 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Interactive Intelligence for Digital Humans
Dec 15, 2025We introduce Interactive Intelligence, a novel paradigm of digital human that is capable of personality-aligned expression, adaptive interaction, and self-evolution. To realize this, we present Mio (Multimodal Interactive Omni-Avatar), an end-to-end framework composed of five specialized modules: Thinker, Talker, Face Animator, Body Animator, and Renderer. This unified architecture integrates cognitive reasoning with real-time multimodal embodiment to enable fluid, consistent interaction. Furthermore, we establish a new benchmark to rigorously evaluate the capabilities of interactive intelligence. Extensive experiments demonstrate that our framework achieves superior performance compared to state-of-the-art methods across all evaluated dimensions. Together, these contributions move digital humans beyond superficial imitation toward intelligent interaction.
Multi-band Frequency Reconstruction for Neural Psychoacoustic Coding
May 12, 2025Achieving high-fidelity audio compression while preserving perceptual quality across diverse content remains a key challenge in Neural Audio Coding (NAC). We introduce MUFFIN, a fully convolutional Neural Psychoacoustic Coding (NPC) framework that leverages psychoacoustically guided multi-band frequency reconstruction. At its core is a Multi-Band Spectral Residual Vector Quantization (MBS-RVQ) module that allocates bitrate across frequency bands based on perceptual salience. This design enables efficient compression while disentangling speaker identity from content using distinct codebooks. MUFFIN incorporates a transformer-inspired convolutional backbone and a modified snake activation to enhance resolution in fine-grained spectral regions. Experimental results on multiple benchmarks demonstrate that MUFFIN consistently outperforms existing approaches in reconstruction quality. A high-compression variant achieves a state-of-the-art 12.5 Hz rate with minimal loss. MUFFIN also proves effective in downstream generative tasks, highlighting its promise as a token representation for integration with language models. Audio samples and code are available.
100 Days After DeepSeek-R1: A Survey on Replication Studies and More Directions for Reasoning Language Models
May 01, 2025The recent development of reasoning language models (RLMs) represents a novel evolution in large language models. In particular, the recent release of DeepSeek-R1 has generated widespread social impact and sparked enthusiasm in the research community for exploring the explicit reasoning paradigm of language models. However, the implementation details of the released models have not been fully open-sourced by DeepSeek, including DeepSeek-R1-Zero, DeepSeek-R1, and the distilled small models. As a result, many replication studies have emerged aiming to reproduce the strong performance achieved by DeepSeek-R1, reaching comparable performance through similar training procedures and fully open-source data resources. These works have investigated feasible strategies for supervised fine-tuning (SFT) and reinforcement learning from verifiable rewards (RLVR), focusing on data preparation and method design, yielding various valuable insights. In this report, we provide a summary of recent replication studies to inspire future research. We primarily focus on SFT and RLVR as two main directions, introducing the details for data construction, method design and training procedure of current replication studies. Moreover, we conclude key findings from the implementation details and experimental results reported by these studies, anticipating to inspire future research. We also discuss additional techniques of enhancing RLMs, highlighting the potential of expanding the application scope of these models, and discussing the challenges in development. By this survey, we aim to help researchers and developers of RLMs stay updated with the latest advancements, and seek to inspire new ideas to further enhance RLMs.
Emotional Dimension Control in Language Model-Based Text-to-Speech: Spanning a Broad Spectrum of Human Emotions
Sep 25, 2024Current emotional text-to-speech (TTS) systems face challenges in mimicking a broad spectrum of human emotions due to the inherent complexity of emotions and limitations in emotional speech datasets and models. This paper proposes a TTS framework that facilitates control over pleasure, arousal, and dominance, and can synthesize a diversity of emotional styles without requiring any emotional speech data during TTS training. We train an emotional attribute predictor using only categorical labels from speech data, aligning with psychological research and incorporating anchored dimensionality reduction on self-supervised learning (SSL) features. The TTS framework converts text inputs into phonetic tokens via an autoregressive language model and uses pseudo-emotional dimensions to guide the parallel prediction of fine-grained acoustic details. Experiments conducted on the LibriTTS dataset demonstrate that our framework can synthesize speech with enhanced naturalness and a variety of emotional styles by effectively controlling emotional dimensions, even without the inclusion of any emotional speech during TTS training.
Towards Audio Codec-based Speech Separation
Jun 18, 2024Recent improvements in neural audio codec (NAC) models have generated interest in adopting pre-trained codecs for a variety of speech processing applications to take advantage of the efficiencies gained from high compression, but these have yet been applied to the speech separation (SS) task. SS can benefit from high compression because the compute required for traditional SS models makes them impractical for many edge computing use cases. However, SS is a waveform-masking task where compression tends to introduce distortions that severely impact performance. Here we propose a novel task of Audio Codec-based SS, where SS is performed within the embedding space of a NAC, and propose a new model, Codecformer, to address this task. At inference, Codecformer achieves a 52x reduction in MAC while producing separation performance comparable to a cloud deployment of Sepformer. This method charts a new direction for performing efficient SS in practical scenarios.
Dataset-Distillation Generative Model for Speech Emotion Recognition
Jun 05, 2024



Deep learning models for speech rely on large datasets, presenting computational challenges. Yet, performance hinges on training data size. Dataset Distillation (DD) aims to learn a smaller dataset without much performance degradation when training with it. DD has been investigated in computer vision but not yet in speech. This paper presents the first approach for DD to speech targeting Speech Emotion Recognition on IEMOCAP. We employ Generative Adversarial Networks (GANs) not to mimic real data but to distil key discriminative information of IEMOCAP that is useful for downstream training. The GAN then replaces the original dataset and can sample custom synthetic dataset sizes. It performs comparably when following the original class imbalance but improves performance by 0.3% absolute UAR with balanced classes. It also reduces dataset storage and accelerates downstream training by 95% in both cases and reduces speaker information which could help for a privacy application.
Phonetic Enhanced Language Modeling for Text-to-Speech Synthesis
Jun 04, 2024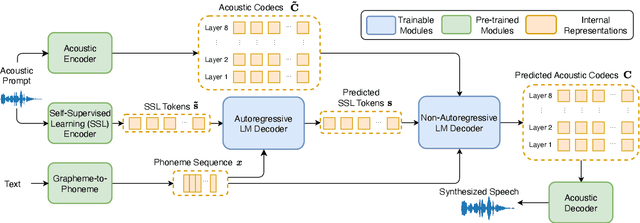
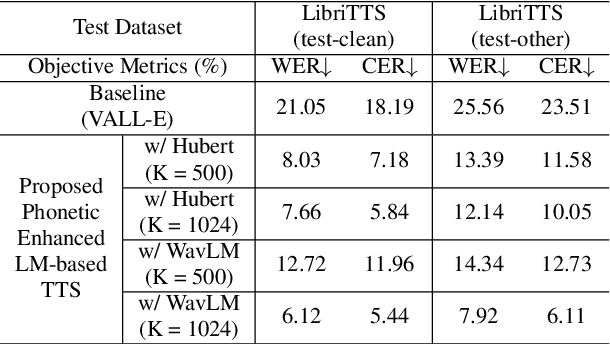
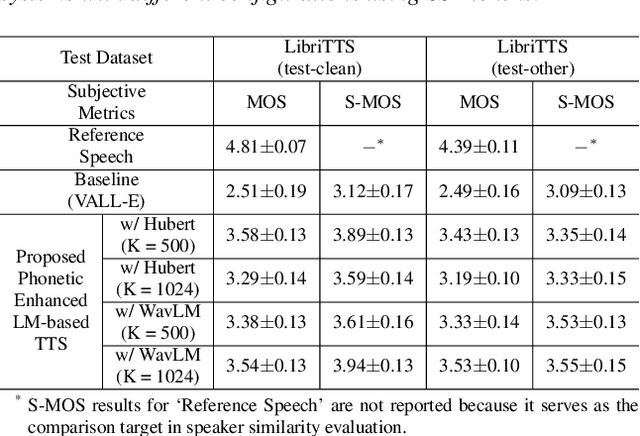
Recent language model-based text-to-speech (TTS) frameworks demonstrate scalability and in-context learning capabilities. However, they suffer from robustness issues due to the accumulation of errors in speech unit predictions during autoregressive language modeling. In this paper, we propose a phonetic enhanced language modeling method to improve the performance of TTS models. We leverage self-supervised representations that are phonetically rich as the training target for the autoregressive language model. Subsequently, a non-autoregressive model is employed to predict discrete acoustic codecs that contain fine-grained acoustic details. The TTS model focuses solely on linguistic modeling during autoregressive training, thereby reducing the error propagation that occurs in non-autoregressive training. Both objective and subjective evaluations validate the effectiveness of our proposed method.
MossFormer2: Combining Transformer and RNN-Free Recurrent Network for Enhanced Time-Domain Monaural Speech Separation
Dec 19, 2023



Our previously proposed MossFormer has achieved promising performance in monaural speech separation. However, it predominantly adopts a self-attention-based MossFormer module, which tends to emphasize longer-range, coarser-scale dependencies, with a deficiency in effectively modelling finer-scale recurrent patterns. In this paper, we introduce a novel hybrid model that provides the capabilities to model both long-range, coarse-scale dependencies and fine-scale recurrent patterns by integrating a recurrent module into the MossFormer framework. Instead of applying the recurrent neural networks (RNNs) that use traditional recurrent connections, we present a recurrent module based on a feedforward sequential memory network (FSMN), which is considered "RNN-free" recurrent network due to the ability to capture recurrent patterns without using recurrent connections. Our recurrent module mainly comprises an enhanced dilated FSMN block by using gated convolutional units (GCU) and dense connections. In addition, a bottleneck layer and an output layer are also added for controlling information flow. The recurrent module relies on linear projections and convolutions for seamless, parallel processing of the entire sequence. The integrated MossFormer2 hybrid model demonstrates remarkable enhancements over MossFormer and surpasses other state-of-the-art methods in WSJ0-2/3mix, Libri2Mix, and WHAM!/WHAMR! benchmarks.
Noise robust distillation of self-supervised speech models via correlation metrics
Dec 19, 2023



Compared to large speech foundation models, small distilled models exhibit degraded noise robustness. The student's robustness can be improved by introducing noise at the inputs during pre-training. Despite this, using the standard distillation loss still yields a student with degraded performance. Thus, this paper proposes improving student robustness via distillation with correlation metrics. Teacher behavior is learned by maximizing the teacher and student cross-correlation matrix between their representations towards identity. Noise robustness is encouraged via the student's self-correlation minimization. The proposed method is agnostic of the teacher model and consistently outperforms the previous approach. This work also proposes an heuristic to weigh the importance of the two correlation terms automatically. Experiments show consistently better clean and noise generalization on Intent Classification, Keyword Spotting, and Automatic Speech Recognition tasks on SUPERB Challenge.
SPGM: Prioritizing Local Features for enhanced speech separation performance
Sep 22, 2023



Dual-path is a popular architecture for speech separation models (e.g. Sepformer) which splits long sequences into overlapping chunks for its intra- and inter-blocks that separately model intra-chunk local features and inter-chunk global relationships. However, it has been found that inter-blocks, which comprise half a dual-path model's parameters, contribute minimally to performance. Thus, we propose the Single-Path Global Modulation (SPGM) block to replace inter-blocks. SPGM is named after its structure consisting of a parameter-free global pooling module followed by a modulation module comprising only 2% of the model's total parameters. The SPGM block allows all transformer layers in the model to be dedicated to local feature modelling, making the overall model single-path. SPGM achieves 22.1 dB SI-SDRi on WSJ0-2Mix and 20.4 dB SI-SDRi on Libri2Mix, exceeding the performance of Sepformer by 0.5 dB and 0.3 dB respectively and matches the performance of recent SOTA models with up to 8 times fewer parameters.