 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeError-Bounded Correction of Noisy Labels
Nov 19, 2020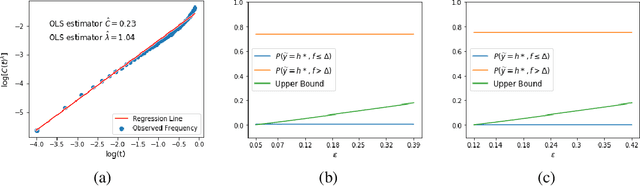
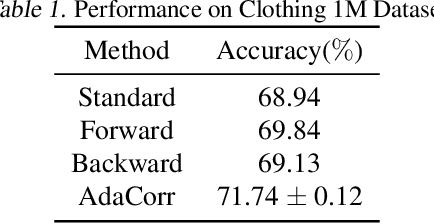
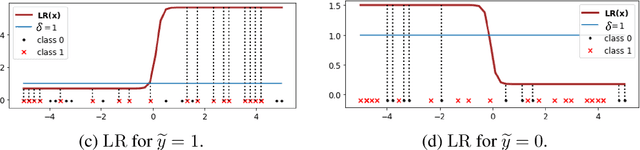
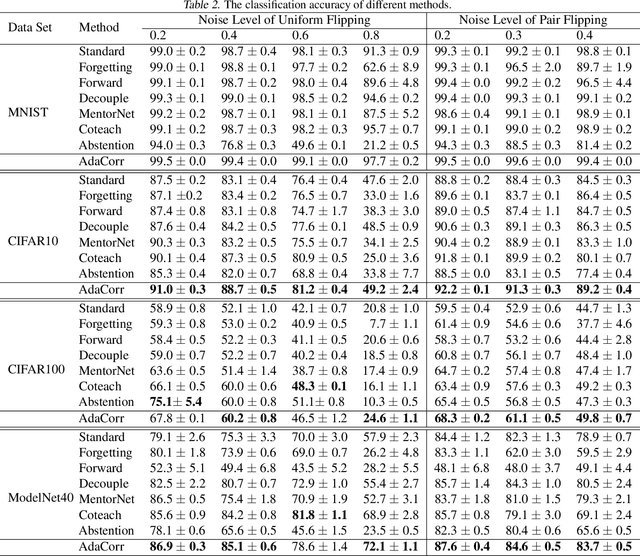
To collect large scale annotated data, it is inevitable to introduce label noise, i.e., incorrect class labels. To be robust against label noise, many successful methods rely on the noisy classifiers (i.e., models trained on the noisy training data) to determine whether a label is trustworthy. However, it remains unknown why this heuristic works well in practice. In this paper, we provide the first theoretical explanation for these methods. We prove that the prediction of a noisy classifier can indeed be a good indicator of whether the label of a training data is clean. Based on the theoretical result, we propose a novel algorithm that corrects the labels based on the noisy classifier prediction. The corrected labels are consistent with the true Bayesian optimal classifier with high probability. We incorporate our label correction algorithm into the training of deep neural networks and train models that achieve superior testing performance on multiple public datasets.
Maximum-Entropy Adversarial Data Augmentation for Improved Generalization and Robustness
Oct 15, 2020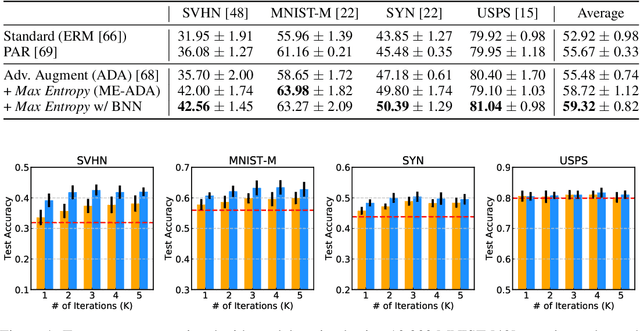
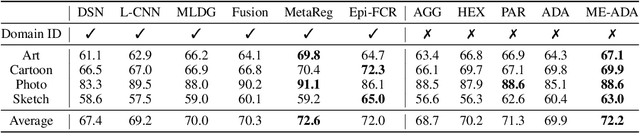
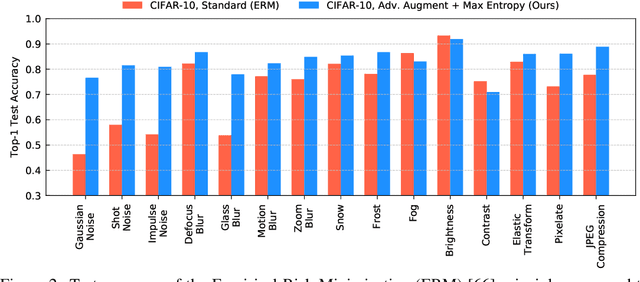
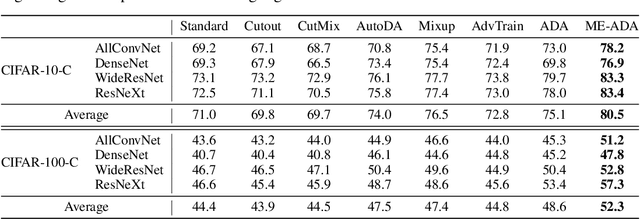
Adversarial data augmentation has shown promise for training robust deep neural networks against unforeseen data shifts or corruptions. However, it is difficult to define heuristics to generate effective fictitious target distributions containing "hard" adversarial perturbations that are largely different from the source distribution. In this paper, we propose a novel and effective regularization term for adversarial data augmentation. We theoretically derive it from the information bottleneck principle, which results in a maximum-entropy formulation. Intuitively, this regularization term encourages perturbing the underlying source distribution to enlarge predictive uncertainty of the current model, so that the generated "hard" adversarial perturbations can improve the model robustness during training. Experimental results on three standard benchmarks demonstrate that our method consistently outperforms the existing state of the art by a statistically significant margin.
Deep Learning based NAS Score and Fibrosis Stage Prediction from CT and Pathology Data
Sep 22, 2020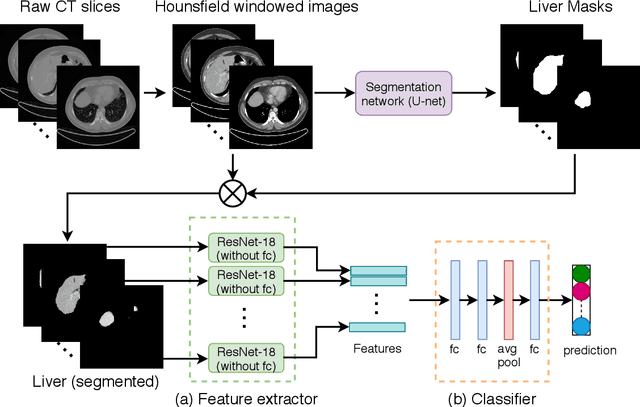
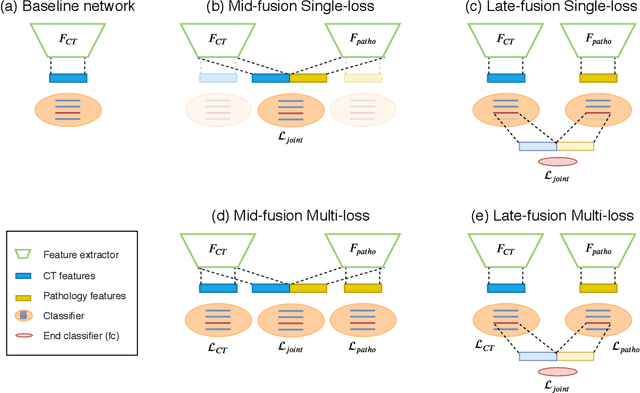
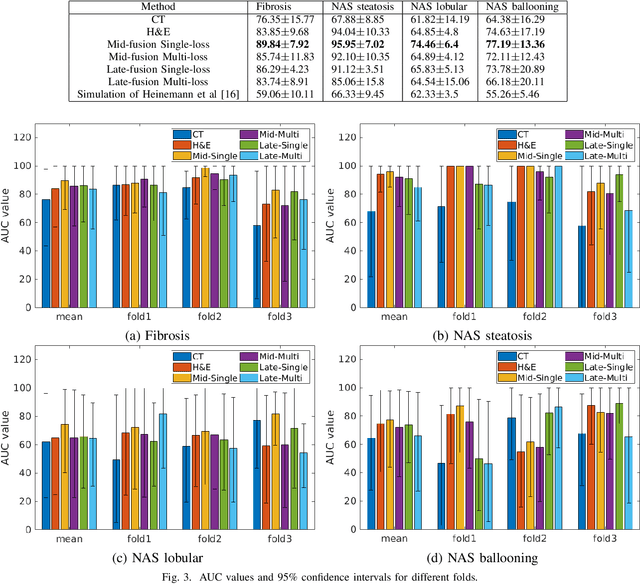

Non-Alcoholic Fatty Liver Disease (NAFLD) is becoming increasingly prevalent in the world population. Without diagnosis at the right time, NAFLD can lead to non-alcoholic steatohepatitis (NASH) and subsequent liver damage. The diagnosis and treatment of NAFLD depend on the NAFLD activity score (NAS) and the liver fibrosis stage, which are usually evaluated from liver biopsies by pathologists. In this work, we propose a novel method to automatically predict NAS score and fibrosis stage from CT data that is non-invasive and inexpensive to obtain compared with liver biopsy. We also present a method to combine the information from CT and H\&E stained pathology data to improve the performance of NAS score and fibrosis stage prediction, when both types of data are available. This is of great value to assist the pathologists in computer-aided diagnosis process. Experiments on a 30-patient dataset illustrate the effectiveness of our method.
Oriented Object Detection in Aerial Images with Box Boundary-Aware Vectors
Aug 29, 2020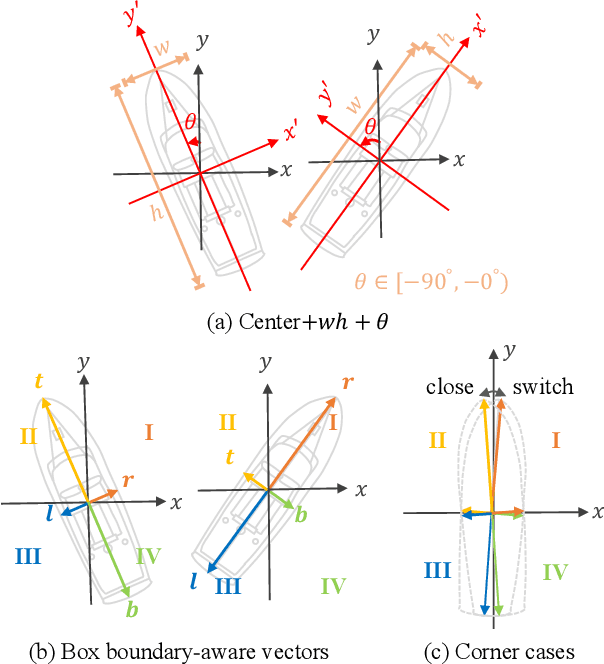
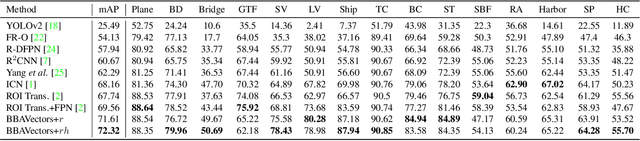
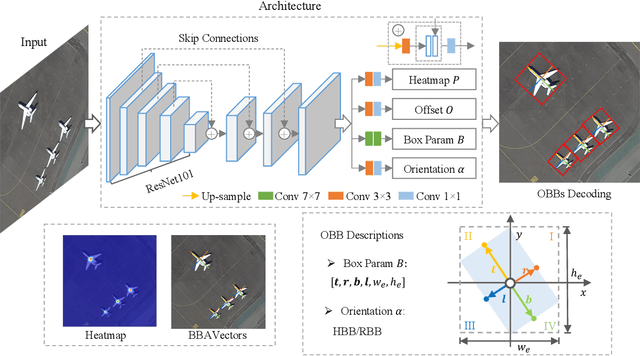
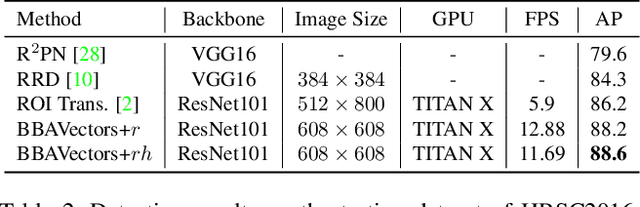
Oriented object detection in aerial images is a challenging task as the objects in aerial images are displayed in arbitrary directions and are usually densely packed. Current oriented object detection methods mainly rely on two-stage anchor-based detectors. However, the anchor-based detectors typically suffer from a severe imbalance issue between the positive and negative anchor boxes. To address this issue, in this work we extend the horizontal keypoint-based object detector to the oriented object detection task. In particular, we first detect the center keypoints of the objects, based on which we then regress the box boundary-aware vectors (BBAVectors) to capture the oriented bounding boxes. The box boundary-aware vectors are distributed in the four quadrants of a Cartesian coordinate system for all arbitrarily oriented objects. To relieve the difficulty of learning the vectors in the corner cases, we further classify the oriented bounding boxes into horizontal and rotational bounding boxes. In the experiment, we show that learning the box boundary-aware vectors is superior to directly predicting the width, height, and angle of an oriented bounding box, as adopted in the baseline method. Besides, the proposed method competes favorably with state-of-the-art methods. Code is available at https://github.com/yijingru/BBAVectors-Oriented-Object-Detection.
Measure Anatomical Thickness from Cardiac MRI with Deep Neural Networks
Aug 25, 2020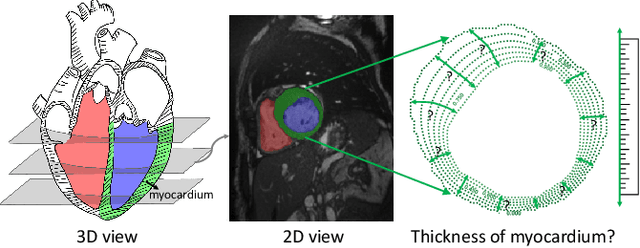
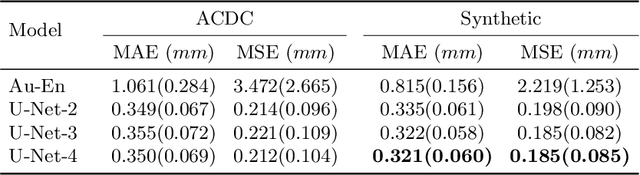
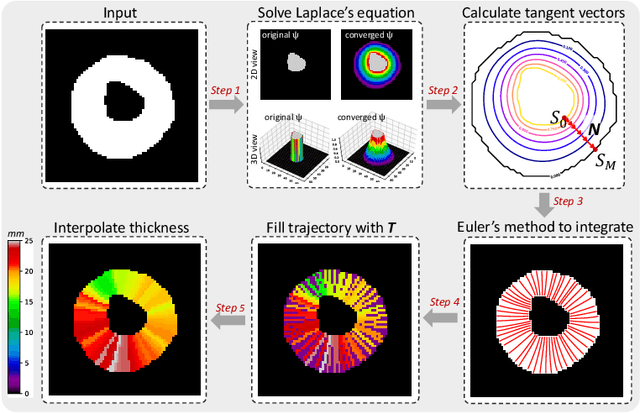
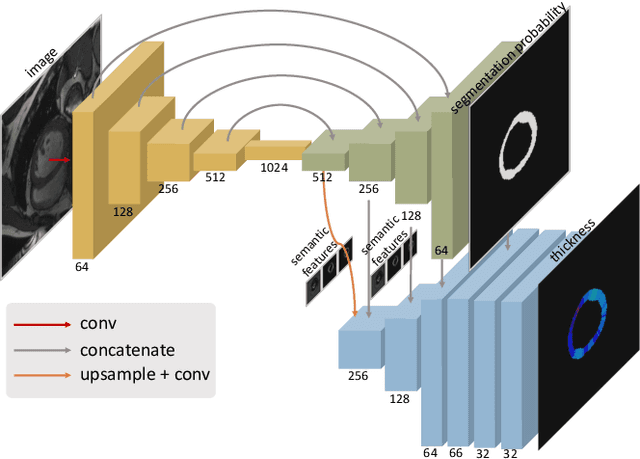
Accurate estimation of shape thickness from medical images is crucial in clinical applications. For example, the thickness of myocardium is one of the key to cardiac disease diagnosis. While mathematical models are available to obtain accurate dense thickness estimation, they suffer from heavy computational overhead due to iterative solvers. To this end, we propose novel methods for dense thickness estimation, including a fast solver that estimates thickness from binary annular shapes and an end-to-end network that estimates thickness directly from raw cardiac images.We test the proposed models on three cardiac datasets and one synthetic dataset, achieving impressive results and generalizability on all. Thickness estimation is performed without iterative solvers or manual correction, which is 100 times faster than the mathematical model. We also analyze thickness patterns on different cardiac pathologies with a standard clinical model and the results demonstrate the potential clinical value of our method for thickness based cardiac disease diagnosis.
OnlineAugment: Online Data Augmentation with Less Domain Knowledge
Aug 22, 2020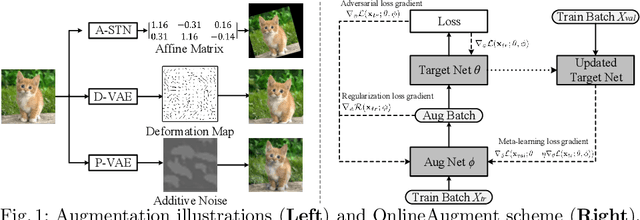
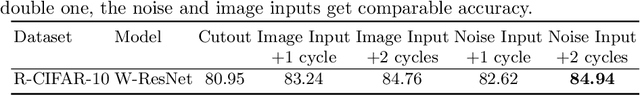
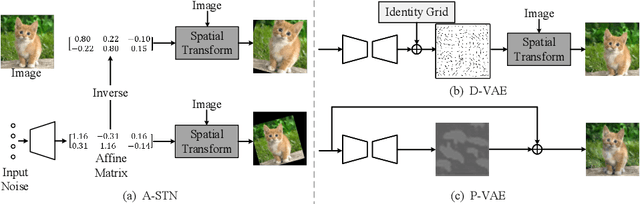

Data augmentation is one of the most important tools in training modern deep neural networks. Recently, great advances have been made in searching for optimal augmentation policies in the image classification domain. However, two key points related to data augmentation remain uncovered by the current methods. First is that most if not all modern augmentation search methods are offline and learning policies are isolated from their usage. The learned policies are mostly constant throughout the training process and are not adapted to the current training model state. Second, the policies rely on class-preserving image processing functions. Hence applying current offline methods to new tasks may require domain knowledge to specify such kind of operations. In this work, we offer an orthogonal online data augmentation scheme together with three new augmentation networks, co-trained with the target learning task. It is both more efficient, in the sense that it does not require expensive offline training when entering a new domain, and more adaptive as it adapts to the learner state. Our augmentation networks require less domain knowledge and are easily applicable to new tasks. Extensive experiments demonstrate that the proposed scheme alone performs on par with the state-of-the-art offline data augmentation methods, as well as improving upon the state-of-the-art in combination with those methods. Code is available at https://github.com/zhiqiangdon/online-augment .
Enhanced MRI Reconstruction Network using Neural Architecture Search
Aug 19, 2020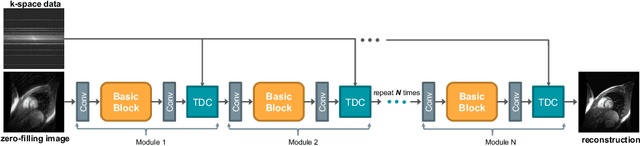



The accurate reconstruction of under-sampled magnetic resonance imaging (MRI) data using modern deep learning technology, requires significant effort to design the necessary complex neural network architectures. The cascaded network architecture for MRI reconstruction has been widely used, while it suffers from the "vanishing gradient" problem when the network becomes deep. In addition, homogeneous architecture degrades the representation capacity of the network. In this work, we present an enhanced MRI reconstruction network using a residual in residual basic block. For each cell in the basic block, we use the differentiable neural architecture search (NAS) technique to automatically choose the optimal operation among eight variants of the dense block. This new heterogeneous network is evaluated on two publicly available datasets and outperforms all current state-of-the-art methods, which demonstrates the effectiveness of our proposed method.
PC-U Net: Learning to Jointly Reconstruct and Segment the Cardiac Walls in 3D from CT Data
Aug 18, 2020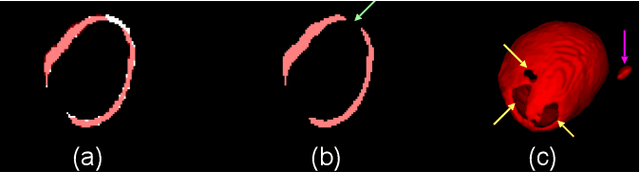
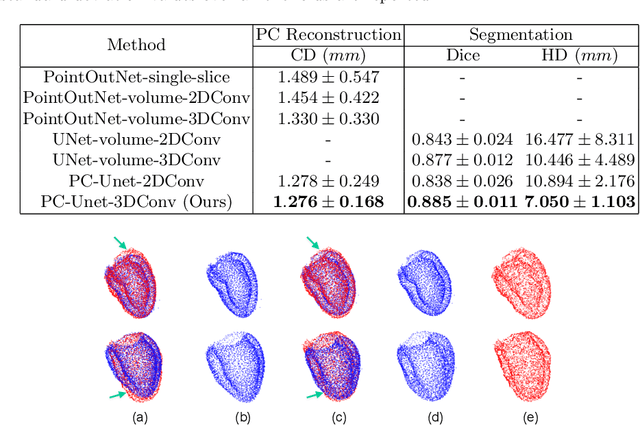
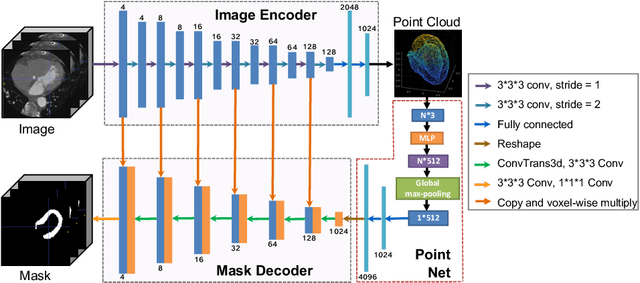

The 3D volumetric shape of the heart's left ventricle (LV) myocardium (MYO) wall provides important information for diagnosis of cardiac disease and invasive procedure navigation. Many cardiac image segmentation methods have relied on detection of region-of-interest as a pre-requisite for shape segmentation and modeling. With segmentation results, a 3D surface mesh and a corresponding point cloud of the segmented cardiac volume can be reconstructed for further analyses. Although state-of-the-art methods (e.g., U-Net) have achieved decent performance on cardiac image segmentation in terms of accuracy, these segmentation results can still suffer from imaging artifacts and noise, which will lead to inaccurate shape modeling results. In this paper, we propose a PC-U net that jointly reconstructs the point cloud of the LV MYO wall directly from volumes of 2D CT slices and generates its segmentation masks from the predicted 3D point cloud. Extensive experimental results show that by incorporating a shape prior from the point cloud, the segmentation masks are more accurate than the state-of-the-art U-Net results in terms of Dice's coefficient and Hausdorff distance.The proposed joint learning framework of our PC-U net is beneficial for automatic cardiac image analysis tasks because it can obtain simultaneously the 3D shape and segmentation of the LV MYO walls.
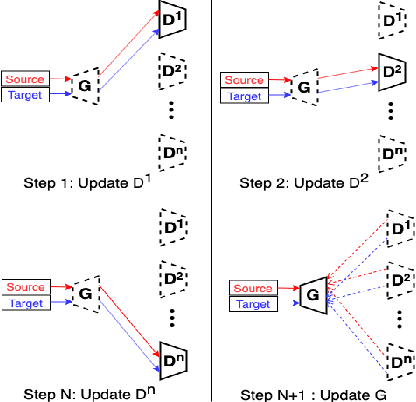
Learn distributed GAN with Temporary Discriminators
Jul 17, 2020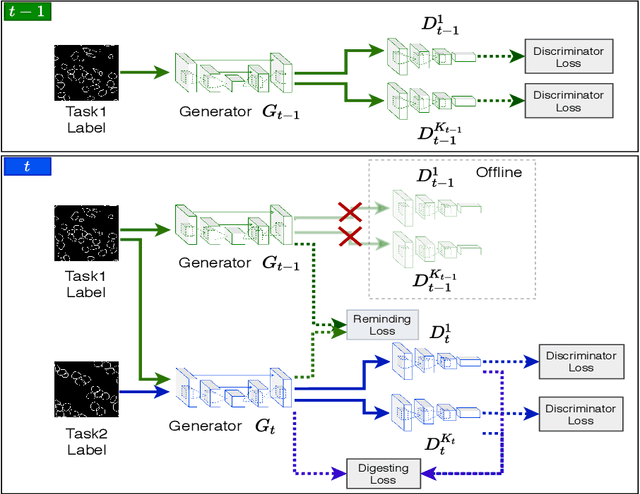
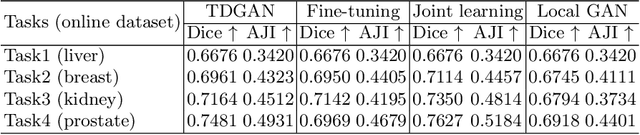

In this work, we propose a method for training distributed GAN with sequential temporary discriminators. Our proposed method tackles the challenge of training GAN in the federated learning manner: How to update the generator with a flow of temporary discriminators? We apply our proposed method to learn a self-adaptive generator with a series of local discriminators from multiple data centers. We show our design of loss function indeed learns the correct distribution with provable guarantees. The empirical experiments show that our approach is capable of generating synthetic data which is practical for real-world applications such as training a segmentation model.
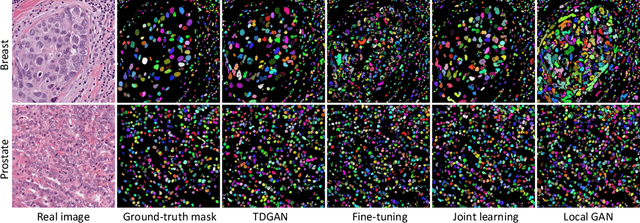
Synthetic Learning: Learn From Distributed Asynchronized Discriminator GAN Without Sharing Medical Image Data
Jun 14, 2020

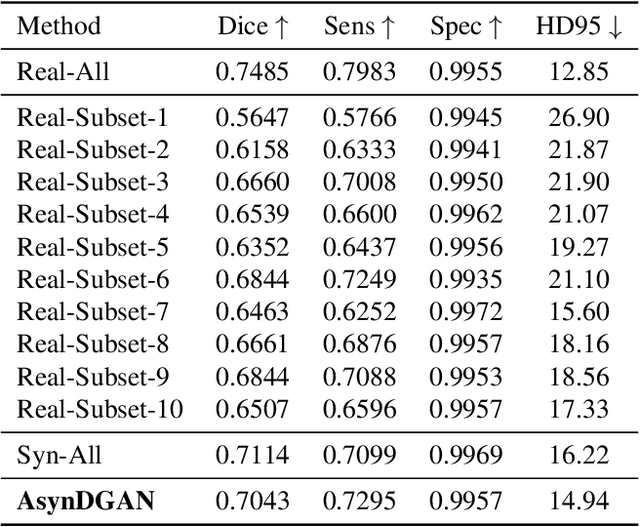
In this paper, we propose a data privacy-preserving and communication efficient distributed GAN learning framework named Distributed Asynchronized Discriminator GAN (AsynDGAN). Our proposed framework aims to train a central generator learns from distributed discriminator, and use the generated synthetic image solely to train the segmentation model.We validate the proposed framework on the application of health entities learning problem which is known to be privacy sensitive. Our experiments show that our approach: 1) could learn the real image's distribution from multiple datasets without sharing the patient's raw data. 2) is more efficient and requires lower bandwidth than other distributed deep learning methods. 3) achieves higher performance compared to the model trained by one real dataset, and almost the same performance compared to the model trained by all real datasets. 4) has provable guarantees that the generator could learn the distributed distribution in an all important fashion thus is unbiased.