 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Rich Nearest Neighbor Representations from Self-supervised Ensembles
Oct 19, 2021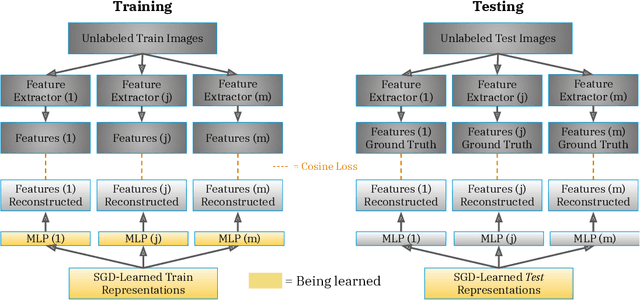
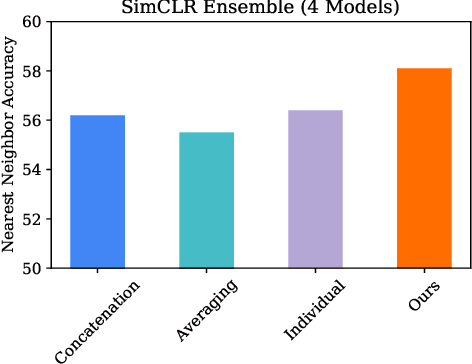
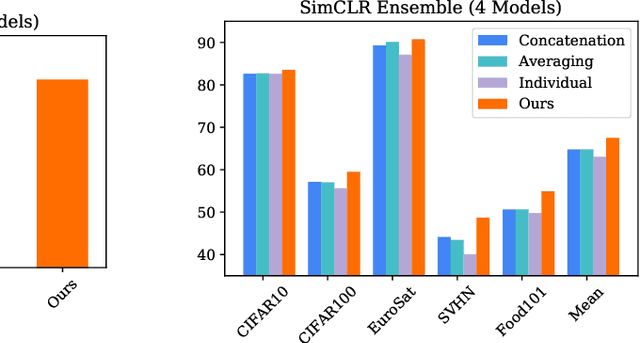
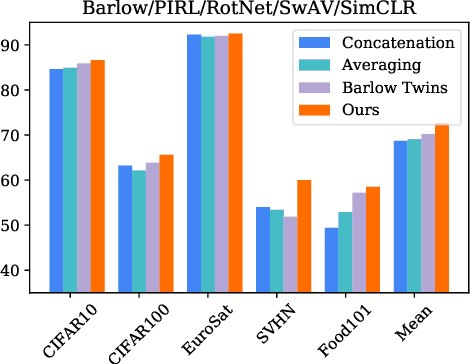
Pretraining convolutional neural networks via self-supervision, and applying them in transfer learning, is an incredibly fast-growing field that is rapidly and iteratively improving performance across practically all image domains. Meanwhile, model ensembling is one of the most universally applicable techniques in supervised learning literature and practice, offering a simple solution to reliably improve performance. But how to optimally combine self-supervised models to maximize representation quality has largely remained unaddressed. In this work, we provide a framework to perform self-supervised model ensembling via a novel method of learning representations directly through gradient descent at inference time. This technique improves representation quality, as measured by k-nearest neighbors, both on the in-domain dataset and in the transfer setting, with models transferable from the former setting to the latter. Additionally, this direct learning of feature through backpropagation improves representations from even a single model, echoing the improvements found in self-distillation.
Merlion: A Machine Learning Library for Time Series
Sep 20, 2021
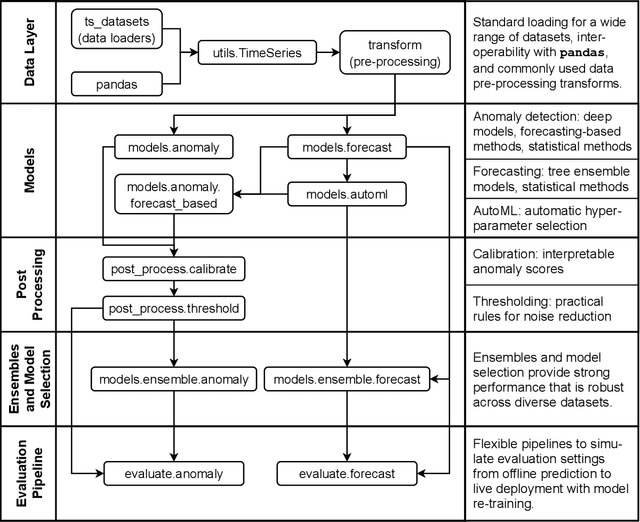
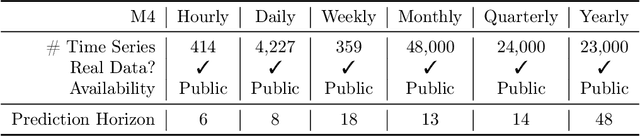

We introduce Merlion, an open-source machine learning library for time series. It features a unified interface for many commonly used models and datasets for anomaly detection and forecasting on both univariate and multivariate time series, along with standard pre/post-processing layers. It has several modules to improve ease-of-use, including visualization, anomaly score calibration to improve interpetability, AutoML for hyperparameter tuning and model selection, and model ensembling. Merlion also provides a unique evaluation framework that simulates the live deployment and re-training of a model in production. This library aims to provide engineers and researchers a one-stop solution to rapidly develop models for their specific time series needs and benchmark them across multiple time series datasets. In this technical report, we highlight Merlion's architecture and major functionalities, and we report benchmark numbers across different baseline models and ensembles.
Catastrophic Fisher Explosion: Early Phase Fisher Matrix Impacts Generalization
Dec 28, 2020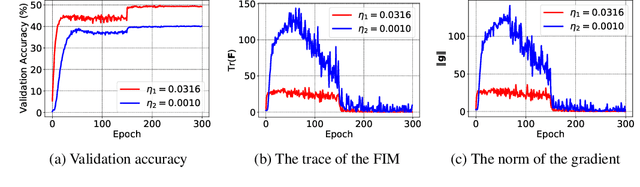
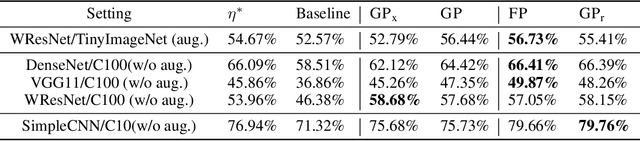
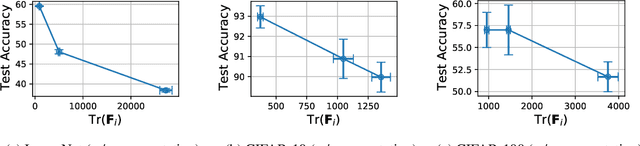
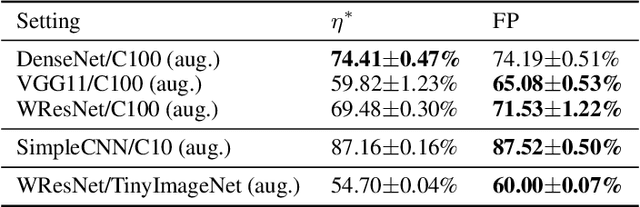
The early phase of training has been shown to be important in two ways for deep neural networks. First, the degree of regularization in this phase significantly impacts the final generalization. Second, it is accompanied by a rapid change in the local loss curvature influenced by regularization choices. Connecting these two findings, we show that stochastic gradient descent (SGD) implicitly penalizes the trace of the Fisher Information Matrix (FIM) from the beginning of training. We argue it is an implicit regularizer in SGD by showing that explicitly penalizing the trace of the FIM can significantly improve generalization. We further show that the early value of the trace of the FIM correlates strongly with the final generalization. We highlight that in the absence of implicit or explicit regularization, the trace of the FIM can increase to a large value early in training, to which we refer as catastrophic Fisher explosion. Finally, to gain insight into the regularization effect of penalizing the trace of the FIM, we show that 1) it limits memorization by reducing the learning speed of examples with noisy labels more than that of the clean examples, and 2) trajectories with a low initial trace of the FIM end in flat minima, which are commonly associated with good generalization.
The Break-Even Point on Optimization Trajectories of Deep Neural Networks
Feb 21, 2020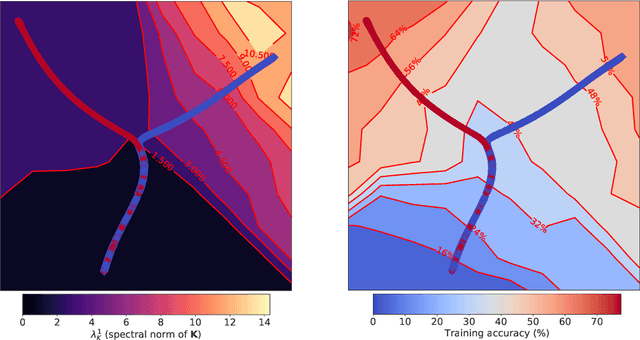
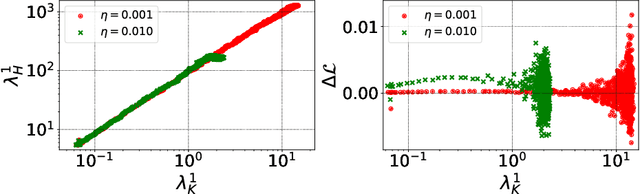

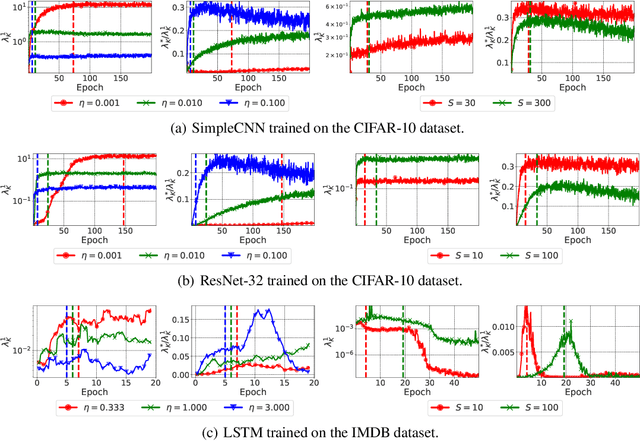
The early phase of training of deep neural networks is critical for their final performance. In this work, we study how the hyperparameters of stochastic gradient descent (SGD) used in the early phase of training affect the rest of the optimization trajectory. We argue for the existence of the "break-even" point on this trajectory, beyond which the curvature of the loss surface and noise in the gradient are implicitly regularized by SGD. In particular, we demonstrate on multiple classification tasks that using a large learning rate in the initial phase of training reduces the variance of the gradient, and improves the conditioning of the covariance of gradients. These effects are beneficial from the optimization perspective and become visible after the break-even point. Complementing prior work, we also show that using a low learning rate results in bad conditioning of the loss surface even for a neural network with batch normalization layers. In short, our work shows that key properties of the loss surface are strongly influenced by SGD in the early phase of training. We argue that studying the impact of the identified effects on generalization is a promising future direction.
Neural Bayes: A Generic Parameterization Method for Unsupervised Representation Learning
Feb 20, 2020
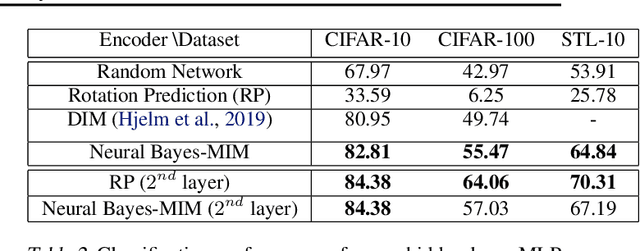
We introduce a parameterization method called Neural Bayes which allows computing statistical quantities that are in general difficult to compute and opens avenues for formulating new objectives for unsupervised representation learning. Specifically, given an observed random variable $\mathbf{x}$ and a latent discrete variable $z$, we can express $p(\mathbf{x}|z)$, $p(z|\mathbf{x})$ and $p(z)$ in closed form in terms of a sufficiently expressive function (Eg. neural network) using our parameterization without restricting the class of these distributions. To demonstrate its usefulness, we develop two independent use cases for this parameterization: 1. Mutual Information Maximization (MIM): MIM has become a popular means for self-supervised representation learning. Neural Bayes allows us to compute mutual information between observed random variables $\mathbf{x}$ and latent discrete random variables $z$ in closed form. We use this for learning image representations and show its usefulness on downstream classification tasks. 2. Disjoint Manifold Labeling: Neural Bayes allows us to formulate an objective which can optimally label samples from disjoint manifolds present in the support of a continuous distribution. This can be seen as a specific form of clustering where each disjoint manifold in the support is a separate cluster. We design clustering tasks that obey this formulation and empirically show that the model optimally labels the disjoint manifolds. Our code is available at \url{https://github.com/salesforce/NeuralBayes}
Entropy Penalty: Towards Generalization Beyond the IID Assumption
Oct 01, 2019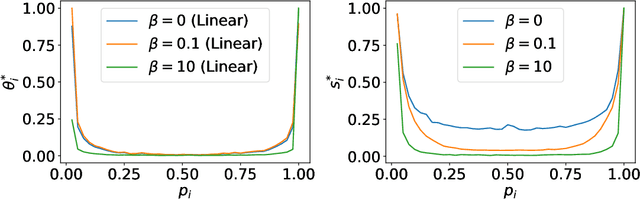
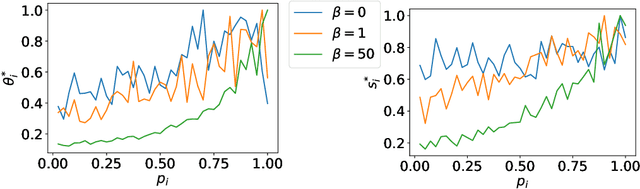
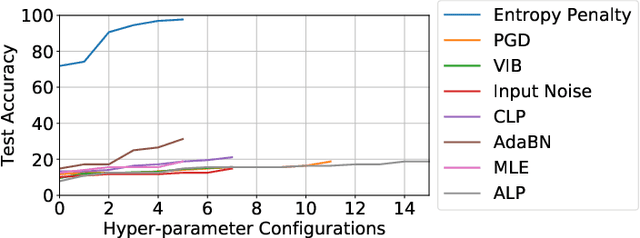
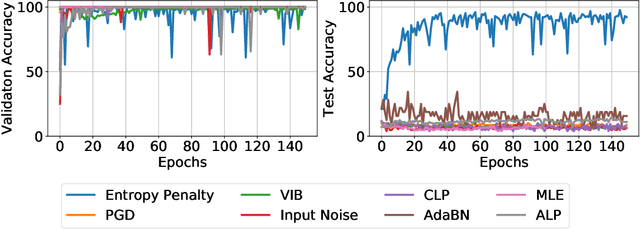
It has been shown that instead of learning actual object features, deep networks tend to exploit non-robust (spurious) discriminative features that are shared between training and test sets. Therefore, while they achieve state of the art performance on such test sets, they achieve poor generalization on out of distribution (OOD) samples where the IID (independent, identical distribution) assumption breaks and the distribution of non-robust features shifts. Through theoretical and empirical analysis, we show that this happens because maximum likelihood training (without appropriate regularization) leads the model to depend on all the correlations (including spurious ones) present between inputs and targets in the dataset. We then show evidence that the information bottleneck (IB) principle can address this problem. To do so, we propose a regularization approach based on IB, called Entropy Penalty, that reduces the model's dependence on spurious features-- features corresponding to such spurious correlations. This allows deep networks trained with Entropy Penalty to generalize well even under distribution shift of spurious features. As a controlled test-bed for evaluating our claim, we train deep networks with Entropy Penalty on a colored MNIST (C-MNIST) dataset and show that it is able to generalize well on vanilla MNIST, MNIST-M and SVHN datasets in addition to an OOD version of C-MNIST itself. The baseline regularization methods we compare against fail to generalize on this test-bed. Our code is available at https://github.com/salesforce/EntropyPenalty.
How to Initialize your Network? Robust Initialization for WeightNorm & ResNets
Jun 05, 2019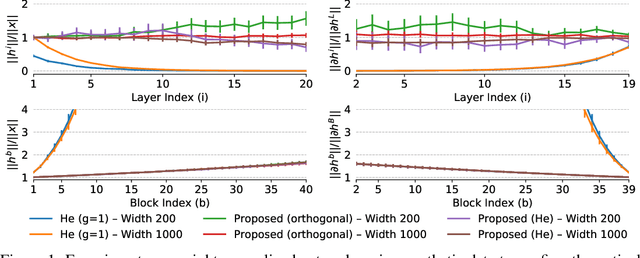
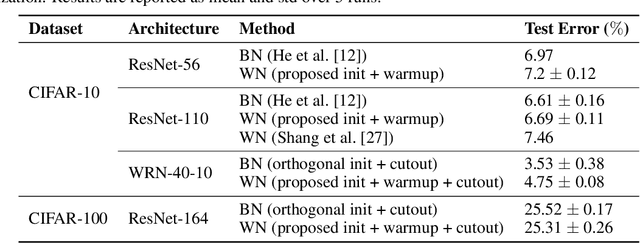
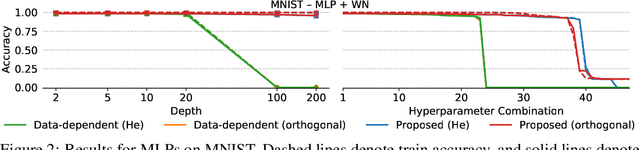

Residual networks (ResNet) and weight normalization play an important role in various deep learning applications. However, parameter initialization strategies have not been studied previously for weight normalized networks and, in practice, initialization methods designed for un-normalized networks are used as a proxy. Similarly, initialization for ResNets have also been studied for un-normalized networks and often under simplified settings ignoring the shortcut connection. To address these issues, we propose a novel parameter initialization strategy that avoids explosion/vanishment of information across layers for weight normalized networks with and without residual connections. The proposed strategy is based on a theoretical analysis using mean field approximation. We run over 2,500 experiments and evaluate our proposal on image datasets showing that the proposed initialization outperforms existing initialization methods in terms of generalization performance, robustness to hyper-parameter values and variance between seeds, especially when networks get deeper in which case existing methods fail to even start training. Finally, we show that using our initialization in conjunction with learning rate warmup is able to reduce the gap between the performance of weight normalized and batch normalized networks.
The Benefits of Over-parameterization at Initialization in Deep ReLU Networks
Jan 11, 2019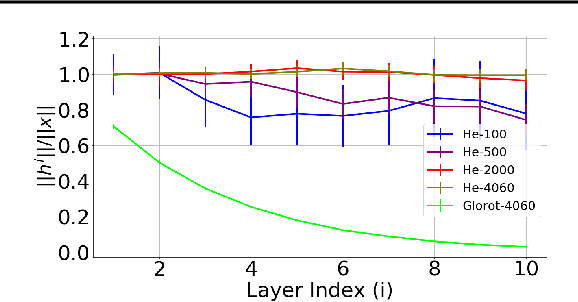
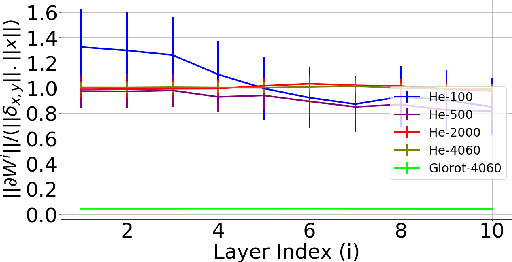
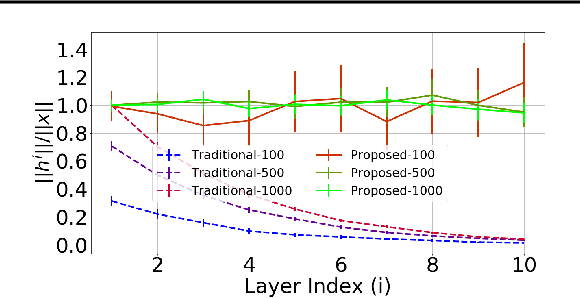
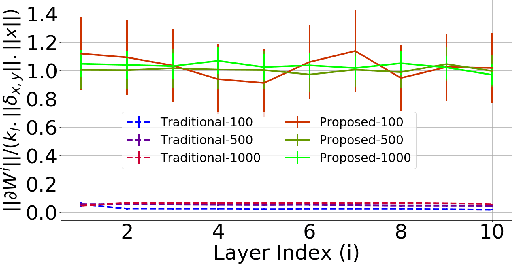
It has been noted in existing literature that over-parameterization in ReLU networks generally leads to better performance. While there could be several reasons for this, we investigate desirable network properties at initialization which may be enjoyed by ReLU networks. Without making any assumption, we derive a lower bound on the layer width of deep ReLU networks whose weights are initialized from a certain distribution, such that with high probability, i) the norm of hidden activation of all layers are roughly equal to the norm of the input, and, ii) the norm of parameter gradient for all the layers are roughly the same. In this way, sufficiently wide deep ReLU nets with appropriate initialization can inherently preserve the forward flow of information and also avoid the gradient exploding/vanishing problem. We further show that these results hold for an infinite number of data samples, in which case the finite lower bound depends on the input dimensionality and the depth of the network. In the case of deep ReLU networks with weight vectors normalized by their norm, we derive an initialization required to tap the aforementioned benefits from over-parameterization without which network fails to learn for large depth.
On the Spectral Bias of Neural Networks
Oct 17, 2018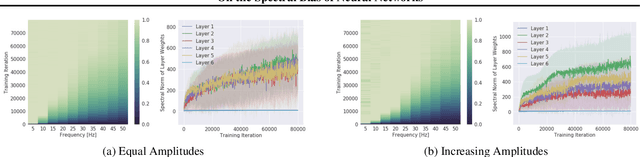
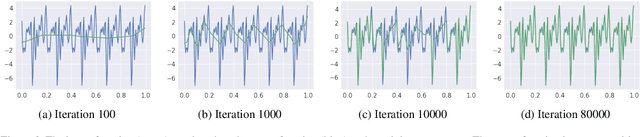
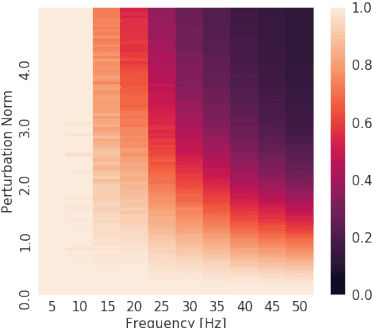
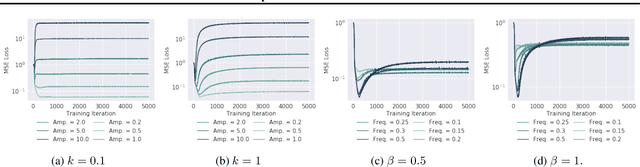
Neural networks are known to be a class of highly expressive functions able to fit even random input-output mappings with $100\%$ accuracy. In this work, we present properties of neural networks that complement this aspect of expressivity. By using tools from Fourier analysis, we show that deep ReLU networks are biased towards low frequency functions, meaning that they cannot have local fluctuations without affecting their global behavior. Intuitively, this property is in line with the observation that over-parameterized networks find simple patterns that generalize across data samples. We also investigate how the shape of the data manifold affects expressivity by showing evidence that learning high frequencies gets \emph{easier} with increasing manifold complexity, and present a theoretical understanding of this behavior. Finally, we study the robustness of the frequency components with respect to parameter perturbation, to develop the intuition that the parameters must be finely tuned to express high frequency functions.
Three Factors Influencing Minima in SGD
Sep 13, 2018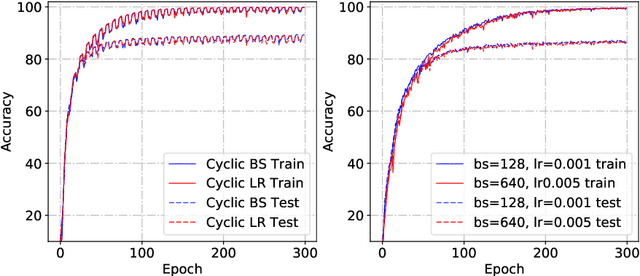
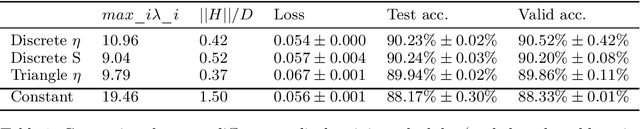
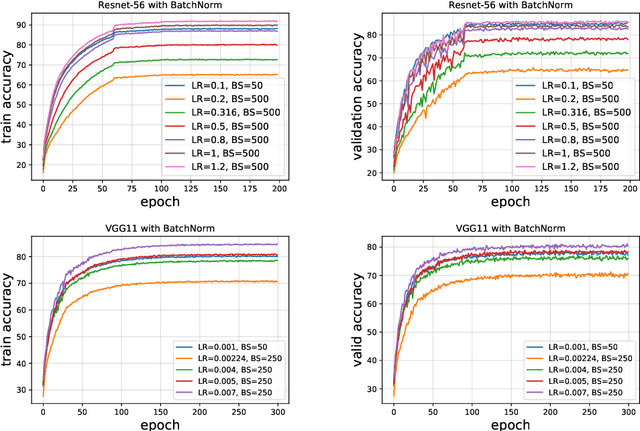
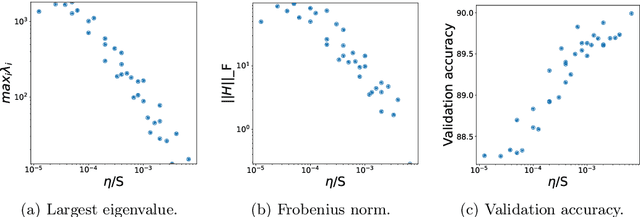
We investigate the dynamical and convergent properties of stochastic gradient descent (SGD) applied to Deep Neural Networks (DNNs). Characterizing the relation between learning rate, batch size and the properties of the final minima, such as width or generalization, remains an open question. In order to tackle this problem we investigate the previously proposed approximation of SGD by a stochastic differential equation (SDE). We theoretically argue that three factors - learning rate, batch size and gradient covariance - influence the minima found by SGD. In particular we find that the ratio of learning rate to batch size is a key determinant of SGD dynamics and of the width of the final minima, and that higher values of the ratio lead to wider minima and often better generalization. We confirm these findings experimentally. Further, we include experiments which show that learning rate schedules can be replaced with batch size schedules and that the ratio of learning rate to batch size is an important factor influencing the memorization process.