 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the model-based stochastic value gradient for continuous reinforcement learning
Aug 28, 2020
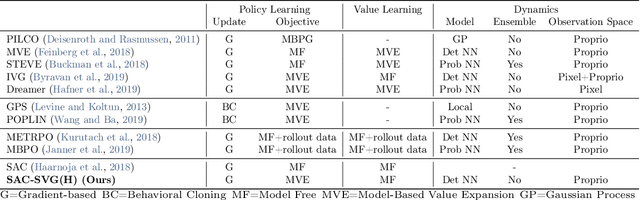

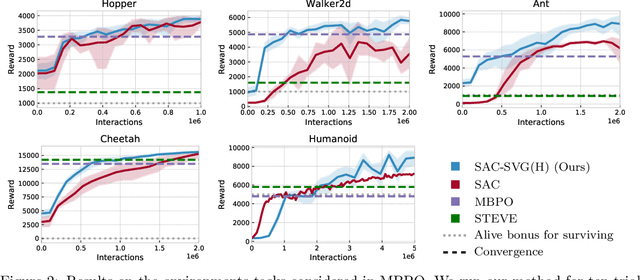
Model-based reinforcement learning approaches add explicit domain knowledge to agents in hopes of improving the sample-efficiency in comparison to model-free agents. However, in practice model-based methods are unable to achieve the same asymptotic performance on challenging continuous control tasks due to the complexity of learning and controlling an explicit world model. In this paper we investigate the stochastic value gradient (SVG), which is a well-known family of methods for controlling continuous systems which includes model-based approaches that distill a model-based value expansion into a model-free policy. We consider a variant of the model-based SVG that scales to larger systems and uses 1) an entropy regularization to help with exploration, 2) a learned deterministic world model to improve the short-horizon value estimate, and 3) a learned model-free value estimate after the model's rollout. This SVG variation captures the model-free soft actor-critic method as an instance when the model rollout horizon is zero, and otherwise uses short-horizon model rollouts to improve the value estimate for the policy update. We surpass the asymptotic performance of other model-based methods on the proprioceptive MuJoCo locomotion tasks from the OpenAI gym, including a humanoid. We notably achieve these results with a simple deterministic world model without requiring an ensemble.
Automatic Data Augmentation for Generalization in Deep Reinforcement Learning
Jun 23, 2020
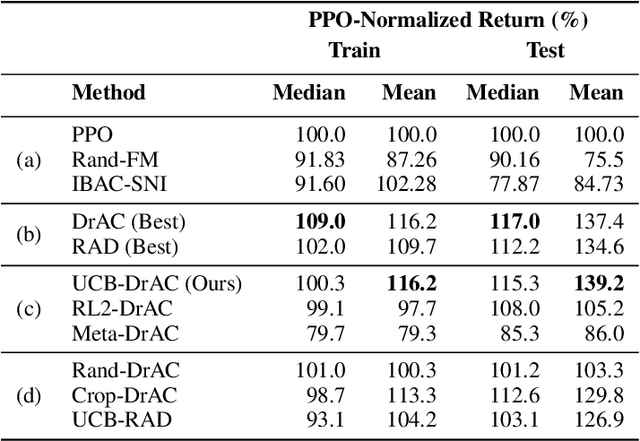
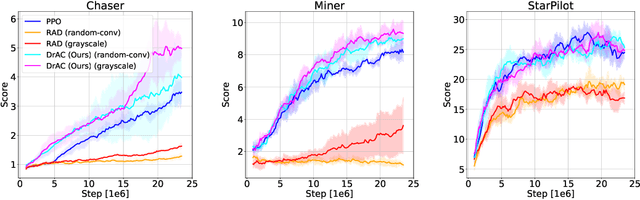
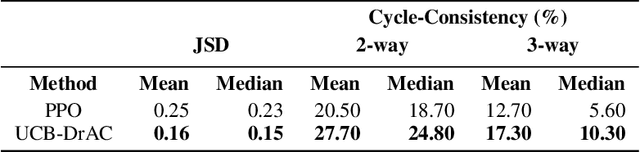
Deep reinforcement learning (RL) agents often fail to generalize to unseen scenarios, even when they are trained on many instances of semantically similar environments. Data augmentation has recently been shown to improve the sample efficiency and generalization of RL agents. However, different tasks tend to benefit from different kinds of data augmentation. In this paper, we compare three approaches for automatically finding an appropriate augmentation. These are combined with two novel regularization terms for the policy and value function, required to make the use of data augmentation theoretically sound for certain actor-critic algorithms. We evaluate our methods on the Procgen benchmark which consists of 16 procedurally-generated environments and show that it improves test performance by ~40% relative to standard RL algorithms. Our agent outperforms other baselines specifically designed to improve generalization in RL. In addition, we show that our agent learns policies and representations that are more robust to changes in the environment that do not affect the agent, such as the background. Our implementation is available at https://github.com/rraileanu/auto-drac.
Image Augmentation Is All You Need: Regularizing Deep Reinforcement Learning from Pixels
Apr 28, 2020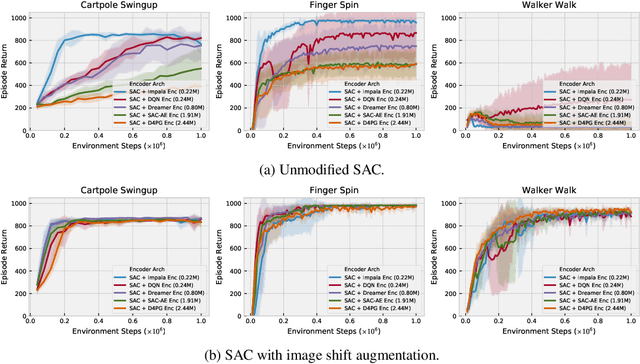
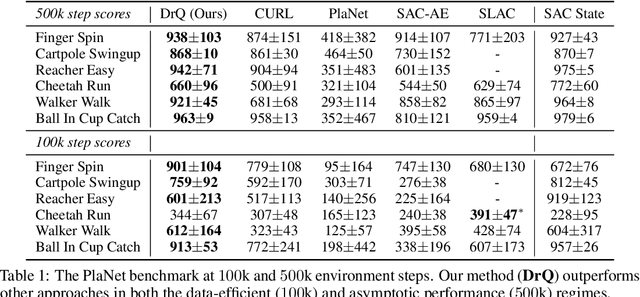
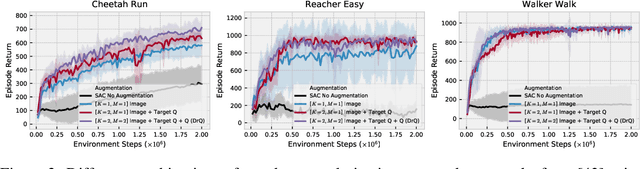
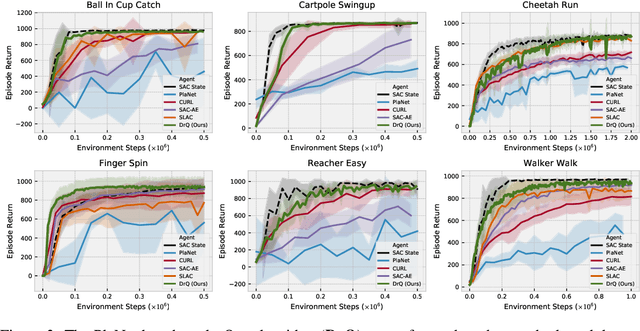
We propose a simple data augmentation technique that can be applied to standard model-free reinforcement learning algorithms, enabling robust learning directly from pixels without the need for auxiliary losses or pre-training. The approach leverages input perturbations commonly used in computer vision tasks to regularize the value function. Existing model-free approaches, such as Soft Actor-Critic (SAC), are not able to train deep networks effectively from image pixels. However, the addition of our augmentation method dramatically improves SAC's performance, enabling it to reach state-of-the-art performance on the DeepMind control suite, surpassing model-based (Dreamer, PlaNet, and SLAC) methods and recently proposed contrastive learning (CURL). Our approach can be combined with any model-free reinforcement learning algorithm, requiring only minor modifications. An implementation can be found at https://sites.google.com/view/data-regularized-q.
On the adequacy of untuned warmup for adaptive optimization
Oct 09, 2019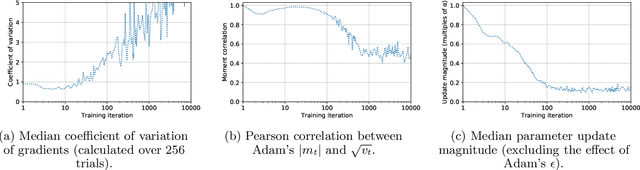
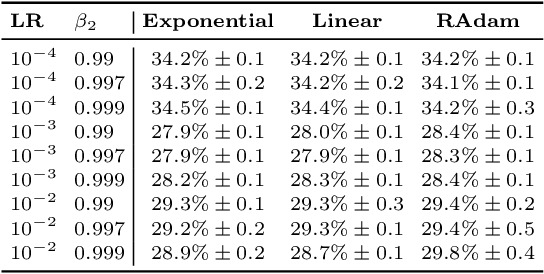
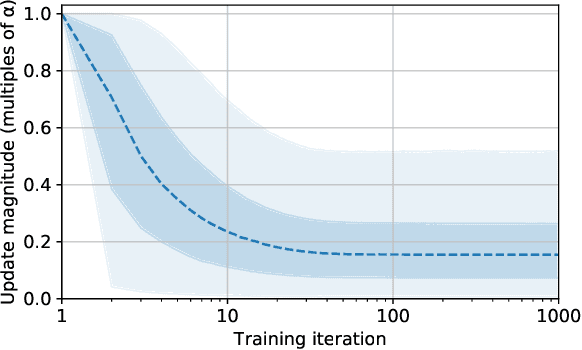
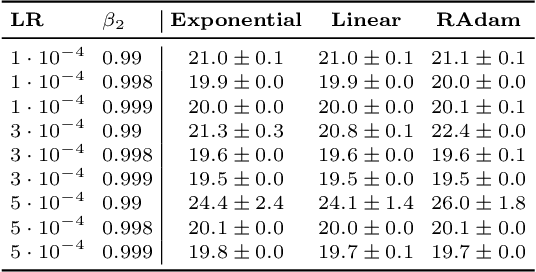
Adaptive optimization algorithms such as Adam (Kingma & Ba, 2014) are widely used in deep learning. The stability of such algorithms is often improved with a warmup schedule for the learning rate. Motivated by the difficulty of choosing and tuning warmup schedules, Liu et al. (2019) propose automatic variance rectification of Adam's adaptive learning rate, claiming that this rectified approach ("RAdam") surpasses the vanilla Adam algorithm and reduces the need for expensive tuning of Adam with warmup. In this work, we point out various shortcomings of this analysis. We then provide an alternative explanation for the necessity of warmup based on the magnitude of the update term, which is of greater relevance to training stability. Finally, we provide some "rule-of-thumb" warmup schedules, and we demonstrate that simple untuned warmup of Adam performs more-or-less identically to RAdam in typical practical settings. We conclude by suggesting that practitioners stick to linear warmup with Adam, with a sensible default being linear warmup over $2 / (1 - \beta_2)$ training iterations.
Generalized Inner Loop Meta-Learning
Oct 07, 2019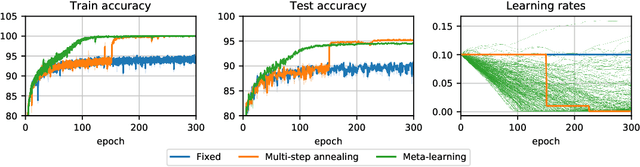

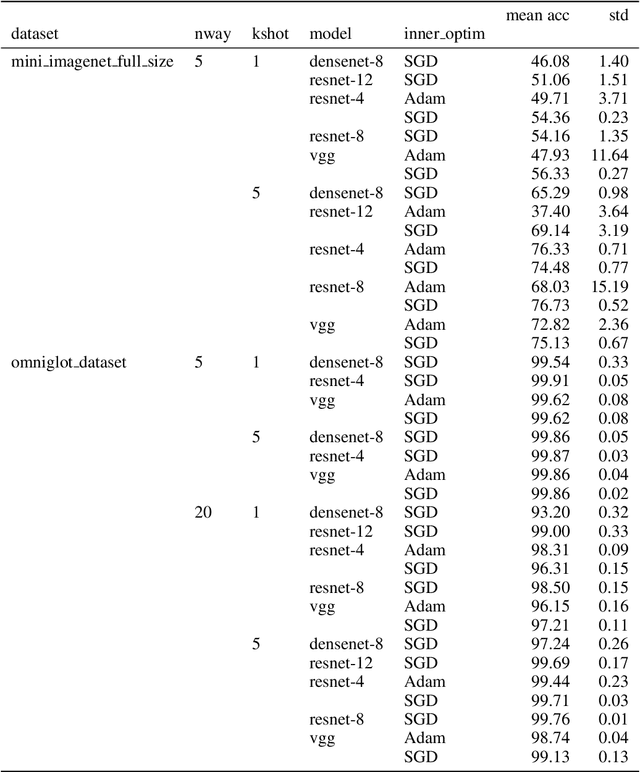
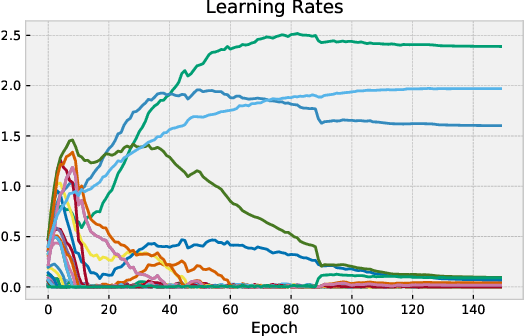
Many (but not all) approaches self-qualifying as "meta-learning" in deep learning and reinforcement learning fit a common pattern of approximating the solution to a nested optimization problem. In this paper, we give a formalization of this shared pattern, which we call GIMLI, prove its general requirements, and derive a general-purpose algorithm for implementing similar approaches. Based on this analysis and algorithm, we describe a library of our design, higher, which we share with the community to assist and enable future research into these kinds of meta-learning approaches. We end the paper by showcasing the practical applications of this framework and library through illustrative experiments and ablation studies which they facilitate.
Improving Sample Efficiency in Model-Free Reinforcement Learning from Images
Oct 07, 2019
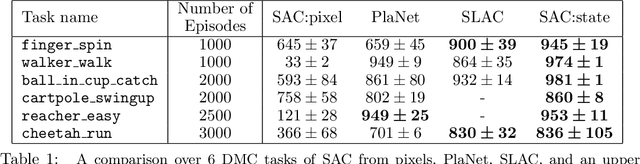
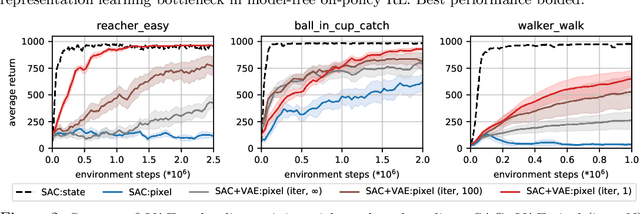
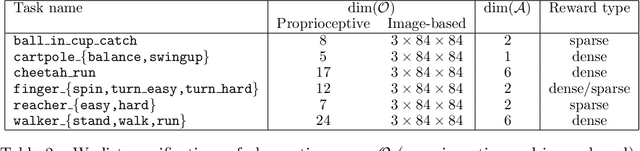
Training an agent to solve control tasks directly from high-dimensional images with model-free reinforcement learning (RL) has proven difficult. The agent needs to learn a latent representation together with a control policy to perform the task. Fitting a high-capacity encoder using a scarce reward signal is not only sample inefficient, but also prone to suboptimal convergence. Two ways to improve sample efficiency are to extract relevant features for the task and use off-policy algorithms. We dissect various approaches of learning good latent features, and conclude that the image reconstruction loss is the essential ingredient that enables efficient and stable representation learning in image-based RL. Following these findings, we devise an off-policy actor-critic algorithm with an auxiliary decoder that trains end-to-end and matches state-of-the-art performance across both model-free and model-based algorithms on many challenging control tasks. We release our code to encourage future research on image-based RL.
The Differentiable Cross-Entropy Method
Sep 27, 2019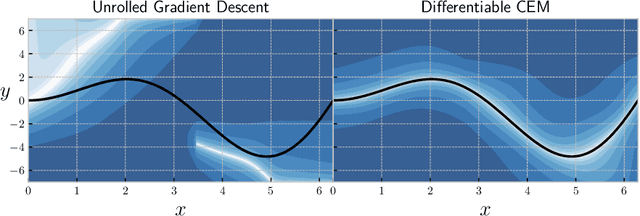
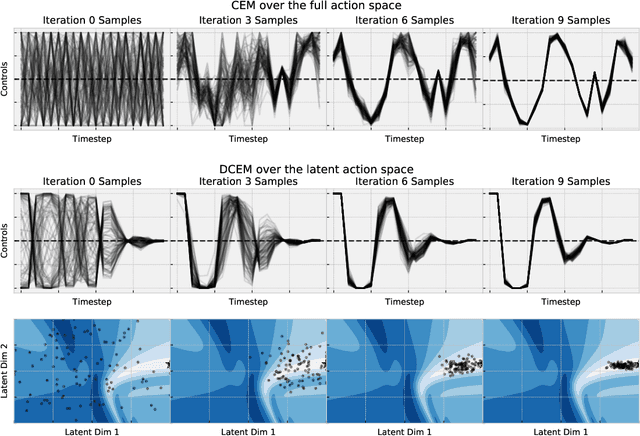
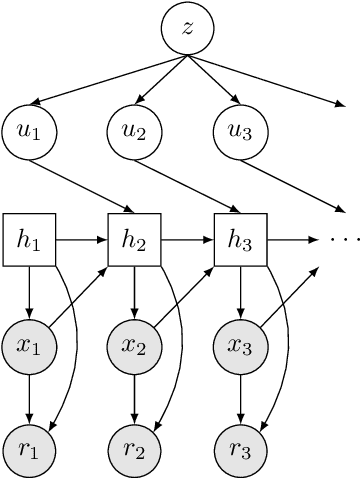
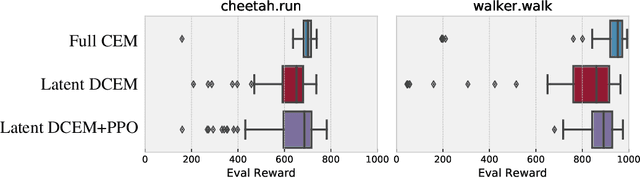
We study the Cross-Entropy Method (CEM) for the non-convex optimization of a continuous and parameterized objective function and introduce a differentiable variant (DCEM) that enables us to differentiate the output of CEM with respect to the objective function's parameters. In the machine learning setting this brings CEM inside of the end-to-end learning pipeline where this has otherwise been impossible. We show applications in a synthetic energy-based structured prediction task and in non-convex continuous control. In the control setting we show on the simulated cheetah and walker tasks that we can embed their optimal action sequences with DCEM and then use policy optimization to fine-tune components of the controller as a step towards combining model-based and model-free RL.
Hierarchical Decision Making by Generating and Following Natural Language Instructions
Jun 12, 2019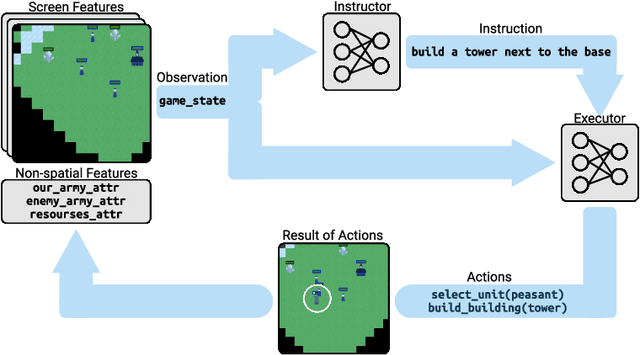
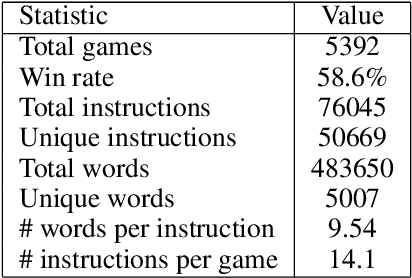
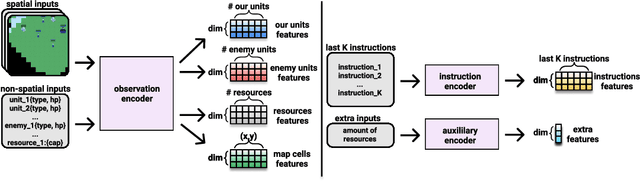
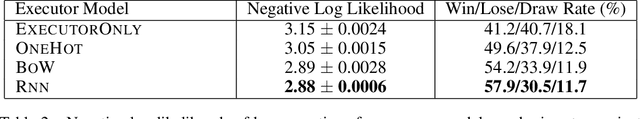
We explore using latent natural language instructions as an expressive and compositional representation of complex actions for hierarchical decision making. Rather than directly selecting micro-actions, our agent first generates a latent plan in natural language, which is then executed by a separate model. We introduce a challenging real-time strategy game environment in which the actions of a large number of units must be coordinated across long time scales. We gather a dataset of 76 thousand pairs of instructions and executions from human play, and train instructor and executor models. Experiments show that models using natural language as a latent variable significantly outperform models that directly imitate human actions. The compositional structure of language proves crucial to its effectiveness for action representation. We also release our code, models and data.
Quasi-hyperbolic momentum and Adam for deep learning
Oct 16, 2018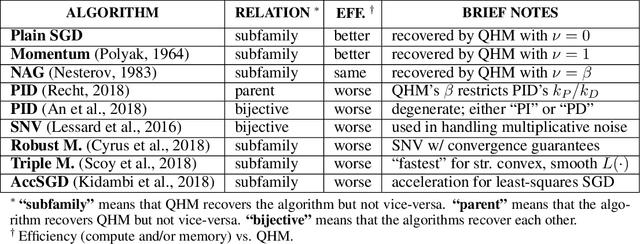
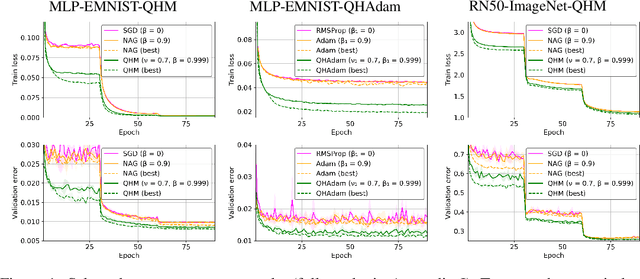
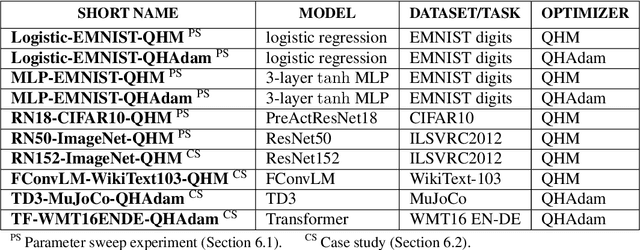
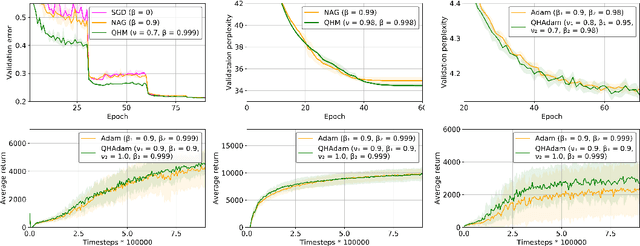
Momentum-based acceleration of stochastic gradient descent (SGD) is widely used in deep learning. We propose the quasi-hyperbolic momentum algorithm (QHM) as an extremely simple alteration of momentum SGD, averaging a plain SGD step with a momentum step. We describe numerous connections to and identities with other algorithms, and we characterize the set of two-state optimization algorithms that QHM can recover. Finally, we propose a QH variant of Adam called QHAdam, and we empirically demonstrate that our algorithms lead to significantly improved training in a variety of settings, including a new state-of-the-art result on WMT16 EN-DE. We hope that these empirical results, combined with the conceptual and practical simplicity of QHM and QHAdam, will spur interest from both practitioners and researchers. PyTorch code is immediately available.
Hierarchical Text Generation and Planning for Strategic Dialogue
Jun 04, 2018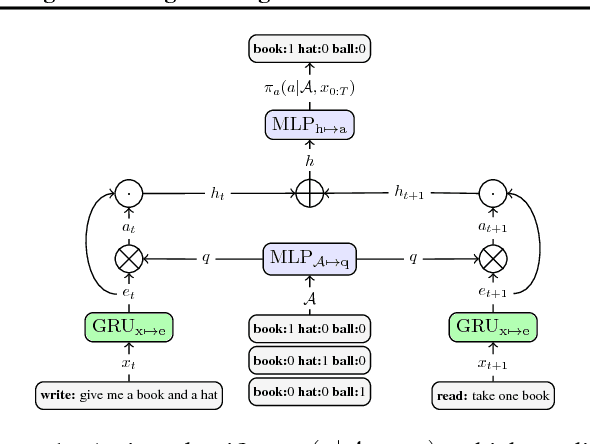
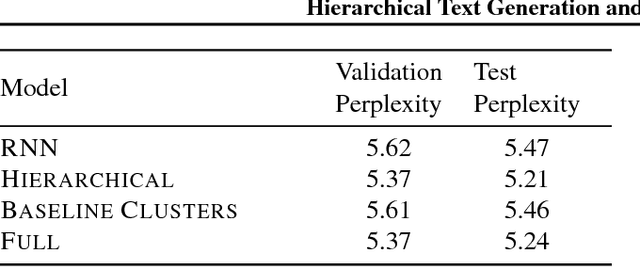
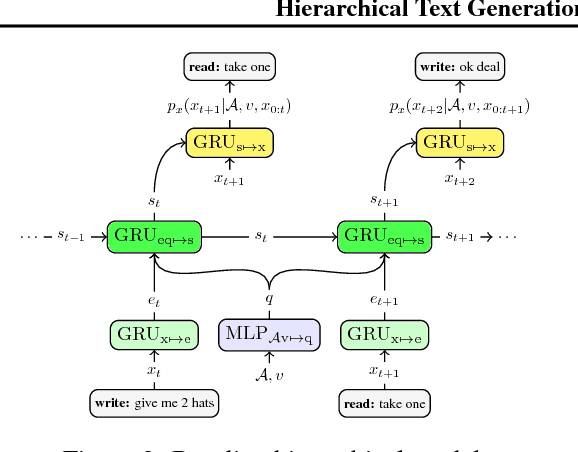
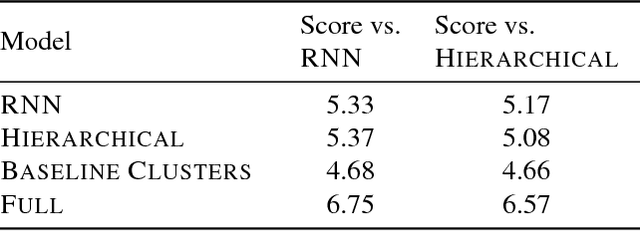
End-to-end models for goal-orientated dialogue are challenging to train, because linguistic and strategic aspects are entangled in latent state vectors. We introduce an approach to learning representations of messages in dialogues by maximizing the likelihood of subsequent sentences and actions, which decouples the semantics of the dialogue utterance from its linguistic realization. We then use these latent sentence representations for hierarchical language generation, planning and reinforcement learning. Experiments show that our approach increases the end-task reward achieved by the model, improves the effectiveness of long-term planning using rollouts, and allows self-play reinforcement learning to improve decision making without diverging from human language. Our hierarchical latent-variable model outperforms previous work both linguistically and strategically.