 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Information-Theoretic Analysis of Self-supervised Discrete Representations of Speech
Jun 04, 2023



Self-supervised representation learning for speech often involves a quantization step that transforms the acoustic input into discrete units. However, it remains unclear how to characterize the relationship between these discrete units and abstract phonetic categories such as phonemes. In this paper, we develop an information-theoretic framework whereby we represent each phonetic category as a distribution over discrete units. We then apply our framework to two different self-supervised models (namely wav2vec 2.0 and XLSR) and use American English speech as a case study. Our study demonstrates that the entropy of phonetic distributions reflects the variability of the underlying speech sounds, with phonetically similar sounds exhibiting similar distributions. While our study confirms the lack of direct, one-to-one correspondence, we find an intriguing, indirect relationship between phonetic categories and discrete units.
Few-shot Fine-tuning vs. In-context Learning: A Fair Comparison and Evaluation
May 30, 2023



Few-shot fine-tuning and in-context learning are two alternative strategies for task adaptation of pre-trained language models. Recently, in-context learning has gained popularity over fine-tuning due to its simplicity and improved out-of-domain generalization, and because extensive evidence shows that fine-tuned models pick up on spurious correlations. Unfortunately, previous comparisons of the two approaches were done using models of different sizes. This raises the question of whether the observed weaker out-of-domain generalization of fine-tuned models is an inherent property of fine-tuning or a limitation of the experimental setup. In this paper, we compare the generalization of few-shot fine-tuning and in-context learning to challenge datasets, while controlling for the models used, the number of examples, and the number of parameters, ranging from 125M to 30B. Our results show that fine-tuned language models can in fact generalize well out-of-domain. We find that both approaches generalize similarly; they exhibit large variation and depend on properties such as model size and the number of examples, highlighting that robust task adaptation remains a challenge.
Weaker Than You Think: A Critical Look atWeakly Supervised Learning
May 27, 2023



Weakly supervised learning is a popular approach for training machine learning models in low-resource settings. Instead of requesting high-quality yet costly human annotations, it allows training models with noisy annotations obtained from various weak sources. Recently, many sophisticated approaches have been proposed for robust training under label noise, reporting impressive results. In this paper, we revisit the setup of these approaches and find that the benefits brought by these approaches are significantly overestimated. Specifically, we find that the success of existing weakly supervised learning approaches heavily relies on the availability of clean validation samples which, as we show, can be leveraged much more efficiently by simply training on them. After using these clean labels in training, the advantages of using these sophisticated approaches are mostly wiped out. This remains true even when reducing the size of the available clean data to just five samples per class, making these approaches impractical. To understand the true value of weakly supervised learning, we thoroughly analyse diverse NLP datasets and tasks to ascertain when and why weakly supervised approaches work, and provide recommendations for future research.
MasakhaPOS: Part-of-Speech Tagging for Typologically Diverse African Languages
May 23, 2023



In this paper, we present MasakhaPOS, the largest part-of-speech (POS) dataset for 20 typologically diverse African languages. We discuss the challenges in annotating POS for these languages using the UD (universal dependencies) guidelines. We conducted extensive POS baseline experiments using conditional random field and several multilingual pre-trained language models. We applied various cross-lingual transfer models trained with data available in UD. Evaluating on the MasakhaPOS dataset, we show that choosing the best transfer language(s) in both single-source and multi-source setups greatly improves the POS tagging performance of the target languages, in particular when combined with cross-lingual parameter-efficient fine-tuning methods. Crucially, transferring knowledge from a language that matches the language family and morphosyntactic properties seems more effective for POS tagging in unseen languages.
$\varepsilon$ KÚ <MASK>: Integrating Yorùbá cultural greetings into machine translation
Apr 24, 2023This paper investigates the performance of massively multilingual neural machine translation (NMT) systems in translating Yor\`ub\'a greetings ($\varepsilon$ k\'u [MASK]), which are a big part of Yor\`ub\'a language and culture, into English. To evaluate these models, we present IkiniYor\`ub\'a, a Yor\`ub\'a-English translation dataset containing some Yor\`ub\'a greetings, and sample use cases. We analysed the performance of different multilingual NMT systems including Google and NLLB and show that these models struggle to accurately translate Yor\`ub\'a greetings into English. In addition, we trained a Yor\`ub\'a-English model by finetuning an existing NMT model on the training split of IkiniYor\`ub\'a and this achieved better performance when compared to the pre-trained multilingual NMT models, although they were trained on a large volume of data.
Analyzing the Representational Geometry of Acoustic Word Embeddings
Jan 08, 2023



Acoustic word embeddings (AWEs) are vector representations such that different acoustic exemplars of the same word are projected nearby in the embedding space. In addition to their use in speech technology applications such as spoken term discovery and keyword spotting, AWE models have been adopted as models of spoken-word processing in several cognitively motivated studies and have been shown to exhibit human-like performance in some auditory processing tasks. Nevertheless, the representational geometry of AWEs remains an under-explored topic that has not been studied in the literature. In this paper, we take a closer analytical look at AWEs learned from English speech and study how the choice of the learning objective and the architecture shapes their representational profile. To this end, we employ a set of analytic techniques from machine learning and neuroscience in three different analyses: embedding space uniformity, word discriminability, and representational consistency. Our main findings highlight the prominent role of the learning objective on shaping the representation profile compared to the model architecture.
A Data-Driven Investigation of Noise-Adaptive Utterance Generation with Linguistic Modification
Oct 19, 2022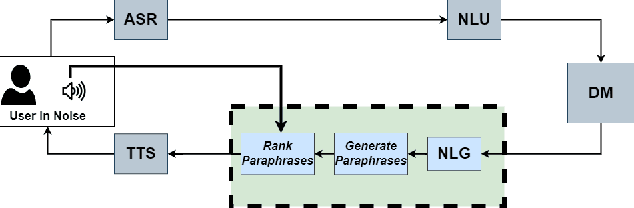
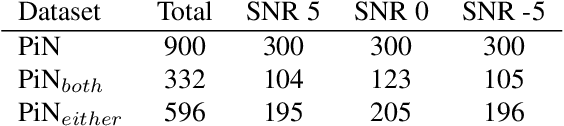
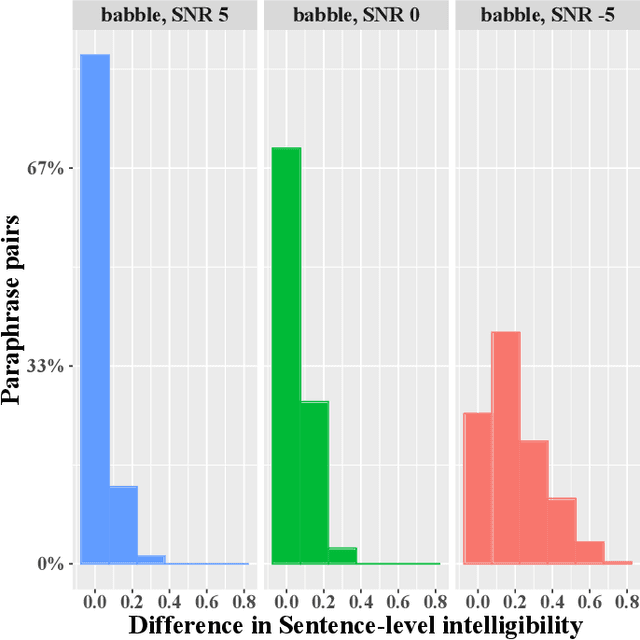
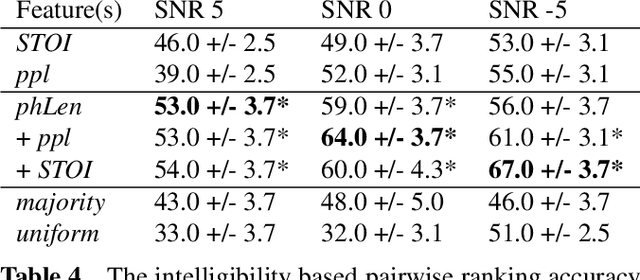
In noisy environments, speech can be hard to understand for humans. Spoken dialog systems can help to enhance the intelligibility of their output, either by modifying the speech synthesis (e.g., imitate Lombard speech) or by optimizing the language generation. We here focus on the second type of approach, by which an intended message is realized with words that are more intelligible in a specific noisy environment. By conducting a speech perception experiment, we created a dataset of 900 paraphrases in babble noise, perceived by native English speakers with normal hearing. We find that careful selection of paraphrases can improve intelligibility by 33% at SNR -5 dB. Our analysis of the data shows that the intelligibility differences between paraphrases are mainly driven by noise-robust acoustic cues. Furthermore, we propose an intelligibility-aware paraphrase ranking model, which outperforms baseline models with a relative improvement of 31.37% at SNR -5 dB.
Integrating Form and Meaning: A Multi-Task Learning Model for Acoustic Word Embeddings
Sep 18, 2022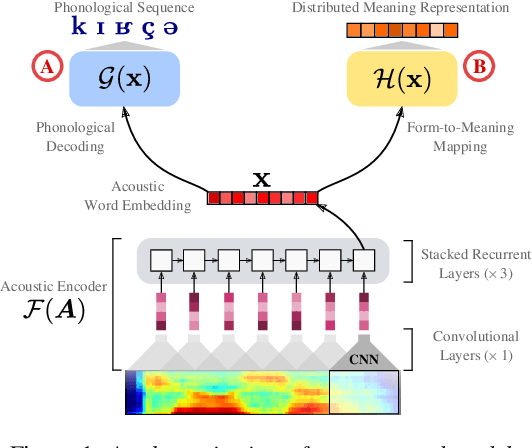
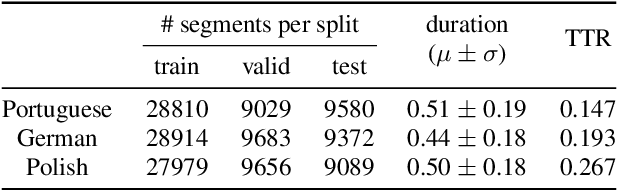

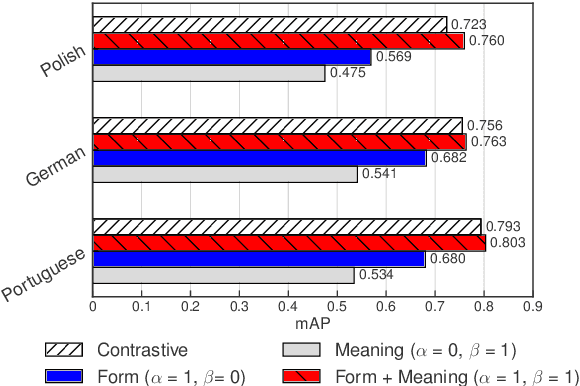
Models of acoustic word embeddings (AWEs) learn to map variable-length spoken word segments onto fixed-dimensionality vector representations such that different acoustic exemplars of the same word are projected nearby in the embedding space. In addition to their speech technology applications, AWE models have been shown to predict human performance on a variety of auditory lexical processing tasks. Current AWE models are based on neural networks and trained in a bottom-up approach that integrates acoustic cues to build up a word representation given an acoustic or symbolic supervision signal. Therefore, these models do not leverage or capture high-level lexical knowledge during the learning process. In this paper, we propose a multi-task learning model that incorporates top-down lexical knowledge into the training procedure of AWEs. Our model learns a mapping between the acoustic input and a lexical representation that encodes high-level information such as word semantics in addition to bottom-up form-based supervision. We experiment with three languages and demonstrate that incorporating lexical knowledge improves the embedding space discriminability and encourages the model to better separate lexical categories.
Fusing Sentence Embeddings Into LSTM-based Autoregressive Language Models
Aug 05, 2022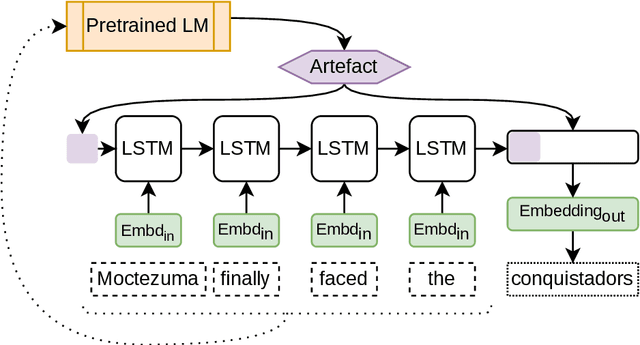
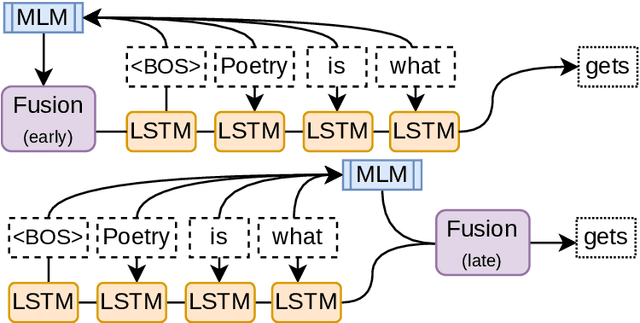

Although masked language models are highly performant and widely adopted by NLP practitioners, they can not be easily used for autoregressive language modelling (next word prediction and sequence probability estimation). We present an LSTM-based autoregressive language model which uses prefix embeddings (from a pretrained masked language model) via fusion (e.g. concatenation) to obtain a richer context representation for language modelling. We find that fusion helps reliably in lowering the perplexity (16.74 $\rightarrow$ 15.80), which is even preserved after a transfer to a dataset from a different domain than the training data. We also evaluate the best-performing fusion model by correlating its next word surprisal estimates with human reading times. Contradicting our expectation, and despite the improvement in perplexity overall, the correlation remains the same as for the baseline model. Lastly, while we focus on language models pre-trained on text as the sources for the fusion, our approach can be possibly extended to fuse any information represented as a fixed-size vector into an auto-regressive language model. These include e.g. sentence external information retrieved for a knowledge base or representations of multi-modal encoders.
TOKEN is a MASK: Few-shot Named Entity Recognition with Pre-trained Language Models
Jun 15, 2022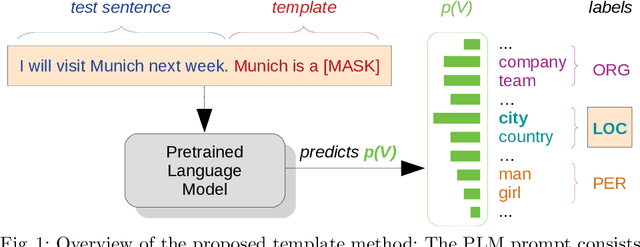



Transferring knowledge from one domain to another is of practical importance for many tasks in natural language processing, especially when the amount of available data in the target domain is limited. In this work, we propose a novel few-shot approach to domain adaptation in the context of Named Entity Recognition (NER). We propose a two-step approach consisting of a variable base module and a template module that leverages the knowledge captured in pre-trained language models with the help of simple descriptive patterns. Our approach is simple yet versatile and can be applied in few-shot and zero-shot settings. Evaluating our lightweight approach across a number of different datasets shows that it can boost the performance of state-of-the-art baselines by 2-5% F1-score.