 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHiKonv: High Throughput Quantized Convolution With Novel Bit-wise Management and Computation
Dec 28, 2021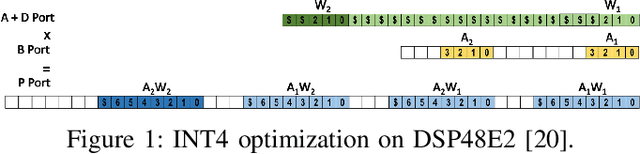
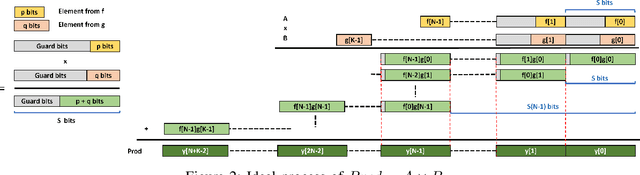

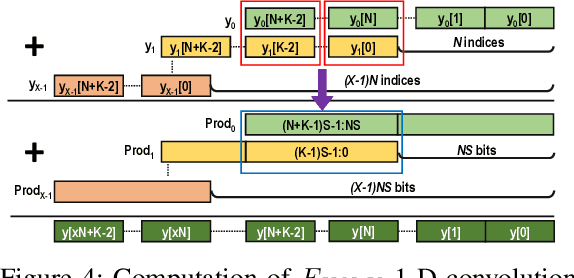
Quantization for Convolutional Neural Network (CNN) has shown significant progress with the intention of reducing the cost of computation and storage with low-bitwidth data inputs. There are, however, no systematic studies on how an existing full-bitwidth processing unit, such as CPUs and DSPs, can be better utilized to carry out significantly higher computation throughput for convolution under various quantized bitwidths. In this study, we propose HiKonv, a unified solution that maximizes the compute throughput of a given underlying processing unit to process low-bitwidth quantized data inputs through novel bit-wise parallel computation. We establish theoretical performance bounds using a full-bitwidth multiplier for highly parallelized low-bitwidth convolution, and demonstrate new breakthroughs for high-performance computing in this critical domain. For example, a single 32-bit processing unit can deliver 128 binarized convolution operations (multiplications and additions) under one CPU instruction, and a single 27x18 DSP core can deliver eight convolution operations with 4-bit inputs in one cycle. We demonstrate the effectiveness of HiKonv on CPU and FPGA for both convolutional layers or a complete DNN model. For a convolutional layer quantized to 4-bit, HiKonv achieves a 3.17x latency improvement over the baseline implementation using C++ on CPU. Compared to the DAC-SDC 2020 champion model for FPGA, HiKonv achieves a 2.37x throughput improvement and 2.61x DSP efficiency improvement, respectively.
EH-DNAS: End-to-End Hardware-aware Differentiable Neural Architecture Search
Nov 24, 2021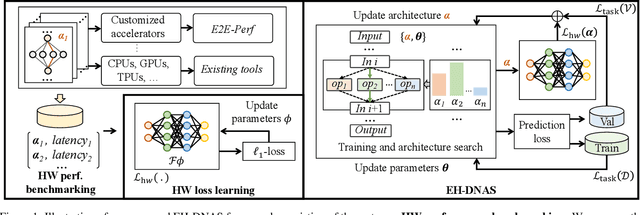
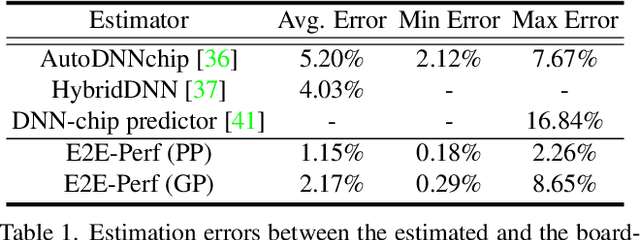
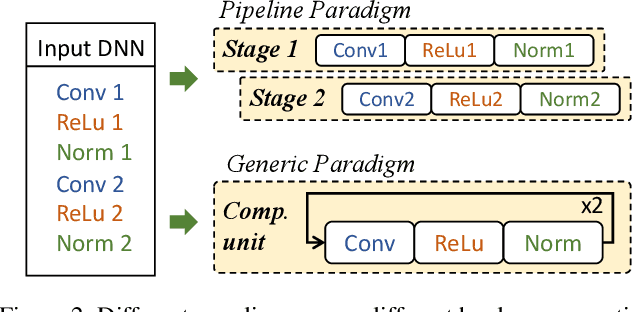
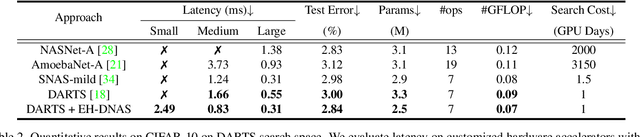
In hardware-aware Differentiable Neural Architecture Search (DNAS), it is challenging to compute gradients of hardware metrics to perform architecture search. Existing works rely on linear approximations with limited support to customized hardware accelerators. In this work, we propose End-to-end Hardware-aware DNAS (EH-DNAS), a seamless integration of end-to-end hardware benchmarking, and fully automated DNAS to deliver hardware-efficient deep neural networks on various platforms, including Edge GPUs, Edge TPUs, Mobile CPUs, and customized accelerators. Given a desired hardware platform, we propose to learn a differentiable model predicting the end-to-end hardware performance of neural network architectures for DNAS. We also introduce E2E-Perf, an end-to-end hardware benchmarking tool for customized accelerators. Experiments on CIFAR10 and ImageNet show that EH-DNAS improves the hardware performance by an average of $1.4\times$ on customized accelerators and $1.6\times$ on existing hardware processors while maintaining the classification accuracy.
YOLO-ReT: Towards High Accuracy Real-time Object Detection on Edge GPUs
Oct 26, 2021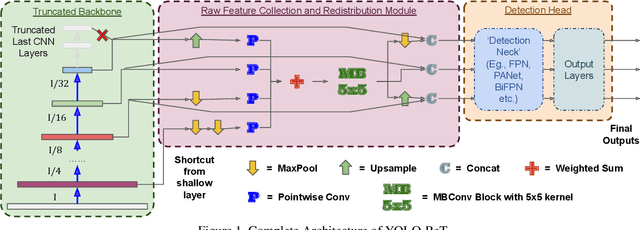
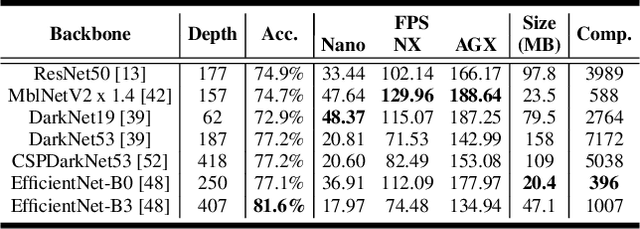
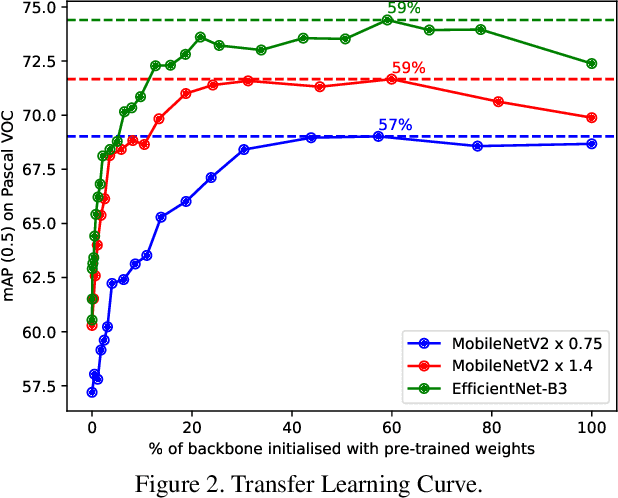
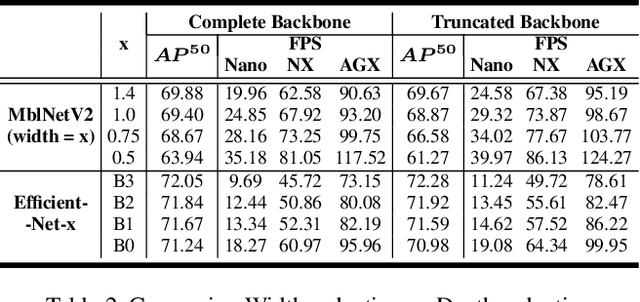
Performance of object detection models has been growing rapidly on two major fronts, model accuracy and efficiency. However, in order to map deep neural network (DNN) based object detection models to edge devices, one typically needs to compress such models significantly, thus compromising the model accuracy. In this paper, we propose a novel edge GPU friendly module for multi-scale feature interaction by exploiting missing combinatorial connections between various feature scales in existing state-of-the-art methods. Additionally, we propose a novel transfer learning backbone adoption inspired by the changing translational information flow across various tasks, designed to complement our feature interaction module and together improve both accuracy as well as execution speed on various edge GPU devices available in the market. For instance, YOLO-ReT with MobileNetV2x0.75 backbone runs real-time on Jetson Nano, and achieves 68.75 mAP on Pascal VOC and 34.91 mAP on COCO, beating its peers by 3.05 mAP and 0.91 mAP respectively, while executing faster by 3.05 FPS. Furthermore, introducing our multi-scale feature interaction module in YOLOv4-tiny and YOLOv4-tiny (3l) improves their performance to 41.5 and 48.1 mAP respectively on COCO, outperforming the original versions by 1.3 and 0.9 mAP.
Generic Neural Architecture Search via Regression
Aug 04, 2021
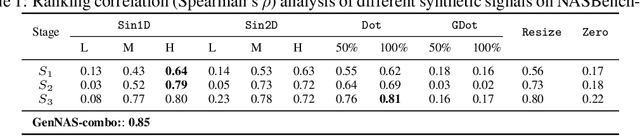
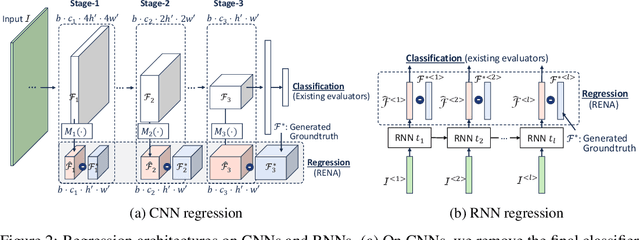
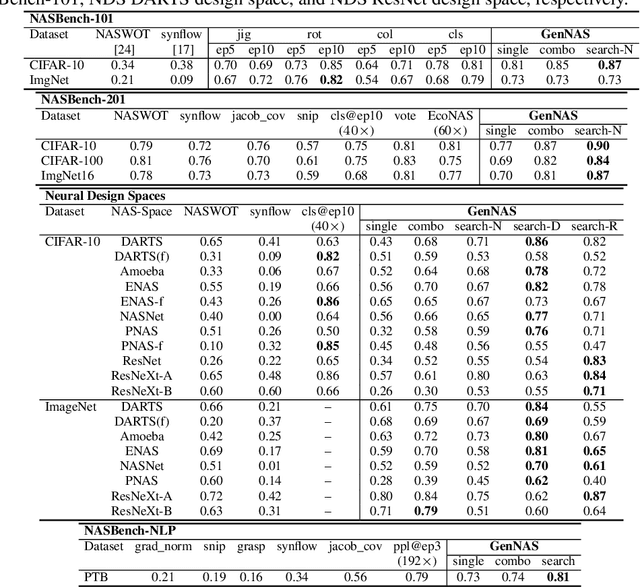
Most existing neural architecture search (NAS) algorithms are dedicated to the downstream tasks, e.g., image classification in computer vision. However, extensive experiments have shown that, prominent neural architectures, such as ResNet in computer vision and LSTM in natural language processing, are generally good at extracting patterns from the input data and perform well on different downstream tasks. These observations inspire us to ask: Is it necessary to use the performance of specific downstream tasks to evaluate and search for good neural architectures? Can we perform NAS effectively and efficiently while being agnostic to the downstream task? In this work, we attempt to affirmatively answer the above two questions and improve the state-of-the-art NAS solution by proposing a novel and generic NAS framework, termed Generic NAS (GenNAS). GenNAS does not use task-specific labels but instead adopts \textit{regression} on a set of manually designed synthetic signal bases for architecture evaluation. Such a self-supervised regression task can effectively evaluate the intrinsic power of an architecture to capture and transform the input signal patterns, and allow more sufficient usage of training samples. We then propose an automatic task search to optimize the combination of synthetic signals using limited downstream-task-specific labels, further improving the performance of GenNAS. We also thoroughly evaluate GenNAS's generality and end-to-end NAS performance on all search spaces, which outperforms almost all existing works with significant speedup.
WinoCNN: Kernel Sharing Winograd Systolic Array for Efficient Convolutional Neural Network Acceleration on FPGAs
Jul 09, 2021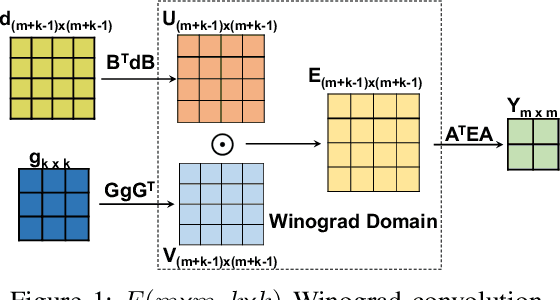
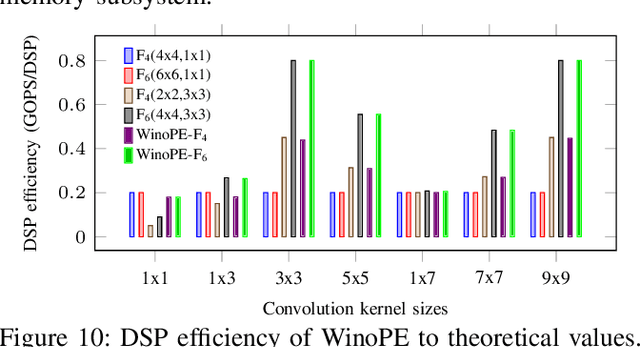
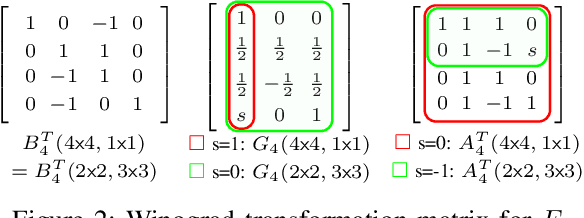
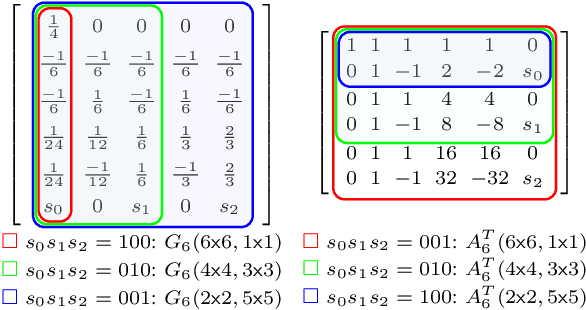
The combination of Winograd's algorithm and systolic array architecture has demonstrated the capability of improving DSP efficiency in accelerating convolutional neural networks (CNNs) on FPGA platforms. However, handling arbitrary convolution kernel sizes in FPGA-based Winograd processing elements and supporting efficient data access remain underexplored. In this work, we are the first to propose an optimized Winograd processing element (WinoPE), which can naturally support multiple convolution kernel sizes with the same amount of computing resources and maintains high runtime DSP efficiency. Using the proposed WinoPE, we construct a highly efficient systolic array accelerator, termed WinoCNN. We also propose a dedicated memory subsystem to optimize the data access. Based on the accelerator architecture, we build accurate resource and performance modeling to explore optimal accelerator configurations under different resource constraints. We implement our proposed accelerator on multiple FPGAs, which outperforms the state-of-the-art designs in terms of both throughput and DSP efficiency. Our implementation achieves DSP efficiency up to 1.33 GOPS/DSP and throughput up to 3.1 TOPS with the Xilinx ZCU102 FPGA. These are 29.1\% and 20.0\% better than the best solutions reported previously, respectively.
Software/Hardware Co-design for Multi-modal Multi-task Learning in Autonomous Systems
Apr 08, 2021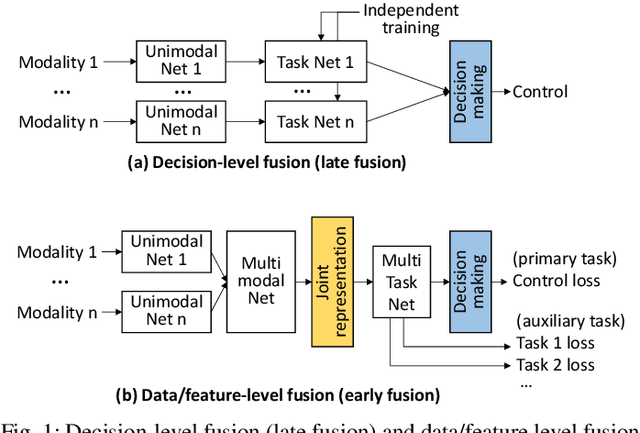
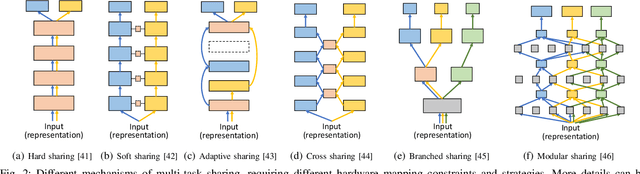
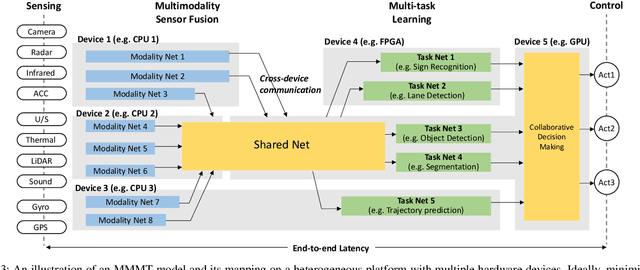
Optimizing the quality of result (QoR) and the quality of service (QoS) of AI-empowered autonomous systems simultaneously is very challenging. First, there are multiple input sources, e.g., multi-modal data from different sensors, requiring diverse data preprocessing, sensor fusion, and feature aggregation. Second, there are multiple tasks that require various AI models to run simultaneously, e.g., perception, localization, and control. Third, the computing and control system is heterogeneous, composed of hardware components with varied features, such as embedded CPUs, GPUs, FPGAs, and dedicated accelerators. Therefore, autonomous systems essentially require multi-modal multi-task (MMMT) learning which must be aware of hardware performance and implementation strategies. While MMMT learning has been attracting intensive research interests, its applications in autonomous systems are still underexplored. In this paper, we first discuss the opportunities of applying MMMT techniques in autonomous systems and then discuss the unique challenges that must be solved. In addition, we discuss the necessity and opportunities of MMMT model and hardware co-design, which is critical for autonomous systems especially with power/resource-limited or heterogeneous platforms. We formulate the MMMT model and heterogeneous hardware implementation co-design as a differentiable optimization problem, with the objective of improving the solution quality and reducing the overall power consumption and critical path latency. We advocate for further explorations of MMMT in autonomous systems and software/hardware co-design solutions.
Enabling Design Methodologies and Future Trends for Edge AI: Specialization and Co-design
Mar 30, 2021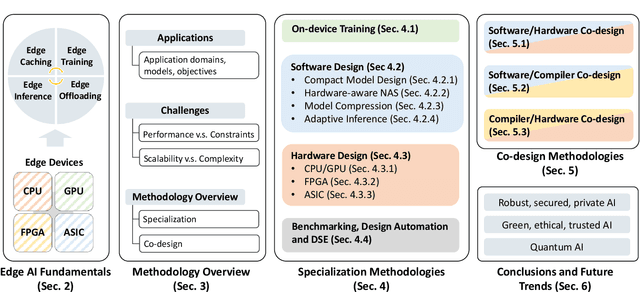
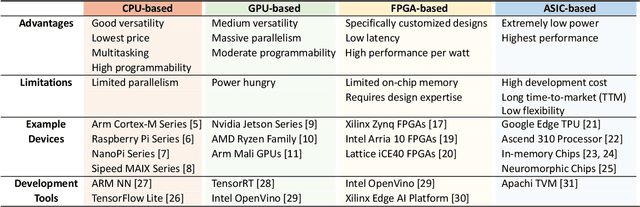

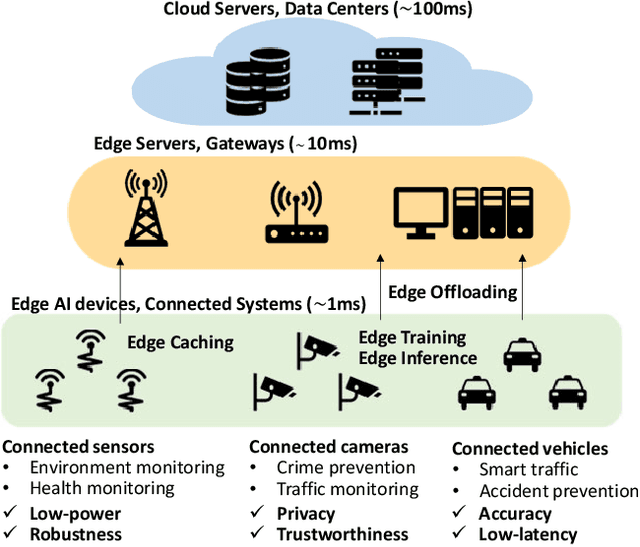
Artificial intelligence (AI) technologies have dramatically advanced in recent years, resulting in revolutionary changes in people's lives. Empowered by edge computing, AI workloads are migrating from centralized cloud architectures to distributed edge systems, introducing a new paradigm called edge AI. While edge AI has the promise of bringing significant increases in autonomy and intelligence into everyday lives through common edge devices, it also raises new challenges, especially for the development of its algorithms and the deployment of its services, which call for novel design methodologies catered to these unique challenges. In this paper, we provide a comprehensive survey of the latest enabling design methodologies that span the entire edge AI development stack. We suggest that the key methodologies for effective edge AI development are single-layer specialization and cross-layer co-design. We discuss representative methodologies in each category in detail, including on-device training methods, specialized software design, dedicated hardware design, benchmarking and design automation, software/hardware co-design, software/compiler co-design, and compiler/hardware co-design. Moreover, we attempt to reveal hidden cross-layer design opportunities that can further boost the solution quality of future edge AI and provide insights into future directions and emerging areas that require increased research focus.
F-CAD: A Framework to Explore Hardware Accelerators for Codec Avatar Decoding
Mar 08, 2021



Creating virtual avatars with realistic rendering is one of the most essential and challenging tasks to provide highly immersive virtual reality (VR) experiences. It requires not only sophisticated deep neural network (DNN) based codec avatar decoders to ensure high visual quality and precise motion expression, but also efficient hardware accelerators to guarantee smooth real-time rendering using lightweight edge devices, like untethered VR headsets. Existing hardware accelerators, however, fail to deliver sufficient performance and efficiency targeting such decoders which consist of multi-branch DNNs and require demanding compute and memory resources. To address these problems, we propose an automation framework, called F-CAD (Facebook Codec avatar Accelerator Design), to explore and deliver optimized hardware accelerators for codec avatar decoding. Novel technologies include 1) a new accelerator architecture to efficiently handle multi-branch DNNs; 2) a multi-branch dynamic design space to enable fine-grained architecture configurations; and 3) an efficient architecture search for picking the optimized hardware design based on both application-specific demands and hardware resource constraints. To the best of our knowledge, F-CAD is the first automation tool that supports the whole design flow of hardware acceleration of codec avatar decoders, allowing joint optimization on decoder designs in popular machine learning frameworks and corresponding customized accelerator design with cycle-accurate evaluation. Results show that the accelerators generated by F-CAD can deliver up to 122.1 frames per second (FPS) and 91.6% hardware efficiency when running the latest codec avatar decoder. Compared to the state-of-the-art designs, F-CAD achieves 4.0X and 2.8X higher throughput, 62.5% and 21.2% higher efficiency than DNNBuilder and HybridDNN by targeting the same hardware device.
Large Graph Convolutional Network Training with GPU-Oriented Data Communication Architecture
Mar 04, 2021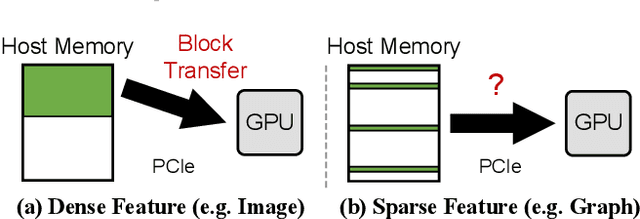

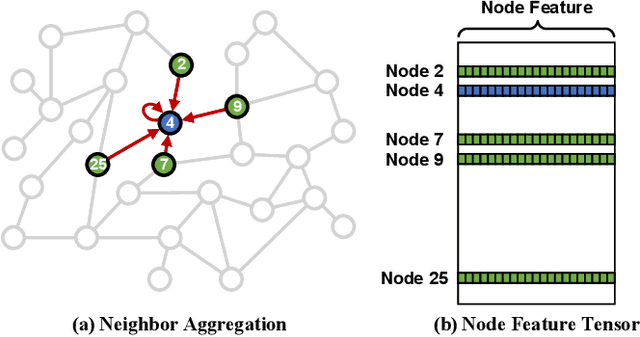

Graph Convolutional Networks (GCNs) are increasingly adopted in large-scale graph-based recommender systems. Training GCN requires the minibatch generator traversing graphs and sampling the sparsely located neighboring nodes to obtain their features. Since real-world graphs often exceed the capacity of GPU memory, current GCN training systems keep the feature table in host memory and rely on the CPU to collect sparse features before sending them to the GPUs. This approach, however, puts tremendous pressure on host memory bandwidth and the CPU. This is because the CPU needs to (1) read sparse features from memory, (2) write features into memory as a dense format, and (3) transfer the features from memory to the GPUs. In this work, we propose a novel GPU-oriented data communication approach for GCN training, where GPU threads directly access sparse features in host memory through zero-copy accesses without much CPU help. By removing the CPU gathering stage, our method significantly reduces the consumption of the host resources and data access latency. We further present two important techniques to achieve high host memory access efficiency by the GPU: (1) automatic data access address alignment to maximize PCIe packet efficiency, and (2) asynchronous zero-copy access and kernel execution to fully overlap data transfer with training. We incorporate our method into PyTorch and evaluate its effectiveness using several graphs with sizes up to 111 million nodes and 1.6 billion edges. In a multi-GPU training setup, our method is 65-92% faster than the conventional data transfer method, and can even match the performance of all-in-GPU-memory training for some graphs that fit in GPU memory.
PyTorch-Direct: Enabling GPU Centric Data Access for Very Large Graph Neural Network Training with Irregular Accesses
Jan 20, 2021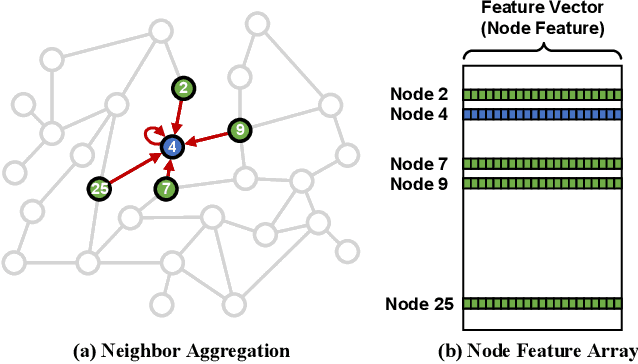

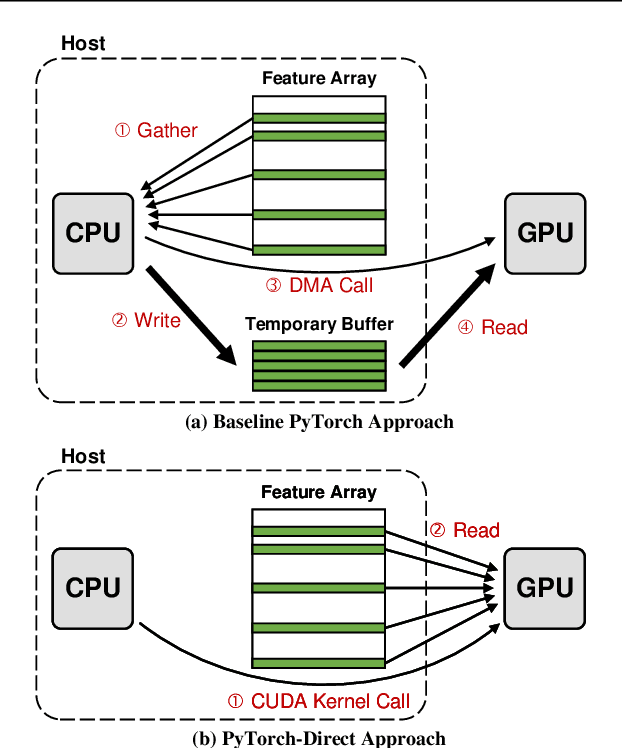

With the increasing adoption of graph neural networks (GNNs) in the machine learning community, GPUs have become an essential tool to accelerate GNN training. However, training GNNs on very large graphs that do not fit in GPU memory is still a challenging task. Unlike conventional neural networks, mini-batching input samples in GNNs requires complicated tasks such as traversing neighboring nodes and gathering their feature values. While this process accounts for a significant portion of the training time, we find existing GNN implementations using popular deep neural network (DNN) libraries such as PyTorch are limited to a CPU-centric approach for the entire data preparation step. This "all-in-CPU" approach has negative impact on the overall GNN training performance as it over-utilizes CPU resources and hinders GPU acceleration of GNN training. To overcome such limitations, we introduce PyTorch-Direct, which enables a GPU-centric data accessing paradigm for GNN training. In PyTorch-Direct, GPUs are capable of efficiently accessing complicated data structures in host memory directly without CPU intervention. Our microbenchmark and end-to-end GNN training results show that PyTorch-Direct reduces data transfer time by 47.1% on average and speeds up GNN training by up to 1.6x. Furthermore, by reducing CPU utilization, PyTorch-Direct also saves system power by 12.4% to 17.5% during training. To minimize programmer effort, we introduce a new "unified tensor" type along with necessary changes to the PyTorch memory allocator, dispatch logic, and placement rules. As a result, users need to change at most two lines of their PyTorch GNN training code for each tensor object to take advantage of PyTorch-Direct.