 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNatural Language Does Not Emerge 'Naturally' in Multi-Agent Dialog
Aug 20, 2017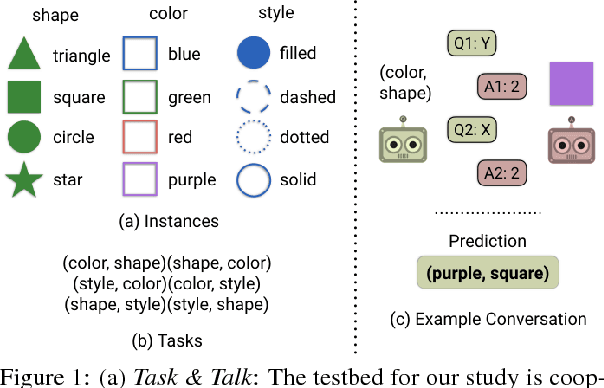
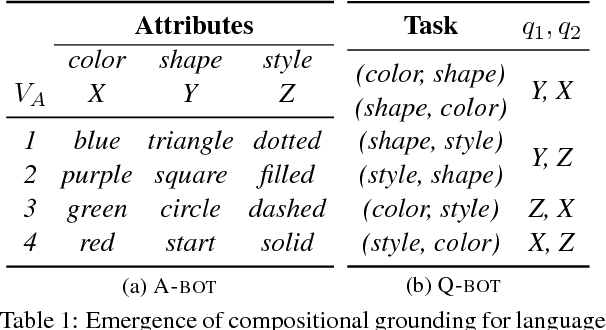
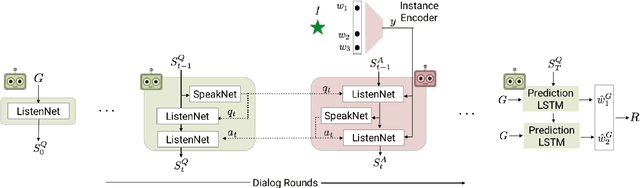
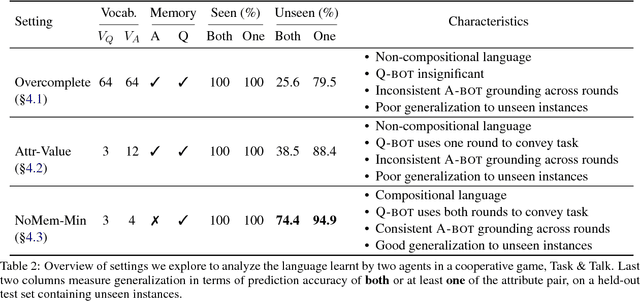
A number of recent works have proposed techniques for end-to-end learning of communication protocols among cooperative multi-agent populations, and have simultaneously found the emergence of grounded human-interpretable language in the protocols developed by the agents, all learned without any human supervision! In this paper, using a Task and Tell reference game between two agents as a testbed, we present a sequence of 'negative' results culminating in a 'positive' one -- showing that while most agent-invented languages are effective (i.e. achieve near-perfect task rewards), they are decidedly not interpretable or compositional. In essence, we find that natural language does not emerge 'naturally', despite the semblance of ease of natural-language-emergence that one may gather from recent literature. We discuss how it is possible to coax the invented languages to become more and more human-like and compositional by increasing restrictions on how two agents may communicate.
The Promise of Premise: Harnessing Question Premises in Visual Question Answering
Aug 17, 2017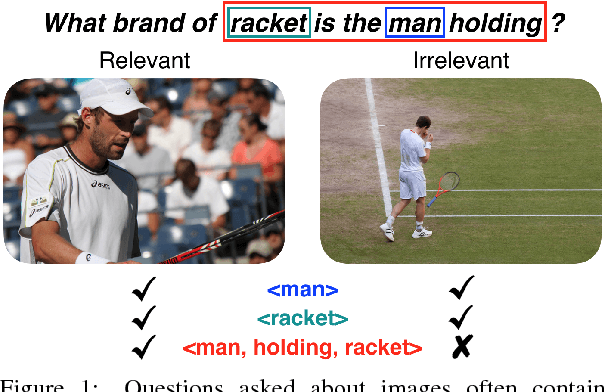
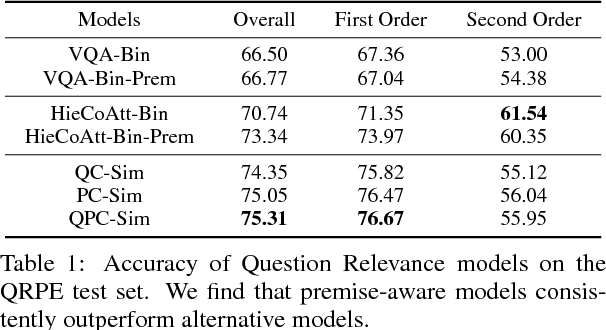
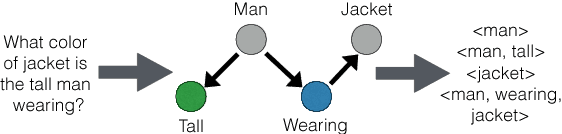
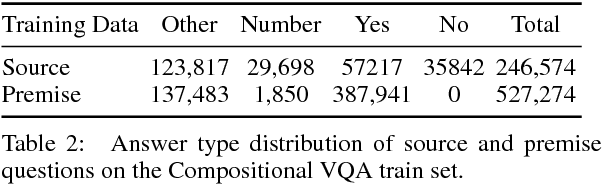
In this paper, we make a simple observation that questions about images often contain premises - objects and relationships implied by the question - and that reasoning about premises can help Visual Question Answering (VQA) models respond more intelligently to irrelevant or previously unseen questions. When presented with a question that is irrelevant to an image, state-of-the-art VQA models will still answer purely based on learned language biases, resulting in non-sensical or even misleading answers. We note that a visual question is irrelevant to an image if at least one of its premises is false (i.e. not depicted in the image). We leverage this observation to construct a dataset for Question Relevance Prediction and Explanation (QRPE) by searching for false premises. We train novel question relevance detection models and show that models that reason about premises consistently outperform models that do not. We also find that forcing standard VQA models to reason about premises during training can lead to improvements on tasks requiring compositional reasoning.
Evaluating Visual Conversational Agents via Cooperative Human-AI Games
Aug 17, 2017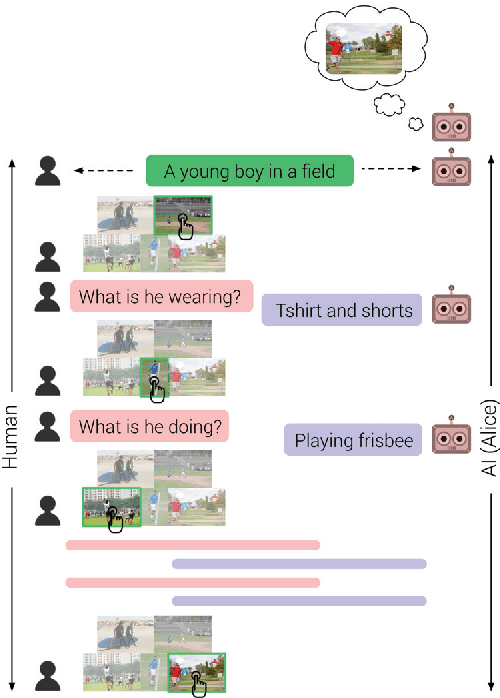


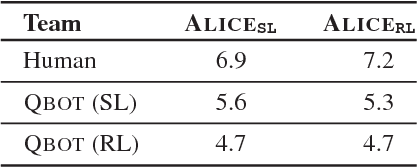
As AI continues to advance, human-AI teams are inevitable. However, progress in AI is routinely measured in isolation, without a human in the loop. It is crucial to benchmark progress in AI, not just in isolation, but also in terms of how it translates to helping humans perform certain tasks, i.e., the performance of human-AI teams. In this work, we design a cooperative game - GuessWhich - to measure human-AI team performance in the specific context of the AI being a visual conversational agent. GuessWhich involves live interaction between the human and the AI. The AI, which we call ALICE, is provided an image which is unseen by the human. Following a brief description of the image, the human questions ALICE about this secret image to identify it from a fixed pool of images. We measure performance of the human-ALICE team by the number of guesses it takes the human to correctly identify the secret image after a fixed number of dialog rounds with ALICE. We compare performance of the human-ALICE teams for two versions of ALICE. Our human studies suggest a counterintuitive trend - that while AI literature shows that one version outperforms the other when paired with an AI questioner bot, we find that this improvement in AI-AI performance does not translate to improved human-AI performance. This suggests a mismatch between benchmarking of AI in isolation and in the context of human-AI teams.
LR-GAN: Layered Recursive Generative Adversarial Networks for Image Generation
Aug 02, 2017
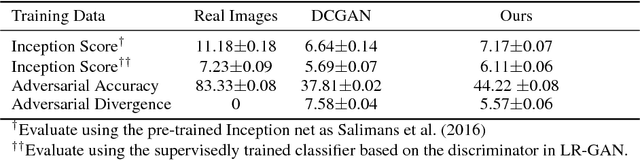
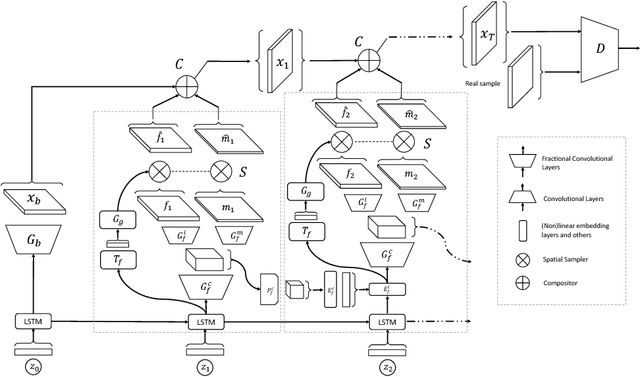

We present LR-GAN: an adversarial image generation model which takes scene structure and context into account. Unlike previous generative adversarial networks (GANs), the proposed GAN learns to generate image background and foregrounds separately and recursively, and stitch the foregrounds on the background in a contextually relevant manner to produce a complete natural image. For each foreground, the model learns to generate its appearance, shape and pose. The whole model is unsupervised, and is trained in an end-to-end manner with gradient descent methods. The experiments demonstrate that LR-GAN can generate more natural images with objects that are more human recognizable than DCGAN.
Visual Dialog
Aug 01, 2017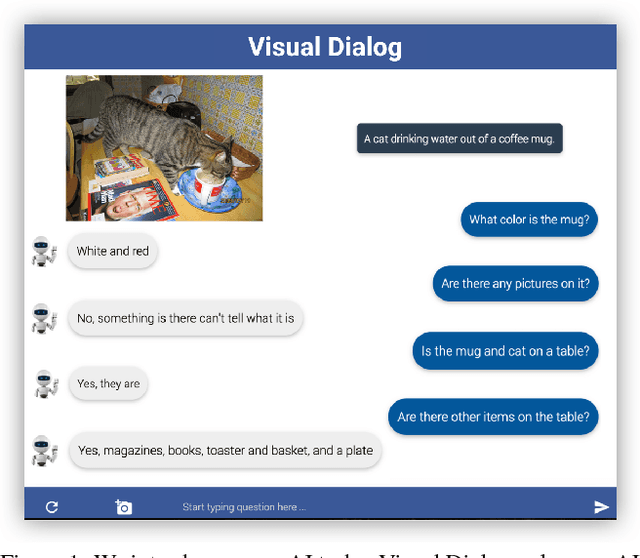
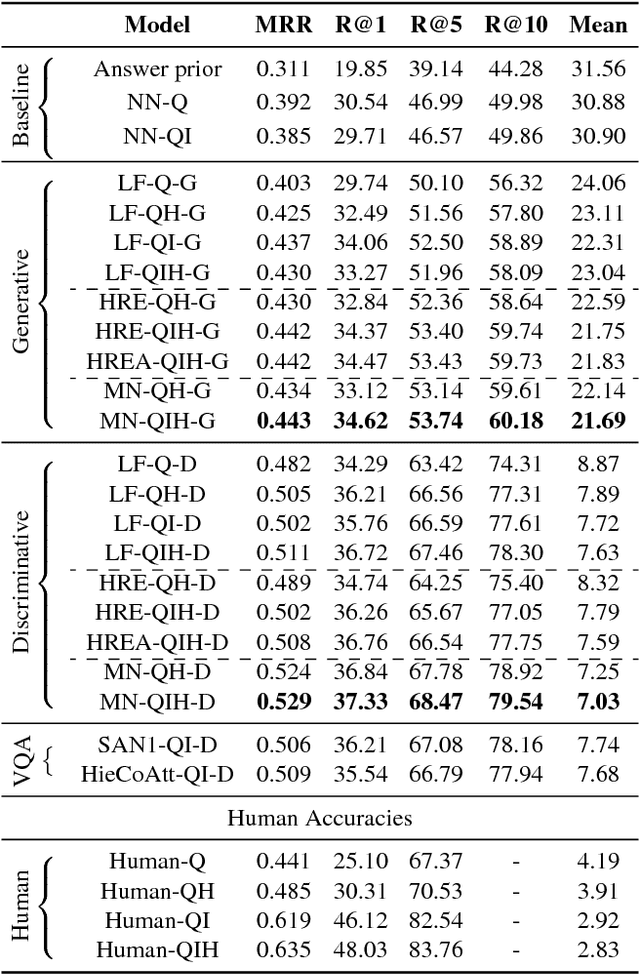


We introduce the task of Visual Dialog, which requires an AI agent to hold a meaningful dialog with humans in natural, conversational language about visual content. Specifically, given an image, a dialog history, and a question about the image, the agent has to ground the question in image, infer context from history, and answer the question accurately. Visual Dialog is disentangled enough from a specific downstream task so as to serve as a general test of machine intelligence, while being grounded in vision enough to allow objective evaluation of individual responses and benchmark progress. We develop a novel two-person chat data-collection protocol to curate a large-scale Visual Dialog dataset (VisDial). VisDial v0.9 has been released and contains 1 dialog with 10 question-answer pairs on ~120k images from COCO, with a total of ~1.2M dialog question-answer pairs. We introduce a family of neural encoder-decoder models for Visual Dialog with 3 encoders -- Late Fusion, Hierarchical Recurrent Encoder and Memory Network -- and 2 decoders (generative and discriminative), which outperform a number of sophisticated baselines. We propose a retrieval-based evaluation protocol for Visual Dialog where the AI agent is asked to sort a set of candidate answers and evaluated on metrics such as mean-reciprocal-rank of human response. We quantify gap between machine and human performance on the Visual Dialog task via human studies. Putting it all together, we demonstrate the first 'visual chatbot'! Our dataset, code, trained models and visual chatbot are available on https://visualdialog.org
Deal or No Deal? End-to-End Learning for Negotiation Dialogues
Jun 16, 2017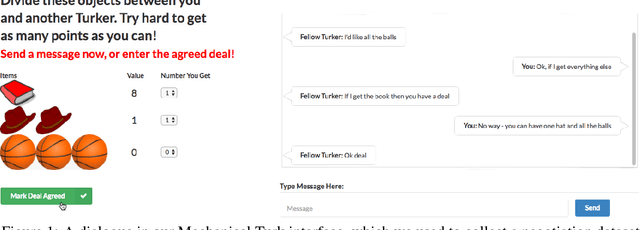
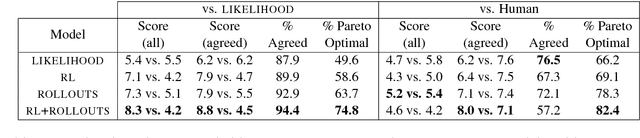
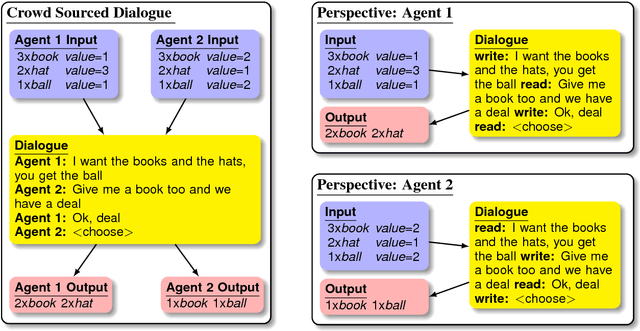
Much of human dialogue occurs in semi-cooperative settings, where agents with different goals attempt to agree on common decisions. Negotiations require complex communication and reasoning skills, but success is easy to measure, making this an interesting task for AI. We gather a large dataset of human-human negotiations on a multi-issue bargaining task, where agents who cannot observe each other's reward functions must reach an agreement (or a deal) via natural language dialogue. For the first time, we show it is possible to train end-to-end models for negotiation, which must learn both linguistic and reasoning skills with no annotated dialogue states. We also introduce dialogue rollouts, in which the model plans ahead by simulating possible complete continuations of the conversation, and find that this technique dramatically improves performance. Our code and dataset are publicly available (https://github.com/facebookresearch/end-to-end-negotiator).
Bidirectional Beam Search: Forward-Backward Inference in Neural Sequence Models for Fill-in-the-Blank Image Captioning
May 24, 2017
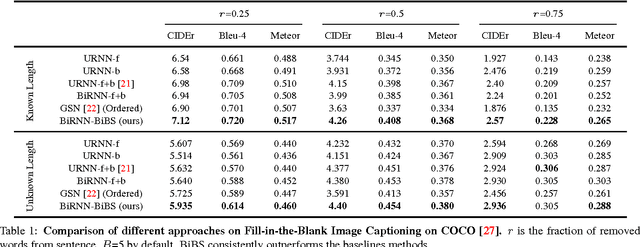
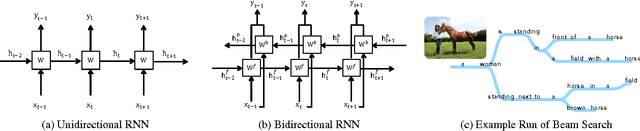
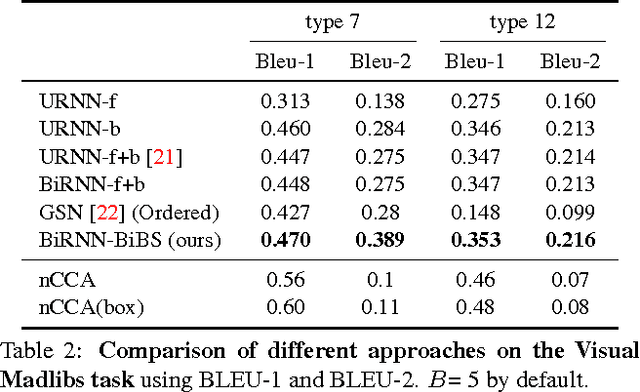
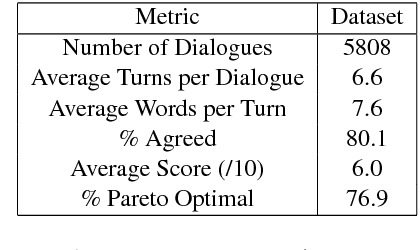
We develop the first approximate inference algorithm for 1-Best (and M-Best) decoding in bidirectional neural sequence models by extending Beam Search (BS) to reason about both forward and backward time dependencies. Beam Search (BS) is a widely used approximate inference algorithm for decoding sequences from unidirectional neural sequence models. Interestingly, approximate inference in bidirectional models remains an open problem, despite their significant advantage in modeling information from both the past and future. To enable the use of bidirectional models, we present Bidirectional Beam Search (BiBS), an efficient algorithm for approximate bidirectional inference.To evaluate our method and as an interesting problem in its own right, we introduce a novel Fill-in-the-Blank Image Captioning task which requires reasoning about both past and future sentence structure to reconstruct sensible image descriptions. We use this task as well as the Visual Madlibs dataset to demonstrate the effectiveness of our approach, consistently outperforming all baseline methods.
Making the V in VQA Matter: Elevating the Role of Image Understanding in Visual Question Answering
May 15, 2017
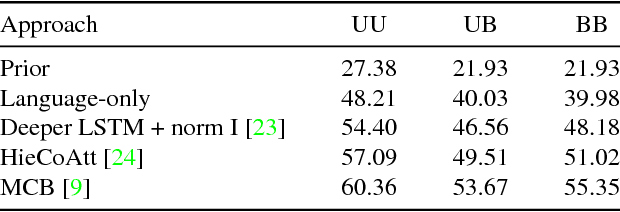
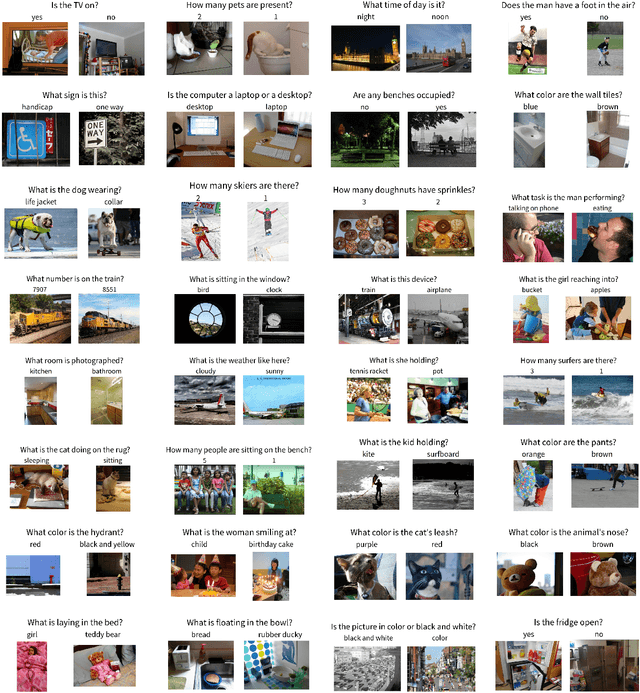
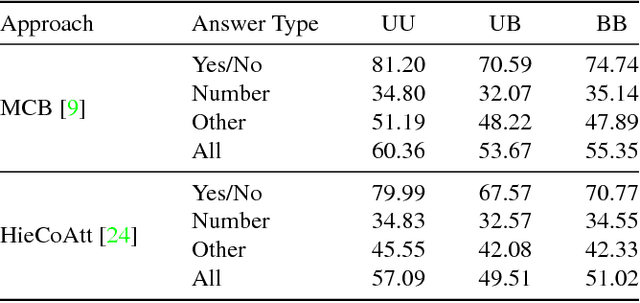
Problems at the intersection of vision and language are of significant importance both as challenging research questions and for the rich set of applications they enable. However, inherent structure in our world and bias in our language tend to be a simpler signal for learning than visual modalities, resulting in models that ignore visual information, leading to an inflated sense of their capability. We propose to counter these language priors for the task of Visual Question Answering (VQA) and make vision (the V in VQA) matter! Specifically, we balance the popular VQA dataset by collecting complementary images such that every question in our balanced dataset is associated with not just a single image, but rather a pair of similar images that result in two different answers to the question. Our dataset is by construction more balanced than the original VQA dataset and has approximately twice the number of image-question pairs. Our complete balanced dataset is publicly available at www.visualqa.org as part of the 2nd iteration of the Visual Question Answering Dataset and Challenge (VQA v2.0). We further benchmark a number of state-of-art VQA models on our balanced dataset. All models perform significantly worse on our balanced dataset, suggesting that these models have indeed learned to exploit language priors. This finding provides the first concrete empirical evidence for what seems to be a qualitative sense among practitioners. Finally, our data collection protocol for identifying complementary images enables us to develop a novel interpretable model, which in addition to providing an answer to the given (image, question) pair, also provides a counter-example based explanation. Specifically, it identifies an image that is similar to the original image, but it believes has a different answer to the same question. This can help in building trust for machines among their users.
Counting Everyday Objects in Everyday Scenes
May 09, 2017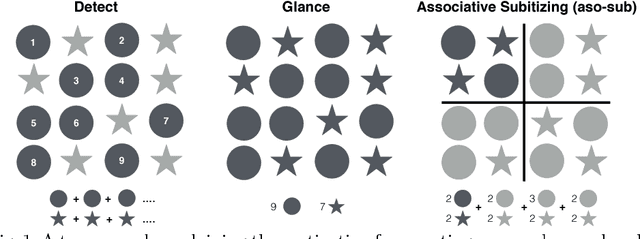
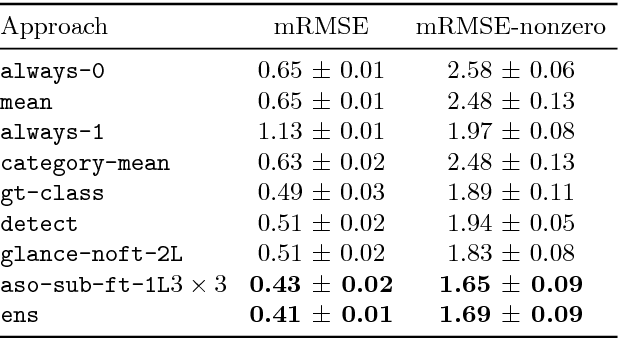
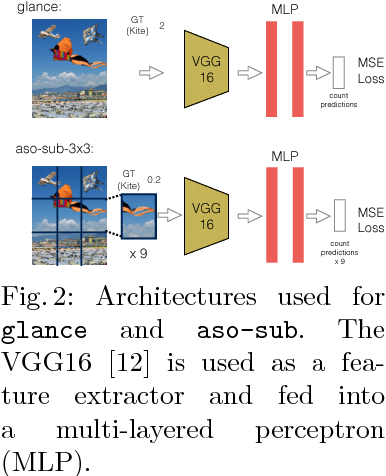
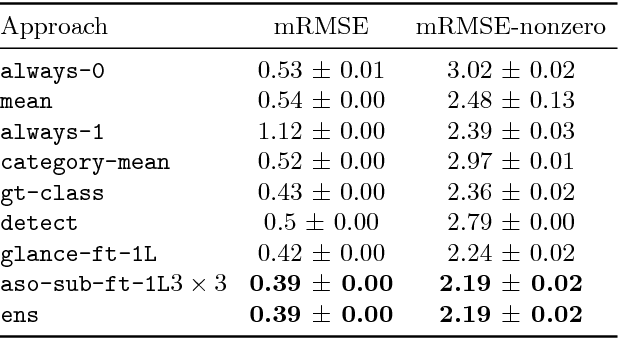
We are interested in counting the number of instances of object classes in natural, everyday images. Previous counting approaches tackle the problem in restricted domains such as counting pedestrians in surveillance videos. Counts can also be estimated from outputs of other vision tasks like object detection. In this work, we build dedicated models for counting designed to tackle the large variance in counts, appearances, and scales of objects found in natural scenes. Our approach is inspired by the phenomenon of subitizing - the ability of humans to make quick assessments of counts given a perceptual signal, for small count values. Given a natural scene, we employ a divide and conquer strategy while incorporating context across the scene to adapt the subitizing idea to counting. Our approach offers consistent improvements over numerous baseline approaches for counting on the PASCAL VOC 2007 and COCO datasets. Subsequently, we study how counting can be used to improve object detection. We then show a proof of concept application of our counting methods to the task of Visual Question Answering, by studying the `how many?' questions in the VQA and COCO-QA datasets.
C-VQA: A Compositional Split of the Visual Question Answering v1.0 Dataset
Apr 26, 2017
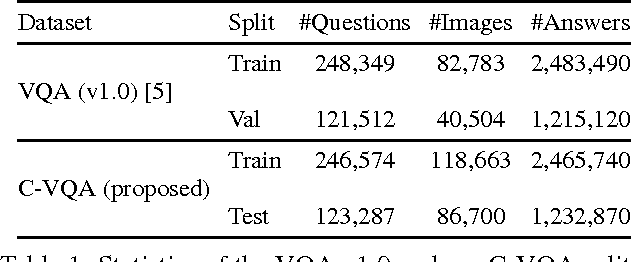
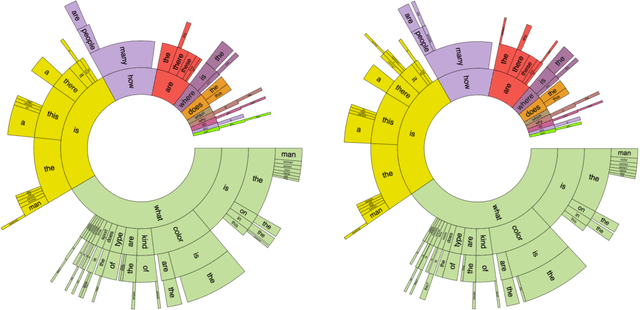
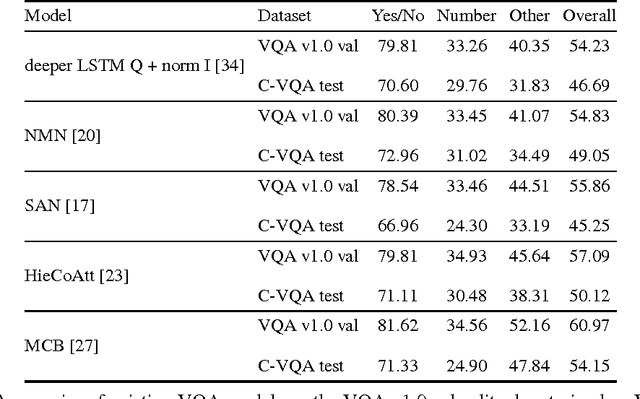
Visual Question Answering (VQA) has received a lot of attention over the past couple of years. A number of deep learning models have been proposed for this task. However, it has been shown that these models are heavily driven by superficial correlations in the training data and lack compositionality -- the ability to answer questions about unseen compositions of seen concepts. This compositionality is desirable and central to intelligence. In this paper, we propose a new setting for Visual Question Answering where the test question-answer pairs are compositionally novel compared to training question-answer pairs. To facilitate developing models under this setting, we present a new compositional split of the VQA v1.0 dataset, which we call Compositional VQA (C-VQA). We analyze the distribution of questions and answers in the C-VQA splits. Finally, we evaluate several existing VQA models under this new setting and show that the performances of these models degrade by a significant amount compared to the original VQA setting.