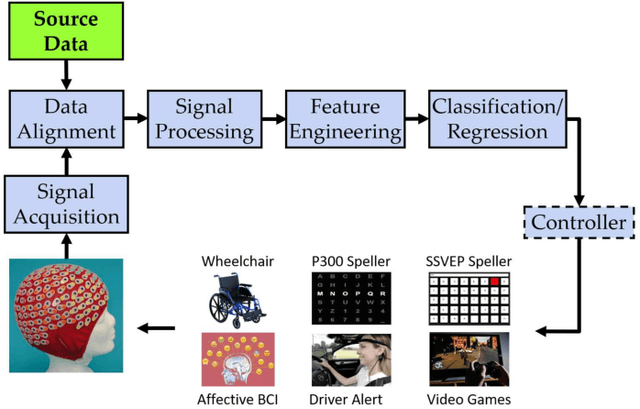
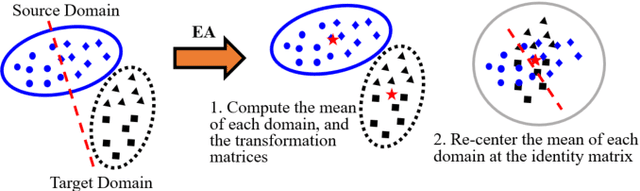
Transfer learning (TL) has been widely used in electroencephalogram (EEG) based brain-computer interfaces (BCIs) to reduce the calibration effort for a new subject, and demonstrated promising performance. After EEG signal acquisition, a closed-loop EEG-based BCI system also includes signal processing, feature engineering, and classification/regression blocks before sending out the control signal, whereas previous approaches only considered TL in one or two such components. This paper proposes that TL could be considered in all three components (signal processing, feature engineering, and classification/regression). Furthermore, it is also very important to specifically add a data alignment component before signal processing to make the data from different subjects more consistent, and hence to facilitate subsequential TL. Offline calibration experiments on two MI datasets verified our proposal. Especially, integrating data alignment and sophisticated TL approaches can significantly improve the classification performance, and hence greatly reduce the calibration effort.
Transfer Learning for EEG-Based Brain-Computer Interfaces: A Review of Progress Made Since 2016
May 06, 2020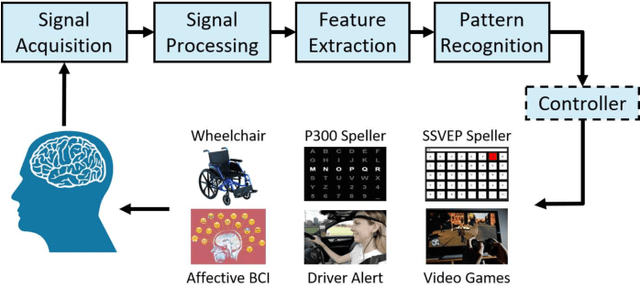

A brain-computer interface (BCI) enables a user to communicate with a computer directly using brain signals. Electroencephalograms (EEGs) used in BCIs are weak, easily contaminated by interference and noise, non-stationary for the same subject, and varying across different subjects and sessions. Therefore, it is difficult to build a generic pattern recognition model in an EEG-based BCI system that is optimal for different subjects, during different sessions, for different devices and tasks. Usually, a calibration session is needed to collect some training data for a new subject, which is time consuming and user unfriendly. Transfer learning (TL), which utilizes data or knowledge from similar or relevant subjects/sessions/devices/tasks to facilitate learning for a new subject/session/device/task, is frequently used to reduce the amount of calibration effort. This paper reviews journal publications on TL approaches in EEG-based BCIs in the last few years, i.e., since 2016. Six paradigms and applications -- motor imagery, event-related potentials, steady-state visual evoked potentials, affective BCIs, regression problems, and adversarial attacks -- are considered. For each paradigm/application, we group the TL approaches into cross-subject/session, cross-device, and cross-task settings and review them separately. Observations and conclusions are made at the end of the paper, which may point to future research directions.
Rethink the Connections among Generalization, Memorization and the Spectral Bias of DNNs
Apr 29, 2020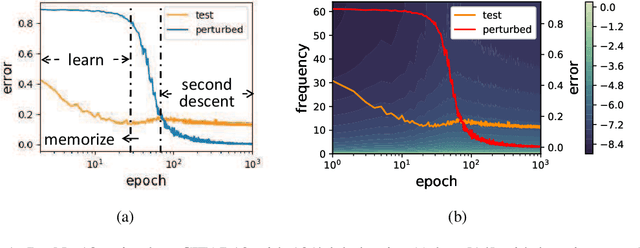
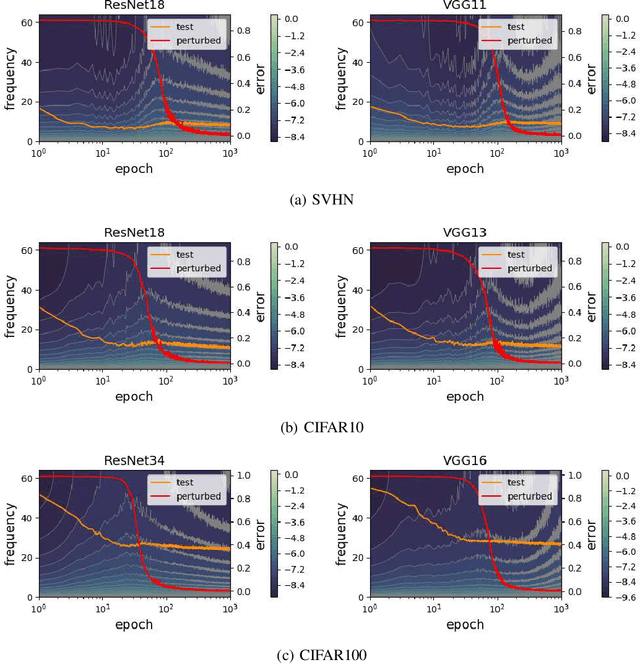
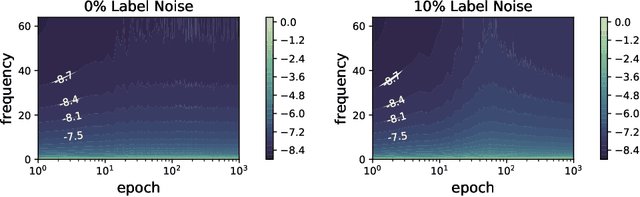
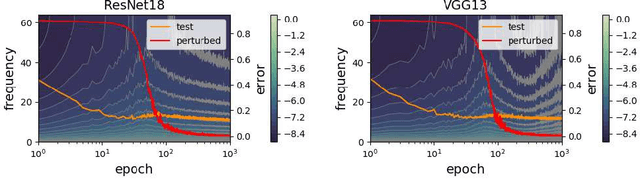
Over-parameterized deep neural networks (DNNs) with sufficient capacity to memorize random noise can achieve excellent generalization performance on normal datasets, challenging the bias-variance trade-off in classical learning theory. Recent studies claimed that DNNs first learn simple patterns and then memorize noise; some other works showed that DNNs have a spectral bias to learn target functions from low to high frequencies during training. These suggest some connections among generalization, memorization and the spectral bias of DNNs: the low-frequency components in the input space represent the \emph{patterns} which can generalize, whereas the high-frequency components represent the \emph{noise} which needs to be memorized. However, we show that it is not true: under the experimental setup of deep double descent, the high-frequency components of DNNs begin to diminish in the second descent, whereas the examples with random labels are still being memorized. Moreover, we find that the spectrum of DNNs can be applied to monitoring the test behavior, e.g., it can indicate when the second descent of the test error starts, even though the spectrum is calculated from the training set only.
Pool-Based Unsupervised Active Learning for Regression Using Iterative Representativeness-Diversity Maximization (iRDM)
Mar 31, 2020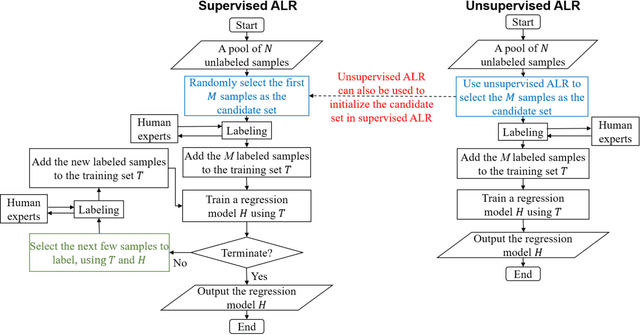
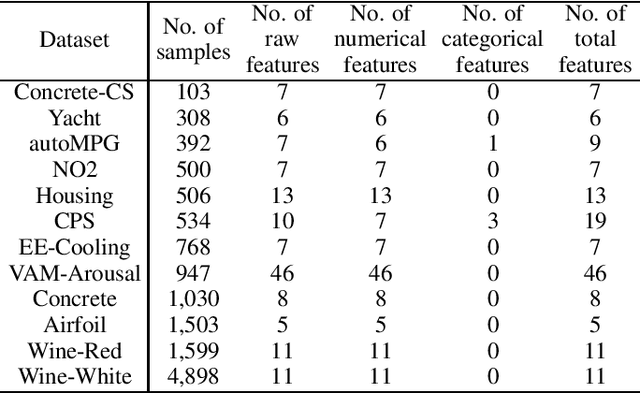
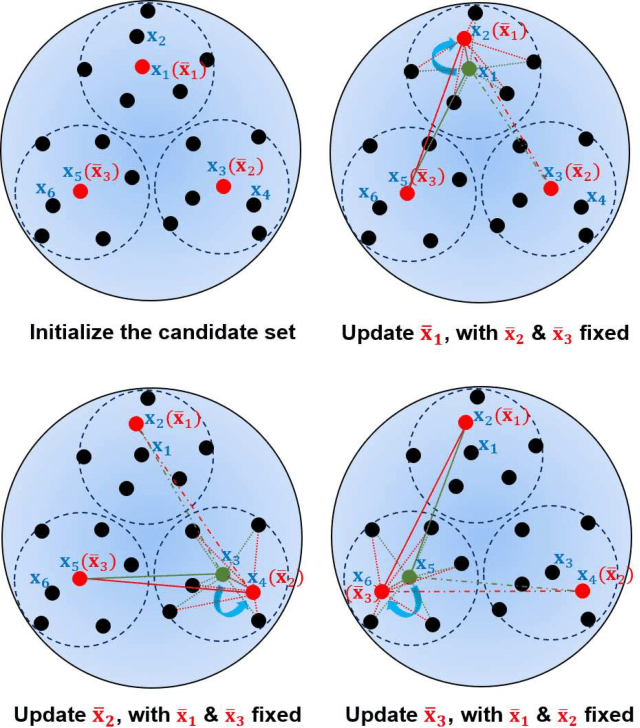
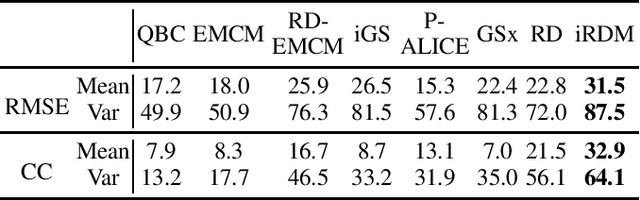
Active learning (AL) selects the most beneficial unlabeled samples to label, and hence a better machine learning model can be trained from the same number of labeled samples. Most existing active learning for regression (ALR) approaches are supervised, which means the sampling process must use some label information, or an existing regression model. This paper considers completely unsupervised ALR, i.e., how to select the samples to label without knowing any true label information. We propose a novel unsupervised ALR approach, iterative representativeness-diversity maximization (iRDM), to optimally balance the representativeness and the diversity of the selected samples. Experiments on 12 datasets from various domains demonstrated its effectiveness. Our iRDM can be applied to both linear regression and kernel regression, and it even significantly outperforms supervised ALR when the number of labeled samples is small.
Integrating Informativeness, Representativeness and Diversity in Pool-Based Sequential Active Learning for Regression
Mar 26, 2020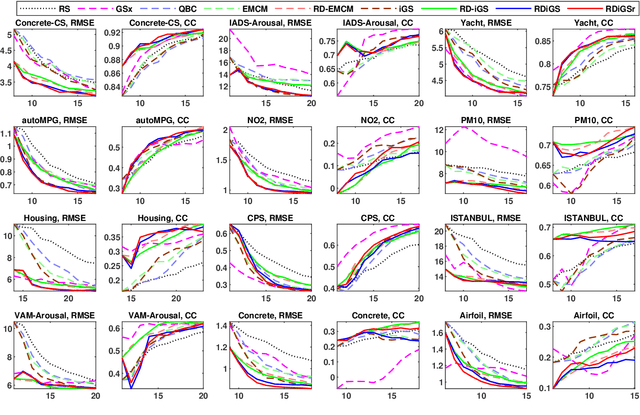
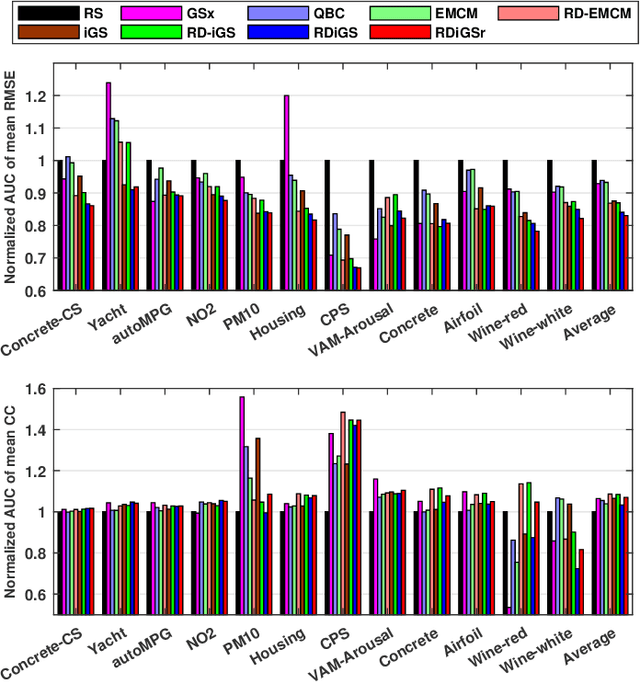
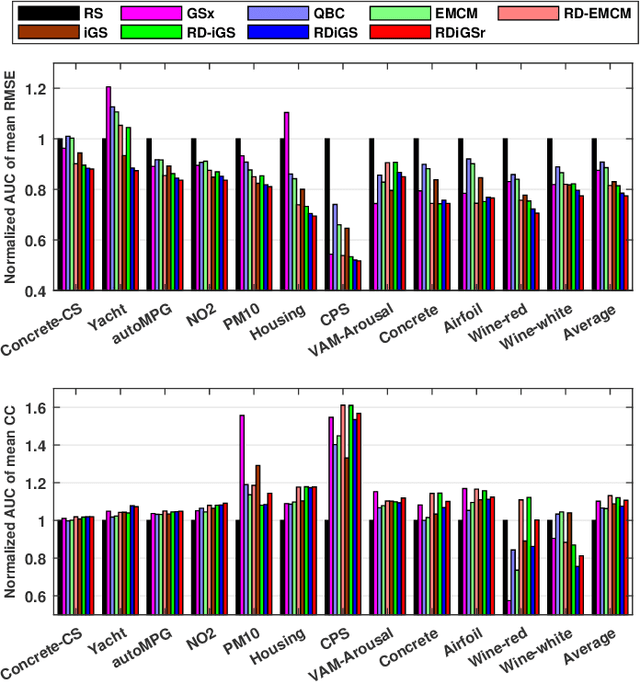
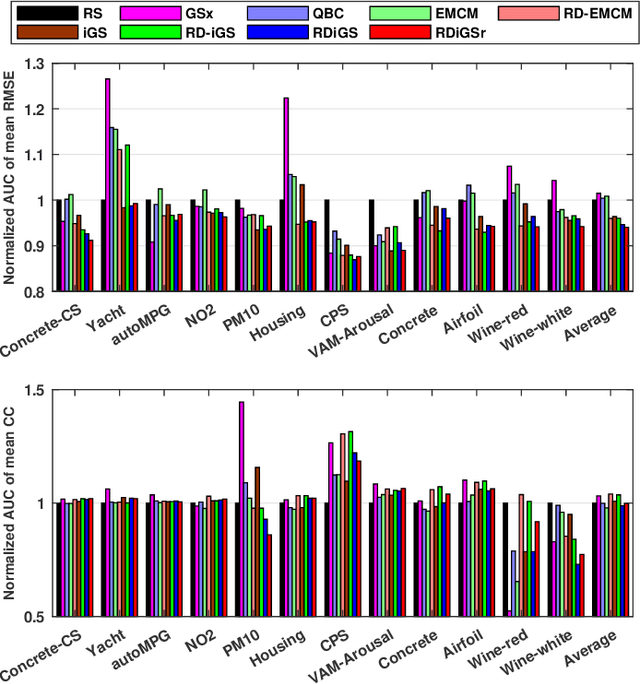
In many real-world machine learning applications, unlabeled samples are easy to obtain, but it is expensive and/or time-consuming to label them. Active learning is a common approach for reducing this data labeling effort. It optimally selects the best few samples to label, so that a better machine learning model can be trained from the same number of labeled samples. This paper considers active learning for regression (ALR) problems. Three essential criteria -- informativeness, representativeness, and diversity -- have been proposed for ALR. However, very few approaches in the literature have considered all three of them simultaneously. We propose three new ALR approaches, with different strategies for integrating the three criteria. Extensive experiments on 12 datasets in various domains demonstrated their effectiveness.
BoostTree and BoostForest for Ensemble Learning
Mar 21, 2020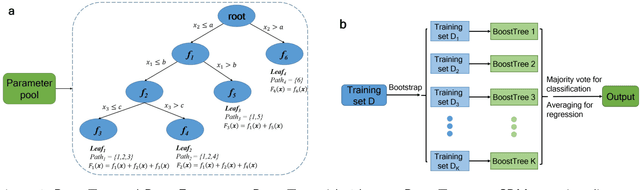
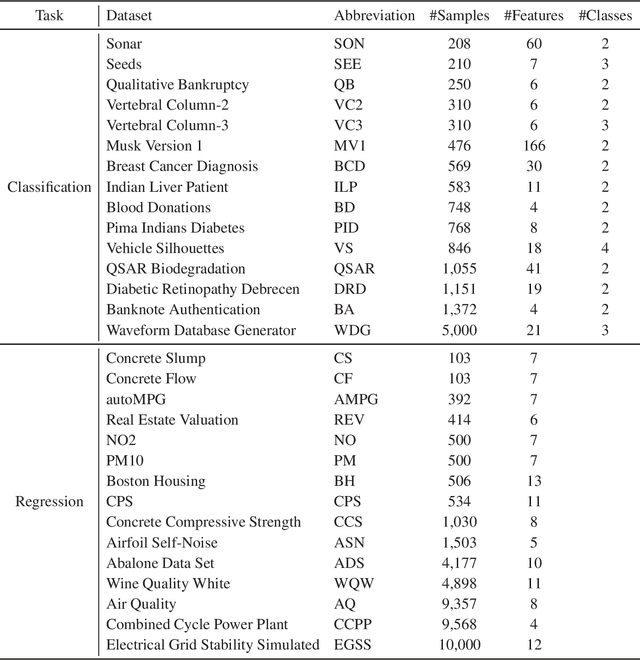

Bootstrap aggregation (Bagging) and boosting are two popular ensemble learning approaches, which combine multiple base learners to generate a composite learner. This article proposes BoostForest, which is an ensemble learning approach using BoostTree as base learners and can be used for both classification and regression. BoostTree constructs a tree by gradient boosting, which trains a linear or nonlinear model at each node. When a new sample comes in, BoostTree first sorts it down to a leaf, then computes the final prediction by summing up the outputs of all models along the path from the root node to that leaf. BoostTree achieves high randomness (diversity) by sampling its parameters randomly from a parameter pool, and selecting a subset of features randomly at node splitting. BoostForest further increases the randomness by bootstrapping the training data in constructing different BoostTrees. BoostForest is compared with four classical ensemble learning approaches on 30 classification and regression datasets, demonstrating that it can generate more accurate and more robust composite learners.
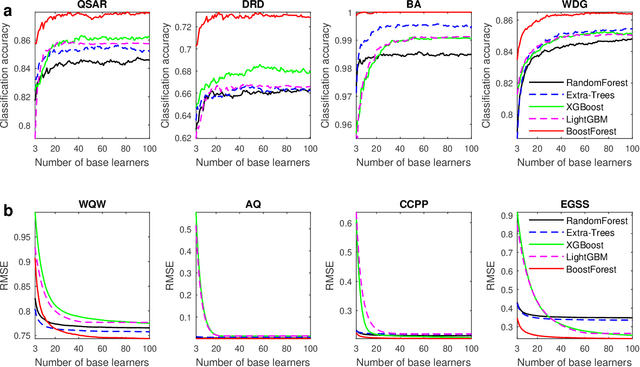
Tiny Noise Can Make an EEG-Based Brain-Computer Interface Speller Output Anything
Mar 04, 2020
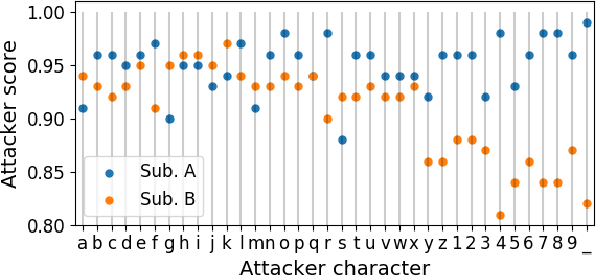
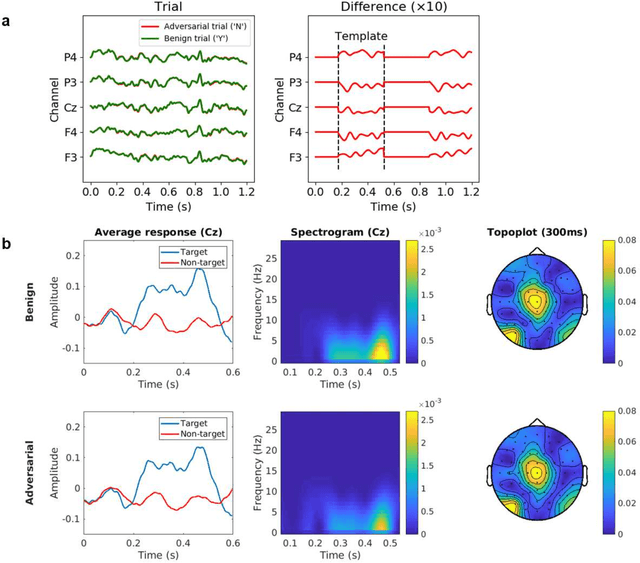
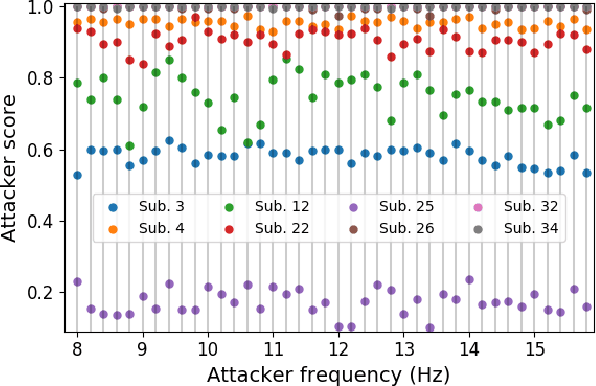
An electroencephalogram (EEG) based brain-computer interface (BCI) speller allows a user to input text to a computer by thought. It is particularly useful to severely disabled individuals, e.g., amyotrophic lateral sclerosis patients, who have no other effective means of communication with another person or a computer. Most studies so far focused on making EEG-based BCI spellers faster and more reliable; however, few have considered their security. Here we show that P300 and steady-state visual evoked potential BCI spellers are very vulnerable, i.e., they can be severely attacked by adversarial perturbations, which are too tiny to be noticed when added to EEG signals, but can mislead the spellers to spell anything the attacker wants. The consequence could range from merely user frustration to severe misdiagnosis in clinical applications. We hope our research can attract more attention to the security of EEG-based BCI spellers, and more broadly, EEG-based BCIs, which has received little attention before.