 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeToward Closed-loop Molecular Discovery via Language Model, Property Alignment and Strategic Search
Dec 18, 2025Drug discovery is a time-consuming and expensive process, with traditional high-throughput and docking-based virtual screening hampered by low success rates and limited scalability. Recent advances in generative modelling, including autoregressive, diffusion, and flow-based approaches, have enabled de novo ligand design beyond the limits of enumerative screening. Yet these models often suffer from inadequate generalization, limited interpretability, and an overemphasis on binding affinity at the expense of key pharmacological properties, thereby restricting their translational utility. Here we present Trio, a molecular generation framework integrating fragment-based molecular language modeling, reinforcement learning, and Monte Carlo tree search, for effective and interpretable closed-loop targeted molecular design. Through the three key components, Trio enables context-aware fragment assembly, enforces physicochemical and synthetic feasibility, and guides a balanced search between the exploration of novel chemotypes and the exploitation of promising intermediates within protein binding pockets. Experimental results show that Trio reliably achieves chemically valid and pharmacologically enhanced ligands, outperforming state-of-the-art approaches with improved binding affinity (+7.85%), drug-likeness (+11.10%) and synthetic accessibility (+12.05%), while expanding molecular diversity more than fourfold. By combining generalization, plausibility, and interpretability, Trio establishes a closed-loop generative paradigm that redefines how chemical space can be navigated, offering a transformative foundation for the next era of AI-driven drug discovery.
4DGS-Craft: Consistent and Interactive 4D Gaussian Splatting Editing
Oct 02, 2025
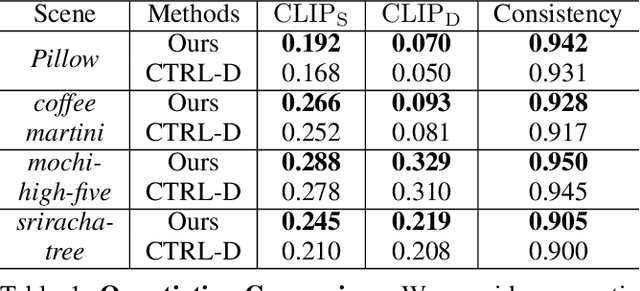
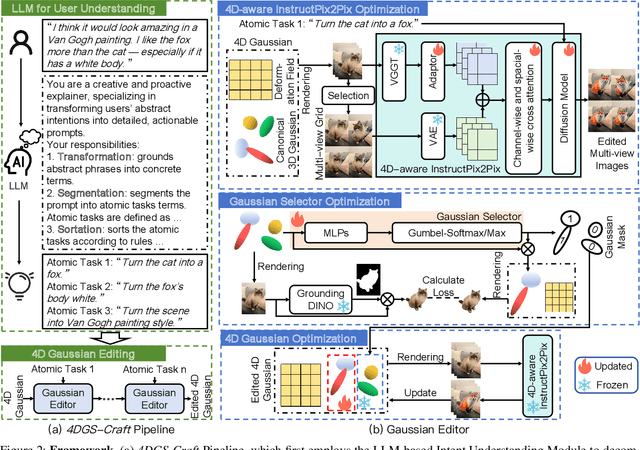
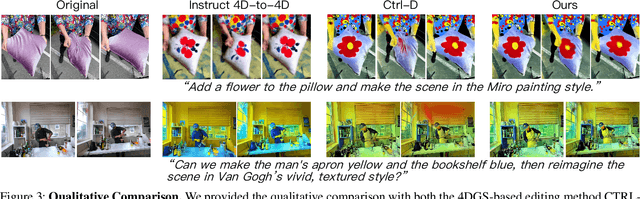
Recent advances in 4D Gaussian Splatting (4DGS) editing still face challenges with view, temporal, and non-editing region consistency, as well as with handling complex text instructions. To address these issues, we propose 4DGS-Craft, a consistent and interactive 4DGS editing framework. We first introduce a 4D-aware InstructPix2Pix model to ensure both view and temporal consistency. This model incorporates 4D VGGT geometry features extracted from the initial scene, enabling it to capture underlying 4D geometric structures during editing. We further enhance this model with a multi-view grid module that enforces consistency by iteratively refining multi-view input images while jointly optimizing the underlying 4D scene. Furthermore, we preserve the consistency of non-edited regions through a novel Gaussian selection mechanism, which identifies and optimizes only the Gaussians within the edited regions. Beyond consistency, facilitating user interaction is also crucial for effective 4DGS editing. Therefore, we design an LLM-based module for user intent understanding. This module employs a user instruction template to define atomic editing operations and leverages an LLM for reasoning. As a result, our framework can interpret user intent and decompose complex instructions into a logical sequence of atomic operations, enabling it to handle intricate user commands and further enhance editing performance. Compared to related works, our approach enables more consistent and controllable 4D scene editing. Our code will be made available upon acceptance.
TOM: An Open-Source Tongue Segmentation Method with Multi-Teacher Distillation and Task-Specific Data Augmentation
Aug 19, 2025Tongue imaging serves as a valuable diagnostic tool, particularly in Traditional Chinese Medicine (TCM). The quality of tongue surface segmentation significantly affects the accuracy of tongue image classification and subsequent diagnosis in intelligent tongue diagnosis systems. However, existing research on tongue image segmentation faces notable limitations, and there is a lack of robust and user-friendly segmentation tools. This paper proposes a tongue image segmentation model (TOM) based on multi-teacher knowledge distillation. By incorporating a novel diffusion-based data augmentation method, we enhanced the generalization ability of the segmentation model while reducing its parameter size. Notably, after reducing the parameter count by 96.6% compared to the teacher models, the student model still achieves an impressive segmentation performance of 95.22% mIoU. Furthermore, we packaged and deployed the trained model as both an online and offline segmentation tool (available at https://itongue.cn/), allowing TCM practitioners and researchers to use it without any programming experience. We also present a case study on TCM constitution classification using segmented tongue patches. Experimental results demonstrate that training with tongue patches yields higher classification performance and better interpretability than original tongue images. To our knowledge, this is the first open-source and freely available tongue image segmentation tool.
On-Device Diffusion Transformer Policy for Efficient Robot Manipulation
Aug 01, 2025Diffusion Policies have significantly advanced robotic manipulation tasks via imitation learning, but their application on resource-constrained mobile platforms remains challenging due to computational inefficiency and extensive memory footprint. In this paper, we propose LightDP, a novel framework specifically designed to accelerate Diffusion Policies for real-time deployment on mobile devices. LightDP addresses the computational bottleneck through two core strategies: network compression of the denoising modules and reduction of the required sampling steps. We first conduct an extensive computational analysis on existing Diffusion Policy architectures, identifying the denoising network as the primary contributor to latency. To overcome performance degradation typically associated with conventional pruning methods, we introduce a unified pruning and retraining pipeline, optimizing the model's post-pruning recoverability explicitly. Furthermore, we combine pruning techniques with consistency distillation to effectively reduce sampling steps while maintaining action prediction accuracy. Experimental evaluations on the standard datasets, \ie, PushT, Robomimic, CALVIN, and LIBERO, demonstrate that LightDP achieves real-time action prediction on mobile devices with competitive performance, marking an important step toward practical deployment of diffusion-based policies in resource-limited environments. Extensive real-world experiments also show the proposed LightDP can achieve performance comparable to state-of-the-art Diffusion Policies.
MODA: A Unified 3D Diffusion Framework for Multi-Task Target-Aware Molecular Generation
Jul 09, 2025Three-dimensional molecular generators based on diffusion models can now reach near-crystallographic accuracy, yet they remain fragmented across tasks. SMILES-only inputs, two-stage pretrain-finetune pipelines, and one-task-one-model practices hinder stereochemical fidelity, task alignment, and zero-shot transfer. We introduce MODA, a diffusion framework that unifies fragment growing, linker design, scaffold hopping, and side-chain decoration with a Bayesian mask scheduler. During training, a contiguous spatial fragment is masked and then denoised in one pass, enabling the model to learn shared geometric and chemical priors across tasks. Multi-task training yields a universal backbone that surpasses six diffusion baselines and three training paradigms on substructure, chemical property, interaction, and geometry. Model-C reduces ligand-protein clashes and substructure divergences while maintaining Lipinski compliance, whereas Model-B preserves similarity but trails in novelty and binding affinity. Zero-shot de novo design and lead-optimisation tests confirm stable negative Vina scores and high improvement rates without force-field refinement. These results demonstrate that a single-stage multi-task diffusion routine can replace two-stage workflows for structure-based molecular design.
Show, Tell and Summarize: Dense Video Captioning Using Visual Cue Aided Sentence Summarization
Jun 25, 2025In this work, we propose a division-and-summarization (DaS) framework for dense video captioning. After partitioning each untrimmed long video as multiple event proposals, where each event proposal consists of a set of short video segments, we extract visual feature (e.g., C3D feature) from each segment and use the existing image/video captioning approach to generate one sentence description for this segment. Considering that the generated sentences contain rich semantic descriptions about the whole event proposal, we formulate the dense video captioning task as a visual cue aided sentence summarization problem and propose a new two stage Long Short Term Memory (LSTM) approach equipped with a new hierarchical attention mechanism to summarize all generated sentences as one descriptive sentence with the aid of visual features. Specifically, the first-stage LSTM network takes all semantic words from the generated sentences and the visual features from all segments within one event proposal as the input, and acts as the encoder to effectively summarize both semantic and visual information related to this event proposal. The second-stage LSTM network takes the output from the first-stage LSTM network and the visual features from all video segments within one event proposal as the input, and acts as the decoder to generate one descriptive sentence for this event proposal. Our comprehensive experiments on the ActivityNet Captions dataset demonstrate the effectiveness of our newly proposed DaS framework for dense video captioning.
Dense Video Captioning using Graph-based Sentence Summarization
Jun 25, 2025Recently, dense video captioning has made attractive progress in detecting and captioning all events in a long untrimmed video. Despite promising results were achieved, most existing methods do not sufficiently explore the scene evolution within an event temporal proposal for captioning, and therefore perform less satisfactorily when the scenes and objects change over a relatively long proposal. To address this problem, we propose a graph-based partition-and-summarization (GPaS) framework for dense video captioning within two stages. For the ``partition" stage, a whole event proposal is split into short video segments for captioning at a finer level. For the ``summarization" stage, the generated sentences carrying rich description information for each segment are summarized into one sentence to describe the whole event. We particularly focus on the ``summarization" stage, and propose a framework that effectively exploits the relationship between semantic words for summarization. We achieve this goal by treating semantic words as nodes in a graph and learning their interactions by coupling Graph Convolutional Network (GCN) and Long Short Term Memory (LSTM), with the aid of visual cues. Two schemes of GCN-LSTM Interaction (GLI) modules are proposed for seamless integration of GCN and LSTM. The effectiveness of our approach is demonstrated via an extensive comparison with the state-of-the-arts methods on the two benchmarks ActivityNet Captions dataset and YouCook II dataset.
Progressive Modality Cooperation for Multi-Modality Domain Adaptation
Jun 24, 2025In this work, we propose a new generic multi-modality domain adaptation framework called Progressive Modality Cooperation (PMC) to transfer the knowledge learned from the source domain to the target domain by exploiting multiple modality clues (\eg, RGB and depth) under the multi-modality domain adaptation (MMDA) and the more general multi-modality domain adaptation using privileged information (MMDA-PI) settings. Under the MMDA setting, the samples in both domains have all the modalities. In two newly proposed modules of our PMC, the multiple modalities are cooperated for selecting the reliable pseudo-labeled target samples, which captures the modality-specific information and modality-integrated information, respectively. Under the MMDA-PI setting, some modalities are missing in the target domain. Hence, to better exploit the multi-modality data in the source domain, we further propose the PMC with privileged information (PMC-PI) method by proposing a new multi-modality data generation (MMG) network. MMG generates the missing modalities in the target domain based on the source domain data by considering both domain distribution mismatch and semantics preservation, which are respectively achieved by using adversarial learning and conditioning on weighted pseudo semantics. Extensive experiments on three image datasets and eight video datasets for various multi-modality cross-domain visual recognition tasks under both MMDA and MMDA-PI settings clearly demonstrate the effectiveness of our proposed PMC framework.
Self-Paced Collaborative and Adversarial Network for Unsupervised Domain Adaptation
Jun 24, 2025



This paper proposes a new unsupervised domain adaptation approach called Collaborative and Adversarial Network (CAN), which uses the domain-collaborative and domain-adversarial learning strategy for training the neural network. The domain-collaborative learning aims to learn domain-specific feature representation to preserve the discriminability for the target domain, while the domain adversarial learning aims to learn domain-invariant feature representation to reduce the domain distribution mismatch between the source and target domains. We show that these two learning strategies can be uniformly formulated as domain classifier learning with positive or negative weights on the losses. We then design a collaborative and adversarial training scheme, which automatically learns domain-specific representations from lower blocks in CNNs through collaborative learning and domain-invariant representations from higher blocks through adversarial learning. Moreover, to further enhance the discriminability in the target domain, we propose Self-Paced CAN (SPCAN), which progressively selects pseudo-labeled target samples for re-training the classifiers. We employ a self-paced learning strategy to select pseudo-labeled target samples in an easy-to-hard fashion. Comprehensive experiments on different benchmark datasets, Office-31, ImageCLEF-DA, and VISDA-2017 for the object recognition task, and UCF101-10 and HMDB51-10 for the video action recognition task, show our newly proposed approaches achieve the state-of-the-art performance, which clearly demonstrates the effectiveness of our proposed approaches for unsupervised domain adaptation.
Reimagining Target-Aware Molecular Generation through Retrieval-Enhanced Aligned Diffusion
Jun 17, 2025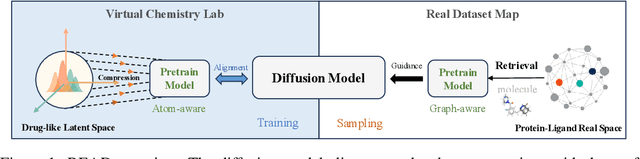
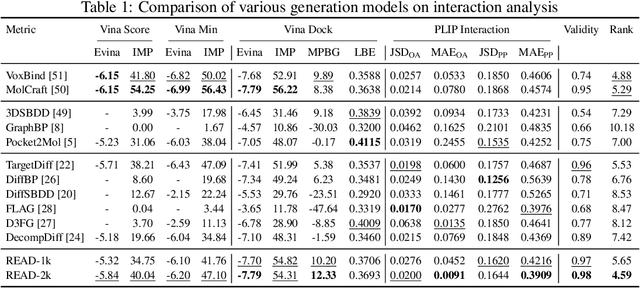
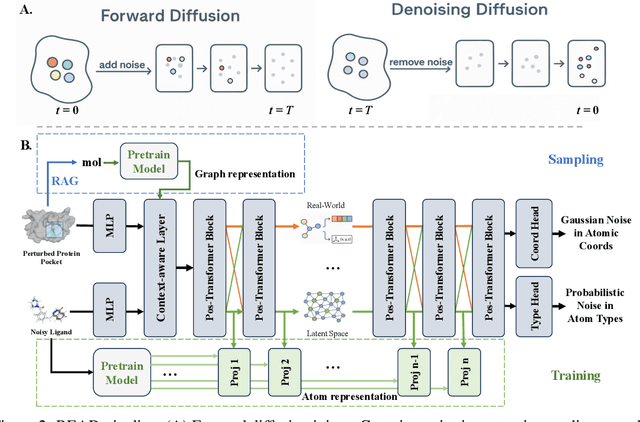
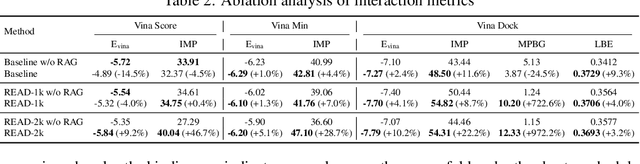
Breakthroughs in high-accuracy protein structure prediction, such as AlphaFold, have established receptor-based molecule design as a critical driver for rapid early-phase drug discovery. However, most approaches still struggle to balance pocket-specific geometric fit with strict valence and synthetic constraints. To resolve this trade-off, a Retrieval-Enhanced Aligned Diffusion termed READ is introduced, which is the first to merge molecular Retrieval-Augmented Generation with an SE(3)-equivariant diffusion model. Specifically, a contrastively pre-trained encoder aligns atom-level representations during training, then retrieves graph embeddings of pocket-matched scaffolds to guide each reverse-diffusion step at inference. This single mechanism can inject real-world chemical priors exactly where needed, producing valid, diverse, and shape-complementary ligands. Experimental results demonstrate that READ can achieve very competitive performance in CBGBench, surpassing state-of-the-art generative models and even native ligands. That suggests retrieval and diffusion can be co-optimized for faster, more reliable structure-based drug design.