 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhat type of inference is planning?
Jun 25, 2024



Multiple types of inference are available for probabilistic graphical models, e.g., marginal, maximum-a-posteriori, and even marginal maximum-a-posteriori. Which one do researchers mean when they talk about "planning as inference"? There is no consistency in the literature, different types are used, and their ability to do planning is further entangled with specific approximations or additional constraints. In this work we use the variational framework to show that all commonly used types of inference correspond to different weightings of the entropy terms in the variational problem, and that planning corresponds _exactly_ to a _different_ set of weights. This means that all the tricks of variational inference are readily applicable to planning. We develop an analogue of loopy belief propagation that allows us to perform approximate planning in factored state Markov decisions processes without incurring intractability due to the exponentially large state space. The variational perspective shows that the previous types of inference for planning are only adequate in environments with low stochasticity, and allows us to characterize each type by its own merits, disentangling the type of inference from the additional approximations that its practical use requires. We validate these results empirically on synthetic MDPs and tasks posed in the International Planning Competition.
Learning Cognitive Maps from Transformer Representations for Efficient Planning in Partially Observed Environments
Jan 11, 2024Despite their stellar performance on a wide range of tasks, including in-context tasks only revealed during inference, vanilla transformers and variants trained for next-token predictions (a) do not learn an explicit world model of their environment which can be flexibly queried and (b) cannot be used for planning or navigation. In this paper, we consider partially observed environments (POEs), where an agent receives perceptually aliased observations as it navigates, which makes path planning hard. We introduce a transformer with (multiple) discrete bottleneck(s), TDB, whose latent codes learn a compressed representation of the history of observations and actions. After training a TDB to predict the future observation(s) given the history, we extract interpretable cognitive maps of the environment from its active bottleneck(s) indices. These maps are then paired with an external solver to solve (constrained) path planning problems. First, we show that a TDB trained on POEs (a) retains the near perfect predictive performance of a vanilla transformer or an LSTM while (b) solving shortest path problems exponentially faster. Second, a TDB extracts interpretable representations from text datasets, while reaching higher in-context accuracy than vanilla sequence models. Finally, in new POEs, a TDB (a) reaches near-perfect in-context accuracy, (b) learns accurate in-context cognitive maps (c) solves in-context path planning problems.
Schema-learning and rebinding as mechanisms of in-context learning and emergence
Jun 16, 2023In-context learning (ICL) is one of the most powerful and most unexpected capabilities to emerge in recent transformer-based large language models (LLMs). Yet the mechanisms that underlie it are poorly understood. In this paper, we demonstrate that comparable ICL capabilities can be acquired by an alternative sequence prediction learning method using clone-structured causal graphs (CSCGs). Moreover, a key property of CSCGs is that, unlike transformer-based LLMs, they are {\em interpretable}, which considerably simplifies the task of explaining how ICL works. Specifically, we show that it uses a combination of (a) learning template (schema) circuits for pattern completion, (b) retrieving relevant templates in a context-sensitive manner, and (c) rebinding of novel tokens to appropriate slots in the templates. We go on to marshall evidence for the hypothesis that similar mechanisms underlie ICL in LLMs. For example, we find that, with CSCGs as with LLMs, different capabilities emerge at different levels of overparameterization, suggesting that overparameterization helps in learning more complex template (schema) circuits. By showing how ICL can be achieved with small models and datasets, we open up a path to novel architectures, and take a vital step towards a more general understanding of the mechanics behind this important capability.
Fast exploration and learning of latent graphs with aliased observations
Mar 21, 2023



Consider this scenario: an agent navigates a latent graph by performing actions that take it from one node to another. The chosen action determines the probability distribution over the next visited node. At each node, the agent receives an observation, but this observation is not unique, so it does not identify the node, making the problem aliased. The purpose of this work is to provide a policy that approximately maximizes exploration efficiency (i.e., how well the graph is recovered for a given exploration budget). In the unaliased case, we show improved performance w.r.t. state-of-the-art reinforcement learning baselines. For the aliased case we are not aware of suitable baselines and instead show faster recovery w.r.t. a random policy for a wide variety of topologies, and exponentially faster recovery than a random policy for challenging topologies. We dub the algorithm eFeX (from eFficient eXploration).
Graph schemas as abstractions for transfer learning, inference, and planning
Feb 14, 2023We propose schemas as a model for abstractions that can be used for rapid transfer learning, inference, and planning. Common structured representations of concepts and behaviors -- schemas -- have been proposed as a powerful way to encode abstractions. Latent graph learning is emerging as a new computational model of the hippocampus to explain map learning and transitive inference. We build on this work to show that learned latent graphs in these models have a slot structure -- schemas -- that allow for quick knowledge transfer across environments. In a new environment, an agent can rapidly learn new bindings between the sensory stream to multiple latent schemas and select the best fitting one to guide behavior. To evaluate these graph schemas, we use two previously published challenging tasks: the memory & planning game and one-shot StreetLearn, that are designed to test rapid task solving in novel environments. Graph schemas can be learned in far fewer episodes than previous baselines, and can model and plan in a few steps in novel variations of these tasks. We further demonstrate learning, matching, and reusing graph schemas in navigation tasks in more challenging environments with aliased observations and size variations, and show how different schemas can be composed to model larger 2D and 3D environments.
3D Neural Embedding Likelihood for Robust Sim-to-Real Transfer in Inverse Graphics
Feb 07, 2023



A central challenge in 3D scene perception via inverse graphics is robustly modeling the gap between 3D graphics and real-world data. We propose a novel 3D Neural Embedding Likelihood (3DNEL) over RGB-D images to address this gap. 3DNEL uses neural embeddings to predict 2D-3D correspondences from RGB and combines this with depth in a principled manner. 3DNEL is trained entirely from synthetic images and generalizes to real-world data. To showcase this capability, we develop a multi-stage inverse graphics pipeline that uses 3DNEL for 6D object pose estimation from real RGB-D images. Our method outperforms the previous state-of-the-art in sim-to-real pose estimation on the YCB-Video dataset, and improves robustness, with significantly fewer large-error predictions. Unlike existing bottom-up, discriminative approaches that are specialized for pose estimation, 3DNEL adopts a probabilistic generative formulation that jointly models multi-object scenes. This generative formulation enables easy extension of 3DNEL to additional tasks like object and camera tracking from video, using principled inference in the same probabilistic model without task specific retraining.
PushWorld: A benchmark for manipulation planning with tools and movable obstacles
Feb 01, 2023While recent advances in artificial intelligence have achieved human-level performance in environments like Starcraft and Go, many physical reasoning tasks remain challenging for modern algorithms. To date, few algorithms have been evaluated on physical tasks that involve manipulating objects when movable obstacles are present and when tools must be used to perform the manipulation. To promote research on such tasks, we introduce PushWorld, an environment with simplistic physics that requires manipulation planning with both movable obstacles and tools. We provide a benchmark of more than 200 PushWorld puzzles in PDDL and in an OpenAI Gym environment. We evaluate state-of-the-art classical planning and reinforcement learning algorithms on this benchmark, and we find that these baseline results are below human-level performance. We then provide a new classical planning heuristic that solves the most puzzles among the baselines, and although it is 40 times faster than the best baseline planner, it remains below human-level performance.
Learning noisy-OR Bayesian Networks with Max-Product Belief Propagation
Jan 31, 2023Noisy-OR Bayesian Networks (BNs) are a family of probabilistic graphical models which express rich statistical dependencies in binary data. Variational inference (VI) has been the main method proposed to learn noisy-OR BNs with complex latent structures (Jaakkola & Jordan, 1999; Ji et al., 2020; Buhai et al., 2020). However, the proposed VI approaches either (a) use a recognition network with standard amortized inference that cannot induce ``explaining-away''; or (b) assume a simple mean-field (MF) posterior which is vulnerable to bad local optima. Existing MF VI methods also update the MF parameters sequentially which makes them inherently slow. In this paper, we propose parallel max-product as an alternative algorithm for learning noisy-OR BNs with complex latent structures and we derive a fast stochastic training scheme that scales to large datasets. We evaluate both approaches on several benchmarks where VI is the state-of-the-art and show that our method (a) achieves better test performance than Ji et al. (2020) for learning noisy-OR BNs with hierarchical latent structures on large sparse real datasets; (b) recovers a higher number of ground truth parameters than Buhai et al. (2020) from cluttered synthetic scenes; and (c) solves the 2D blind deconvolution problem from Lazaro-Gredilla et al. (2021) and variant - including binary matrix factorization - while VI catastrophically fails and is up to two orders of magnitude slower.
PGMax: Factor Graphs for Discrete Probabilistic Graphical Models and Loopy Belief Propagation in JAX
Feb 08, 2022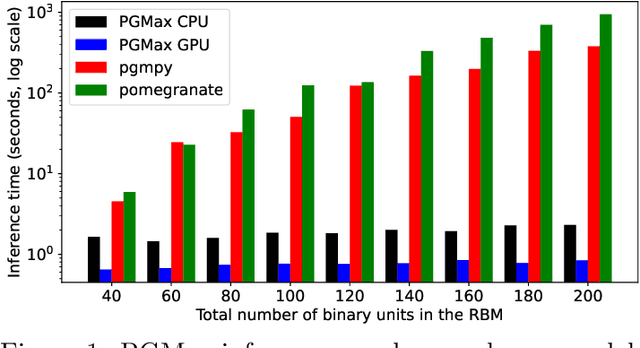
PGMax is an open-source Python package for easy specification of discrete Probabilistic Graphical Models (PGMs) as factor graphs, and automatic derivation of efficient and scalable loopy belief propagation (LBP) implementation in JAX. It supports general factor graphs, and can effectively leverage modern accelerators like GPUs for inference. Compared with existing alternatives, PGMax obtains higher-quality inference results with orders-of-magnitude inference speedups. PGMax additionally interacts seamlessly with the rapidly growing JAX ecosystem, opening up exciting new possibilities. Our source code, examples and documentation are available at https://github.com/vicariousinc/PGMax.
DURableVS: Data-efficient Unsupervised Recalibrating Visual Servoing via online learning in a structured generative model
Feb 08, 2022
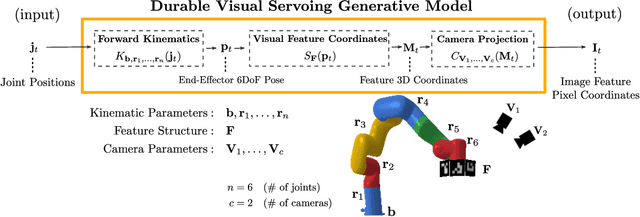
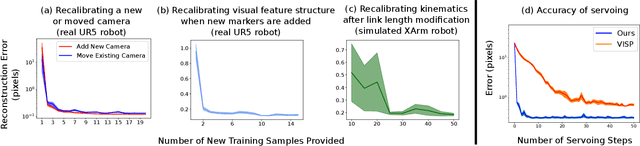

Visual servoing enables robotic systems to perform accurate closed-loop control, which is required in many applications. However, existing methods either require precise calibration of the robot kinematic model and cameras or use neural architectures that require large amounts of data to train. In this work, we present a method for unsupervised learning of visual servoing that does not require any prior calibration and is extremely data-efficient. Our key insight is that visual servoing does not depend on identifying the veridical kinematic and camera parameters, but instead only on an accurate generative model of image feature observations from the joint positions of the robot. We demonstrate that with our model architecture and learning algorithm, we can consistently learn accurate models from less than 50 training samples (which amounts to less than 1 min of unsupervised data collection), and that such data-efficient learning is not possible with standard neural architectures. Further, we show that by using the generative model in the loop and learning online, we can enable a robotic system to recover from calibration errors and to detect and quickly adapt to possibly unexpected changes in the robot-camera system (e.g. bumped camera, new objects).