 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBridging Single Distortion Artifacts and Mmultifactorial Clinical Quality: Few-shot Biparametric MRI Quality Assessment via Distortion-trained Prototypical Networks
Jun 17, 2026Clinical prostate multi-parametric MRI relies heavily on high-quality diffusion-weighted imaging (DWI), yet reading DWI is frequently compromised by geometric distortion, often caused by rectal air. Assessing quality via the PI-QUAL scoring system is an emerging clinical standard, but it is subjective, time-consuming and suffers from a class imbalance where low-quality cases are diverse and relatively scarce. Using the PRIME clinical trial as an example, there are $6\%$ images with PI-QUAL scores lower than 4, $87\%$ of DWI issues are due to distortion. Many of the other clinical quality issues are under-represented. To address this common dual-scarcity of annotated clinical data, we propose a few-shot biparametric prototypical network for automated image quality assessment (IQA). Our framework utilizes a dual-branch 3D ResNet to fuse T2-weighted and DWI features, providing anatomical context to distinguish true morphology from distortion. To handle real-world heterogeneity, we introduce feature-wise linear modulation (FiLM) and a gradient reversal layer (GRL) to align feature distributions conditioned on varying b-values while suppressing acquisition-related biases. We demonstrate that a model meta-trained solely on comparatively objective, readily obtainable distortion labels can effectively adapt to predicting complex, multi-factorial clinical quality scores such as PI-QUAL using only five representative samples. Experimental results on two datasets show that our method significantly outperforms few-shot learning baselines for this challenging IQA task, offering a practically feasible and data-efficient solution for standardizing prostate MRI quality control in clinical workflows.
Learning to Distort: Weakly-Supervised Image Quality Transfer for Prostate DWI Correction
Jun 17, 2026Single-shot echo-planar prostate diffusion-weighted imaging (DWI) is frequently complicated by geometric distortions, which impact the ability to derive reliable diagnoses from such images. Developing automated correction methods is challenged by the absence of paired distorted and undistorted clinical scans. In this paper, we first propose a novel weakly-supervised image quality transfer (IQT) framework from undistorted to distorted images that utilizes image quality assessment (IQA) signals to supervise the transfer process. Unlike traditional methods that require expensive, voxel-wise paired data or resort to developing unpaired algorithms, our approach utilizes image-level quality labels (here, distorted vs. undistorted) to establish latent quality prototypes within a pre-trained feature space. Recognizing that simulating realistic distortions is more reliable than direct unpaired correction, we describe a weakly-supervised prototype flow matching algorithm to explicitly regularize generative trajectories towards distorted prototypes, producing realistic susceptibility artifacts that mimic clinical degradations. By synthesizing these realistic pairs, we enable a second IQT model to be trained in the forward direction for distortion correction. Experimental results demonstrate that our generated images successfully mimic the diagnostic interference of real-world artifacts, which leads to more capable distortion correction IQT models. In addition to qualitative comparisons, we also conduct exhaustive quantitative evaluations that compare our approach with existing unpaired approaches (e.g., CycleGAN, UNIT-DDPM, and OT-FM) - as either forward or reverse alternatives - by assessing clinical downstream task performance in PI-RADS and Gleason score classification, using both in-distribution and external data sets.
Understanding the Transfer Limits of Vision Foundation Models
Jan 22, 2026Foundation models leverage large-scale pretraining to capture extensive knowledge, demonstrating generalization in a wide range of language tasks. By comparison, vision foundation models (VFMs) often exhibit uneven improvements across downstream tasks, despite substantial computational investment. We postulate that this limitation arises from a mismatch between pretraining objectives and the demands of downstream vision-and-imaging tasks. Pretraining strategies like masked image reconstruction or contrastive learning shape representations for tasks such as recovery of generic visual patterns or global semantic structures, which may not align with the task-specific requirements of downstream applications including segmentation, classification, or image synthesis. To investigate this in a concrete real-world clinical area, we assess two VFMs, a reconstruction-focused MAE-based model (ProFound) and a contrastive-learning-based model (ProViCNet), on five prostate multiparametric MR imaging tasks, examining how such task alignment influences transfer performance, i.e., from pretraining to fine-tuning. Our findings indicate that better alignment between pretraining and downstream tasks, measured by simple divergence metrics such as maximum-mean-discrepancy (MMD) between the same features before and after fine-tuning, correlates with greater performance improvements and faster convergence, emphasizing the importance of designing and analyzing pretraining objectives with downstream applicability in mind.
Dynamic Rebatching for Efficient Early-Exit Inference with DREX
Dec 17, 2025Early-Exit (EE) is a Large Language Model (LLM) architecture that accelerates inference by allowing easier tokens to be generated using only a subset of the model's layers. However, traditional batching frameworks are ill-suited for EE LLMs, as not all requests in a batch may be ready to exit at the same time. Existing solutions either force a uniform decision on the batch, which overlooks EE opportunities, or degrade output quality by forcing premature exits. We propose Dynamic Rebatching, a solution where we dynamically reorganize the batch at each early-exit point. Requests that meet the exit criteria are immediately processed, while those that continue are held in a buffer, re-grouped into a new batch, and forwarded to deeper layers. We introduce DREX, an early-exit inference system that implements Dynamic Rebatching with two key optimizations: 1) a copy-free rebatching buffer that avoids physical data movement, and 2) an EE and SLA-aware scheduler that analytically predicts whether a given rebatching operation will be profitable. DREX also efficiently handles the missing KV cache from skipped layers using memory-efficient state-copying. Our evaluation shows that DREX improves throughput by 2-12% compared to baseline approaches while maintaining output quality. Crucially, DREX completely eliminates involuntary exits, providing a key guarantee for preserving the output quality intended by the EE model.
Learning to Address Intra-segment Misclassification in Retinal Imaging
Apr 25, 2021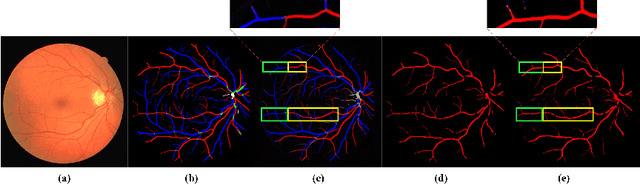
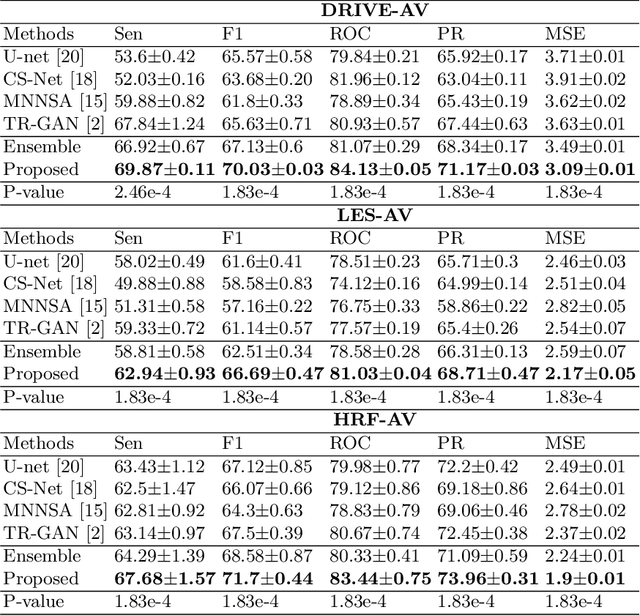

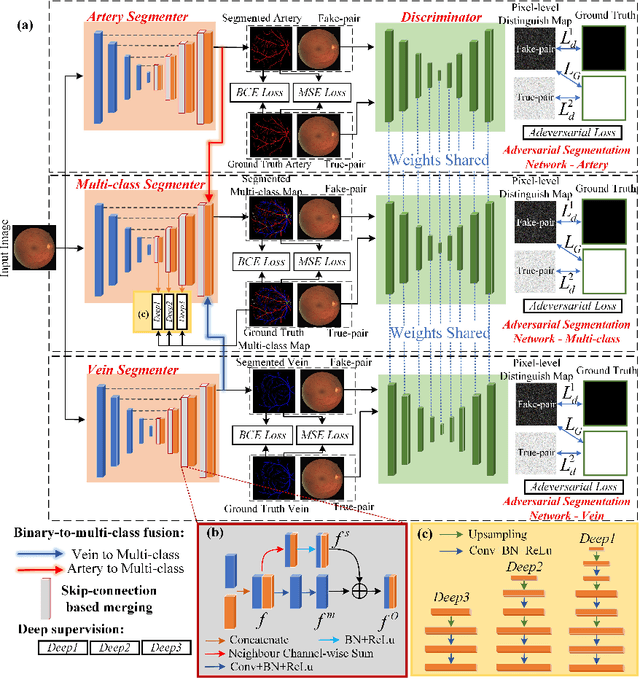
Accurate multi-class segmentation is a long-standing challenge in medical imaging, especially in scenarios where classes share strong similarity. Segmenting retinal blood vessels in retinal photographs is one such scenario, in which arteries and veins need to be identified and differentiated from each other and from the background. Intra-segment misclassification, i.e. veins classified as arteries or vice versa, frequently occurs when arteries and veins intersect, whereas in binary retinal vessel segmentation, error rates are much lower. We thus propose a new approach that decomposes multi-class segmentation into multiple binary, followed by a binary-to-multi-class fusion network. The network merges representations of artery, vein, and multi-class feature maps, each of which are supervised by expert vessel annotation in adversarial training. A skip-connection based merging process explicitly maintains class-specific gradients to avoid gradient vanishing in deep layers, to favor the discriminative features. The results show that, our model respectively improves F1-score by 4.4\%, 5.1\%, and 4.2\% compared with three state-of-the-art deep learning based methods on DRIVE-AV, LES-AV, and HRF-AV data sets.