 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGeneralizable Human-Robot Collaborative Assembly Using Imitation Learning and Force Control
Dec 02, 2022



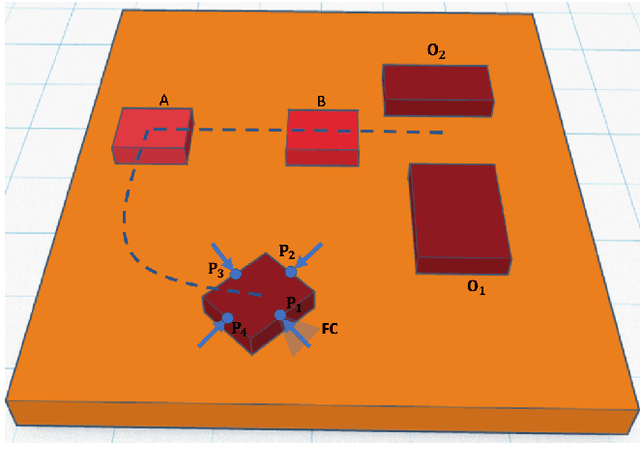
Robots have been steadily increasing their presence in our daily lives, where they can work along with humans to provide assistance in various tasks on industry floors, in offices, and in homes. Automated assembly is one of the key applications of robots, and the next generation assembly systems could become much more efficient by creating collaborative human-robot systems. However, although collaborative robots have been around for decades, their application in truly collaborative systems has been limited. This is because a truly collaborative human-robot system needs to adjust its operation with respect to the uncertainty and imprecision in human actions, ensure safety during interaction, etc. In this paper, we present a system for human-robot collaborative assembly using learning from demonstration and pose estimation, so that the robot can adapt to the uncertainty caused by the operation of humans. Learning from demonstration is used to generate motion trajectories for the robot based on the pose estimate of different goal locations from a deep learning-based vision system. The proposed system is demonstrated using a physical 6 DoF manipulator in a collaborative human-robot assembly scenario. We show successful generalization of the system's operation to changes in the initial and final goal locations through various experiments.
Active Exploration for Robotic Manipulation
Oct 23, 2022Robotic manipulation stands as a largely unsolved problem despite significant advances in robotics and machine learning in recent years. One of the key challenges in manipulation is the exploration of the dynamics of the environment when there is continuous contact between the objects being manipulated. This paper proposes a model-based active exploration approach that enables efficient learning in sparse-reward robotic manipulation tasks. The proposed method estimates an information gain objective using an ensemble of probabilistic models and deploys model predictive control (MPC) to plan actions online that maximize the expected reward while also performing directed exploration. We evaluate our proposed algorithm in simulation and on a real robot, trained from scratch with our method, on a challenging ball pushing task on tilted tables, where the target ball position is not known to the agent a-priori. Our real-world robot experiment serves as a fundamental application of active exploration in model-based reinforcement learning of complex robotic manipulation tasks.
Constrained Dynamic Movement Primitives for Safe Learning of Motor Skills
Sep 28, 2022
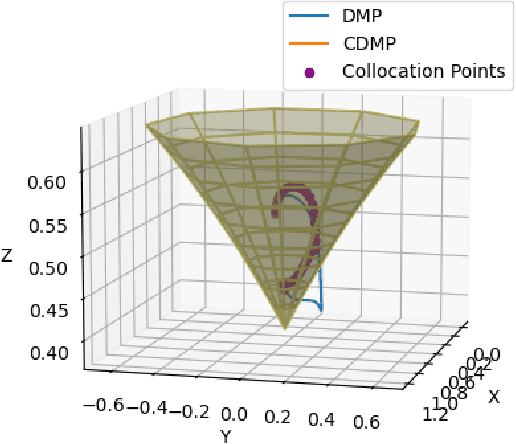
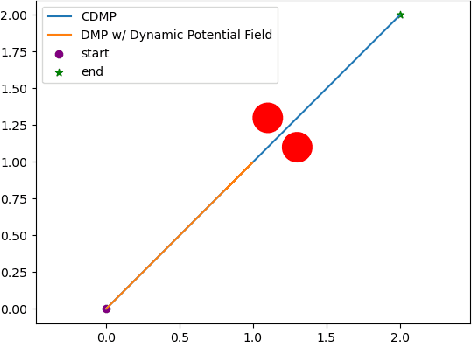
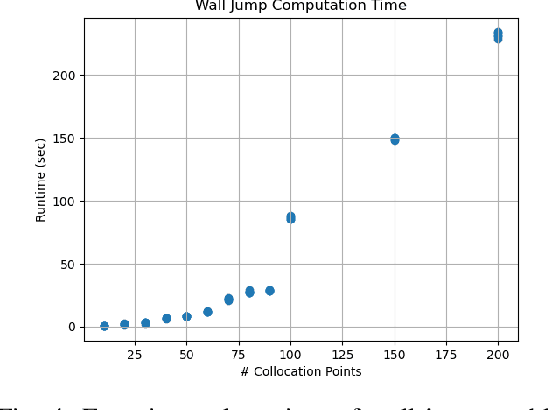
Dynamic movement primitives are widely used for learning skills which can be demonstrated to a robot by a skilled human or controller. While their generalization capabilities and simple formulation make them very appealing to use, they possess no strong guarantees to satisfy operational safety constraints for a task. In this paper, we present constrained dynamic movement primitives (CDMP) which can allow for constraint satisfaction in the robot workspace. We present a formulation of a non-linear optimization to perturb the DMP forcing weights regressed by locally-weighted regression to admit a Zeroing Barrier Function (ZBF), which certifies workspace constraint satisfaction. We demonstrate the proposed CDMP under different constraints on the end-effector movement such as obstacle avoidance and workspace constraints on a physical robot. A video showing the implementation of the proposed algorithm using different manipulators in different environments could be found here https://youtu.be/hJegJJkJfys.
Design of Adaptive Compliance Controllers for Safe Robotic Assembly
Apr 22, 2022
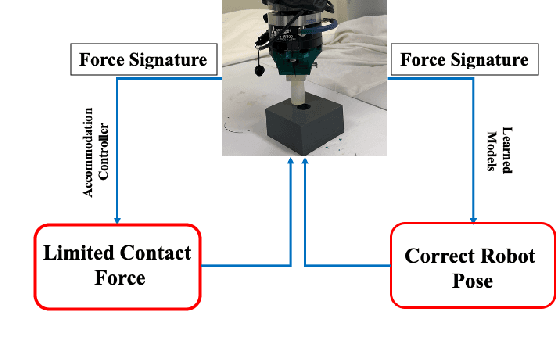
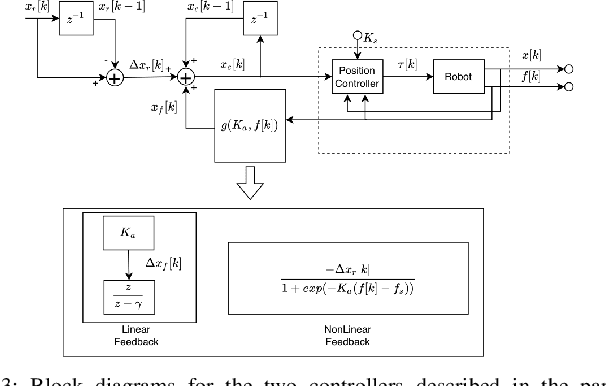
Insertion operations are a critical element of most robotic assembly operation, and peg-in-hole (PiH) insertion is one of the most widely studied tasks in the industrial and academic manipulation communities. PiH insertion is in fact an entire class of problems, where the complexity of the problem can depend on the type of misalignment and contact formation during an insertion attempt. In this paper, we present the design and analysis of adaptive compliance controllers which can be used in insertion-type assembly tasks, including learning-based compliance controllers which can be used for insertion problems in the presence of uncertainty in the goal location during robotic assembly. We first present the design of compliance controllers which can ensure safe operation of the robot by limiting experienced contact forces during contact formation. Consequently, we present analysis of the force signature obtained during the contact formation to learn the corrective action needed to perform insertion. Finally, we use the proposed compliance controllers and learned models to design a policy that can successfully perform insertion in novel test conditions with almost perfect success rate. We validate the proposed approach on a physical robotic test-bed using a 6-DoF manipulator arm.
Robust Pivoting: Exploiting Frictional Stability Using Bilevel Optimization
Mar 22, 2022
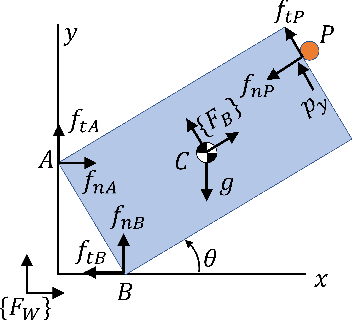
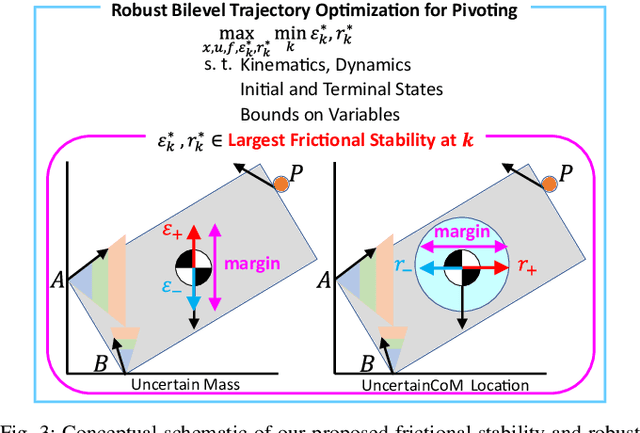
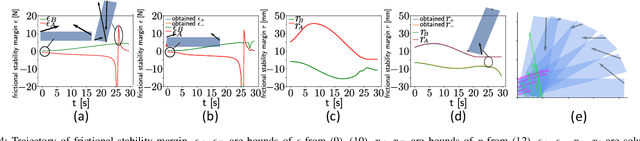
Generalizable manipulation requires that robots be able to interact with novel objects and environment. This requirement makes manipulation extremely challenging as a robot has to reason about complex frictional interaction with uncertainty in physical properties of the object. In this paper, we study robust optimization for control of pivoting manipulation in the presence of uncertainties. We present insights about how friction can be exploited to compensate for the inaccuracies in the estimates of the physical properties during manipulation. In particular, we derive analytical expressions for stability margin provided by friction during pivoting manipulation. This margin is then used in a bilevel trajectory optimization algorithm to design a controller that maximizes this stability margin to provide robustness against uncertainty in physical properties of the object. We demonstrate our proposed method using a 6 DoF manipulator for manipulating several different objects.
PYROBOCOP: Python-based Robotic Control & Optimization Package for Manipulation
Mar 18, 2022
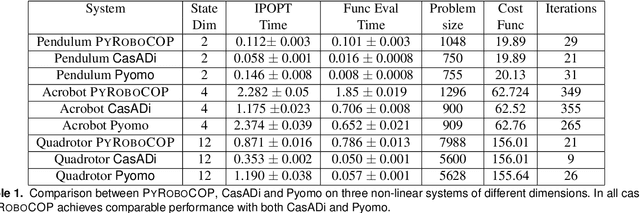
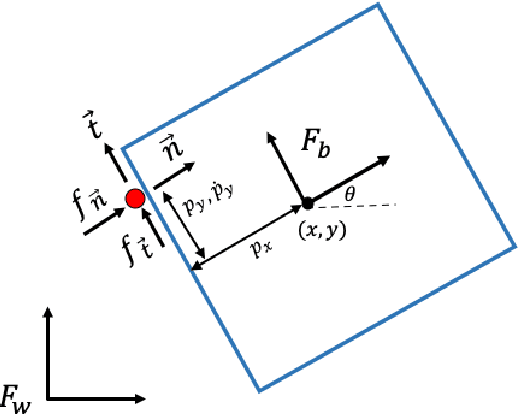
PYROBOCOP is a Python-based package for control, optimization and estimation of robotic systems described by nonlinear Differential Algebraic Equations (DAEs). In particular, the package can handle systems with contacts that are described by complementarity constraints and provides a general framework for specifying obstacle avoidance constraints. The package performs direct transcription of the DAEs into a set of nonlinear equations by performing orthogonal collocation on finite elements. PYROBOCOP provides automatic reformulation of the complementarity constraints that are tractable to NLP solvers to perform optimization of robotic systems. The package is interfaced with ADOL-C[1] for obtaining sparse derivatives by automatic differentiation and IPOPT[2] for performing optimization. We evaluate PYROBOCOP on several manipulation problems for control and estimation.
Chance-Constrained Optimization in Contact-Rich Systems for Robust Manipulation
Mar 05, 2022
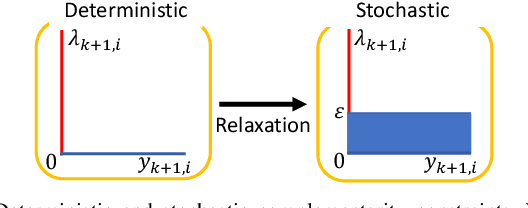
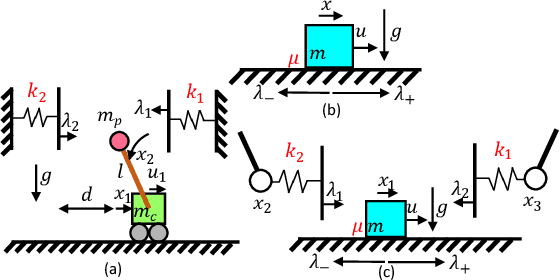
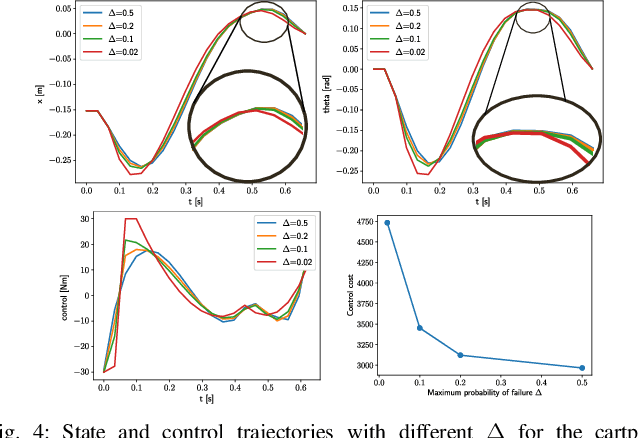
This paper presents a chance-constrained formulation for robust trajectory optimization during manipulation. In particular, we present a chance-constrained optimization for Stochastic Discrete-time Linear Complementarity Systems (SDLCS). To solve the optimization problem, we formulate Mixed-Integer Quadratic Programming with Chance Constraints (MIQPCC). In our formulation, we explicitly consider joint chance constraints for complementarity as well as states to capture the stochastic evolution of dynamics. We evaluate robustness of our optimized trajectories in simulation on several systems. The proposed approach outperforms some recent approaches for robust trajectory optimization for SDLCS.
* 9 pages, 9 figures
Imitation and Supervised Learning of Compliance for Robotic Assembly
Nov 20, 2021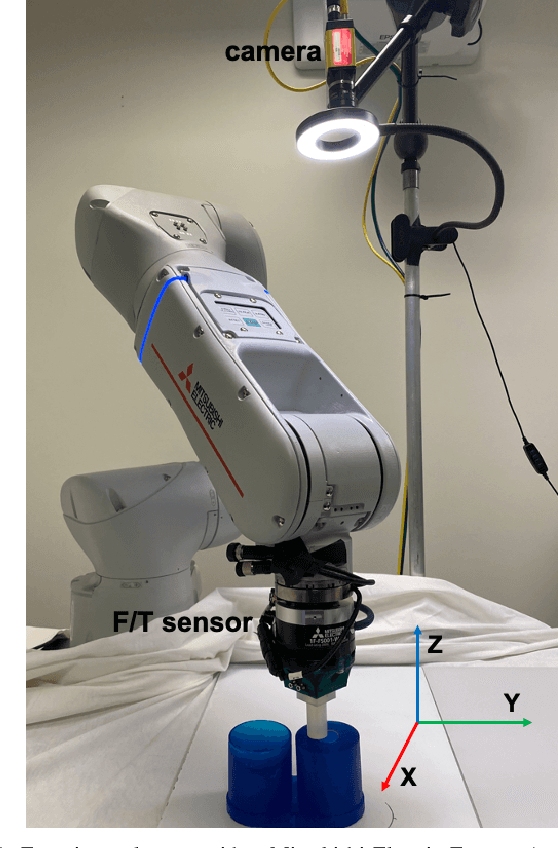
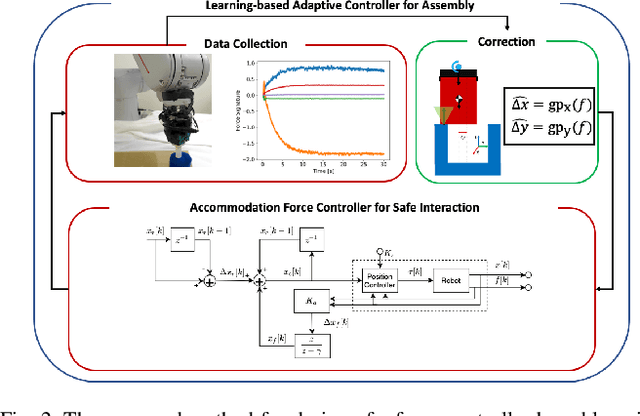
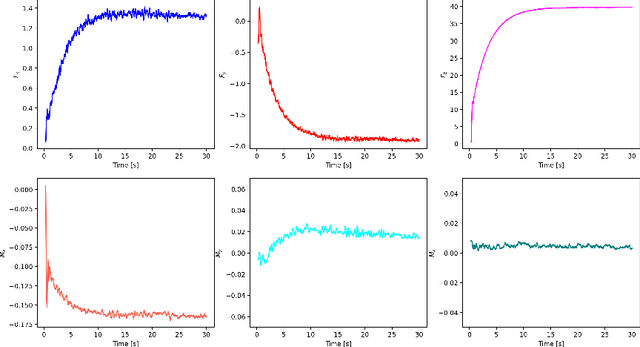
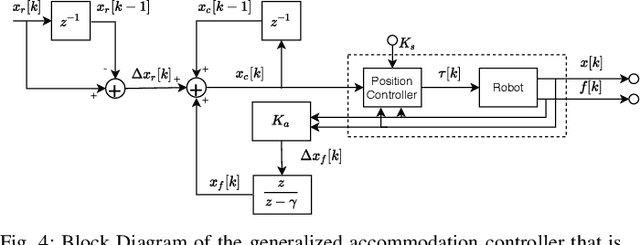
We present the design of a learning-based compliance controller for assembly operations for industrial robots. We propose a solution within the general setting of learning from demonstration (LfD), where a nominal trajectory is provided through demonstration by an expert teacher. This can be used to learn a suitable representation of the skill that can be generalized to novel positions of one of the parts involved in the assembly, for example the hole in a peg-in-hole (PiH) insertion task. Under the expectation that this novel position might not be entirely accurately estimated by a vision or other sensing system, the robot will need to further modify the generated trajectory in response to force readings measured by means of a force-torque (F/T) sensor mounted at the wrist of the robot or another suitable location. Under the assumption of constant velocity of traversing the reference trajectory during assembly, we propose a novel accommodation force controller that allows the robot to safely explore different contact configurations. The data collected using this controller is used to train a Gaussian process model to predict the misalignment in the position of the peg with respect to the target hole. We show that the proposed learning-based approach can correct various contact configurations caused by misalignment between the assembled parts in a PiH task, achieving high success rate during insertion. We show results using an industrial manipulator arm, and demonstrate that the proposed method can perform adaptive insertion using force feedback from the trained machine learning models.
Distributed Task Allocation in Homogeneous Swarms Using Language Measure Theory
Jun 25, 2021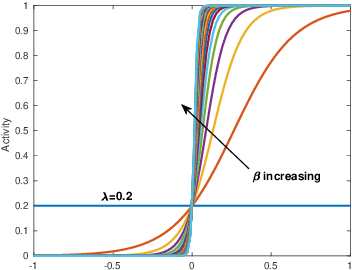
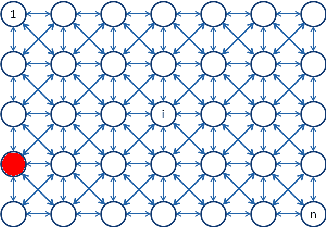
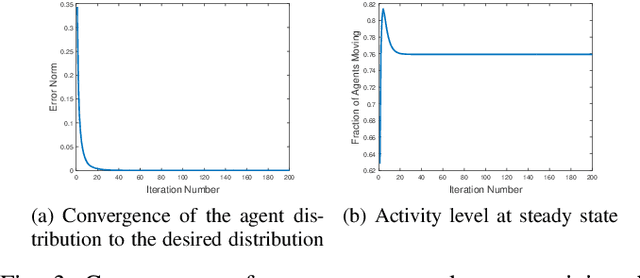
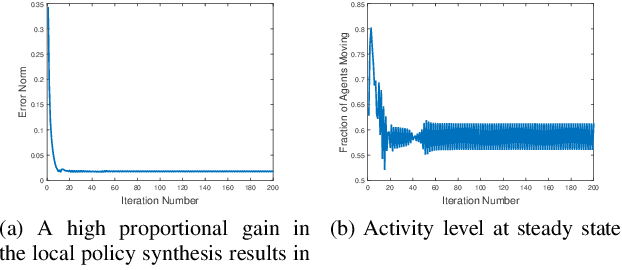
In this paper, we present algorithms for synthesizing controllers to distribute a group (possibly swarms) of homogeneous robots (agents) over heterogeneous tasks which are operated in parallel. We present algorithms as well as analysis for global and local-feedback-based controller for the swarms. Using ergodicity property of irreducible Markov chains, we design a controller for global swarm control. Furthermore, to provide some degree of autonomy to the agents, we augment this global controller by a local feedback-based controller using Language measure theory. We provide analysis of the proposed algorithms to show their correctness. Numerical experiments are shown to illustrate the performance of the proposed algorithms.
Trajectory Optimization for Manipulation of Deformable Objects: Assembly of Belt Drive Units
Jun 21, 2021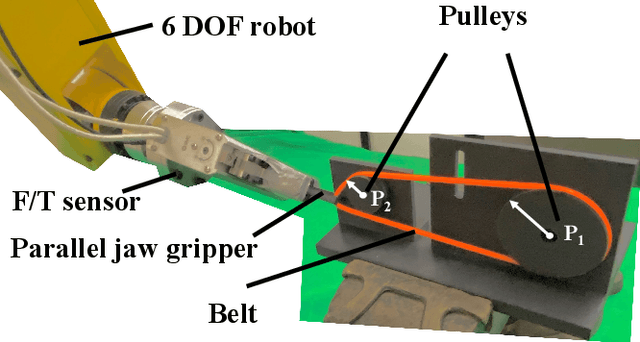
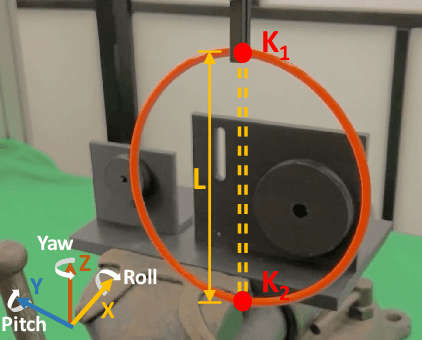
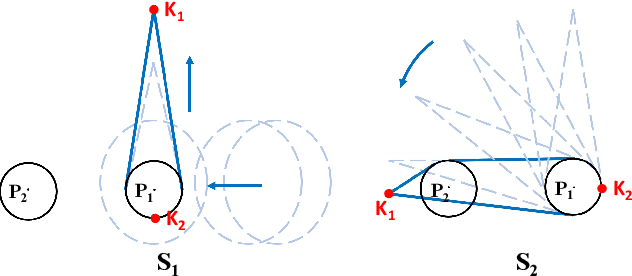
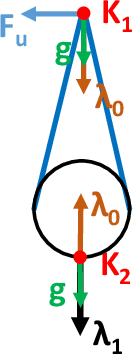
This paper presents a novel trajectory optimization formulation to solve the robotic assembly of the belt drive unit. Robotic manipulations involving contacts and deformable objects are challenging in both dynamic modeling and trajectory planning. For modeling, variations in the belt tension and contact forces between the belt and the pulley could dramatically change the system dynamics. For trajectory planning, it is computationally expensive to plan trajectories for such hybrid dynamical systems as it usually requires planning for discrete modes separately. In this work, we formulate the belt drive unit assembly task as a trajectory optimization problem with complementarity constraints to avoid explicitly imposing contact mode sequences. The problem is solved as a mathematical program with complementarity constraints (MPCC) to obtain feasible and efficient assembly trajectories. We validate the proposed method both in simulations with a physics engine and in real-world experiments with a robotic manipulator.