 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConvergence and Margin of Adversarial Training on Separable Data
May 22, 2019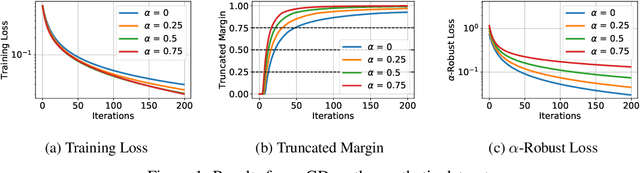
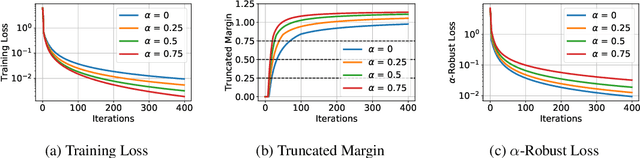
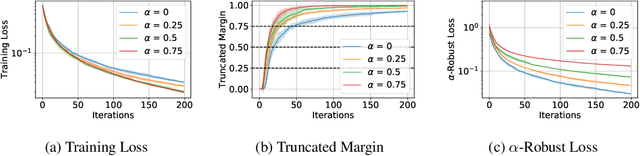
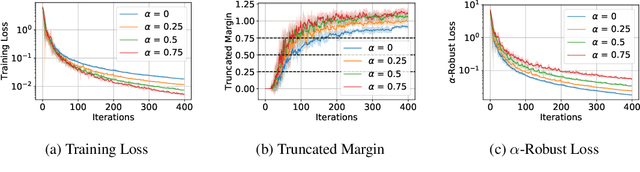
Adversarial training is a technique for training robust machine learning models. To encourage robustness, it iteratively computes adversarial examples for the model, and then re-trains on these examples via some update rule. This work analyzes the performance of adversarial training on linearly separable data, and provides bounds on the number of iterations required for large margin. We show that when the update rule is given by an arbitrary empirical risk minimizer, adversarial training may require exponentially many iterations to obtain large margin. However, if gradient or stochastic gradient update rules are used, only polynomially many iterations are required to find a large-margin separator. By contrast, without the use of adversarial examples, gradient methods may require exponentially many iterations to achieve large margin. Our results are derived by showing that adversarial training with gradient updates minimizes a robust version of the empirical risk at a $\mathcal{O}(\ln(t)^2/t)$ rate, despite non-smoothness. We corroborate our theory empirically.
Does Data Augmentation Lead to Positive Margin?
May 08, 2019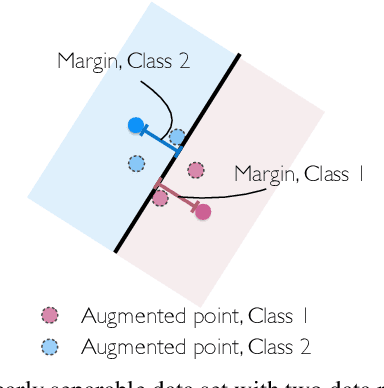
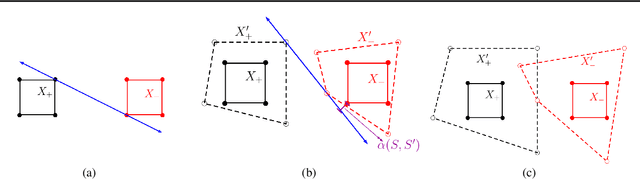
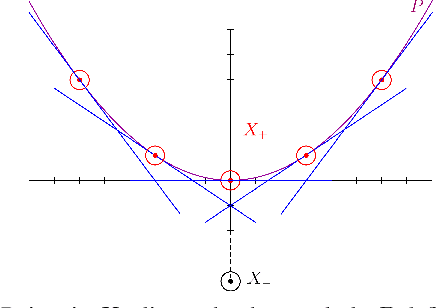
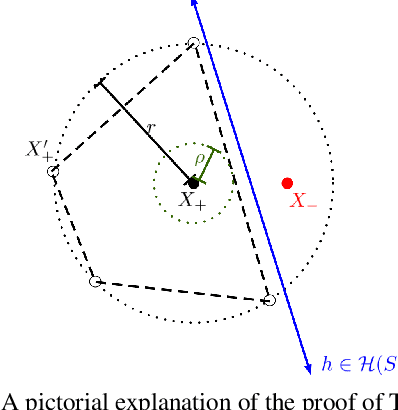
Data augmentation (DA) is commonly used during model training, as it significantly improves test error and model robustness. DA artificially expands the training set by applying random noise, rotations, crops, or even adversarial perturbations to the input data. Although DA is widely used, its capacity to provably improve robustness is not fully understood. In this work, we analyze the robustness that DA begets by quantifying the margin that DA enforces on empirical risk minimizers. We first focus on linear separators, and then a class of nonlinear models whose labeling is constant within small convex hulls of data points. We present lower bounds on the number of augmented data points required for non-zero margin, and show that commonly used DA techniques may only introduce significant margin after adding exponentially many points to the data set.
SysML: The New Frontier of Machine Learning Systems
May 01, 2019Machine learning (ML) techniques are enjoying rapidly increasing adoption. However, designing and implementing the systems that support ML models in real-world deployments remains a significant obstacle, in large part due to the radically different development and deployment profile of modern ML methods, and the range of practical concerns that come with broader adoption. We propose to foster a new systems machine learning research community at the intersection of the traditional systems and ML communities, focused on topics such as hardware systems for ML, software systems for ML, and ML optimized for metrics beyond predictive accuracy. To do this, we describe a new conference, SysML, that explicitly targets research at the intersection of systems and machine learning with a program committee split evenly between experts in systems and ML, and an explicit focus on topics at the intersection of the two.
ErasureHead: Distributed Gradient Descent without Delays Using Approximate Gradient Coding
Jan 28, 2019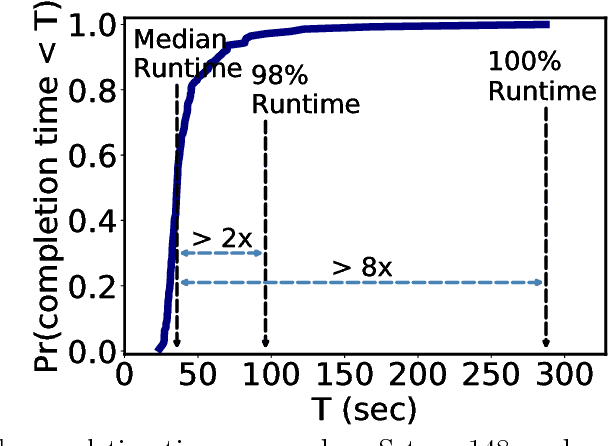

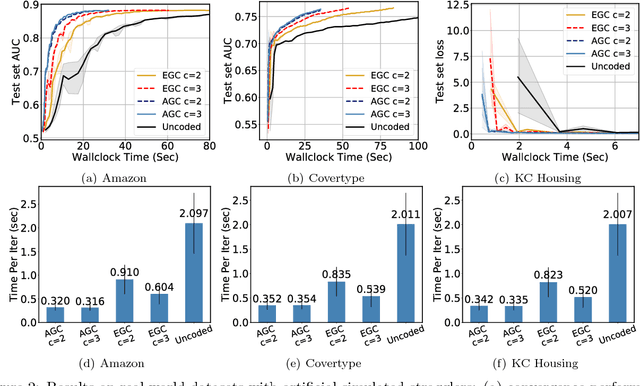
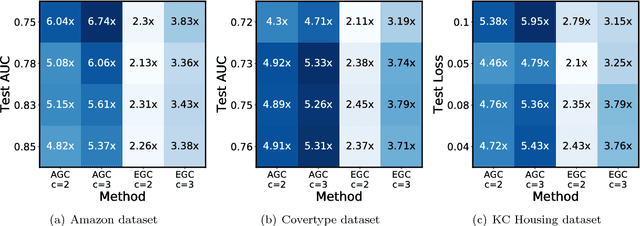
We present ErasureHead, a new approach for distributed gradient descent (GD) that mitigates system delays by employing approximate gradient coding. Gradient coded distributed GD uses redundancy to exactly recover the gradient at each iteration from a subset of compute nodes. ErasureHead instead uses approximate gradient codes to recover an inexact gradient at each iteration, but with higher delay tolerance. Unlike prior work on gradient coding, we provide a performance analysis that combines both delay and convergence guarantees. We establish that down to a small noise floor, ErasureHead converges as quickly as distributed GD and has faster overall runtime under a probabilistic delay model. We conduct extensive experiments on real world datasets and distributed clusters and demonstrate that our method can lead to significant speedups over both standard and gradient coded GD.
A Geometric Perspective on the Transferability of Adversarial Directions
Nov 08, 2018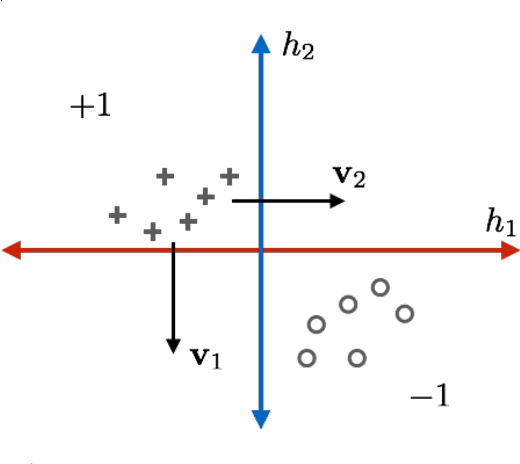
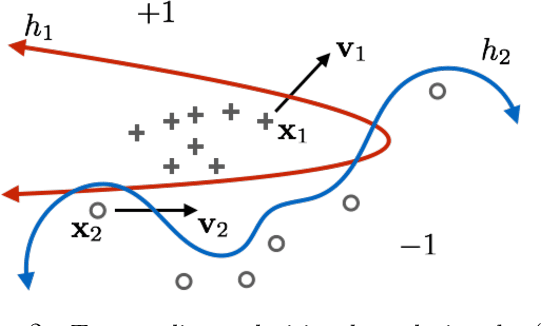
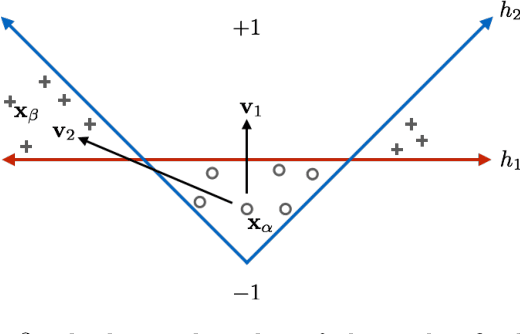
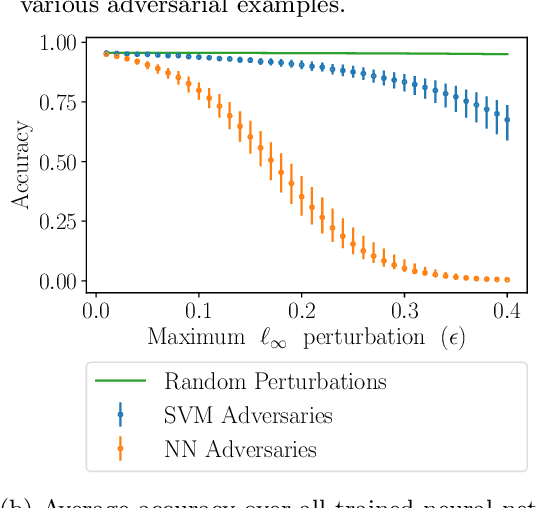
State-of-the-art machine learning models frequently misclassify inputs that have been perturbed in an adversarial manner. Adversarial perturbations generated for a given input and a specific classifier often seem to be effective on other inputs and even different classifiers. In other words, adversarial perturbations seem to transfer between different inputs, models, and even different neural network architectures. In this work, we show that in the context of linear classifiers and two-layer ReLU networks, there provably exist directions that give rise to adversarial perturbations for many classifiers and data points simultaneously. We show that these "transferable adversarial directions" are guaranteed to exist for linear separators of a given set, and will exist with high probability for linear classifiers trained on independent sets drawn from the same distribution. We extend our results to large classes of two-layer ReLU networks. We further show that adversarial directions for ReLU networks transfer to linear classifiers while the reverse need not hold, suggesting that adversarial perturbations for more complex models are more likely to transfer to other classifiers. We validate our findings empirically, even for deeper ReLU networks.
ATOMO: Communication-efficient Learning via Atomic Sparsification
Jun 24, 2018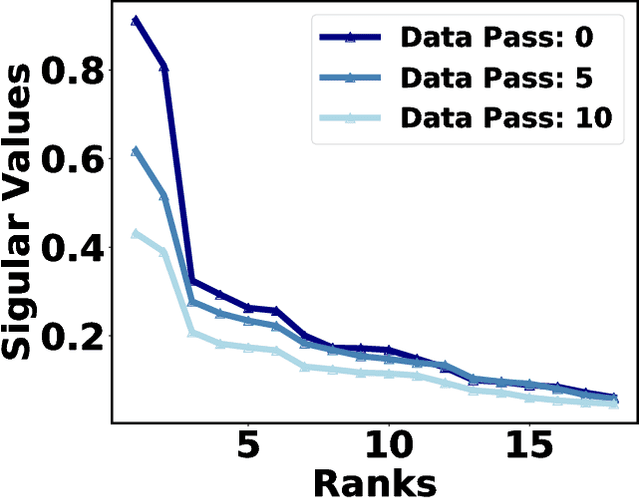

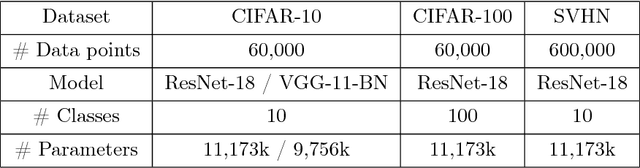
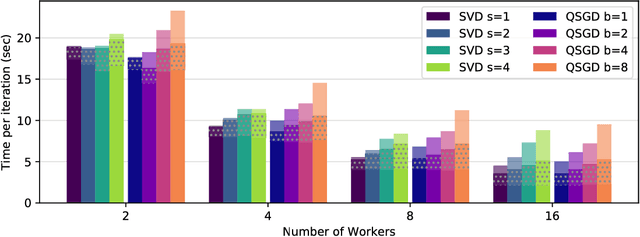
Distributed model training suffers from communication overheads due to frequent gradient updates transmitted between compute nodes. To mitigate these overheads, several studies propose the use of sparsified stochastic gradients. We argue that these are facets of a general sparsification method that can operate on any possible atomic decomposition. Notable examples include element-wise, singular value, and Fourier decompositions. We present ATOMO, a general framework for atomic sparsification of stochastic gradients. Given a gradient, an atomic decomposition, and a sparsity budget, ATOMO gives a random unbiased sparsification of the atoms minimizing variance. We show that methods such as QSGD and TernGrad are special cases of ATOMO and show that sparsifiying gradients in their singular value decomposition (SVD), rather than the coordinate-wise one, can lead to significantly faster distributed training.
DRACO: Byzantine-resilient Distributed Training via Redundant Gradients
Jun 22, 2018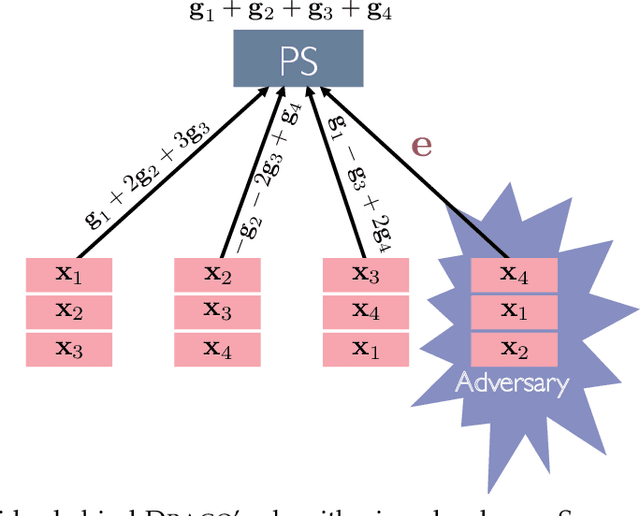
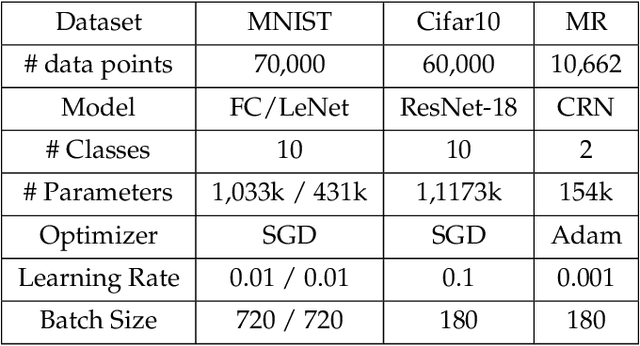
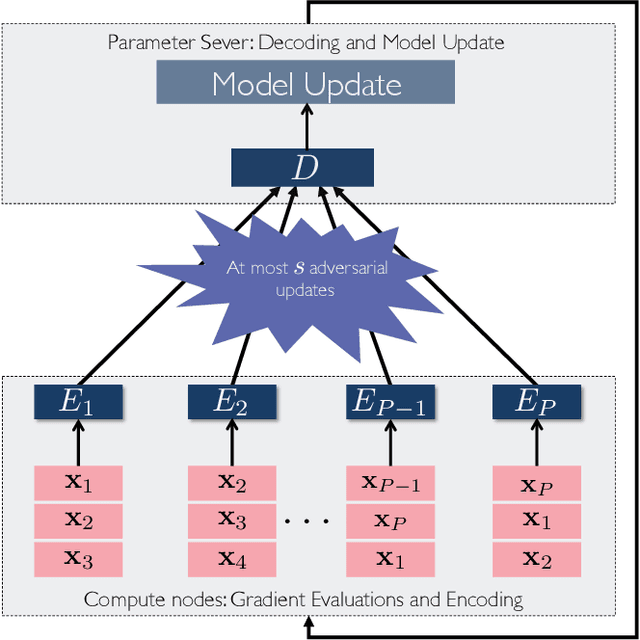
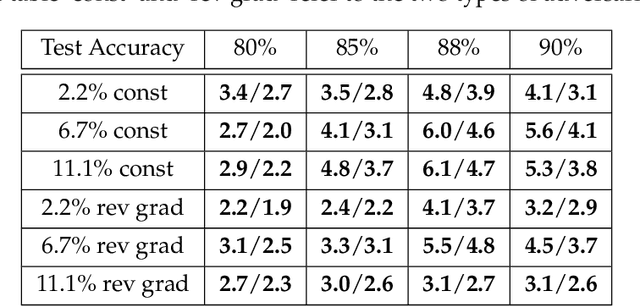
Distributed model training is vulnerable to byzantine system failures and adversarial compute nodes, i.e., nodes that use malicious updates to corrupt the global model stored at a parameter server (PS). To guarantee some form of robustness, recent work suggests using variants of the geometric median as an aggregation rule, in place of gradient averaging. Unfortunately, median-based rules can incur a prohibitive computational overhead in large-scale settings, and their convergence guarantees often require strong assumptions. In this work, we present DRACO, a scalable framework for robust distributed training that uses ideas from coding theory. In DRACO, each compute node evaluates redundant gradients that are used by the parameter server to eliminate the effects of adversarial updates. DRACO comes with problem-independent robustness guarantees, and the model that it trains is identical to the one trained in the adversary-free setup. We provide extensive experiments on real datasets and distributed setups across a variety of large-scale models, where we show that DRACO is several times, to orders of magnitude faster than median-based approaches.
The Effect of Network Width on the Performance of Large-batch Training
Jun 11, 2018



Distributed implementations of mini-batch stochastic gradient descent (SGD) suffer from communication overheads, attributed to the high frequency of gradient updates inherent in small-batch training. Training with large batches can reduce these overheads; however, large batches can affect the convergence properties and generalization performance of SGD. In this work, we take a first step towards analyzing how the structure (width and depth) of a neural network affects the performance of large-batch training. We present new theoretical results which suggest that--for a fixed number of parameters--wider networks are more amenable to fast large-batch training compared to deeper ones. We provide extensive experiments on residual and fully-connected neural networks which suggest that wider networks can be trained using larger batches without incurring a convergence slow-down, unlike their deeper variants.
Gradient Coding via the Stochastic Block Model
May 25, 2018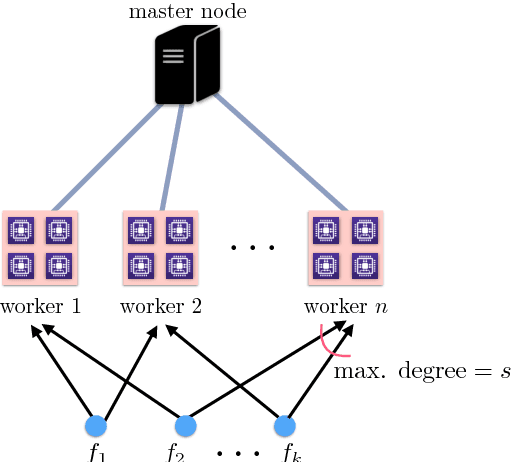
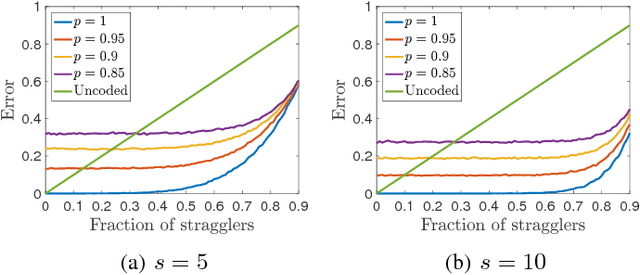
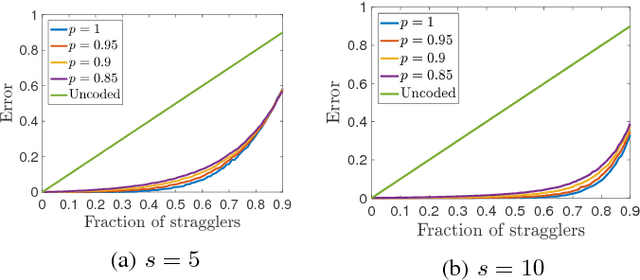
Gradient descent and its many variants, including mini-batch stochastic gradient descent, form the algorithmic foundation of modern large-scale machine learning. Due to the size and scale of modern data, gradient computations are often distributed across multiple compute nodes. Unfortunately, such distributed implementations can face significant delays caused by straggler nodes, i.e., nodes that are much slower than average. Gradient coding is a new technique for mitigating the effect of stragglers via algorithmic redundancy. While effective, previously proposed gradient codes can be computationally expensive to construct, inaccurate, or susceptible to adversarial stragglers. In this work, we present the stochastic block code (SBC), a gradient code based on the stochastic block model. We show that SBCs are efficient, accurate, and that under certain settings, adversarial straggler selection becomes as hard as detecting a community structure in the multiple community, block stochastic graph model.
Speeding Up Distributed Machine Learning Using Codes
Jan 29, 2018
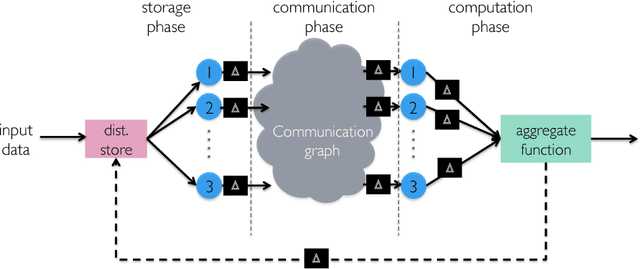
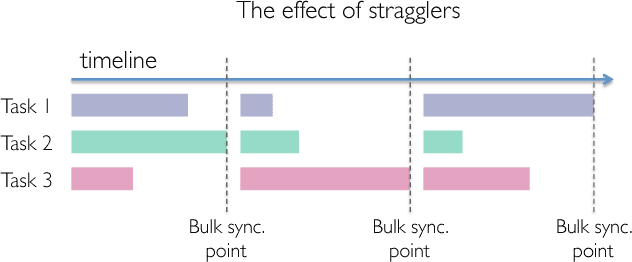
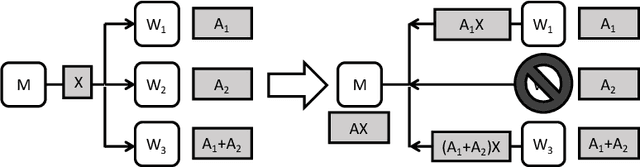
Codes are widely used in many engineering applications to offer robustness against noise. In large-scale systems there are several types of noise that can affect the performance of distributed machine learning algorithms -- straggler nodes, system failures, or communication bottlenecks -- but there has been little interaction cutting across codes, machine learning, and distributed systems. In this work, we provide theoretical insights on how coded solutions can achieve significant gains compared to uncoded ones. We focus on two of the most basic building blocks of distributed learning algorithms: matrix multiplication and data shuffling. For matrix multiplication, we use codes to alleviate the effect of stragglers, and show that if the number of homogeneous workers is $n$, and the runtime of each subtask has an exponential tail, coded computation can speed up distributed matrix multiplication by a factor of $\log n$. For data shuffling, we use codes to reduce communication bottlenecks, exploiting the excess in storage. We show that when a constant fraction $\alpha$ of the data matrix can be cached at each worker, and $n$ is the number of workers, \emph{coded shuffling} reduces the communication cost by a factor of $(\alpha + \frac{1}{n})\gamma(n)$ compared to uncoded shuffling, where $\gamma(n)$ is the ratio of the cost of unicasting $n$ messages to $n$ users to multicasting a common message (of the same size) to $n$ users. For instance, $\gamma(n) \simeq n$ if multicasting a message to $n$ users is as cheap as unicasting a message to one user. We also provide experiment results, corroborating our theoretical gains of the coded algorithms.