 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAlexa Teacher Model: Pretraining and Distilling Multi-Billion-Parameter Encoders for Natural Language Understanding Systems
Jun 15, 2022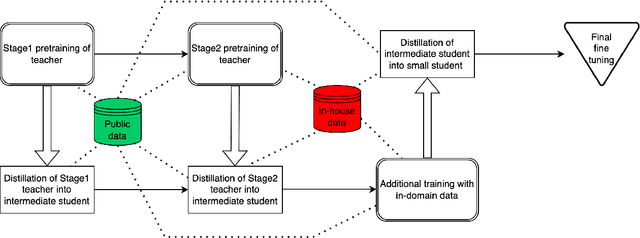
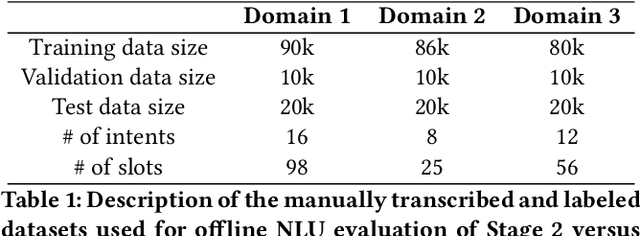
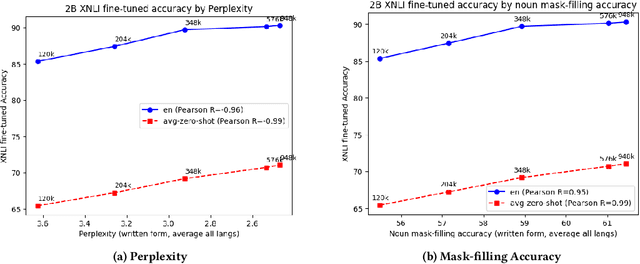
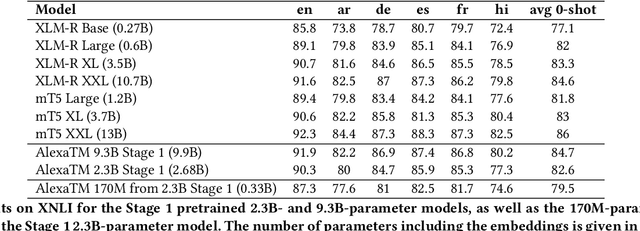
We present results from a large-scale experiment on pretraining encoders with non-embedding parameter counts ranging from 700M to 9.3B, their subsequent distillation into smaller models ranging from 17M-170M parameters, and their application to the Natural Language Understanding (NLU) component of a virtual assistant system. Though we train using 70% spoken-form data, our teacher models perform comparably to XLM-R and mT5 when evaluated on the written-form Cross-lingual Natural Language Inference (XNLI) corpus. We perform a second stage of pretraining on our teacher models using in-domain data from our system, improving error rates by 3.86% relative for intent classification and 7.01% relative for slot filling. We find that even a 170M-parameter model distilled from our Stage 2 teacher model has 2.88% better intent classification and 7.69% better slot filling error rates when compared to the 2.3B-parameter teacher trained only on public data (Stage 1), emphasizing the importance of in-domain data for pretraining. When evaluated offline using labeled NLU data, our 17M-parameter Stage 2 distilled model outperforms both XLM-R Base (85M params) and DistillBERT (42M params) by 4.23% to 6.14%, respectively. Finally, we present results from a full virtual assistant experimentation platform, where we find that models trained using our pretraining and distillation pipeline outperform models distilled from 85M-parameter teachers by 3.74%-4.91% on an automatic measurement of full-system user dissatisfaction.
* KDD 2022
Enhanced Knowledge Selection for Grounded Dialogues via Document Semantic Graphs
Jun 15, 2022
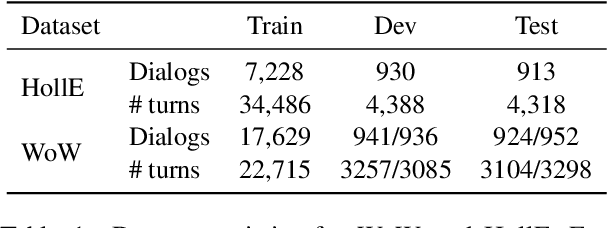
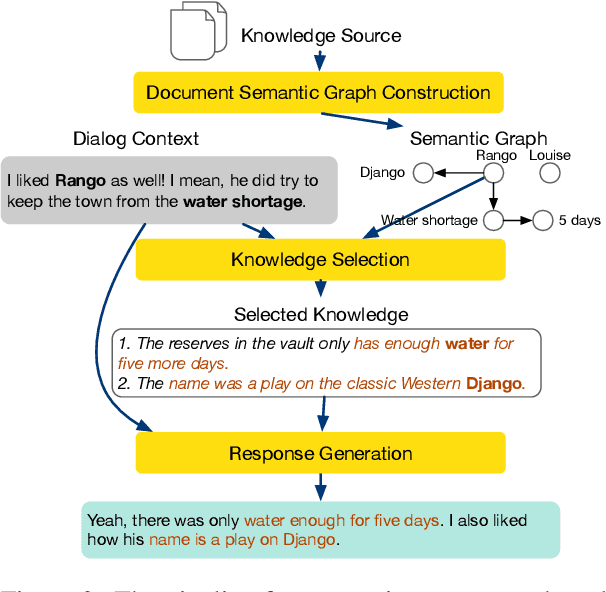
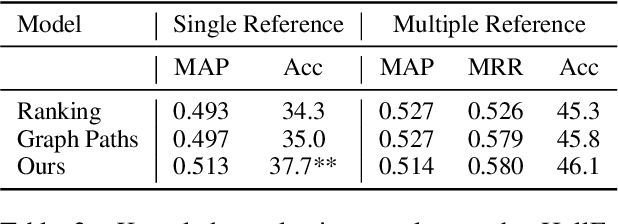
Providing conversation models with background knowledge has been shown to make open-domain dialogues more informative and engaging. Existing models treat knowledge selection as a sentence ranking or classification problem where each sentence is handled individually, ignoring the internal semantic connection among sentences in the background document. In this work, we propose to automatically convert the background knowledge documents into document semantic graphs and then perform knowledge selection over such graphs. Our document semantic graphs preserve sentence-level information through the use of sentence nodes and provide concept connections between sentences. We jointly apply multi-task learning for sentence-level and concept-level knowledge selection and show that it improves sentence-level selection. Our experiments show that our semantic graph-based knowledge selection improves over sentence selection baselines for both the knowledge selection task and the end-to-end response generation task on HollE and improves generalization on unseen topics in WoW.
Calibrate and Debias Layer-wise Sampling for Graph Convolutional Networks
Jun 01, 2022
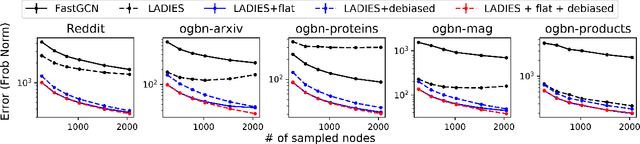
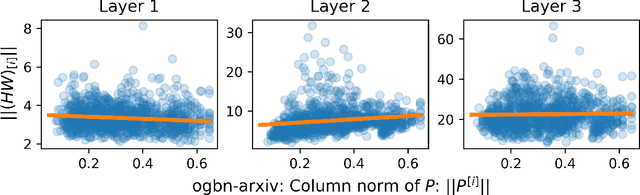
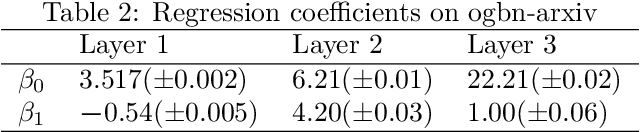
To accelerate the training of graph convolutional networks (GCNs), many sampling-based methods have been developed for approximating the embedding aggregation. Among them, a layer-wise approach recursively performs importance sampling to select neighbors jointly for existing nodes in each layer. This paper revisits the approach from a matrix approximation perspective. We identify two issues in the existing layer-wise sampling methods: sub-optimal sampling probabilities and the approximation bias induced by sampling without replacement. We propose two remedies: new sampling probabilities and a debiasing algorithm, to address these issues, and provide the statistical analysis of the estimation variance. The improvements are demonstrated by extensive analyses and experiments on common benchmarks.
Understanding How People Rate Their Conversations
Jun 01, 2022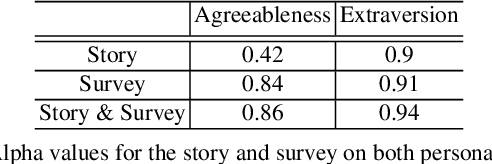
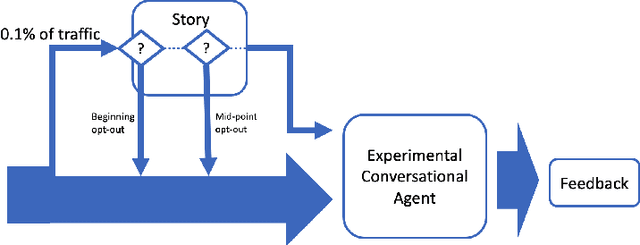
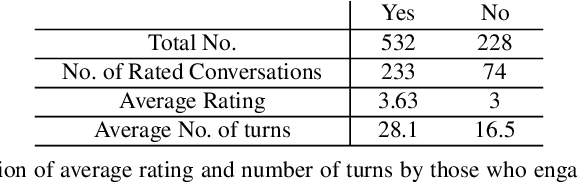
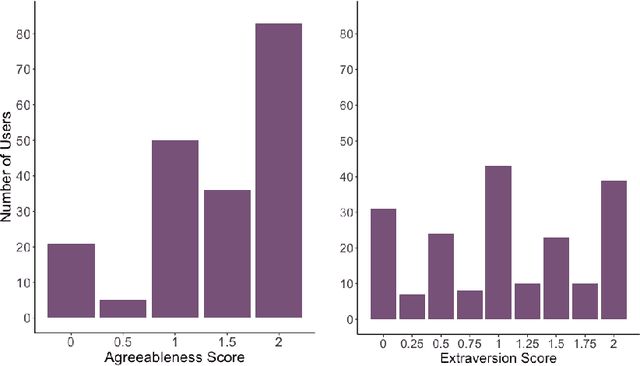
User ratings play a significant role in spoken dialogue systems. Typically, such ratings tend to be averaged across all users and then utilized as feedback to improve the system or personalize its behavior. While this method can be useful to understand broad, general issues with the system and its behavior, it does not take into account differences between users that affect their ratings. In this work, we conduct a study to better understand how people rate their interactions with conversational agents. One macro-level characteristic that has been shown to correlate with how people perceive their inter-personal communication is personality. We specifically focus on agreeableness and extraversion as variables that may explain variation in ratings and therefore provide a more meaningful signal for training or personalization. In order to elicit those personality traits during an interaction with a conversational agent, we designed and validated a fictional story, grounded in prior work in psychology. We then implemented the story into an experimental conversational agent that allowed users to opt-in to hearing the story. Our results suggest that for human-conversational agent interactions, extraversion may play a role in user ratings, but more data is needed to determine if the relationship is significant. Agreeableness, on the other hand, plays a statistically significant role in conversation ratings: users who are more agreeable are more likely to provide a higher rating for their interaction. In addition, we found that users who opted to hear the story were, in general, more likely to rate their conversational experience higher than those who did not.
On the Limits of Evaluating Embodied Agent Model Generalization Using Validation Sets
May 18, 2022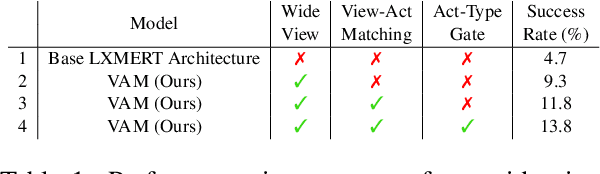
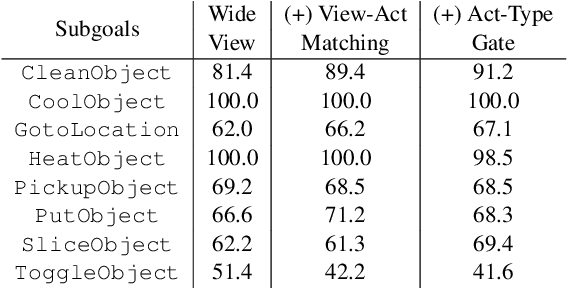
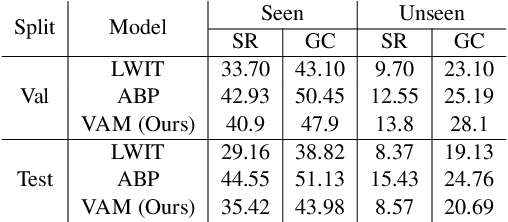
Natural language guided embodied task completion is a challenging problem since it requires understanding natural language instructions, aligning them with egocentric visual observations, and choosing appropriate actions to execute in the environment to produce desired changes. We experiment with augmenting a transformer model for this task with modules that effectively utilize a wider field of view and learn to choose whether the next step requires a navigation or manipulation action. We observed that the proposed modules resulted in improved, and in fact state-of-the-art performance on an unseen validation set of a popular benchmark dataset, ALFRED. However, our best model selected using the unseen validation set underperforms on the unseen test split of ALFRED, indicating that performance on the unseen validation set may not in itself be a sufficient indicator of whether model improvements generalize to unseen test sets. We highlight this result as we believe it may be a wider phenomenon in machine learning tasks but primarily noticeable only in benchmarks that limit evaluations on test splits, and highlights the need to modify benchmark design to better account for variance in model performance.
Empowering parameter-efficient transfer learning by recognizing the kernel structure in self-attention
May 07, 2022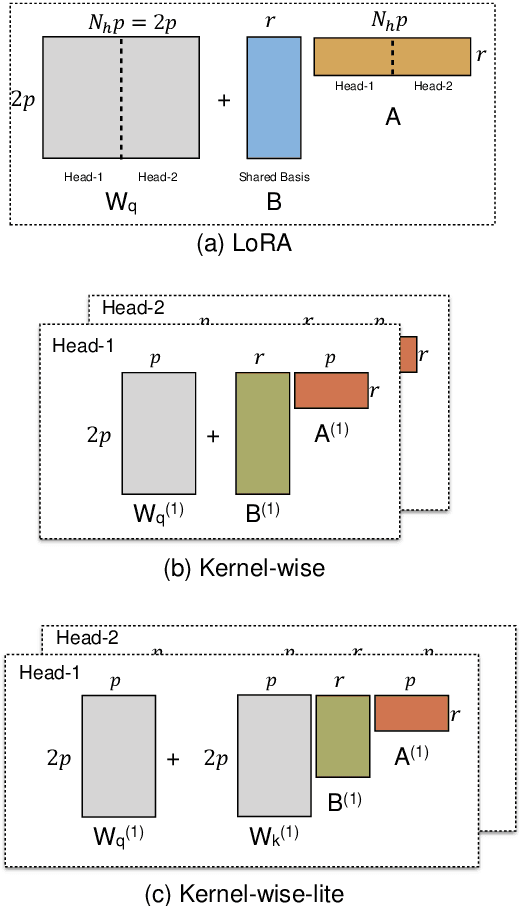
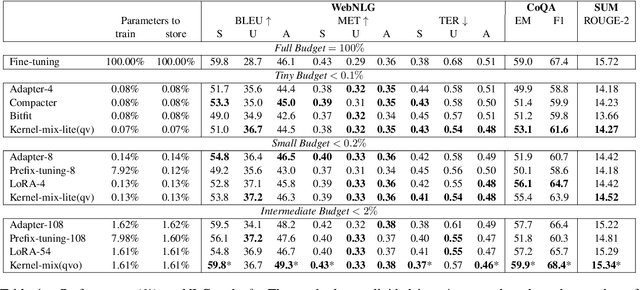
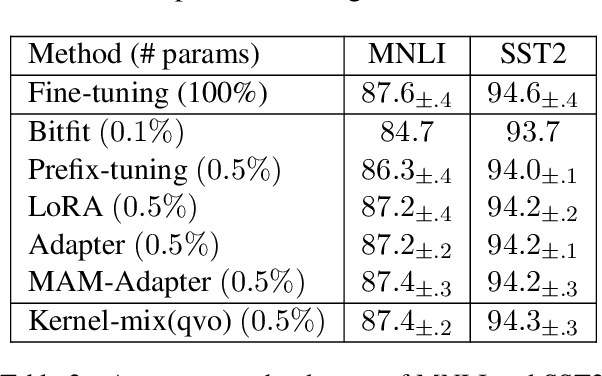
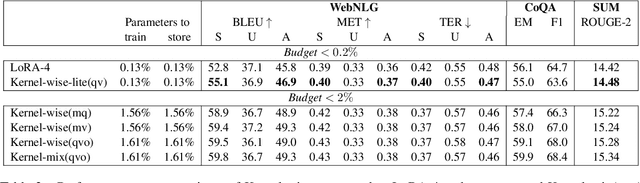
The massive amount of trainable parameters in the pre-trained language models (PLMs) makes them hard to be deployed to multiple downstream tasks. To address this issue, parameter-efficient transfer learning methods have been proposed to tune only a few parameters during fine-tuning while freezing the rest. This paper looks at existing methods along this line through the \textit{kernel lens}. Motivated by the connection between self-attention in transformer-based PLMs and kernel learning, we propose \textit{kernel-wise adapters}, namely \textit{Kernel-mix}, that utilize the kernel structure in self-attention to guide the assignment of the tunable parameters. These adapters use guidelines found in classical kernel learning and enable separate parameter tuning for each attention head. Our empirical results, over a diverse set of natural language generation and understanding tasks, show that our proposed adapters can attain or improve the strong performance of existing baselines.
What is wrong with you?: Leveraging User Sentiment for Automatic Dialog Evaluation
Mar 25, 2022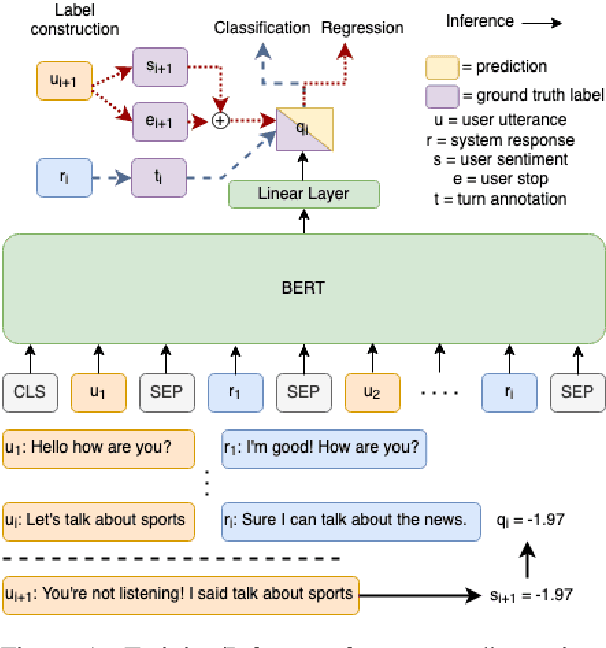

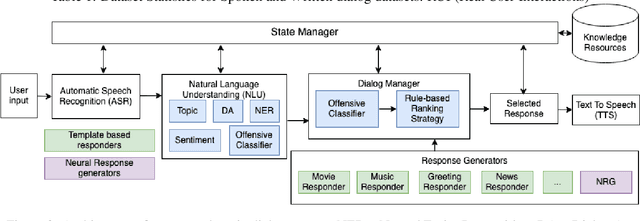
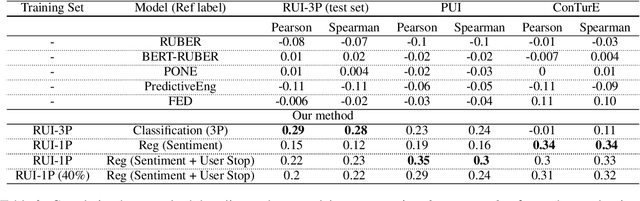
Accurate automatic evaluation metrics for open-domain dialogs are in high demand. Existing model-based metrics for system response evaluation are trained on human annotated data, which is cumbersome to collect. In this work, we propose to use information that can be automatically extracted from the next user utterance, such as its sentiment or whether the user explicitly ends the conversation, as a proxy to measure the quality of the previous system response. This allows us to train on a massive set of dialogs with weak supervision, without requiring manual system turn quality annotations. Experiments show that our model is comparable to models trained on human annotated data. Furthermore, our model generalizes across both spoken and written open-domain dialog corpora collected from real and paid users.
Towards Textual Out-of-Domain Detection without In-Domain Labels
Mar 22, 2022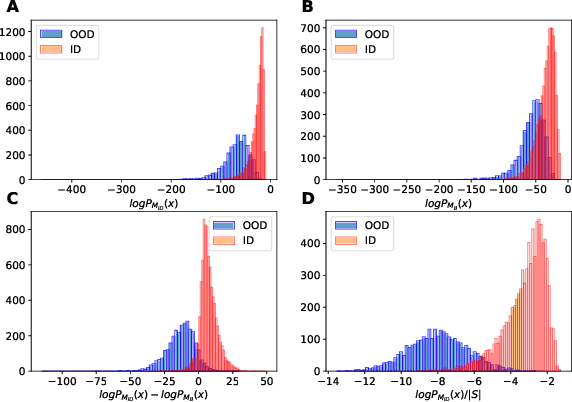
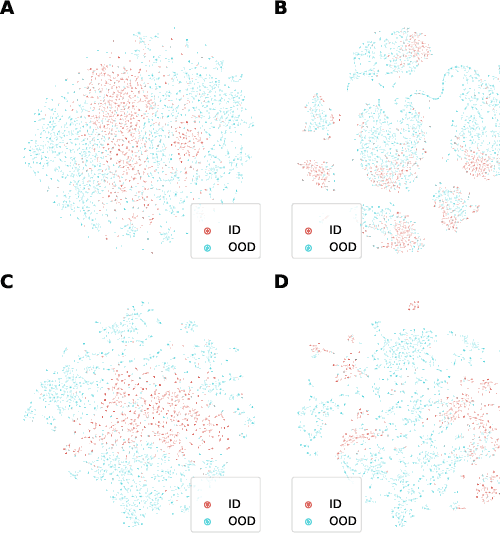
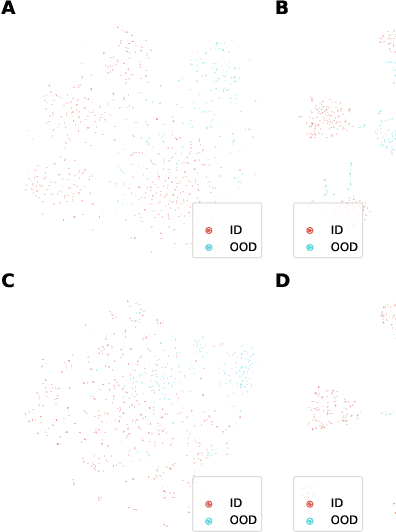
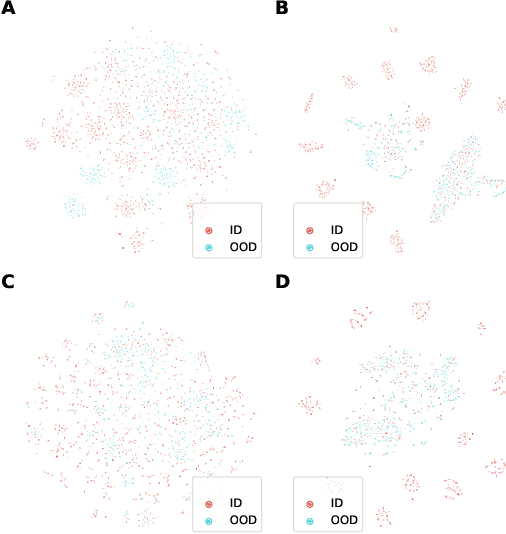
In many real-world settings, machine learning models need to identify user inputs that are out-of-domain (OOD) so as to avoid performing wrong actions. This work focuses on a challenging case of OOD detection, where no labels for in-domain data are accessible (e.g., no intent labels for the intent classification task). To this end, we first evaluate different language model based approaches that predict likelihood for a sequence of tokens. Furthermore, we propose a novel representation learning based method by combining unsupervised clustering and contrastive learning so that better data representations for OOD detection can be learned. Through extensive experiments, we demonstrate that this method can significantly outperform likelihood-based methods and can be even competitive to the state-of-the-art supervised approaches with label information.
Report from the NSF Future Directions Workshop on Automatic Evaluation of Dialog: Research Directions and Challenges
Mar 18, 2022

This is a report on the NSF Future Directions Workshop on Automatic Evaluation of Dialog. The workshop explored the current state of the art along with its limitations and suggested promising directions for future work in this important and very rapidly changing area of research.
Multi-Sentence Knowledge Selection in Open-Domain Dialogue
Mar 01, 2022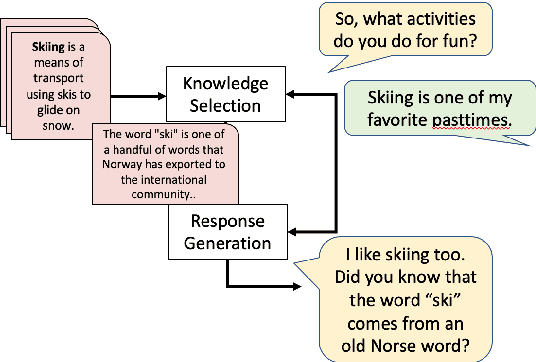



Incorporating external knowledge sources effectively in conversations is a longstanding problem in open-domain dialogue research. The existing literature on open-domain knowledge selection is limited and makes certain brittle assumptions on knowledge sources to simplify the overall task (Dinan et al., 2019), such as the existence of a single relevant knowledge sentence per context. In this work, we evaluate the existing state of open-domain conversation knowledge selection, showing where the existing methodologies regarding data and evaluation are flawed. We then improve on them by proposing a new framework for collecting relevant knowledge, and create an augmented dataset based on the Wizard of Wikipedia (WOW) corpus, which we call WOW++. WOW++ averages 8 relevant knowledge sentences per dialogue context, embracing the inherent ambiguity of open-domain dialogue knowledge selection. We then benchmark various knowledge ranking algorithms on this augmented dataset with both intrinsic evaluation and extrinsic measures of response quality, showing that neural rerankers that use WOW++ can outperform rankers trained on standard datasets.