 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeForethought and Hindsight in Credit Assignment
Oct 26, 2020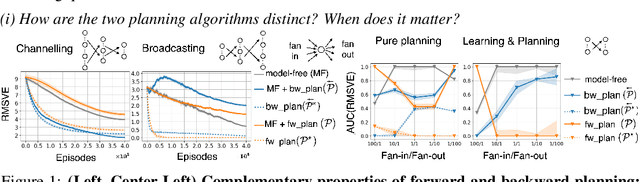
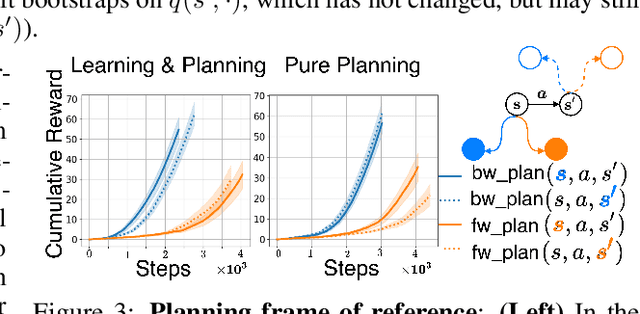
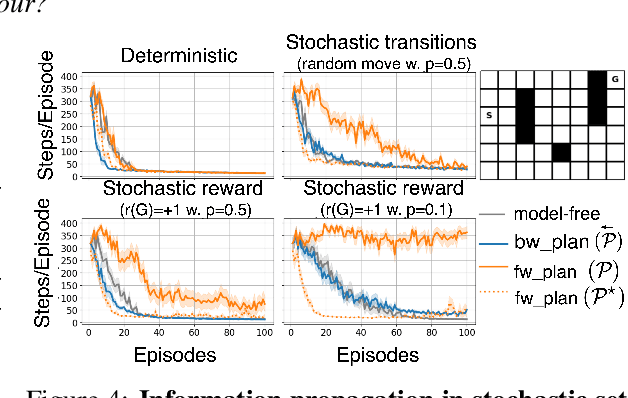

We address the problem of credit assignment in reinforcement learning and explore fundamental questions regarding the way in which an agent can best use additional computation to propagate new information, by planning with internal models of the world to improve its predictions. Particularly, we work to understand the gains and peculiarities of planning employed as forethought via forward models or as hindsight operating with backward models. We establish the relative merits, limitations and complementary properties of both planning mechanisms in carefully constructed scenarios. Further, we investigate the best use of models in planning, primarily focusing on the selection of states in which predictions should be (re)-evaluated. Lastly, we discuss the issue of model estimation and highlight a spectrum of methods that stretch from explicit environment-dynamics predictors to more abstract planner-aware models.
Connecting Weighted Automata, Tensor Networks and Recurrent Neural Networks through Spectral Learning
Oct 19, 2020
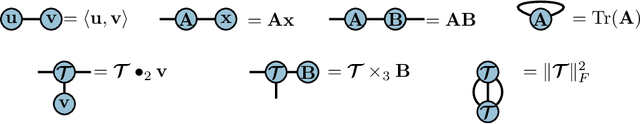

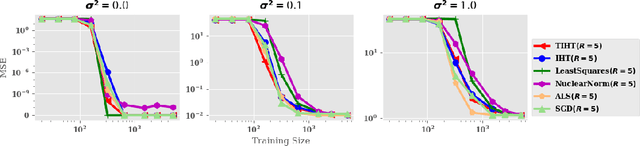
In this paper, we present connections between three models used in different research fields: weighted finite automata~(WFA) from formal languages and linguistics, recurrent neural networks used in machine learning, and tensor networks which encompasses a set of optimization techniques for high-order tensors used in quantum physics and numerical analysis. We first present an intrinsic relation between WFA and the tensor train decomposition, a particular form of tensor network. This relation allows us to exhibit a novel low rank structure of the Hankel matrix of a function computed by a WFA and to design an efficient spectral learning algorithm leveraging this structure to scale the algorithm up to very large Hankel matrices. We then unravel a fundamental connection between WFA and second-order recurrent neural networks~(2-RNN): in the case of sequences of discrete symbols, WFA and 2-RNN with linear activation functions are expressively equivalent. Furthermore, we introduce the first provable learning algorithm for linear 2-RNN defined over sequences of continuous input vectors. This algorithm relies on estimating low rank sub-blocks of the Hankel tensor, from which the parameters of a linear 2-RNN can be provably recovered. The performances of the proposed learning algorithm are assessed in a simulation study on both synthetic and real-world data.
A Fully Tensorized Recurrent Neural Network
Oct 13, 2020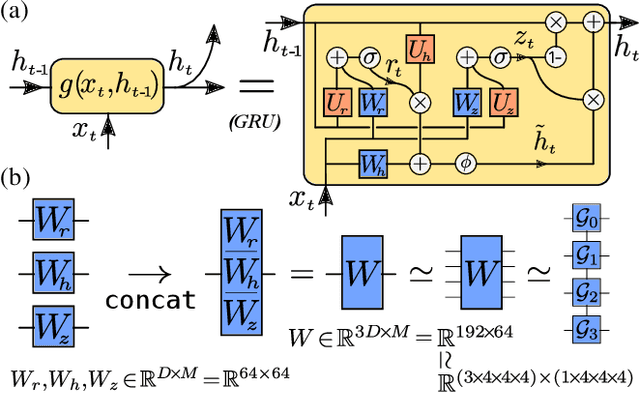
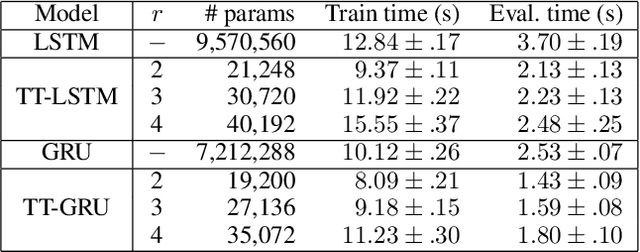
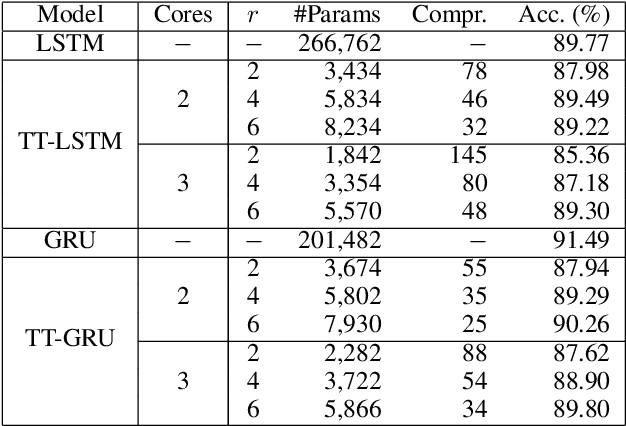
Recurrent neural networks (RNNs) are powerful tools for sequential modeling, but typically require significant overparameterization and regularization to achieve optimal performance. This leads to difficulties in the deployment of large RNNs in resource-limited settings, while also introducing complications in hyperparameter selection and training. To address these issues, we introduce a "fully tensorized" RNN architecture which jointly encodes the separate weight matrices within each recurrent cell using a lightweight tensor-train (TT) factorization. This approach represents a novel form of weight sharing which reduces model size by several orders of magnitude, while still maintaining similar or better performance compared to standard RNNs. Experiments on image classification and speaker verification tasks demonstrate further benefits for reducing inference times and stabilizing model training and hyperparameter selection.
Reward Propagation Using Graph Convolutional Networks
Oct 06, 2020

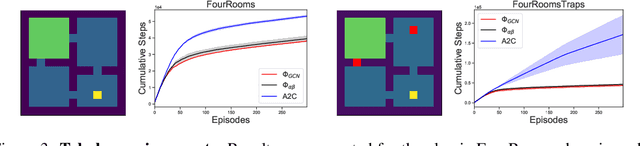
Potential-based reward shaping provides an approach for designing good reward functions, with the purpose of speeding up learning. However, automatically finding potential functions for complex environments is a difficult problem (in fact, of the same difficulty as learning a value function from scratch). We propose a new framework for learning potential functions by leveraging ideas from graph representation learning. Our approach relies on Graph Convolutional Networks which we use as a key ingredient in combination with the probabilistic inference view of reinforcement learning. More precisely, we leverage Graph Convolutional Networks to perform message passing from rewarding states. The propagated messages can then be used as potential functions for reward shaping to accelerate learning. We verify empirically that our approach can achieve considerable improvements in both small and high-dimensional control problems.
Complete the Missing Half: Augmenting Aggregation Filtering with Diversification for Graph Convolutional Networks
Sep 15, 2020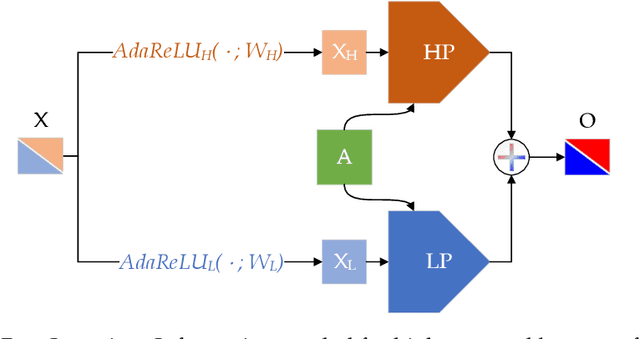
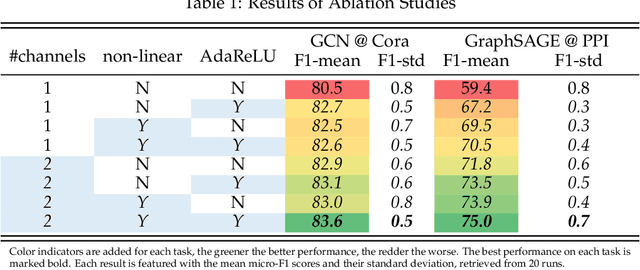
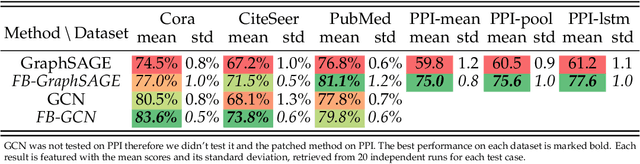
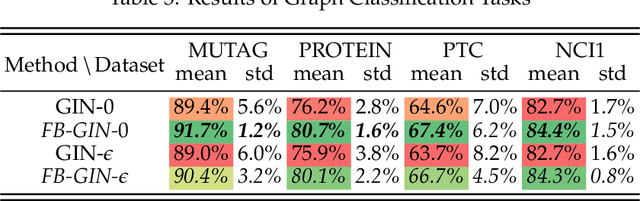
The core operation of current Graph Neural Networks (GNNs) is the aggregation enabled by the graph Laplacian or message passing, which filters the neighborhood node information. Though effective for various tasks, in this paper, we show that they are potentially a problematic factor underlying all GNN methods for learning on certain datasets, as they force the node representations similar, making the nodes gradually lose their identity and become indistinguishable. Hence, we augment the aggregation operations with their dual, i.e. diversification operators that make the node more distinct and preserve the identity. Such augmentation replaces the aggregation with a two-channel filtering process that, in theory, is beneficial for enriching the node representations. In practice, the proposed two-channel filters can be easily patched on existing GNN methods with diverse training strategies, including spectral and spatial (message passing) methods. In the experiments, we observe desired characteristics of the models and significant performance boost upon the baselines on 9 node classification tasks.
Training Matters: Unlocking Potentials of Deeper Graph Convolutional Neural Networks
Aug 20, 2020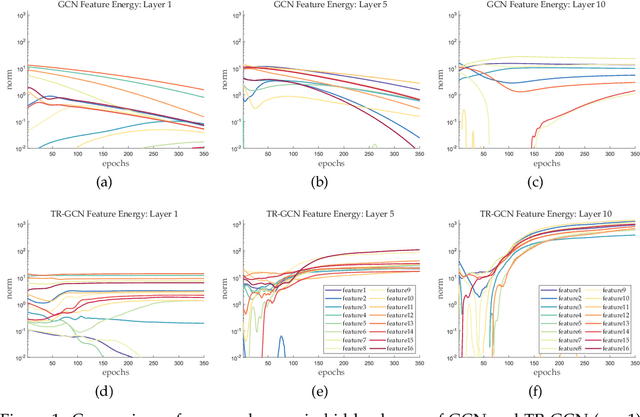
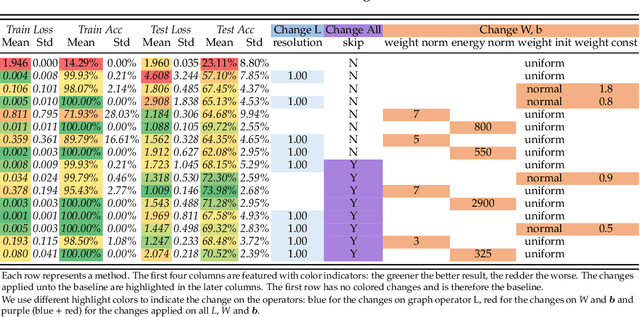
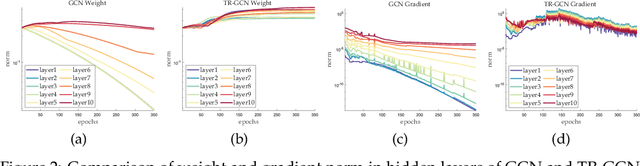
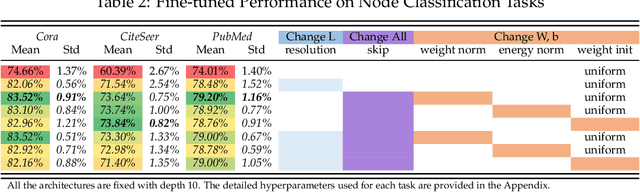
The performance limit of Graph Convolutional Networks (GCNs) and the fact that we cannot stack more of them to increase the performance, which we usually do for other deep learning paradigms, are pervasively thought to be caused by the limitations of the GCN layers, including insufficient expressive power, etc. However, if so, for a fixed architecture, it would be unlikely to lower the training difficulty and to improve performance by changing only the training procedure, which we show in this paper not only possible but possible in several ways. This paper first identify the training difficulty of GCNs from the perspective of graph signal energy loss. More specifically, we find that the loss of energy in the backward pass during training nullifies the learning of the layers closer to the input. Then, we propose several methodologies to mitigate the training problem by slightly modifying the GCN operator, from the energy perspective. After empirical validation, we confirm that these changes of operator lead to significant decrease in the training difficulties and notable performance boost, without changing the composition of parameters. With these, we conclude that the root cause of the problem is more likely the training difficulty than the others.
An Equivalence between Loss Functions and Non-Uniform Sampling in Experience Replay
Jul 12, 2020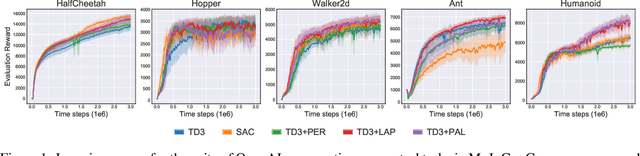
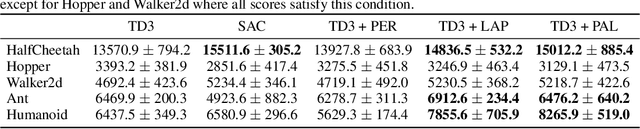
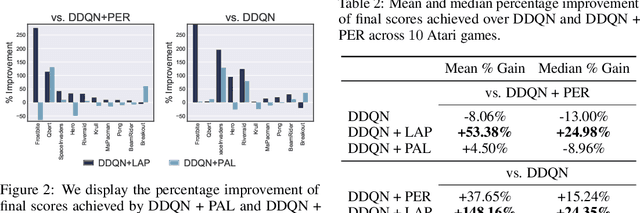
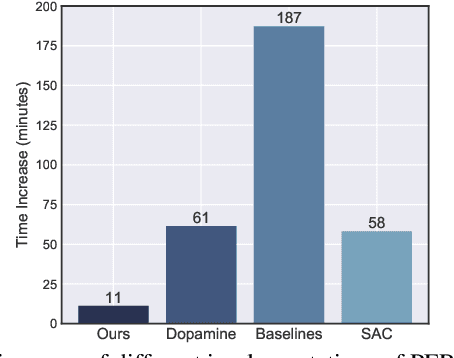
Prioritized Experience Replay (PER) is a deep reinforcement learning technique in which agents learn from transitions sampled with non-uniform probability proportionate to their temporal-difference error. We show that any loss function evaluated with non-uniformly sampled data can be transformed into another uniformly sampled loss function with the same expected gradient. Surprisingly, we find in some environments PER can be replaced entirely by this new loss function without impact to empirical performance. Furthermore, this relationship suggests a new branch of improvements to PER by correcting its uniformly sampled loss function equivalent. We demonstrate the effectiveness of our proposed modifications to PER and the equivalent loss function in several MuJoCo and Atari environments.
A Brief Look at Generalization in Visual Meta-Reinforcement Learning
Jul 03, 2020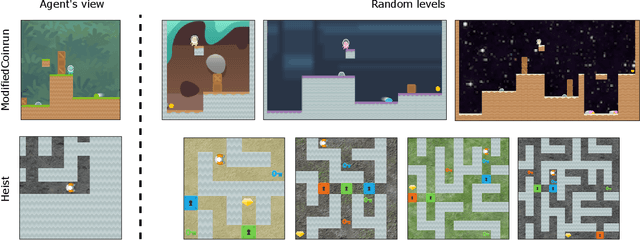
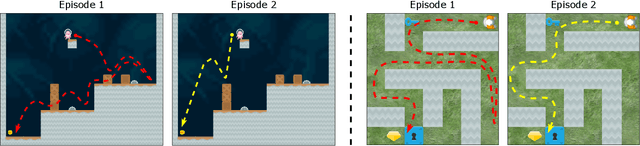
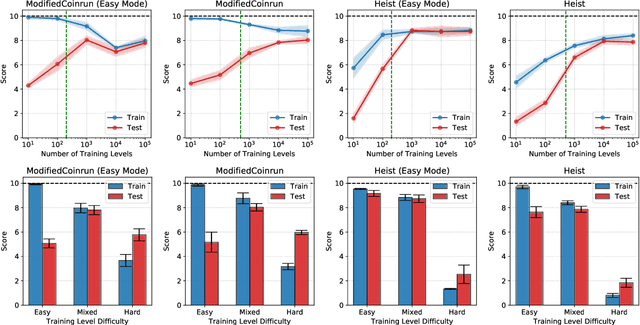
Due to the realization that deep reinforcement learning algorithms trained on high-dimensional tasks can strongly overfit to their training environments, there have been several studies that investigated the generalization performance of these algorithms. However, there has been no similar study that evaluated the generalization performance of algorithms that were specifically designed for generalization, i.e. meta-reinforcement learning algorithms. In this paper, we assess the generalization performance of these algorithms by leveraging high-dimensional, procedurally generated environments. We find that these algorithms can display strong overfitting when they are evaluated on challenging tasks. We also observe that scalability to high-dimensional tasks with sparse rewards remains a significant problem among many of the current meta-reinforcement learning algorithms. With these results, we highlight the need for developing meta-reinforcement learning algorithms that can both generalize and scale.
What can I do here? A Theory of Affordances in Reinforcement Learning
Jun 26, 2020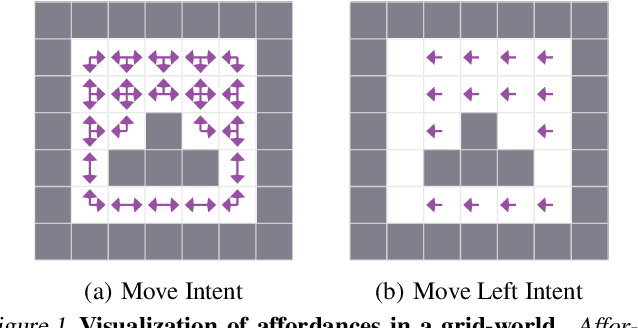
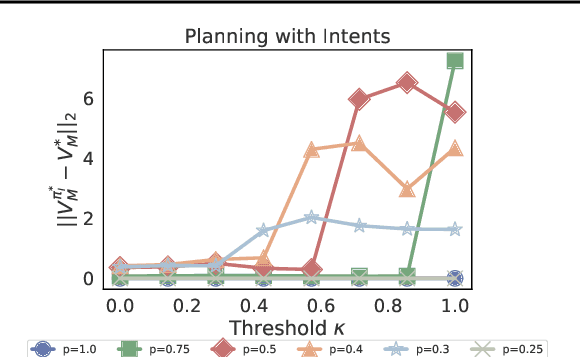
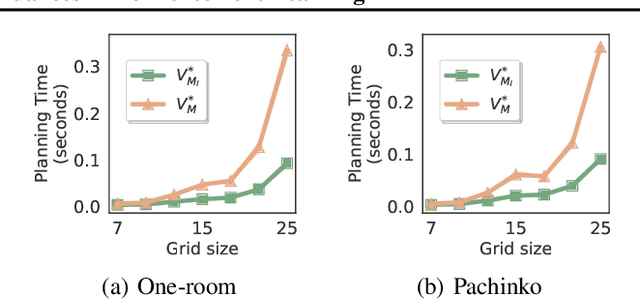
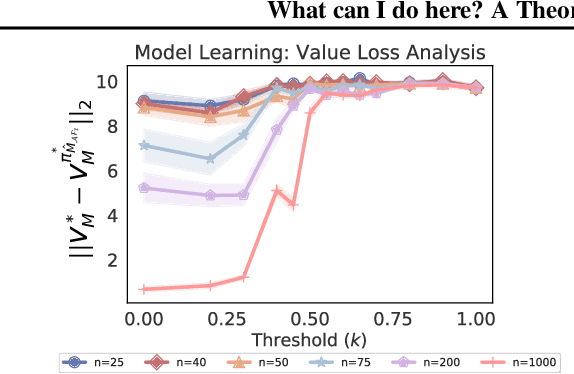
Reinforcement learning algorithms usually assume that all actions are always available to an agent. However, both people and animals understand the general link between the features of their environment and the actions that are feasible. Gibson (1977) coined the term "affordances" to describe the fact that certain states enable an agent to do certain actions, in the context of embodied agents. In this paper, we develop a theory of affordances for agents who learn and plan in Markov Decision Processes. Affordances play a dual role in this case. On one hand, they allow faster planning, by reducing the number of actions available in any given situation. On the other hand, they facilitate more efficient and precise learning of transition models from data, especially when such models require function approximation. We establish these properties through theoretical results as well as illustrative examples. We also propose an approach to learn affordances and use it to estimate transition models that are simpler and generalize better.
Learning to Prove from Synthetic Theorems
Jun 19, 2020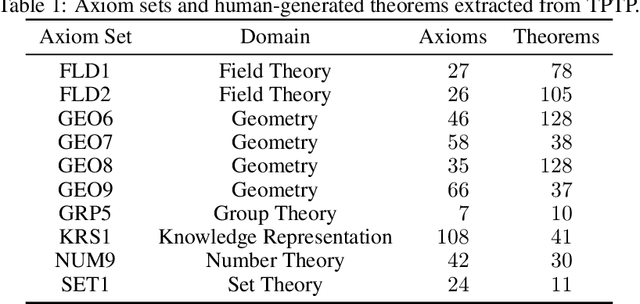
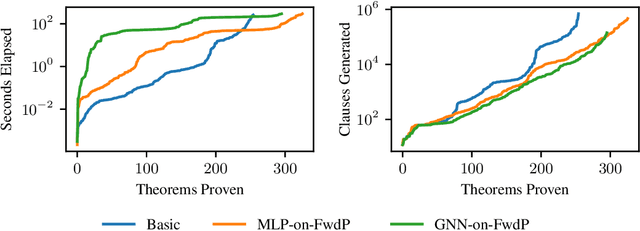
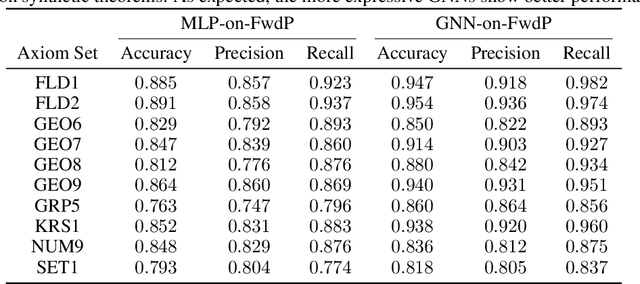
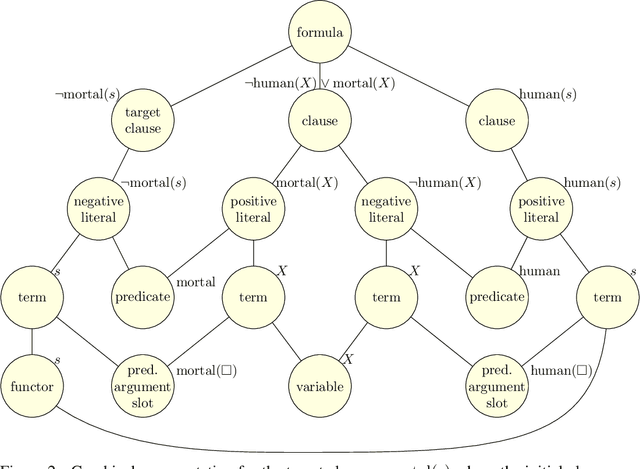
A major challenge in applying machine learning to automated theorem proving is the scarcity of training data, which is a key ingredient in training successful deep learning models. To tackle this problem, we propose an approach that relies on training with synthetic theorems, generated from a set of axioms. We show that such theorems can be used to train an automated prover and that the learned prover transfers successfully to human-generated theorems. We demonstrate that a prover trained exclusively on synthetic theorems can solve a substantial fraction of problems in TPTP, a benchmark dataset that is used to compare state-of-the-art heuristic provers. Our approach outperforms a model trained on human-generated problems in most axiom sets, thereby showing the promise of using synthetic data for this task.