 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Zero and Few-shot Knowledge-seeking Turn Detection in Task-orientated Dialogue Systems
Sep 18, 2021
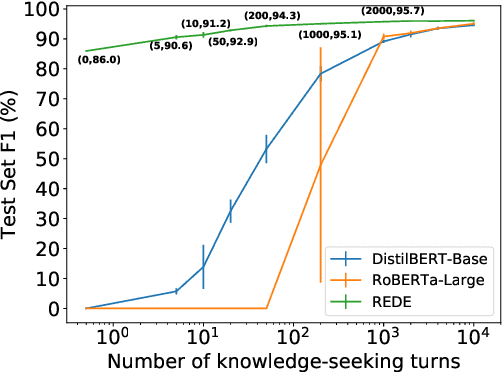
Most prior work on task-oriented dialogue systems is restricted to supporting domain APIs. However, users may have requests that are out of the scope of these APIs. This work focuses on identifying such user requests. Existing methods for this task mainly rely on fine-tuning pre-trained models on large annotated data. We propose a novel method, REDE, based on adaptive representation learning and density estimation. REDE can be applied to zero-shot cases, and quickly learns a high-performing detector with only a few shots by updating less than 3K parameters. We demonstrate REDE's competitive performance on DSTC9 data and our newly collected test set.
Can I Be of Further Assistance? Using Unstructured Knowledge Access to Improve Task-oriented Conversational Modeling
Jun 16, 2021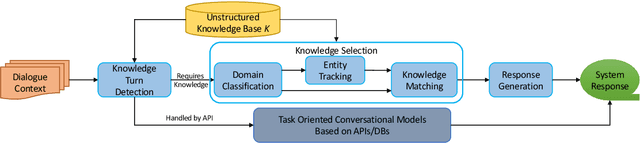

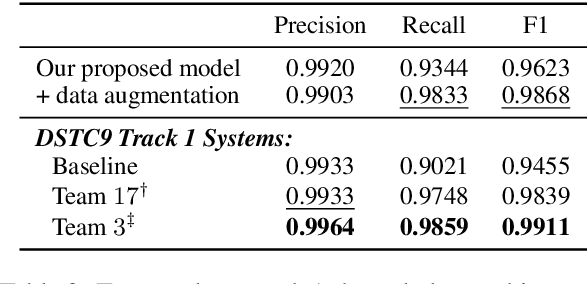
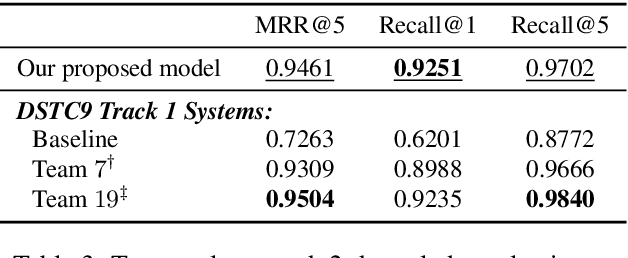
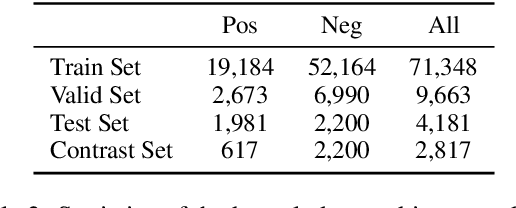
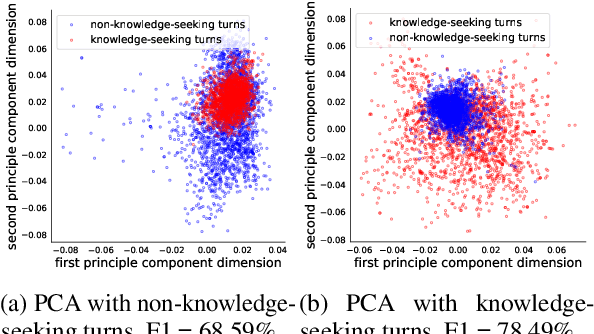
Most prior work on task-oriented dialogue systems are restricted to limited coverage of domain APIs. However, users oftentimes have requests that are out of the scope of these APIs. This work focuses on responding to these beyond-API-coverage user turns by incorporating external, unstructured knowledge sources. Our approach works in a pipelined manner with knowledge-seeking turn detection, knowledge selection, and response generation in sequence. We introduce novel data augmentation methods for the first two steps and demonstrate that the use of information extracted from dialogue context improves the knowledge selection and end-to-end performances. Through experiments, we achieve state-of-the-art performance for both automatic and human evaluation metrics on the DSTC9 Track 1 benchmark dataset, validating the effectiveness of our contributions.
Generative Conversational Networks
Jun 15, 2021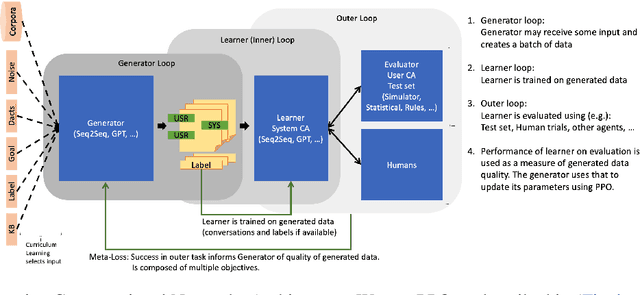
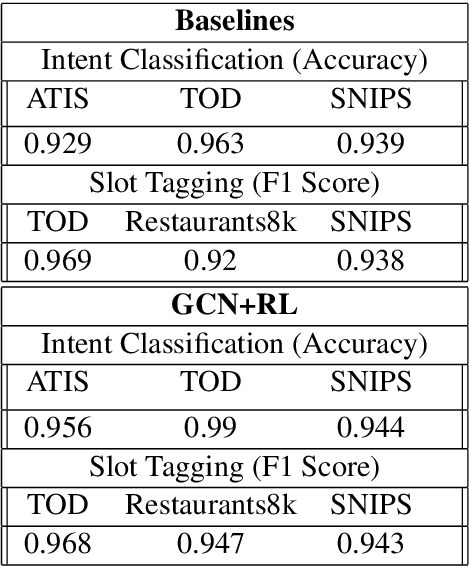
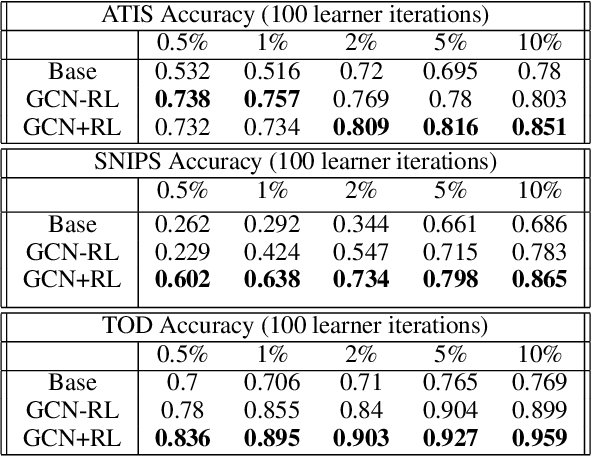
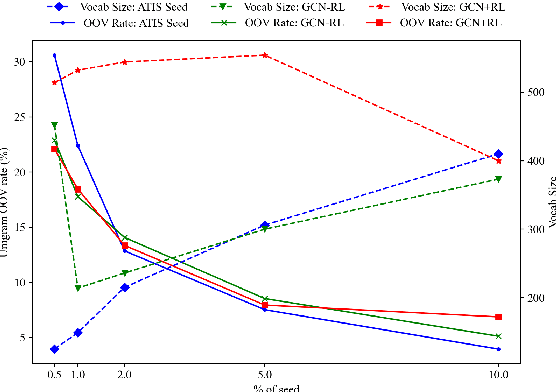
Inspired by recent work in meta-learning and generative teaching networks, we propose a framework called Generative Conversational Networks, in which conversational agents learn to generate their own labelled training data (given some seed data) and then train themselves from that data to perform a given task. We use reinforcement learning to optimize the data generation process where the reward signal is the agent's performance on the task. The task can be any language-related task, from intent detection to full task-oriented conversations. In this work, we show that our approach is able to generalise from seed data and performs well in limited data and limited computation settings, with significant gains for intent detection and slot tagging across multiple datasets: ATIS, TOD, SNIPS, and Restaurants8k. We show an average improvement of 35% in intent detection and 21% in slot tagging over a baseline model trained from the seed data. We also conduct an analysis of the novelty of the generated data and provide generated examples for intent detection, slot tagging, and non-goal oriented conversations.
Go Beyond Plain Fine-tuning: Improving Pretrained Models for Social Commonsense
May 12, 2021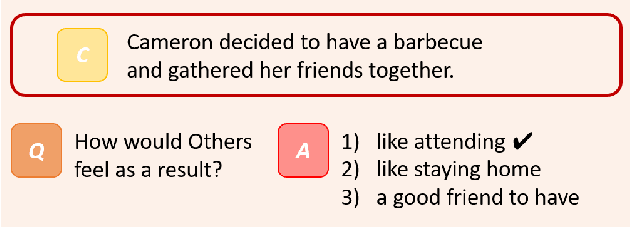
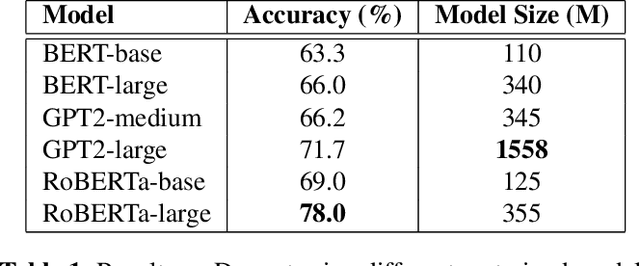
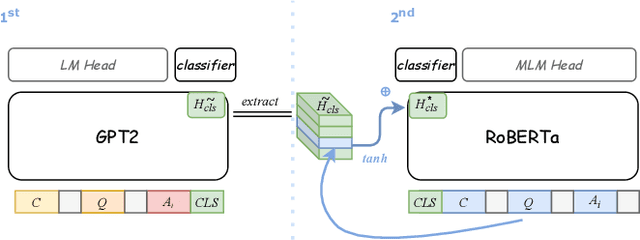
Pretrained language models have demonstrated outstanding performance in many NLP tasks recently. However, their social intelligence, which requires commonsense reasoning about the current situation and mental states of others, is still developing. Towards improving language models' social intelligence, we focus on the Social IQA dataset, a task requiring social and emotional commonsense reasoning. Building on top of the pretrained RoBERTa and GPT2 models, we propose several architecture variations and extensions, as well as leveraging external commonsense corpora, to optimize the model for Social IQA. Our proposed system achieves competitive results as those top-ranking models on the leaderboard. This work demonstrates the strengths of pretrained language models, and provides viable ways to improve their performance for a particular task.
Incorporating Commonsense Knowledge Graph in Pretrained Models for Social Commonsense Tasks
May 12, 2021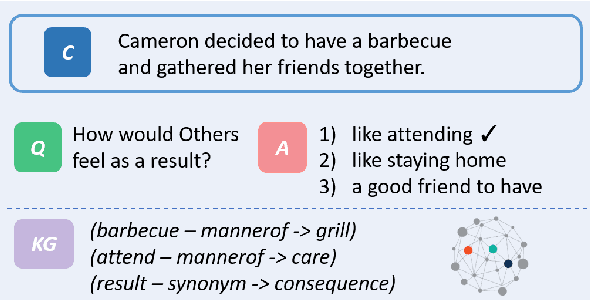
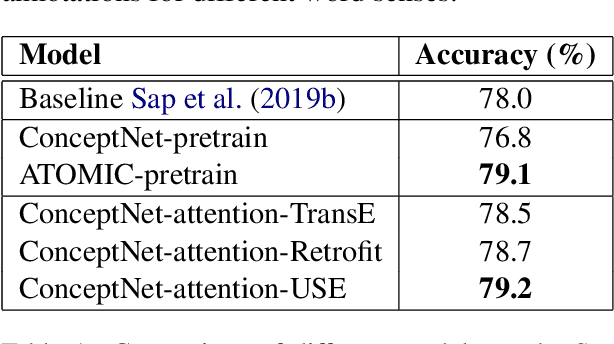
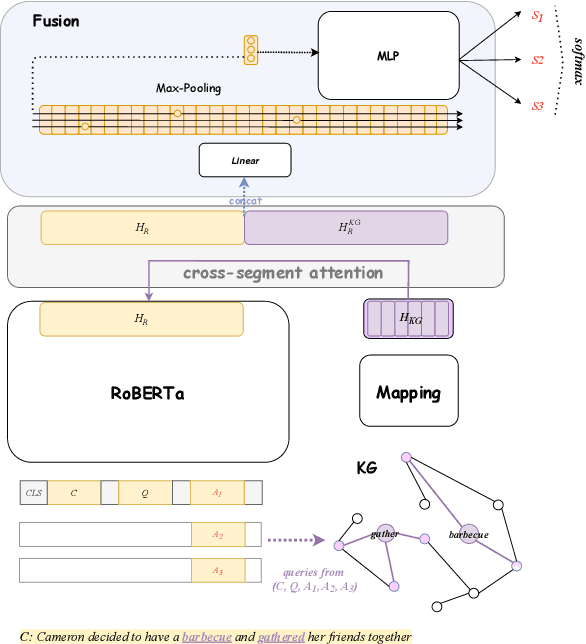
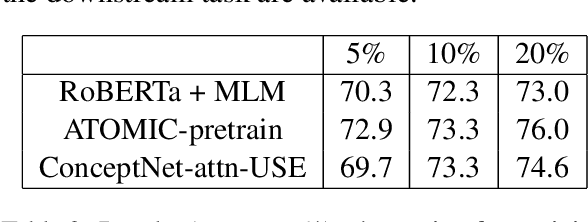
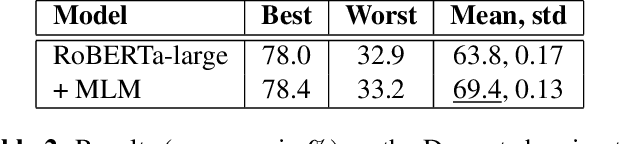
Pretrained language models have excelled at many NLP tasks recently; however, their social intelligence is still unsatisfactory. To enable this, machines need to have a more general understanding of our complicated world and develop the ability to perform commonsense reasoning besides fitting the specific downstream tasks. External commonsense knowledge graphs (KGs), such as ConceptNet, provide rich information about words and their relationships. Thus, towards general commonsense learning, we propose two approaches to \emph{implicitly} and \emph{explicitly} infuse such KGs into pretrained language models. We demonstrate our proposed methods perform well on SocialIQA, a social commonsense reasoning task, in both limited and full training data regimes.
Alexa Conversations: An Extensible Data-driven Approach for Building Task-oriented Dialogue Systems
Apr 19, 2021
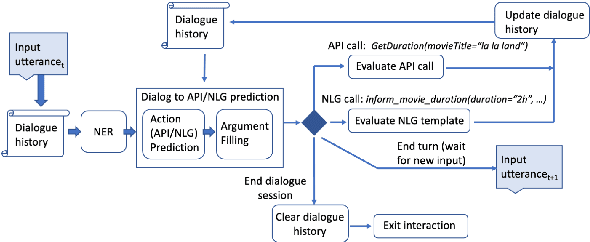

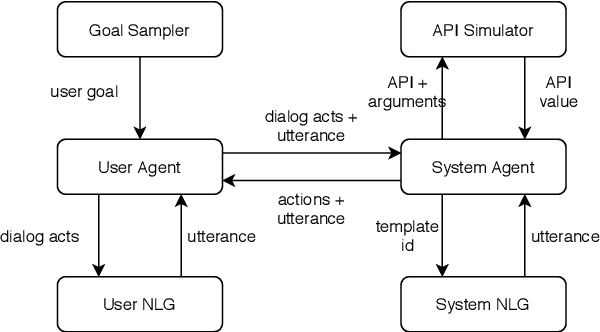
Traditional goal-oriented dialogue systems rely on various components such as natural language understanding, dialogue state tracking, policy learning and response generation. Training each component requires annotations which are hard to obtain for every new domain, limiting scalability of such systems. Similarly, rule-based dialogue systems require extensive writing and maintenance of rules and do not scale either. End-to-End dialogue systems, on the other hand, do not require module-specific annotations but need a large amount of data for training. To overcome these problems, in this demo, we present Alexa Conversations, a new approach for building goal-oriented dialogue systems that is scalable, extensible as well as data efficient. The components of this system are trained in a data-driven manner, but instead of collecting annotated conversations for training, we generate them using a novel dialogue simulator based on a few seed dialogues and specifications of APIs and entities provided by the developer. Our approach provides out-of-the-box support for natural conversational phenomena like entity sharing across turns or users changing their mind during conversation without requiring developers to provide any such dialogue flows. We exemplify our approach using a simple pizza ordering task and showcase its value in reducing the developer burden for creating a robust experience. Finally, we evaluate our system using a typical movie ticket booking task and show that the dialogue simulator is an essential component of the system that leads to over $50\%$ improvement in turn-level action signature prediction accuracy.
Beyond Domain APIs: Task-oriented Conversational Modeling with Unstructured Knowledge Access Track in DSTC9
Feb 04, 2021
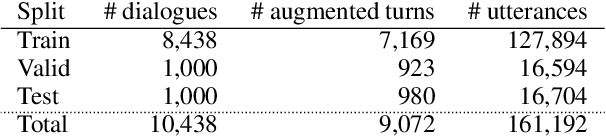
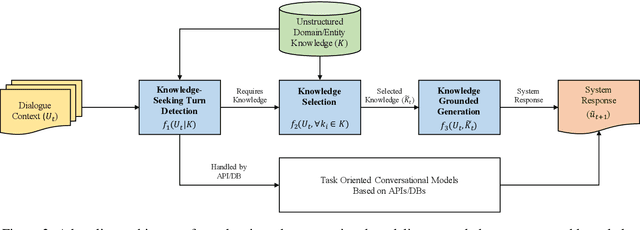

Most prior work on task-oriented dialogue systems are restricted to a limited coverage of domain APIs, while users oftentimes have domain related requests that are not covered by the APIs. This challenge track aims to expand the coverage of task-oriented dialogue systems by incorporating external unstructured knowledge sources. We define three tasks: knowledge-seeking turn detection, knowledge selection, and knowledge-grounded response generation. We introduce the data sets and the neural baseline models for three tasks. The challenge track received a total of 105 entries from 24 participating teams. In the evaluation results, the ensemble methods with different large-scale pretrained language models achieved high performances with improved knowledge selection capability and better generalization into unseen data.
Few Shot Dialogue State Tracking using Meta-learning
Jan 23, 2021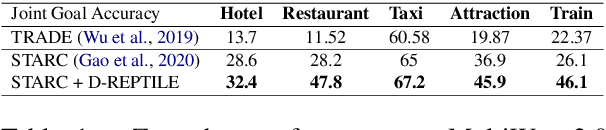
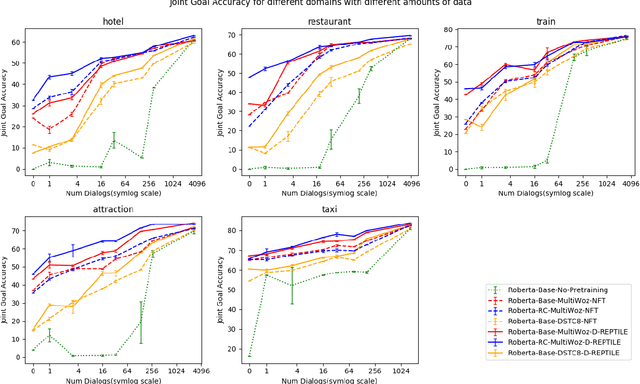
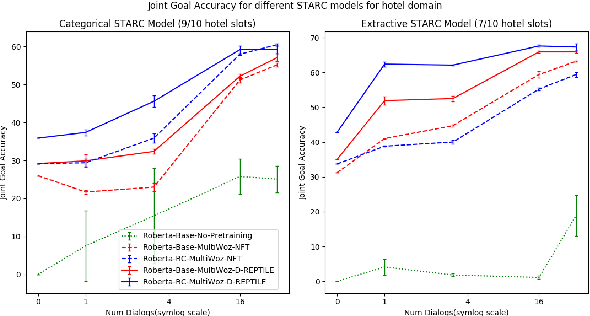
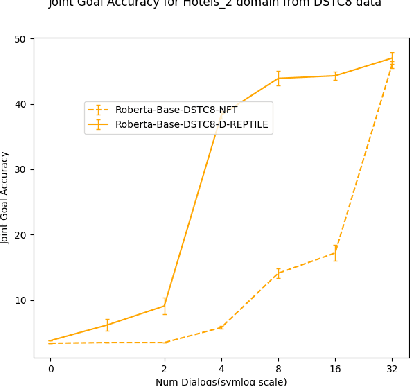
Dialogue State Tracking (DST) forms a core component of automated chatbot based systems designed for specific goals like hotel, taxi reservation, tourist information, etc. With the increasing need to deploy such systems in new domains, solving the problem of zero/few-shot DST has become necessary. There has been a rising trend for learning to transfer knowledge from resource-rich domains to unknown domains with minimal need for additional data. In this work, we explore the merits of meta-learning algorithms for this transfer and hence, propose a meta-learner D-REPTILE specific to the DST problem. With extensive experimentation, we provide clear evidence of benefits over conventional approaches across different domains, methods, base models, and datasets with significant (5-25%) improvement over the baseline in a low-data setting. Our proposed meta-learner is agnostic of the underlying model and hence any existing state-of-the-art DST system can improve its performance on unknown domains using our training strategy.
Interactive Teaching for Conversational AI
Dec 02, 2020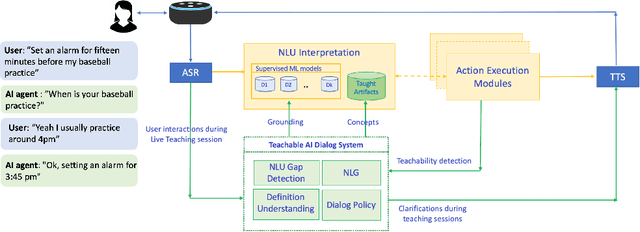
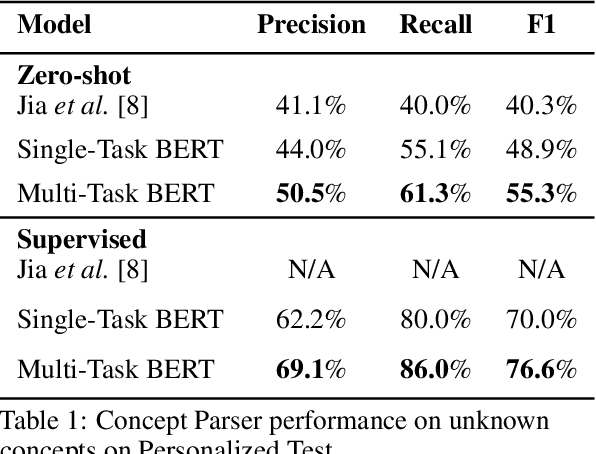
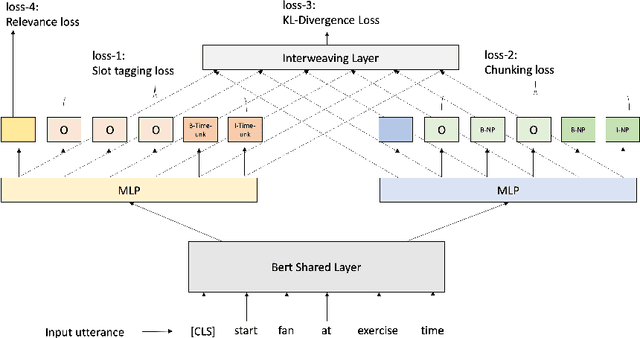
Current conversational AI systems aim to understand a set of pre-designed requests and execute related actions, which limits them to evolve naturally and adapt based on human interactions. Motivated by how children learn their first language interacting with adults, this paper describes a new Teachable AI system that is capable of learning new language nuggets called concepts, directly from end users using live interactive teaching sessions. The proposed setup uses three models to: a) Identify gaps in understanding automatically during live conversational interactions, b) Learn the respective interpretations of such unknown concepts from live interactions with users, and c) Manage a classroom sub-dialogue specifically tailored for interactive teaching sessions. We propose state-of-the-art transformer based neural architectures of models, fine-tuned on top of pre-trained models, and show accuracy improvements on the respective components. We demonstrate that this method is very promising in leading way to build more adaptive and personalized language understanding models.
Dialog Simulation with Realistic Variations for Training Goal-Oriented Conversational Systems
Nov 16, 2020
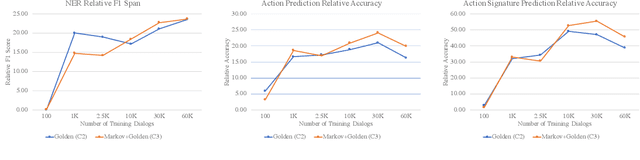
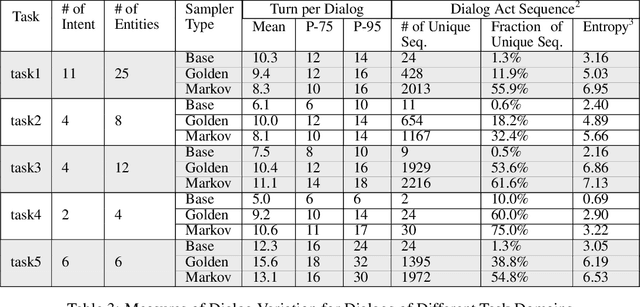
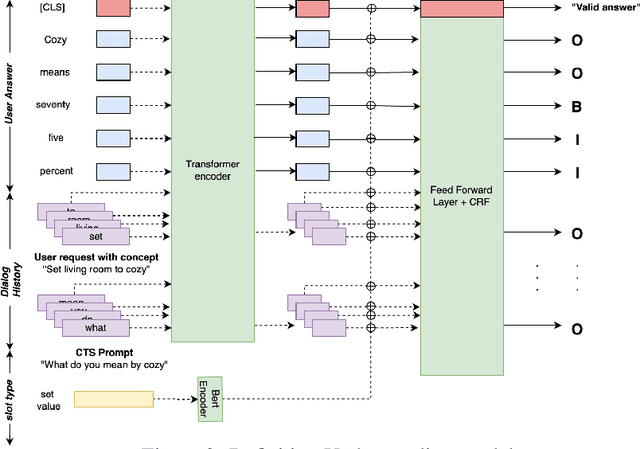
Goal-oriented dialog systems enable users to complete specific goals like requesting information about a movie or booking a ticket. Typically the dialog system pipeline contains multiple ML models, including natural language understanding, state tracking and action prediction (policy learning). These models are trained through a combination of supervised or reinforcement learning methods and therefore require collection of labeled domain specific datasets. However, collecting annotated datasets with language and dialog-flow variations is expensive, time-consuming and scales poorly due to human involvement. In this paper, we propose an approach for automatically creating a large corpus of annotated dialogs from a few thoroughly annotated sample dialogs and the dialog schema. Our approach includes a novel goal-sampling technique for sampling plausible user goals and a dialog simulation technique that uses heuristic interplay between the user and the system (Alexa), where the user tries to achieve the sampled goal. We validate our approach by generating data and training three different downstream conversational ML models. We achieve 18 ? 50% relative accuracy improvements on a held-out test set compared to a baseline dialog generation approach that only samples natural language and entity value variations from existing catalogs but does not generate any novel dialog flow variations. We also qualitatively establish that the proposed approach is better than the baseline. Moreover, several different conversational experiences have been built using this method, which enables customers to have a wide variety of conversations with Alexa.