 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDetecting Vulnerable Nodes in Urban Infrastructure Interdependent Network
Aug 01, 2023Understanding and characterizing the vulnerability of urban infrastructures, which refers to the engineering facilities essential for the regular running of cities and that exist naturally in the form of networks, is of great value to us. Potential applications include protecting fragile facilities and designing robust topologies, etc. Due to the strong correlation between different topological characteristics and infrastructure vulnerability and their complicated evolution mechanisms, some heuristic and machine-assisted analysis fall short in addressing such a scenario. In this paper, we model the interdependent network as a heterogeneous graph and propose a system based on graph neural network with reinforcement learning, which can be trained on real-world data, to characterize the vulnerability of the city system accurately. The presented system leverages deep learning techniques to understand and analyze the heterogeneous graph, which enables us to capture the risk of cascade failure and discover vulnerable infrastructures of cities. Extensive experiments with various requests demonstrate not only the expressive power of our system but also transferring ability and necessity of the specific components.
Road Planning for Slums via Deep Reinforcement Learning
May 22, 2023Millions of slum dwellers suffer from poor accessibility to urban services due to inadequate road infrastructure within slums, and road planning for slums is critical to the sustainable development of cities. Existing re-blocking or heuristic methods are either time-consuming which cannot generalize to different slums, or yield sub-optimal road plans in terms of accessibility and construction costs. In this paper, we present a deep reinforcement learning based approach to automatically layout roads for slums. We propose a generic graph model to capture the topological structure of a slum, and devise a novel graph neural network to select locations for the planned roads. Through masked policy optimization, our model can generate road plans that connect places in a slum at minimal construction costs. Extensive experiments on real-world slums in different countries verify the effectiveness of our model, which can significantly improve accessibility by 14.3% against existing baseline methods. Further investigations on transferring across different tasks demonstrate that our model can master road planning skills in simple scenarios and adapt them to much more complicated ones, indicating the potential of applying our model in real-world slum upgrading.
Spatio-temporal Diffusion Point Processes
May 21, 2023



Spatio-temporal point process (STPP) is a stochastic collection of events accompanied with time and space. Due to computational complexities, existing solutions for STPPs compromise with conditional independence between time and space, which consider the temporal and spatial distributions separately. The failure to model the joint distribution leads to limited capacities in characterizing the spatio-temporal entangled interactions given past events. In this work, we propose a novel parameterization framework for STPPs, which leverages diffusion models to learn complex spatio-temporal joint distributions. We decompose the learning of the target joint distribution into multiple steps, where each step can be faithfully described by a Gaussian distribution. To enhance the learning of each step, an elaborated spatio-temporal co-attention module is proposed to capture the interdependence between the event time and space adaptively. For the first time, we break the restrictions on spatio-temporal dependencies in existing solutions, and enable a flexible and accurate modeling paradigm for STPPs. Extensive experiments from a wide range of fields, such as epidemiology, seismology, crime, and urban mobility, demonstrate that our framework outperforms the state-of-the-art baselines remarkably, with an average improvement of over 50%. Further in-depth analyses validate its ability to capture spatio-temporal interactions, which can learn adaptively for different scenarios. The datasets and source code are available online: https://github.com/tsinghua-fib-lab/Spatio-temporal-Diffusion-Point-Processes.
Robust Preference-Guided Denoising for Graph based Social Recommendation
Mar 15, 2023



Graph Neural Network(GNN) based social recommendation models improve the prediction accuracy of user preference by leveraging GNN in exploiting preference similarity contained in social relations. However, in terms of both effectiveness and efficiency of recommendation, a large portion of social relations can be redundant or even noisy, e.g., it is quite normal that friends share no preference in a certain domain. Existing models do not fully solve this problem of relation redundancy and noise, as they directly characterize social influence over the full social network. In this paper, we instead propose to improve graph based social recommendation by only retaining the informative social relations to ensure an efficient and effective influence diffusion, i.e., graph denoising. Our designed denoising method is preference-guided to model social relation confidence and benefits user preference learning in return by providing a denoised but more informative social graph for recommendation models. Moreover, to avoid interference of noisy social relations, it designs a self-correcting curriculum learning module and an adaptive denoising strategy, both favoring highly-confident samples. Experimental results on three public datasets demonstrate its consistent capability of improving two state-of-the-art social recommendation models by robustly removing 10-40% of original relations. We release the source code at https://github.com/tsinghua-fib-lab/Graph-Denoising-SocialRec.
Advancements in Federated Learning: Models, Methods, and Privacy
Mar 05, 2023



Federated learning (FL) is a promising technique for addressing the rising privacy and security issues. Its main ingredient is to cooperatively learn the model among the distributed clients without uploading any sensitive data. In this paper, we conducted a thorough review of the related works, following the development context and deeply mining the key technologies behind FL from both theoretical and practical perspectives. Specifically, we first classify the existing works in FL architecture based on the network topology of FL systems with detailed analysis and summarization. Next, we abstract the current application problems, summarize the general techniques and frame the application problems into the general paradigm of FL base models. Moreover, we provide our proposed solutions for model training via FL. We have summarized and analyzed the existing FedOpt algorithms, and deeply revealed the algorithmic development principles of many first-order algorithms in depth, proposing a more generalized algorithm design framework. Based on these frameworks, we have instantiated FedOpt algorithms. As privacy and security is the fundamental requirement in FL, we provide the existing attack scenarios and the defense methods. To the best of our knowledge, we are among the first tier to review the theoretical methodology and propose our strategies since there are very few works surveying the theoretical approaches. Our survey targets motivating the development of high-performance, privacy-preserving, and secure methods to integrate FL into real-world applications.
Dual-interest Factorization-heads Attention for Sequential Recommendation
Feb 10, 2023



Accurate user interest modeling is vital for recommendation scenarios. One of the effective solutions is the sequential recommendation that relies on click behaviors, but this is not elegant in the video feed recommendation where users are passive in receiving the streaming contents and return skip or no-skip behaviors. Here skip and no-skip behaviors can be treated as negative and positive feedback, respectively. With the mixture of positive and negative feedback, it is challenging to capture the transition pattern of behavioral sequence. To do so, FeedRec has exploited a shared vanilla Transformer, which may be inelegant because head interaction of multi-heads attention does not consider different types of feedback. In this paper, we propose Dual-interest Factorization-heads Attention for Sequential Recommendation (short for DFAR) consisting of feedback-aware encoding layer, dual-interest disentangling layer and prediction layer. In the feedback-aware encoding layer, we first suppose each head of multi-heads attention can capture specific feedback relations. Then we further propose factorization-heads attention which can mask specific head interaction and inject feedback information so as to factorize the relation between different types of feedback. Additionally, we propose a dual-interest disentangling layer to decouple positive and negative interests before performing disentanglement on their representations. Finally, we evolve the positive and negative interests by corresponding towers whose outputs are contrastive by BPR loss. Experiments on two real-world datasets show the superiority of our proposed method against state-of-the-art baselines. Further ablation study and visualization also sustain its effectiveness. We release the source code here: https://github.com/tsinghua-fib-lab/WWW2023-DFAR.
Learning to Simulate Daily Activities via Modeling Dynamic Human Needs
Feb 09, 2023Daily activity data that records individuals' various types of activities in daily life are widely used in many applications such as activity scheduling, activity recommendation, and policymaking. Though with high value, its accessibility is limited due to high collection costs and potential privacy issues. Therefore, simulating human activities to produce massive high-quality data is of great importance to benefit practical applications. However, existing solutions, including rule-based methods with simplified assumptions of human behavior and data-driven methods directly fitting real-world data, both cannot fully qualify for matching reality. In this paper, motivated by the classic psychological theory, Maslow's need theory describing human motivation, we propose a knowledge-driven simulation framework based on generative adversarial imitation learning. To enhance the fidelity and utility of the generated activity data, our core idea is to model the evolution of human needs as the underlying mechanism that drives activity generation in the simulation model. Specifically, this is achieved by a hierarchical model structure that disentangles different need levels, and the use of neural stochastic differential equations that successfully captures piecewise-continuous characteristics of need dynamics. Extensive experiments demonstrate that our framework outperforms the state-of-the-art baselines in terms of data fidelity and utility. Besides, we present the insightful interpretability of the need modeling. The code is available at https://github.com/tsinghua-fib-lab/SAND.
Dual Contrastive Network for Sequential Recommendation with User and Item-Centric Perspectives
Sep 18, 2022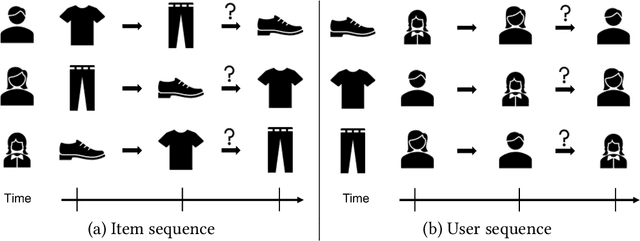
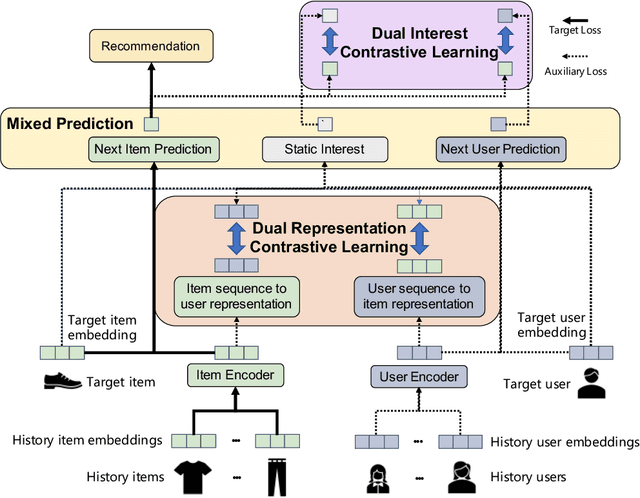

With the outbreak of today's streaming data, sequential recommendation is a promising solution to achieve time-aware personalized modeling. It aims to infer the next interacted item of given user based on history item sequence. Some recent works tend to improve the sequential recommendation via randomly masking on the history item so as to generate self-supervised signals. But such approach will indeed result in sparser item sequence and unreliable signals. Besides, the existing sequential recommendation is only user-centric, i.e., based on the historical items by chronological order to predict the probability of candidate items, which ignores whether the items from a provider can be successfully recommended. The such user-centric recommendation will make it impossible for the provider to expose their new items and result in popular bias. In this paper, we propose a novel Dual Contrastive Network (DCN) to generate ground-truth self-supervised signals for sequential recommendation by auxiliary user-sequence from item-centric perspective. Specifically, we propose dual representation contrastive learning to refine the representation learning by minimizing the euclidean distance between the representations of given user/item and history items/users of them. Before the second contrastive learning module, we perform next user prediction to to capture the trends of items preferred by certain types of users and provide personalized exploration opportunities for item providers. Finally, we further propose dual interest contrastive learning to self-supervise the dynamic interest from next item/user prediction and static interest of matching probability. Experiments on four benchmark datasets verify the effectiveness of our proposed method. Further ablation study also illustrates the boosting effect of the proposed components upon different sequential models.
DisenHCN: Disentangled Hypergraph Convolutional Networks for Spatiotemporal Activity Prediction
Aug 14, 2022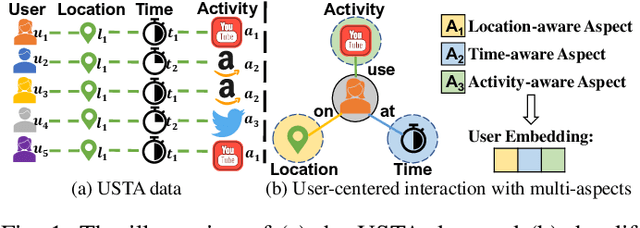
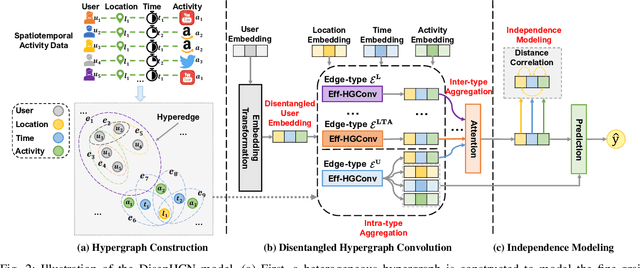
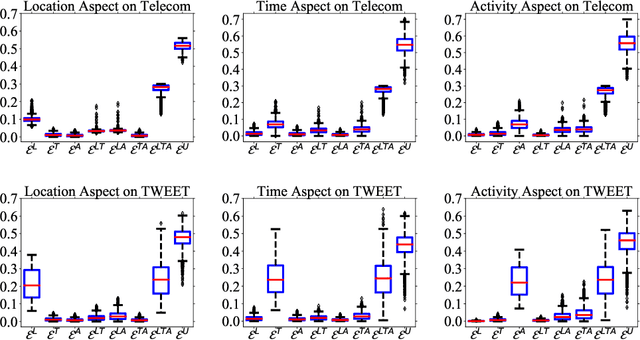
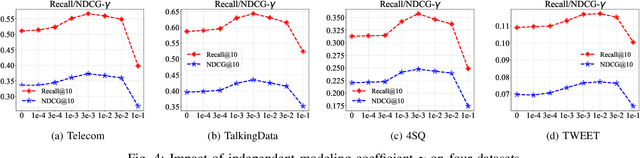
Spatiotemporal activity prediction, aiming to predict user activities at a specific location and time, is crucial for applications like urban planning and mobile advertising. Existing solutions based on tensor decomposition or graph embedding suffer from the following two major limitations: 1) ignoring the fine-grained similarities of user preferences; 2) user's modeling is entangled. In this work, we propose a hypergraph neural network model called DisenHCN to bridge the above gaps. In particular, we first unify the fine-grained user similarity and the complex matching between user preferences and spatiotemporal activity into a heterogeneous hypergraph. We then disentangle the user representations into different aspects (location-aware, time-aware, and activity-aware) and aggregate corresponding aspect's features on the constructed hypergraph, capturing high-order relations from different aspects and disentangles the impact of each aspect for final prediction. Extensive experiments show that our DisenHCN outperforms the state-of-the-art methods by 14.23% to 18.10% on four real-world datasets. Further studies also convincingly verify the rationality of each component in our DisenHCN.
DVR: Micro-Video Recommendation Optimizing Watch-Time-Gain under Duration Bias
Aug 10, 2022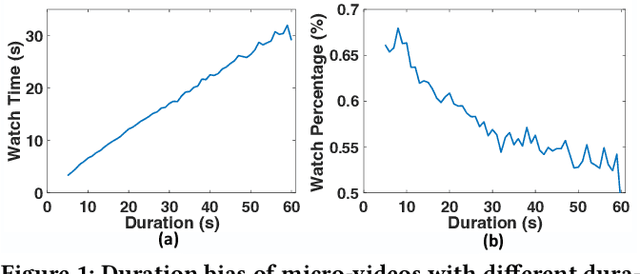
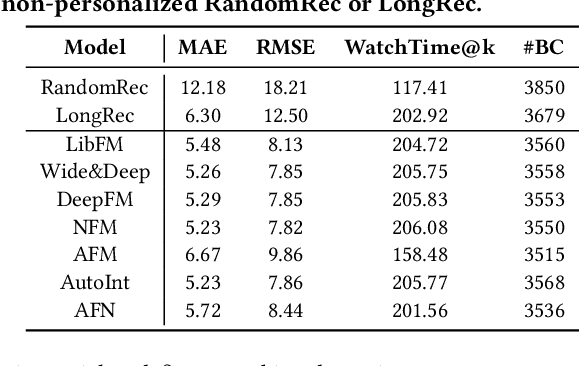
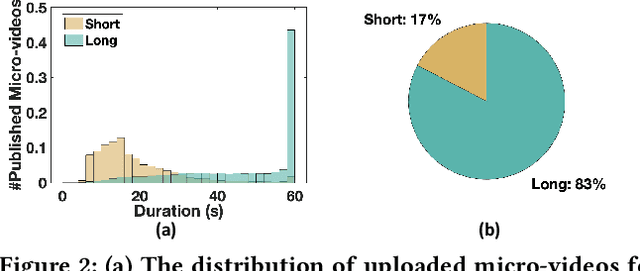
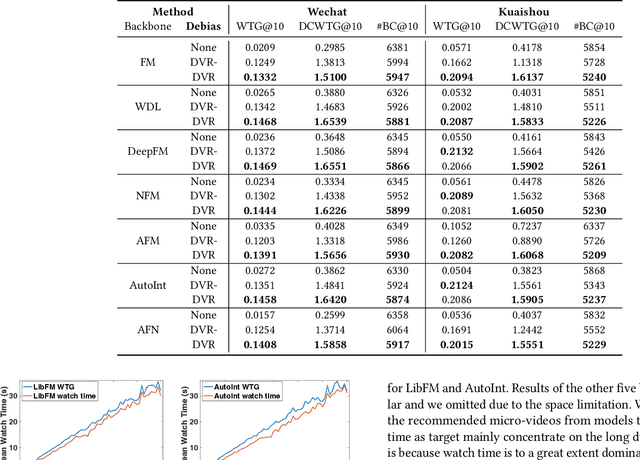
Recommender systems are prone to be misled by biases in the data. Models trained with biased data fail to capture the real interests of users, thus it is critical to alleviate the impact of bias to achieve unbiased recommendation. In this work, we focus on an essential bias in micro-video recommendation, duration bias. Specifically, existing micro-video recommender systems usually consider watch time as the most critical metric, which measures how long a user watches a video. Since videos with longer duration tend to have longer watch time, there exists a kind of duration bias, making longer videos tend to be recommended more against short videos. In this paper, we empirically show that commonly-used metrics are vulnerable to duration bias, making them NOT suitable for evaluating micro-video recommendation. To address it, we further propose an unbiased evaluation metric, called WTG (short for Watch Time Gain). Empirical results reveal that WTG can alleviate duration bias and better measure recommendation performance. Moreover, we design a simple yet effective model named DVR (short for Debiased Video Recommendation) that can provide unbiased recommendation of micro-videos with varying duration, and learn unbiased user preferences via adversarial learning. Extensive experiments based on two real-world datasets demonstrate that DVR successfully eliminates duration bias and significantly improves recommendation performance with over 30% relative progress. Codes and datasets are released at https://github.com/tsinghua-fib-lab/WTG-DVR.