 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeural Inheritance Relation Guided One-Shot Layer Assignment Search
Feb 28, 2020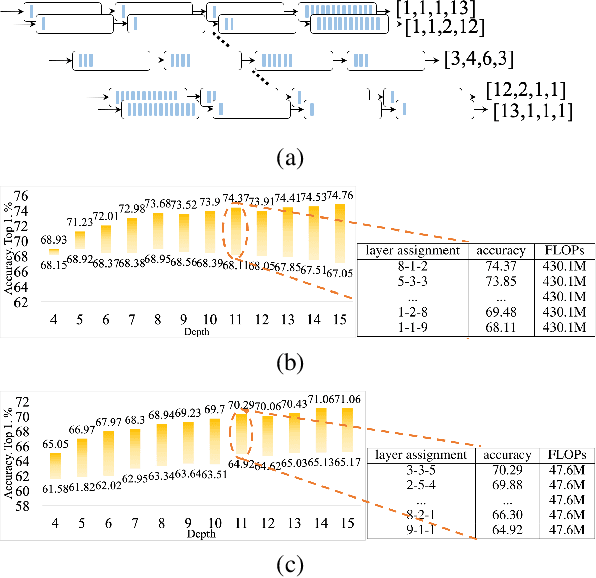
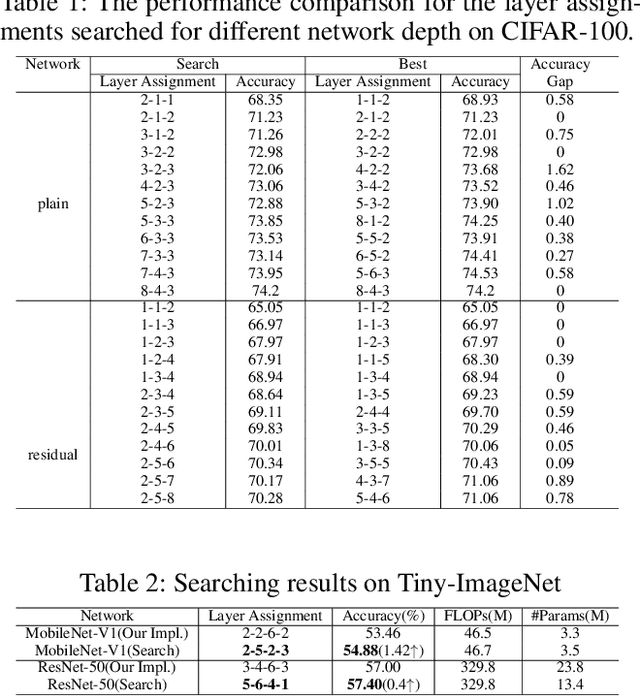
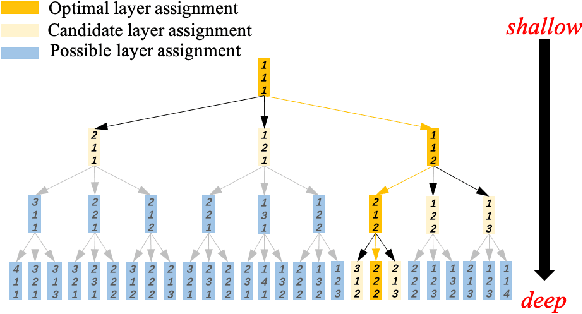
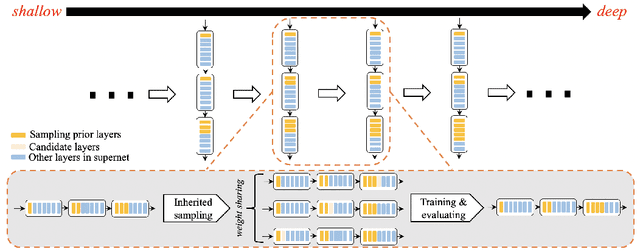
Layer assignment is seldom picked out as an independent research topic in neural architecture search. In this paper, for the first time, we systematically investigate the impact of different layer assignments to the network performance by building an architecture dataset of layer assignment on CIFAR-100. Through analyzing this dataset, we discover a neural inheritance relation among the networks with different layer assignments, that is, the optimal layer assignments for deeper networks always inherit from those for shallow networks. Inspired by this neural inheritance relation, we propose an efficient one-shot layer assignment search approach via inherited sampling. Specifically, the optimal layer assignment searched in the shallow network can be provided as a strong sampling priori to train and search the deeper ones in supernet, which extremely reduces the network search space. Comprehensive experiments carried out on CIFAR-100 illustrate the efficiency of our proposed method. Our search results are strongly consistent with the optimal ones directly selected from the architecture dataset. To further confirm the generalization of our proposed method, we also conduct experiments on Tiny-ImageNet and ImageNet. Our searched results are remarkably superior to the handcrafted ones under the unchanged computational budgets. The neural inheritance relation discovered in this paper can provide insights to the universal neural architecture search.
An End-to-End Audio Classification System based on Raw Waveforms and Mix-Training Strategy
Nov 21, 2019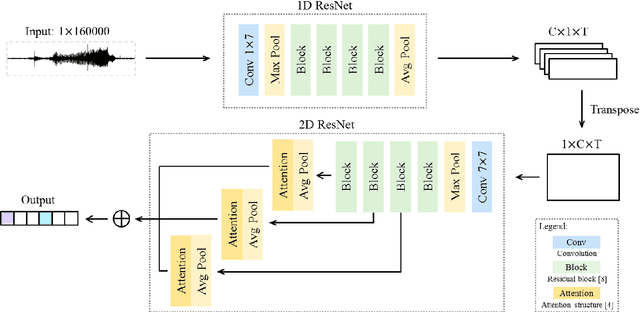

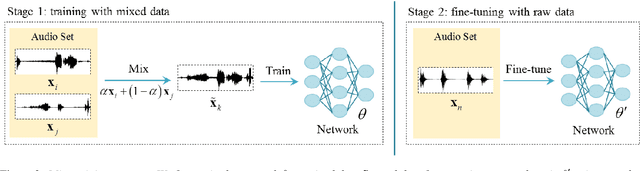

Audio classification can distinguish different kinds of sounds, which is helpful for intelligent applications in daily life. However, it remains a challenging task since the sound events in an audio clip is probably multiple, even overlapping. This paper introduces an end-to-end audio classification system based on raw waveforms and mix-training strategy. Compared to human-designed features which have been widely used in existing research, raw waveforms contain more complete information and are more appropriate for multi-label classification. Taking raw waveforms as input, our network consists of two variants of ResNet structure which can learn a discriminative representation. To explore the information in intermediate layers, a multi-level prediction with attention structure is applied in our model. Furthermore, we design a mix-training strategy to break the performance limitation caused by the amount of training data. Experiments show that the mean average precision of the proposed audio classification system on Audio Set dataset is 37.2%. Without using extra training data, our system exceeds the state-of-the-art multi-level attention model.
All You Need is a Few Shifts: Designing Efficient Convolutional Neural Networks for Image Classification
Mar 13, 2019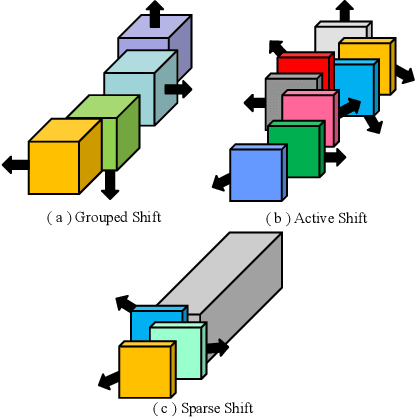
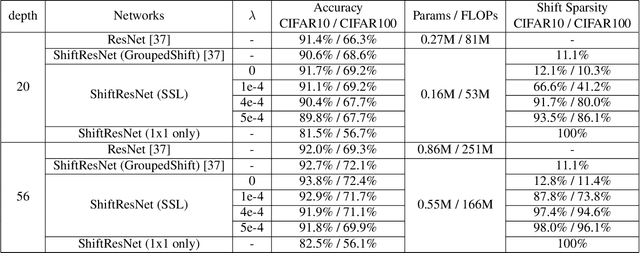

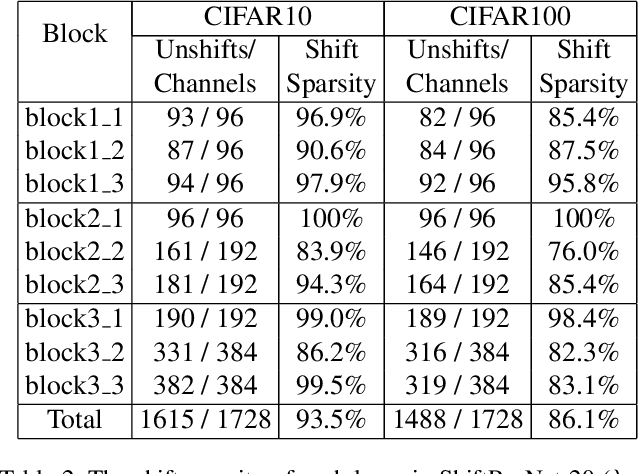
Shift operation is an efficient alternative over depthwise separable convolution. However, it is still bottlenecked by its implementation manner, namely memory movement. To put this direction forward, a new and novel basic component named Sparse Shift Layer (SSL) is introduced in this paper to construct efficient convolutional neural networks. In this family of architectures, the basic block is only composed by 1x1 convolutional layers with only a few shift operations applied to the intermediate feature maps. To make this idea feasible, we introduce shift operation penalty during optimization and further propose a quantization-aware shift learning method to impose the learned displacement more friendly for inference. Extensive ablation studies indicate that only a few shift operations are sufficient to provide spatial information communication. Furthermore, to maximize the role of SSL, we redesign an improved network architecture to Fully Exploit the limited capacity of neural Network (FE-Net). Equipped with SSL, this network can achieve 75.0% top-1 accuracy on ImageNet with only 563M M-Adds. It surpasses other counterparts constructed by depthwise separable convolution and the networks searched by NAS in terms of accuracy and practical speed.
Collaborative Spatio-temporal Feature Learning for Video Action Recognition
Mar 04, 2019
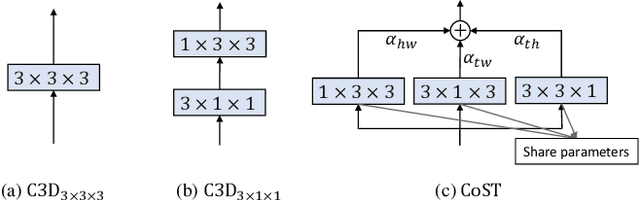
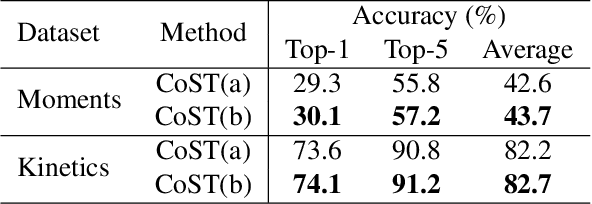
Spatio-temporal feature learning is of central importance for action recognition in videos. Existing deep neural network models either learn spatial and temporal features independently (C2D) or jointly with unconstrained parameters (C3D). In this paper, we propose a novel neural operation which encodes spatio-temporal features collaboratively by imposing a weight-sharing constraint on the learnable parameters. In particular, we perform 2D convolution along three orthogonal views of volumetric video data,which learns spatial appearance and temporal motion cues respectively. By sharing the convolution kernels of different views, spatial and temporal features are collaboratively learned and thus benefit from each other. The complementary features are subsequently fused by a weighted summation whose coefficients are learned end-to-end. Our approach achieves state-of-the-art performance on large-scale benchmarks and won the 1st place in the Moments in Time Challenge 2018. Moreover, based on the learned coefficients of different views, we are able to quantify the contributions of spatial and temporal features. This analysis sheds light on interpretability of the model and may also guide the future design of algorithm for video recognition.
A Layer Decomposition-Recomposition Framework for Neuron Pruning towards Accurate Lightweight Networks
Dec 17, 2018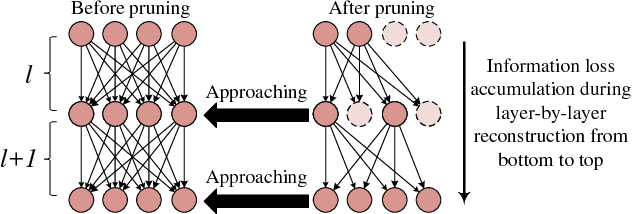
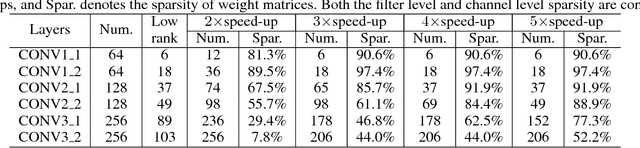
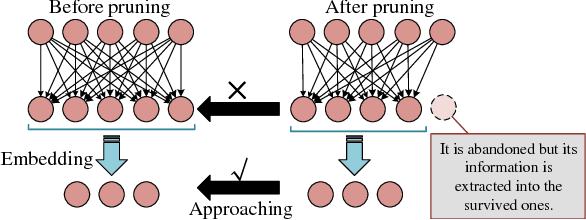
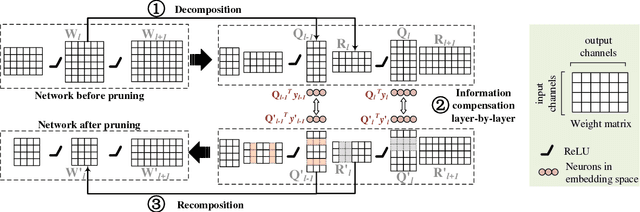
Neuron pruning is an efficient method to compress the network into a slimmer one for reducing the computational cost and storage overhead. Most of state-of-the-art results are obtained in a layer-by-layer optimization mode. It discards the unimportant input neurons and uses the survived ones to reconstruct the output neurons approaching to the original ones in a layer-by-layer manner. However, an unnoticed problem arises that the information loss is accumulated as layer increases since the survived neurons still do not encode the entire information as before. A better alternative is to propagate the entire useful information to reconstruct the pruned layer instead of directly discarding the less important neurons. To this end, we propose a novel Layer Decomposition-Recomposition Framework (LDRF) for neuron pruning, by which each layer's output information is recovered in an embedding space and then propagated to reconstruct the following pruned layers with useful information preserved. We mainly conduct our experiments on ILSVRC-12 benchmark with VGG-16 and ResNet-50. What should be emphasized is that our results before end-to-end fine-tuning are significantly superior owing to the information-preserving property of our proposed framework.With end-to-end fine-tuning, we achieve state-of-the-art results of 5.13x and 3x speed-up with only 0.5% and 0.65% top-5 accuracy drop respectively, which outperform the existing neuron pruning methods.
Learning Incremental Triplet Margin for Person Re-identification
Dec 17, 2018

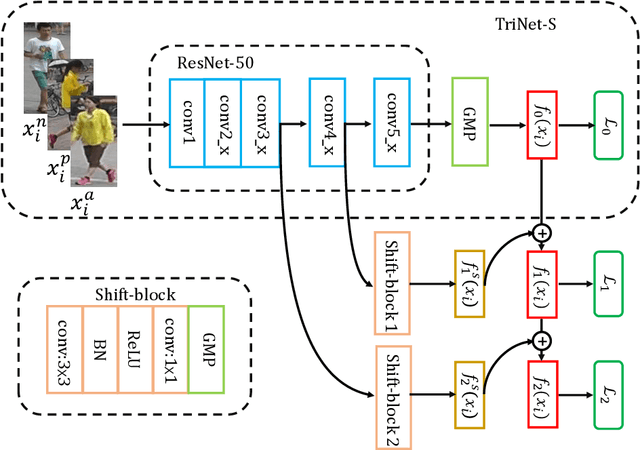

Person re-identification (ReID) aims to match people across multiple non-overlapping video cameras deployed at different locations. To address this challenging problem, many metric learning approaches have been proposed, among which triplet loss is one of the state-of-the-arts. In this work, we explore the margin between positive and negative pairs of triplets and prove that large margin is beneficial. In particular, we propose a novel multi-stage training strategy which learns incremental triplet margin and improves triplet loss effectively. Multiple levels of feature maps are exploited to make the learned features more discriminative. Besides, we introduce global hard identity searching method to sample hard identities when generating a training batch. Extensive experiments on Market-1501, CUHK03, and DukeMTMCreID show that our approach yields a performance boost and outperforms most existing state-of-the-art methods.
Attentive Sequence to Sequence Translation for Localizing Clips of Interest by Natural Language Descriptions
Aug 27, 2018
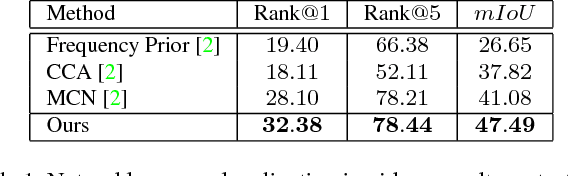
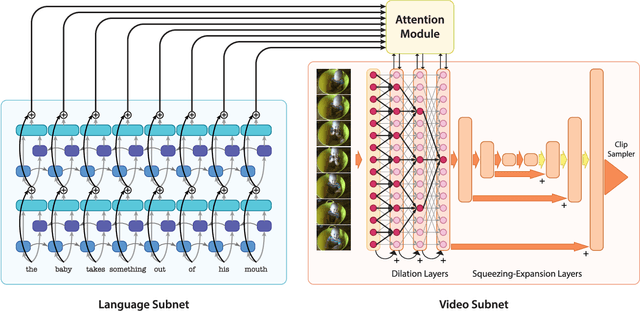
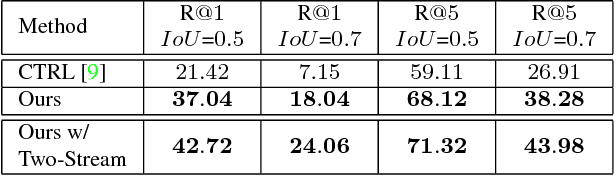
We propose a novel attentive sequence to sequence translator (ASST) for clip localization in videos by natural language descriptions. We make two contributions. First, we propose a bi-directional Recurrent Neural Network (RNN) with a finely calibrated vision-language attentive mechanism to comprehensively understand the free-formed natural language descriptions. The RNN parses natural language descriptions in two directions, and the attentive model attends every meaningful word or phrase to each frame, thereby resulting in a more detailed understanding of video content and description semantics. Second, we design a hierarchical architecture for the network to jointly model language descriptions and video content. Given a video-description pair, the network generates a matrix representation, i.e., a sequence of vectors. Each vector in the matrix represents a video frame conditioned by the description. The 2D representation not only preserves the temporal dependencies of frames but also provides an effective way to perform frame-level video-language matching. The hierarchical architecture exploits video content with multiple granularities, ranging from subtle details to global context. Integration of the multiple granularities yields a robust representation for multi-level video-language abstraction. We validate the effectiveness of our ASST on two large-scale datasets. Our ASST outperforms the state-of-the-art by $4.28\%$ in Rank$@1$ on the DiDeMo dataset. On the Charades-STA dataset, we significantly improve the state-of-the-art by $13.41\%$ in Rank$@1,IoU=0.5$.
Extreme Network Compression via Filter Group Approximation
Jul 31, 2018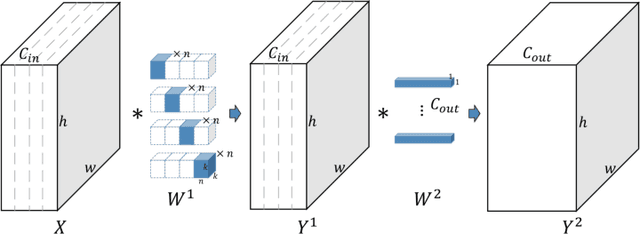

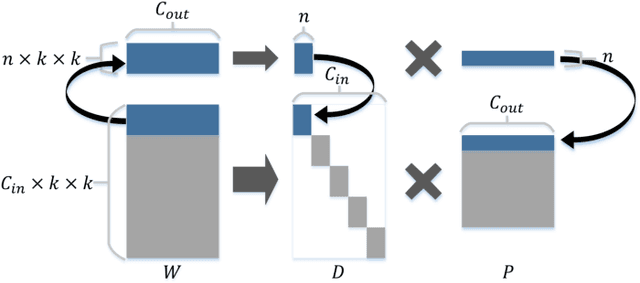
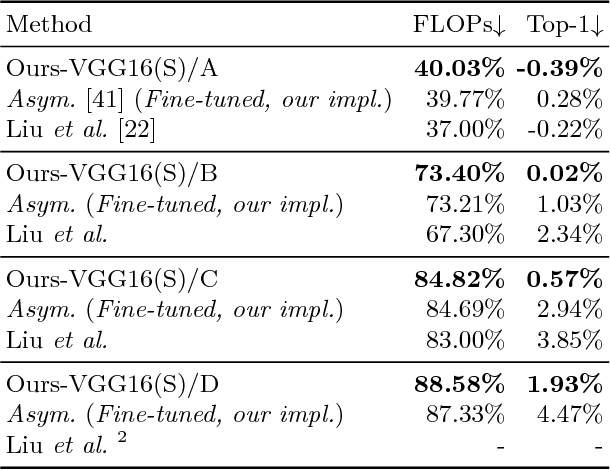
In this paper we propose a novel decomposition method based on filter group approximation, which can significantly reduce the redundancy of deep convolutional neural networks (CNNs) while maintaining the majority of feature representation. Unlike other low-rank decomposition algorithms which operate on spatial or channel dimension of filters, our proposed method mainly focuses on exploiting the filter group structure for each layer. For several commonly used CNN models, including VGG and ResNet, our method can reduce over 80% floating-point operations (FLOPs) with less accuracy drop than state-of-the-art methods on various image classification datasets. Besides, experiments demonstrate that our method is conducive to alleviating degeneracy of the compressed network, which hurts the convergence and performance of the network.
Small-scale Pedestrian Detection Based on Somatic Topology Localization and Temporal Feature Aggregation
Jul 04, 2018
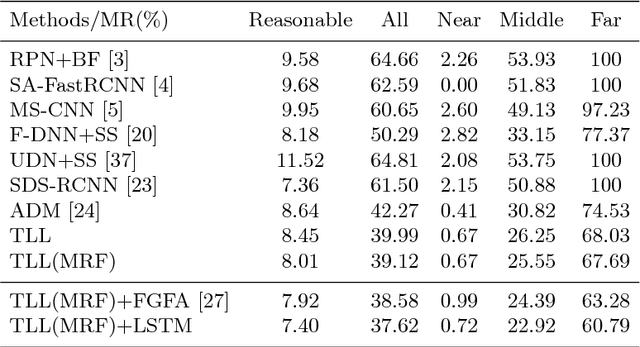
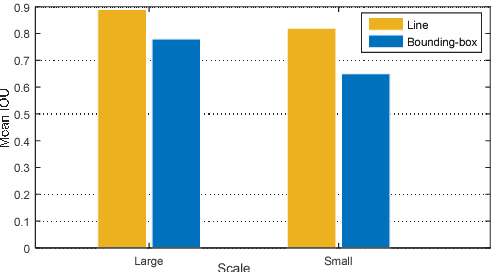
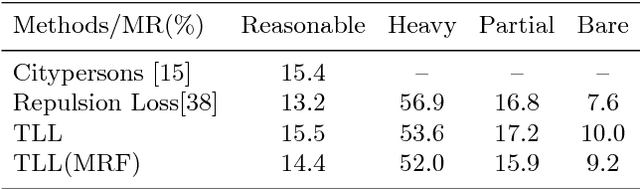
A critical issue in pedestrian detection is to detect small-scale objects that will introduce feeble contrast and motion blur in images and videos, which in our opinion should partially resort to deep-rooted annotation bias. Motivated by this, we propose a novel method integrated with somatic topological line localization (TLL) and temporal feature aggregation for detecting multi-scale pedestrians, which works particularly well with small-scale pedestrians that are relatively far from the camera. Moreover, a post-processing scheme based on Markov Random Field (MRF) is introduced to eliminate ambiguities in occlusion cases. Applying with these methodologies comprehensively, we achieve best detection performance on Caltech benchmark and improve performance of small-scale objects significantly (miss rate decreases from 74.53% to 60.79%). Beyond this, we also achieve competitive performance on CityPersons dataset and show the existence of annotation bias in KITTI dataset.
Co-occurrence Feature Learning from Skeleton Data for Action Recognition and Detection with Hierarchical Aggregation
Apr 17, 2018
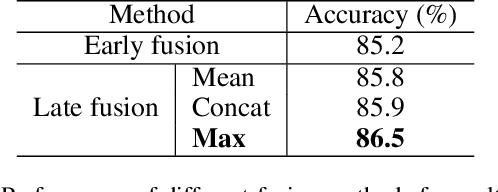
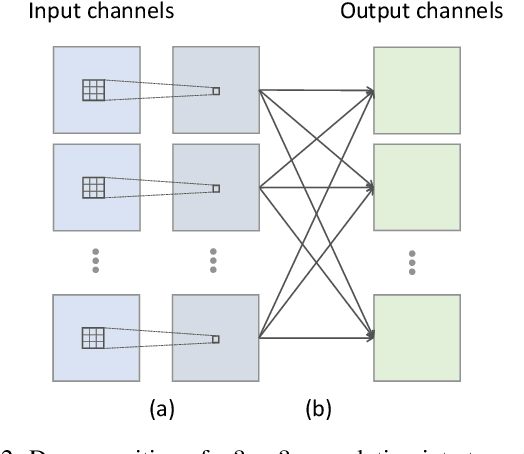
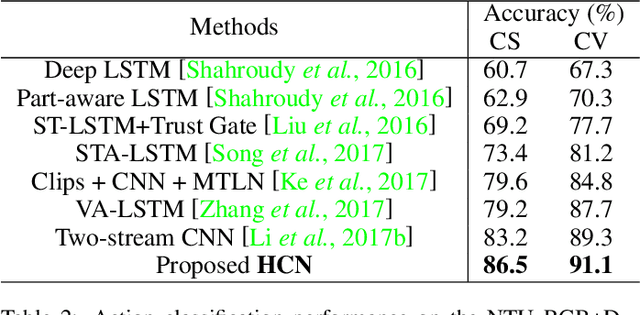
Skeleton-based human action recognition has recently drawn increasing attentions with the availability of large-scale skeleton datasets. The most crucial factors for this task lie in two aspects: the intra-frame representation for joint co-occurrences and the inter-frame representation for skeletons' temporal evolutions. In this paper we propose an end-to-end convolutional co-occurrence feature learning framework. The co-occurrence features are learned with a hierarchical methodology, in which different levels of contextual information are aggregated gradually. Firstly point-level information of each joint is encoded independently. Then they are assembled into semantic representation in both spatial and temporal domains. Specifically, we introduce a global spatial aggregation scheme, which is able to learn superior joint co-occurrence features over local aggregation. Besides, raw skeleton coordinates as well as their temporal difference are integrated with a two-stream paradigm. Experiments show that our approach consistently outperforms other state-of-the-arts on action recognition and detection benchmarks like NTU RGB+D, SBU Kinect Interaction and PKU-MMD.