 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVector Quantized Wasserstein Auto-Encoder
Feb 12, 2023Learning deep discrete latent presentations offers a promise of better symbolic and summarized abstractions that are more useful to subsequent downstream tasks. Inspired by the seminal Vector Quantized Variational Auto-Encoder (VQ-VAE), most of work in learning deep discrete representations has mainly focused on improving the original VQ-VAE form and none of them has studied learning deep discrete representations from the generative viewpoint. In this work, we study learning deep discrete representations from the generative viewpoint. Specifically, we endow discrete distributions over sequences of codewords and learn a deterministic decoder that transports the distribution over the sequences of codewords to the data distribution via minimizing a WS distance between them. We develop further theories to connect it with the clustering viewpoint of WS distance, allowing us to have a better and more controllable clustering solution. Finally, we empirically evaluate our method on several well-known benchmarks, where it achieves better qualitative and quantitative performances than the other VQ-VAE variants in terms of the codebook utilization and image reconstruction/generation.
Flat Seeking Bayesian Neural Networks
Feb 09, 2023Bayesian Neural Networks (BNNs) offer a probabilistic interpretation for deep learning models by imposing a prior distribution over model parameters and inferencing a posterior distribution based on observed data. The model sampled from the posterior distribution can be used for providing ensemble predictions and quantifying prediction uncertainty. It is well-known that deep learning models with a lower sharpness have a better generalization ability. Nonetheless, existing posterior inferences are not aware of sharpness/flatness, hence possibly leading to high sharpness for the models sampled from it. In this paper, we develop theories, the Bayesian setting, and the variational inference approach for the sharpness-aware posterior. Specifically, the models sampled from our sharpness-aware posterior and the optimal approximate posterior estimating this sharpness-aware posterior have a better flatness, hence possibly possessing a higher generalization ability. We conduct experiments by leveraging the sharpness-aware posterior with the state-of-the-art Bayesian Neural Networks, showing that the flat-seeking counterparts outperform their baselines in all metrics of interest.
Class Enhancement Losses with Pseudo Labels for Zero-shot Semantic Segmentation
Jan 18, 2023



Recent mask proposal models have significantly improved the performance of zero-shot semantic segmentation. However, the use of a `background' embedding during training in these methods is problematic as the resulting model tends to over-learn and assign all unseen classes as the background class instead of their correct labels. Furthermore, they ignore the semantic relationship of text embeddings, which arguably can be highly informative for zero-shot prediction as seen classes may have close relationship with unseen classes. To this end, this paper proposes novel class enhancement losses to bypass the use of the background embbedding during training, and simultaneously exploit the semantic relationship between text embeddings and mask proposals by ranking the similarity scores. To further capture the relationship between seen and unseen classes, we propose an effective pseudo label generation pipeline using pretrained vision-language model. Extensive experiments on several benchmark datasets show that our method achieves overall the best performance for zero-shot semantic segmentation. Our method is flexible, and can also be applied to the challenging open-vocabulary semantic segmentation problem.
Multiple Perturbation Attack: Attack Pixelwise Under Different $\ell_p$-norms For Better Adversarial Performance
Dec 07, 2022



Adversarial machine learning has been both a major concern and a hot topic recently, especially with the ubiquitous use of deep neural networks in the current landscape. Adversarial attacks and defenses are usually likened to a cat-and-mouse game in which defenders and attackers evolve over the time. On one hand, the goal is to develop strong and robust deep networks that are resistant to malicious actors. On the other hand, in order to achieve that, we need to devise even stronger adversarial attacks to challenge these defense models. Most of existing attacks employs a single $\ell_p$ distance (commonly, $p\in\{1,2,\infty\}$) to define the concept of closeness and performs steepest gradient ascent w.r.t. this $p$-norm to update all pixels in an adversarial example in the same way. These $\ell_p$ attacks each has its own pros and cons; and there is no single attack that can successfully break through defense models that are robust against multiple $\ell_p$ norms simultaneously. Motivated by these observations, we come up with a natural approach: combining various $\ell_p$ gradient projections on a pixel level to achieve a joint adversarial perturbation. Specifically, we learn how to perturb each pixel to maximize the attack performance, while maintaining the overall visual imperceptibility of adversarial examples. Finally, through various experiments with standardized benchmarks, we show that our method outperforms most current strong attacks across state-of-the-art defense mechanisms, while retaining its ability to remain clean visually.
Continual Learning with Optimal Transport based Mixture Model
Dec 05, 2022Online Class Incremental learning (CIL) is a challenging setting in Continual Learning (CL), wherein data of new tasks arrive in incoming streams and online learning models need to handle incoming data streams without revisiting previous ones. Existing works used a single centroid adapted with incoming data streams to characterize a class. This approach possibly exposes limitations when the incoming data stream of a class is naturally multimodal. To address this issue, in this work, we first propose an online mixture model learning approach based on nice properties of the mature optimal transport theory (OT-MM). Specifically, the centroids and covariance matrices of the mixture model are adapted incrementally according to incoming data streams. The advantages are two-fold: (i) we can characterize more accurately complex data streams and (ii) by using centroids for each class produced by OT-MM, we can estimate the similarity of an unseen example to each class more reasonably when doing inference. Moreover, to combat the catastrophic forgetting in the CIL scenario, we further propose Dynamic Preservation. Particularly, after performing the dynamic preservation technique across data streams, the latent representations of the classes in the old and new tasks become more condensed themselves and more separate from each other. Together with a contraction feature extractor, this technique facilitates the model in mitigating the catastrophic forgetting. The experimental results on real-world datasets show that our proposed method can significantly outperform the current state-of-the-art baselines.
Improving Multi-task Learning via Seeking Task-based Flat Regions
Nov 24, 2022



Multi-Task Learning (MTL) is a widely-used and powerful learning paradigm for training deep neural networks that allows learning more than one objective by a single backbone. Compared to training tasks separately, MTL significantly reduces computational costs, improves data efficiency, and potentially enhances model performance by leveraging knowledge across tasks. Hence, it has been adopted in a variety of applications, ranging from computer vision to natural language processing and speech recognition. Among them, there is an emerging line of work in MTL that focuses on manipulating the task gradient to derive an ultimate gradient descent direction to benefit all tasks. Despite achieving impressive results on many benchmarks, directly applying these approaches without using appropriate regularization techniques might lead to suboptimal solutions on real-world problems. In particular, standard training that minimizes the empirical loss on the training data can easily suffer from overfitting to low-resource tasks or be spoiled by noisy-labeled ones, which can cause negative transfer between tasks and overall performance drop. To alleviate such problems, we propose to leverage a recently introduced training method, named Sharpness-aware Minimization, which can enhance model generalization ability on single-task learning. Accordingly, we present a novel MTL training methodology, encouraging the model to find task-based flat minima for coherently improving its generalization capability on all tasks. Finally, we conduct comprehensive experiments on a variety of applications to demonstrate the merit of our proposed approach to existing gradient-based MTL methods, as suggested by our developed theory.
Vision Transformer Visualization: What Neurons Tell and How Neurons Behave?
Oct 18, 2022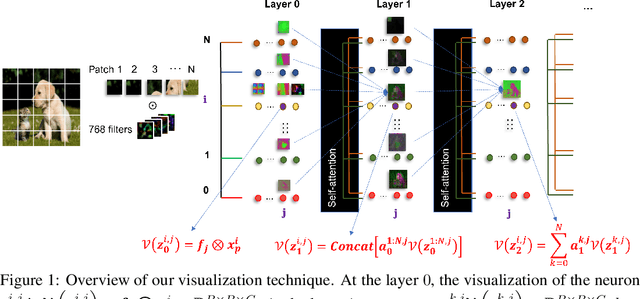
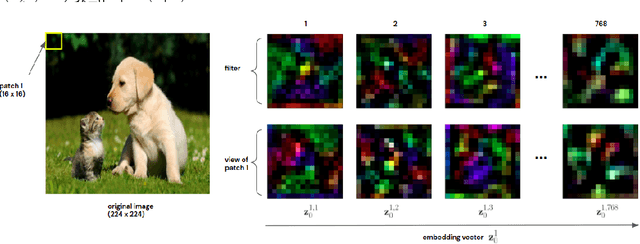


Recently vision transformers (ViT) have been applied successfully for various tasks in computer vision. However, important questions such as why they work or how they behave still remain largely unknown. In this paper, we propose an effective visualization technique, to assist us in exposing the information carried in neurons and feature embeddings across the ViT's layers. Our approach departs from the computational process of ViTs with a focus on visualizing the local and global information in input images and the latent feature embeddings at multiple levels. Visualizations at the input and embeddings at level 0 reveal interesting findings such as providing support as to why ViTs are rather generally robust to image occlusions and patch shuffling; or unlike CNNs, level 0 embeddings already carry rich semantic details. Next, we develop a rigorous framework to perform effective visualizations across layers, exposing the effects of ViTs filters and grouping/clustering behaviors to object patches. Finally, we provide comprehensive experiments on real datasets to qualitatively and quantitatively demonstrate the merit of our proposed methods as well as our findings. https://github.com/byM1902/ViT_visualization
Learning to Counter: Stochastic Feature-based Learning for Diverse Counterfactual Explanations
Sep 27, 2022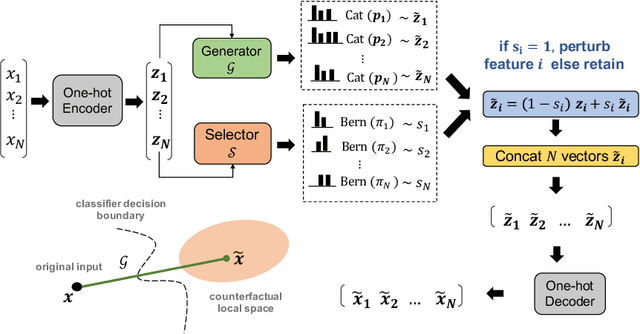

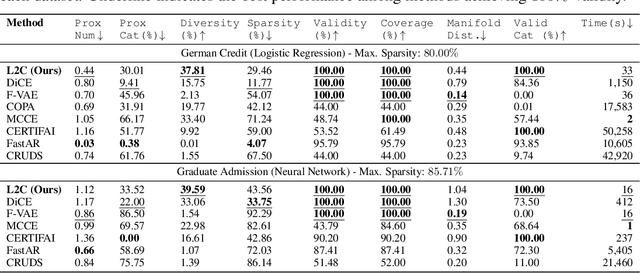
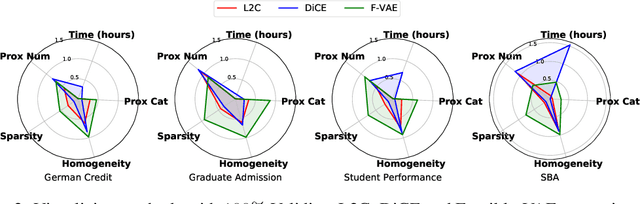
Interpretable machine learning seeks to understand the reasoning process of complex black-box systems that are long notorious for lack of explainability. One growing interpreting approach is through counterfactual explanations, which go beyond why a system arrives at a certain decision to further provide suggestions on what a user can do to alter the outcome. A counterfactual example must be able to counter the original prediction from the black-box classifier, while also satisfying various constraints for practical applications. These constraints exist at trade-offs between one and another presenting radical challenges to existing works. To this end, we propose a stochastic learning-based framework that effectively balances the counterfactual trade-offs. The framework consists of a generation and a feature selection module with complementary roles: the former aims to model the distribution of valid counterfactuals whereas the latter serves to enforce additional constraints in a way that allows for differentiable training and amortized optimization. We demonstrate the effectiveness of our method in generating actionable and plausible counterfactuals that are more diverse than the existing methods and particularly in a more efficient manner than counterparts of the same capacity.
An Information-Theoretic and Contrastive Learning-based Approach for Identifying Code Statements Causing Software Vulnerability
Sep 20, 2022
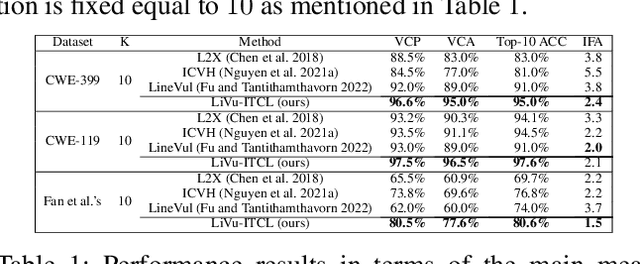
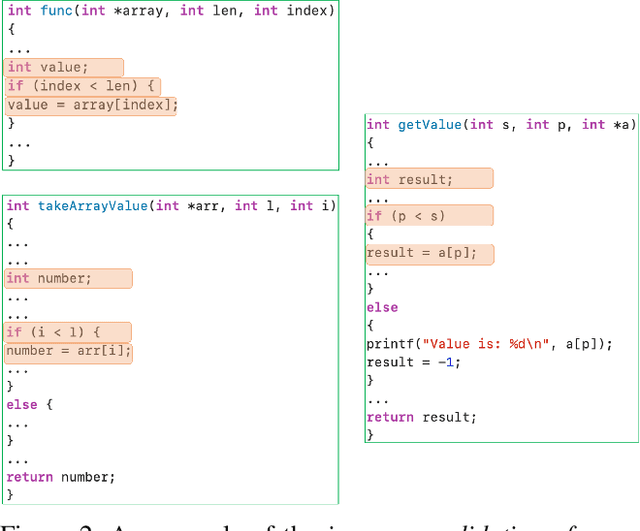
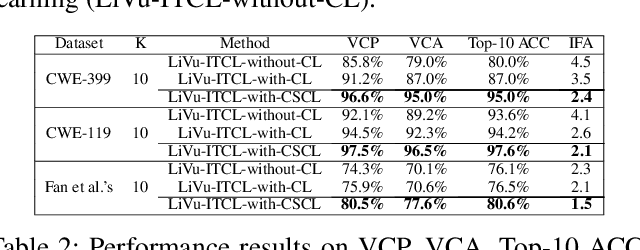
Software vulnerabilities existing in a program or function of computer systems are a serious and crucial concern. Typically, in a program or function consisting of hundreds or thousands of source code statements, there are only few statements causing the corresponding vulnerabilities. Vulnerability labeling is currently done on a function or program level by experts with the assistance of machine learning tools. Extending this approach to the code statement level is much more costly and time-consuming and remains an open problem. In this paper we propose a novel end-to-end deep learning-based approach to identify the vulnerability-relevant code statements of a specific function. Inspired by the specific structures observed in real world vulnerable code, we first leverage mutual information for learning a set of latent variables representing the relevance of the source code statements to the corresponding function's vulnerability. We then propose novel clustered spatial contrastive learning in order to further improve the representation learning and the robust selection process of vulnerability-relevant code statements. Experimental results on real-world datasets of 200k+ C/C++ functions show the superiority of our method over other state-of-the-art baselines. In general, our method obtains a higher performance in VCP, VCA, and Top-10 ACC measures of between 3\% to 14\% over the baselines when running on real-world datasets in an unsupervised setting. Our released source code samples are publicly available at \href{https://github.com/vannguyennd/livuitcl}{https://github.com/vannguyennd/livuitcl.}
Cross Project Software Vulnerability Detection via Domain Adaptation and Max-Margin Principle
Sep 19, 2022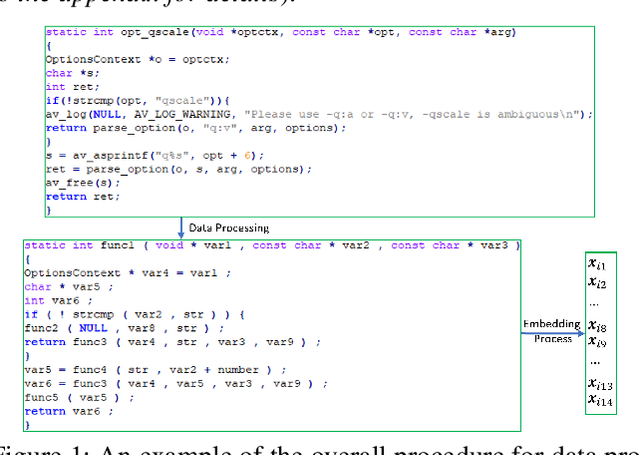
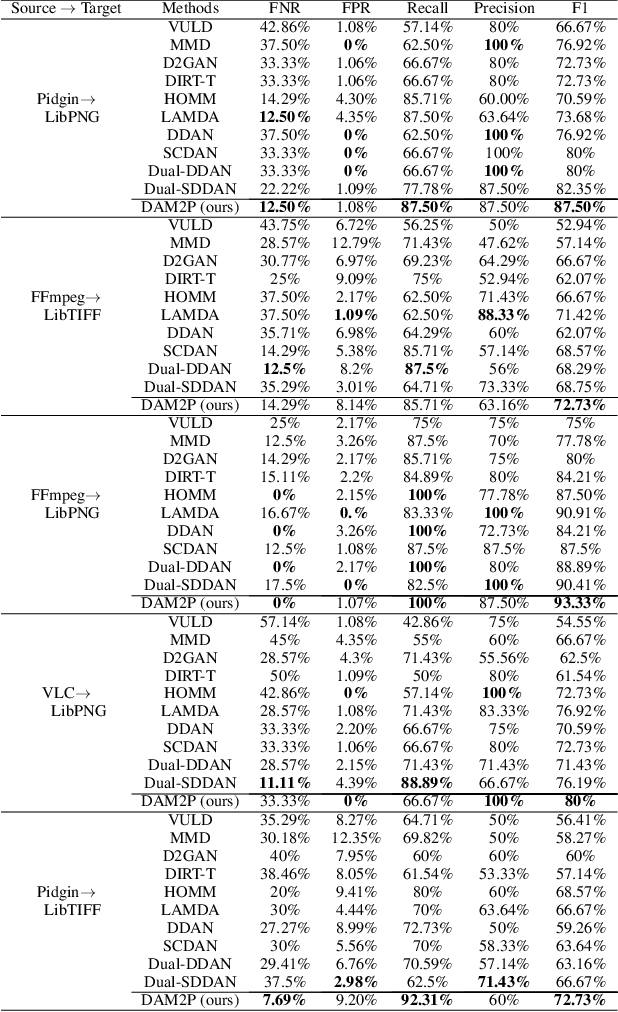
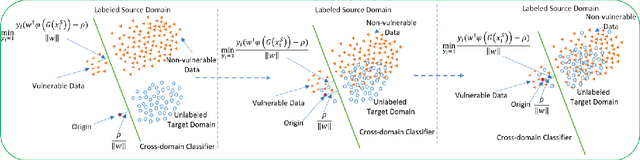
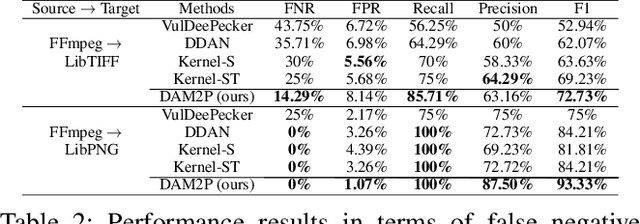
Software vulnerabilities (SVs) have become a common, serious and crucial concern due to the ubiquity of computer software. Many machine learning-based approaches have been proposed to solve the software vulnerability detection (SVD) problem. However, there are still two open and significant issues for SVD in terms of i) learning automatic representations to improve the predictive performance of SVD, and ii) tackling the scarcity of labeled vulnerabilities datasets that conventionally need laborious labeling effort by experts. In this paper, we propose a novel end-to-end approach to tackle these two crucial issues. We first exploit the automatic representation learning with deep domain adaptation for software vulnerability detection. We then propose a novel cross-domain kernel classifier leveraging the max-margin principle to significantly improve the transfer learning process of software vulnerabilities from labeled projects into unlabeled ones. The experimental results on real-world software datasets show the superiority of our proposed method over state-of-the-art baselines. In short, our method obtains a higher performance on F1-measure, the most important measure in SVD, from 1.83% to 6.25% compared to the second highest method in the used datasets. Our released source code samples are publicly available at https://github.com/vannguyennd/dam2p