 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSubgraph Extraction-based Feedback-guided Iterative Scheduling for HLS
Jan 22, 2024



This paper proposes ISDC, a novel feedback-guided iterative system of difference constraints (SDC) scheduling algorithm for high-level synthesis (HLS). ISDC leverages subgraph extraction-based low-level feedback from downstream tools like logic synthesizers to iteratively refine HLS scheduling. Technical innovations include: (1) An enhanced SDC formulation that effectively integrates low-level feedback into the linear-programming (LP) problem; (2) A fanout and window-based subgraph extraction mechanism driving the feedback cycle; (3) A no-human-in-loop ISDC flow compatible with a wide range of downstream tools and process design kits (PDKs). Evaluation shows that ISDC reduces register usage by 28.5% against an industrial-strength open-source HLS tool.
Medusa: Simple LLM Inference Acceleration Framework with Multiple Decoding Heads
Jan 19, 2024



The inference process in Large Language Models (LLMs) is often limited due to the absence of parallelism in the auto-regressive decoding process, resulting in most operations being restricted by the memory bandwidth of accelerators. While methods such as speculative decoding have been suggested to address this issue, their implementation is impeded by the challenges associated with acquiring and maintaining a separate draft model. In this paper, we present Medusa, an efficient method that augments LLM inference by adding extra decoding heads to predict multiple subsequent tokens in parallel. Using a tree-based attention mechanism, Medusa constructs multiple candidate continuations and verifies them simultaneously in each decoding step. By leveraging parallel processing, Medusa introduces only minimal overhead in terms of single-step latency while substantially reducing the number of decoding steps required. We present two levels of fine-tuning procedures for Medusa to meet the needs of different use cases: Medusa-1: Medusa is directly fine-tuned on top of a frozen backbone LLM, enabling lossless inference acceleration. Medusa-2: Medusa is fine-tuned together with the backbone LLM, enabling better prediction accuracy of Medusa heads and higher speedup but needing a special training recipe that preserves the backbone model's capabilities. Moreover, we propose several extensions that improve or expand the utility of Medusa, including a self-distillation to handle situations where no training data is available and a typical acceptance scheme to boost the acceptance rate while maintaining generation quality. We evaluate Medusa on models of various sizes and training procedures. Our experiments demonstrate that Medusa-1 can achieve over 2.2x speedup without compromising generation quality, while Medusa-2 further improves the speedup to 2.3-3.6x.
What Makes Convolutional Models Great on Long Sequence Modeling?
Oct 17, 2022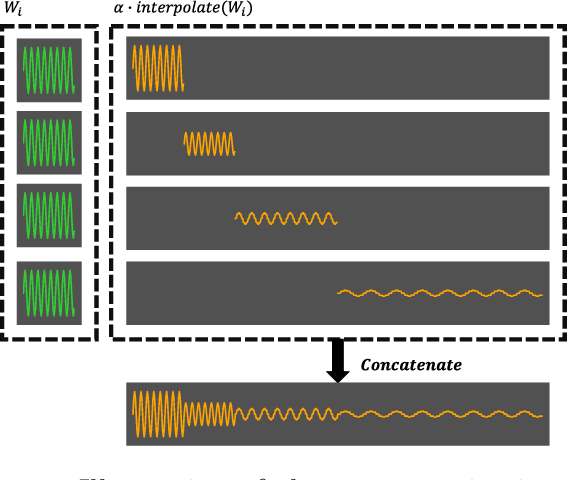
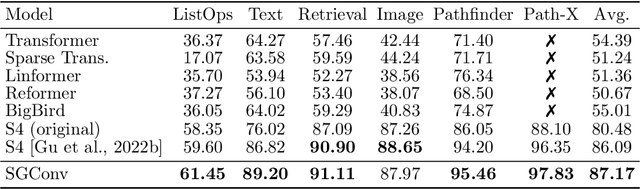
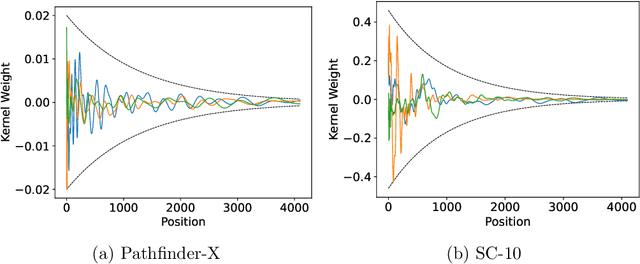
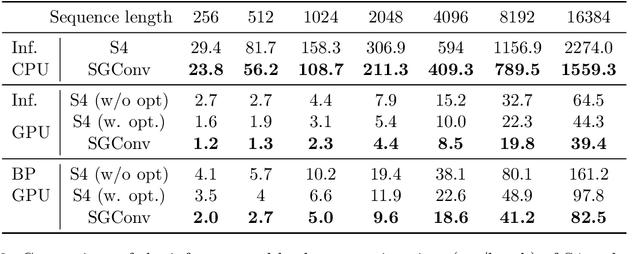
Convolutional models have been widely used in multiple domains. However, most existing models only use local convolution, making the model unable to handle long-range dependency efficiently. Attention overcomes this problem by aggregating global information but also makes the computational complexity quadratic to the sequence length. Recently, Gu et al. [2021] proposed a model called S4 inspired by the state space model. S4 can be efficiently implemented as a global convolutional model whose kernel size equals the input sequence length. S4 can model much longer sequences than Transformers and achieve significant gains over SoTA on several long-range tasks. Despite its empirical success, S4 is involved. It requires sophisticated parameterization and initialization schemes. As a result, S4 is less intuitive and hard to use. Here we aim to demystify S4 and extract basic principles that contribute to the success of S4 as a global convolutional model. We focus on the structure of the convolution kernel and identify two critical but intuitive principles enjoyed by S4 that are sufficient to make up an effective global convolutional model: 1) The parameterization of the convolutional kernel needs to be efficient in the sense that the number of parameters should scale sub-linearly with sequence length. 2) The kernel needs to satisfy a decaying structure that the weights for convolving with closer neighbors are larger than the more distant ones. Based on the two principles, we propose a simple yet effective convolutional model called Structured Global Convolution (SGConv). SGConv exhibits strong empirical performance over several tasks: 1) With faster speed, SGConv surpasses S4 on Long Range Arena and Speech Command datasets. 2) When plugging SGConv into standard language and vision models, it shows the potential to improve both efficiency and performance.
Extensible Proxy for Efficient NAS
Oct 17, 2022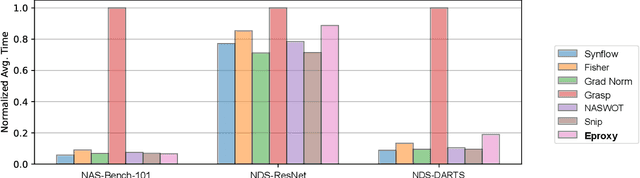

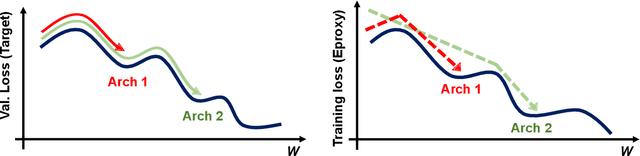

Neural Architecture Search (NAS) has become a de facto approach in the recent trend of AutoML to design deep neural networks (DNNs). Efficient or near-zero-cost NAS proxies are further proposed to address the demanding computational issues of NAS, where each candidate architecture network only requires one iteration of backpropagation. The values obtained from the proxies are considered the predictions of architecture performance on downstream tasks. However, two significant drawbacks hinder the extended usage of Efficient NAS proxies. (1) Efficient proxies are not adaptive to various search spaces. (2) Efficient proxies are not extensible to multi-modality downstream tasks. Based on the observations, we design a Extensible proxy (Eproxy) that utilizes self-supervised, few-shot training (i.e., 10 iterations of backpropagation) which yields near-zero costs. The key component that makes Eproxy efficient is an untrainable convolution layer termed barrier layer that add the non-linearities to the optimization spaces so that the Eproxy can discriminate the performance of architectures in the early stage. Furthermore, to make Eproxy adaptive to different downstream tasks/search spaces, we propose a Discrete Proxy Search (DPS) to find the optimized training settings for Eproxy with only handful of benchmarked architectures on the target tasks. Our extensive experiments confirm the effectiveness of both Eproxy and Eproxy+DPS. Code is available at https://github.com/leeyeehoo/GenNAS-Zero.
HiKonv: Maximizing the Throughput of Quantized Convolution With Novel Bit-wise Management and Computation
Jul 22, 2022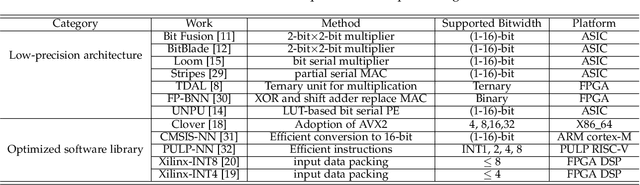
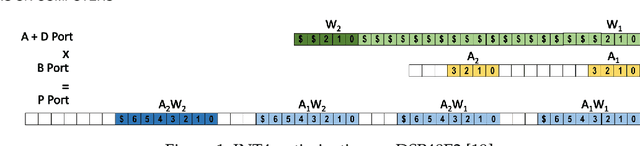
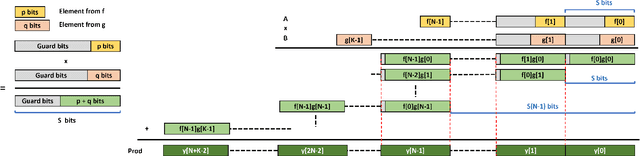
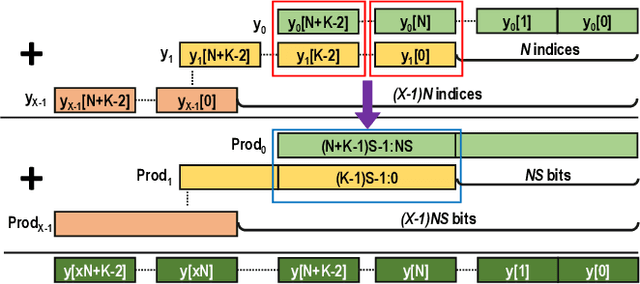
Quantization for CNN has shown significant progress with the intention of reducing the cost of computation and storage with low-bitwidth data representations. There are, however, no systematic studies on how an existing full-bitwidth processing unit, such as ALU in CPUs and DSP in FPGAs, can be better utilized to deliver significantly higher computation throughput for convolution under various quantized bitwidths. In this study, we propose HiKonv, a unified solution that maximizes the throughput of convolution on a given underlying processing unit with low-bitwidth quantized data inputs through novel bit-wise management and parallel computation. We establish theoretical framework and performance models using a full-bitwidth multiplier for highly parallelized low-bitwidth convolution, and demonstrate new breakthroughs for high-performance computing in this critical domain. For example, a single 32-bit processing unit in CPU can deliver 128 binarized convolution operations (multiplications and additions) and 13 4-bit convolution operations with a single multiplication instruction, and a single 27x18 multiplier in the FPGA DSP can deliver 60, 8 or 2 convolution operations with 1, 4 or 8-bit inputs in one clock cycle. We demonstrate the effectiveness of HiKonv on both CPU and FPGA. On CPU, HiKonv outperforms the baseline implementation with 1 to 8-bit inputs and provides up to 7.6x and 1.4x performance improvements for 1-D convolution, and performs 2.74x and 3.19x over the baseline implementation for 4-bit signed and unsigned data inputs for 2-D convolution. On FPGA, HiKonv solution enables a single DSP to process multiple convolutions with a shorter processing latency. For binarized input, each DSP with HiKonv is equivalent up to 76.6 LUTs. Compared to the DAC-SDC 2020 champion model, HiKonv achieves a 2.37x throughput improvement and 2.61x DSP efficiency improvement, respectively.
ORB-based SLAM accelerator on SoC FPGA
Jul 18, 2022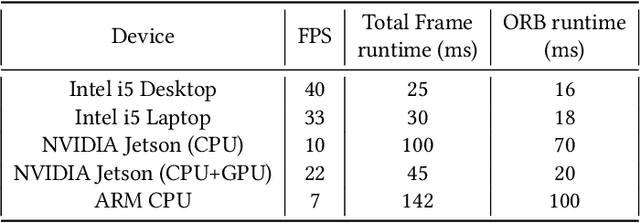
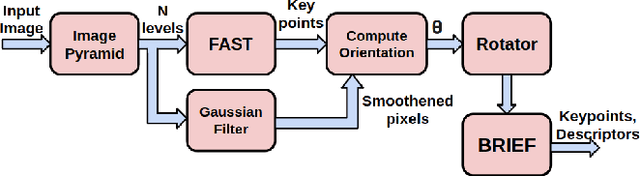
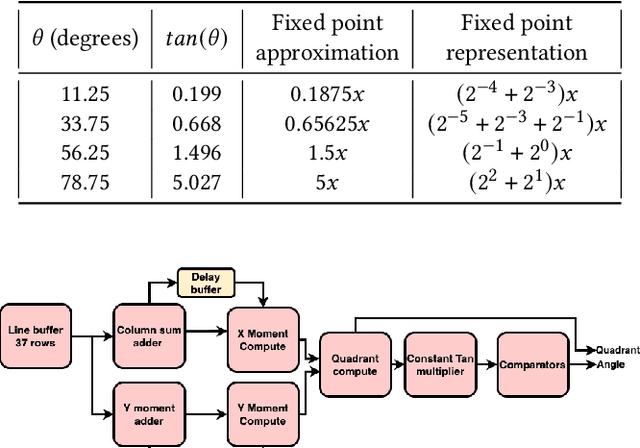
Simultaneous Localization and Mapping (SLAM) is one of the main components of autonomous navigation systems. With the increase in popularity of drones, autonomous navigation on low-power systems is seeing widespread application. Most SLAM algorithms are computationally intensive and struggle to run in real-time on embedded devices with reasonable accuracy. ORB-SLAM is an open-sourced feature-based SLAM that achieves high accuracy with reduced computational complexity. We propose an SoC based ORB-SLAM system that accelerates the computationally intensive visual feature extraction and matching on hardware. Our FPGA system based on a Zynq-family SoC runs 8.5x, 1.55x and 1.35x faster compared to an ARM CPU, Intel Desktop CPU, and a state-of-the-art FPGA system respectively, while averaging a 2x improvement in accuracy compared to prior work on FPGA.
Chimera: A Hybrid Machine Learning Driven Multi-Objective Design Space Exploration Tool for FPGA High-Level Synthesis
Jul 03, 2022In recent years, hardware accelerators based on field-programmable gate arrays (FPGAs) have been widely adopted, thanks to FPGAs' extraordinary flexibility. However, with the high flexibility comes the difficulty in design and optimization. Conventionally, these accelerators are designed with low-level hardware descriptive languages, which means creating large designs with complex behavior is extremely difficult. Therefore, high-level synthesis (HLS) tools were created to simplify hardware designs for FPGAs. They enable the user to create hardware designs using high-level languages and provide various optimization directives to help to improve the performance of the synthesized hardware. However, applying these optimizations to achieve high performance is time-consuming and usually requires expert knowledge. To address this difficulty, we present an automated design space exploration tool for applying HLS optimization directives, called Chimera, which significantly reduces the human effort and expertise needed for creating high-performance HLS designs. It utilizes a novel multi-objective exploration method that seamlessly integrates active learning, evolutionary algorithm, and Thompson sampling, making it capable of finding a set of optimized designs on a Pareto curve with only a small number of design points evaluated during the exploration. In the experiments, in less than 24 hours, this hybrid method explored design points that have the same or superior performance compared to highly optimized hand-tuned designs created by expert HLS users from the Rosetta benchmark suite. In addition to discovering the extreme points, it also explores a Pareto frontier, where the elbow point can potentially save up to 26\% of Flip-Flop resource with negligibly higher latency.
Efficient Machine Learning, Compilers, and Optimizations for Embedded Systems
Jun 06, 2022
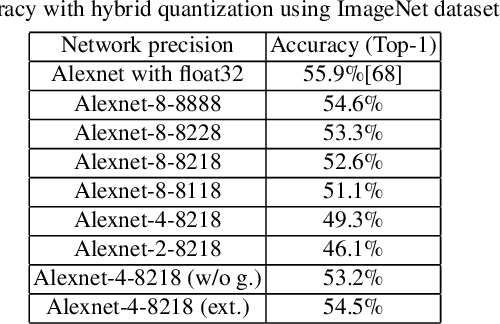
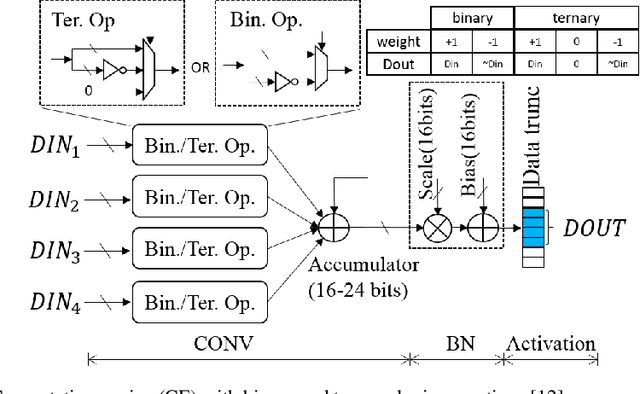
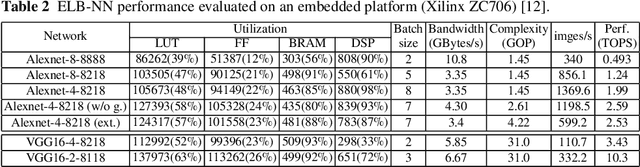
Deep Neural Networks (DNNs) have achieved great success in a massive number of artificial intelligence (AI) applications by delivering high-quality computer vision, natural language processing, and virtual reality applications. However, these emerging AI applications also come with increasing computation and memory demands, which are challenging to handle especially for the embedded systems where limited computation/memory resources, tight power budgets, and small form factors are demanded. Challenges also come from the diverse application-specific requirements, including real-time responses, high-throughput performance, and reliable inference accuracy. To address these challenges, we will introduce a series of effective design methods in this book chapter to enable efficient algorithms, compilers, and various optimizations for embedded systems.
Physics Community Needs, Tools, and Resources for Machine Learning
Mar 30, 2022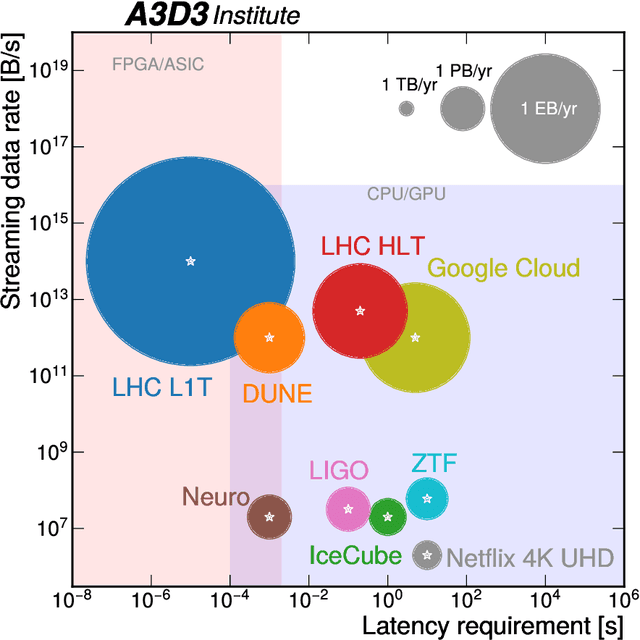

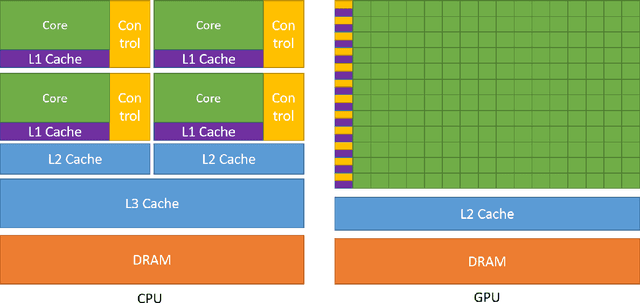
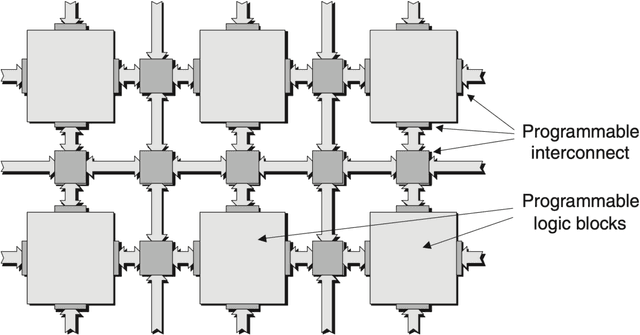
Machine learning (ML) is becoming an increasingly important component of cutting-edge physics research, but its computational requirements present significant challenges. In this white paper, we discuss the needs of the physics community regarding ML across latency and throughput regimes, the tools and resources that offer the possibility of addressing these needs, and how these can be best utilized and accessed in the coming years.
AutoDistill: an End-to-End Framework to Explore and Distill Hardware-Efficient Language Models
Jan 21, 2022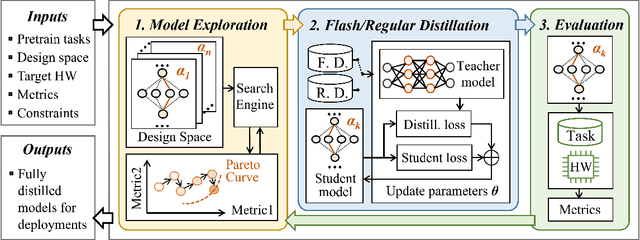
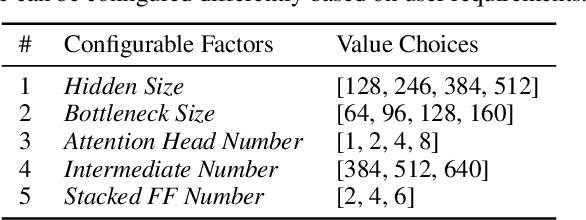
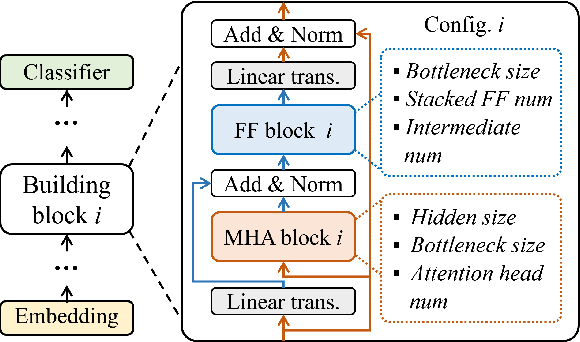
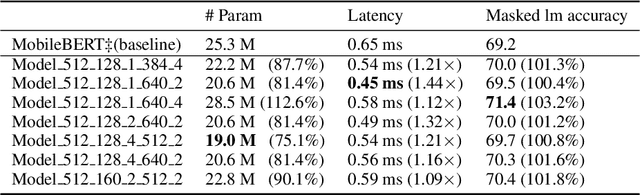
Recently, large pre-trained models have significantly improved the performance of various Natural LanguageProcessing (NLP) tasks but they are expensive to serve due to long serving latency and large memory usage. To compress these models, knowledge distillation has attracted an increasing amount of interest as one of the most effective methods for model compression. However, existing distillation methods have not yet addressed the unique challenges of model serving in datacenters, such as handling fast evolving models, considering serving performance, and optimizing for multiple objectives. To solve these problems, we propose AutoDistill, an end-to-end model distillation framework integrating model architecture exploration and multi-objective optimization for building hardware-efficient NLP pre-trained models. We use Bayesian Optimization to conduct multi-objective Neural Architecture Search for selecting student model architectures. The proposed search comprehensively considers both prediction accuracy and serving latency on target hardware. The experiments on TPUv4i show the finding of seven model architectures with better pre-trained accuracy (up to 3.2% higher) and lower inference latency (up to 1.44x faster) than MobileBERT. By running downstream NLP tasks in the GLUE benchmark, the model distilled for pre-training by AutoDistill with 28.5M parameters achieves an 81.69 average score, which is higher than BERT_BASE, DistillBERT, TinyBERT, NAS-BERT, and MobileBERT. The most compact model found by AutoDistill contains only 20.6M parameters but still outperform BERT_BASE(109M), DistillBERT(67M), TinyBERT(67M), and MobileBERT(25.3M) regarding the average GLUE score. By evaluating on SQuAD, a model found by AutoDistill achieves an 88.4% F1 score with 22.8M parameters, which reduces parameters by more than 62% while maintaining higher accuracy than DistillBERT, TinyBERT, and NAS-BERT.