 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKnowledge Transfer via Dense Cross-Layer Mutual-Distillation
Aug 18, 2020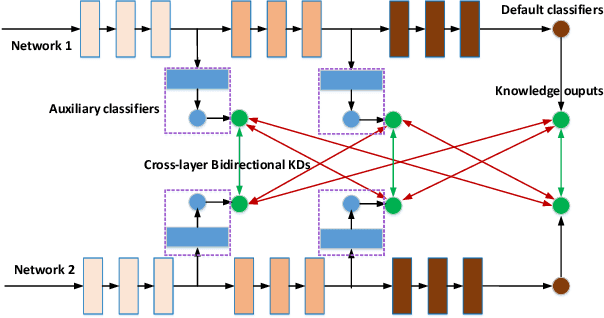
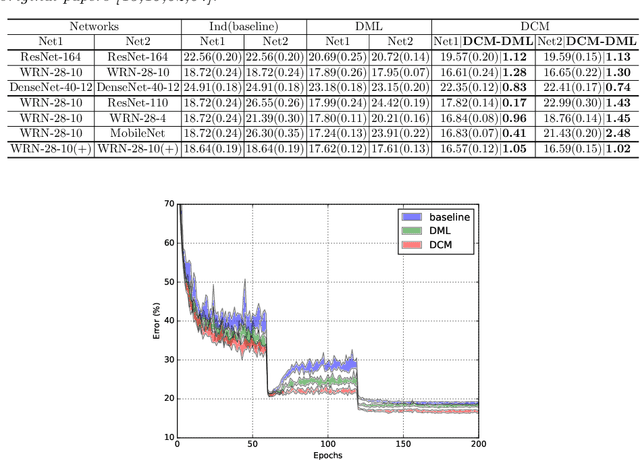

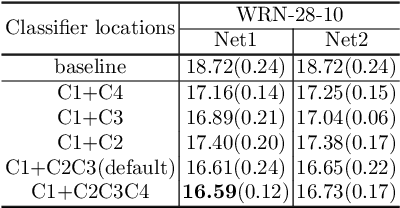
Knowledge Distillation (KD) based methods adopt the one-way Knowledge Transfer (KT) scheme in which training a lower-capacity student network is guided by a pre-trained high-capacity teacher network. Recently, Deep Mutual Learning (DML) presented a two-way KT strategy, showing that the student network can be also helpful to improve the teacher network. In this paper, we propose Dense Cross-layer Mutual-distillation (DCM), an improved two-way KT method in which the teacher and student networks are trained collaboratively from scratch. To augment knowledge representation learning, well-designed auxiliary classifiers are added to certain hidden layers of both teacher and student networks. To boost KT performance, we introduce dense bidirectional KD operations between the layers appended with classifiers. After training, all auxiliary classifiers are discarded, and thus there are no extra parameters introduced to final models. We test our method on a variety of KT tasks, showing its superiorities over related methods. Code is available at https://github.com/sundw2014/DCM
Optimistic Optimization for Statistical Model Checking with Regret Bounds
Nov 04, 2019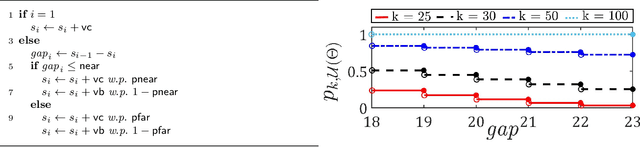
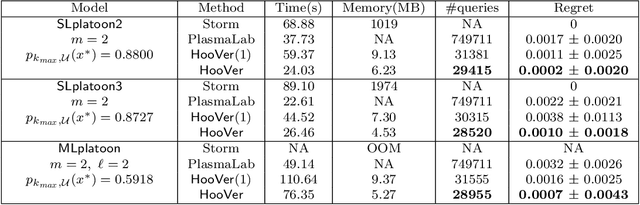
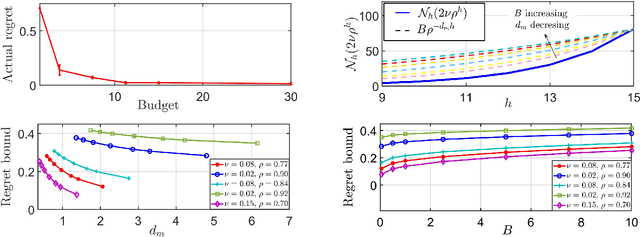
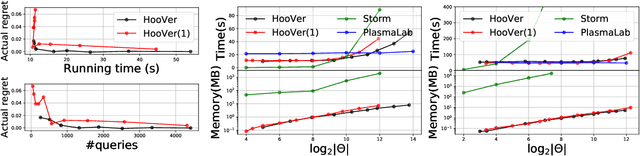
We explore application of multi-armed bandit algorithms to statistical model checking (SMC) of Markov chains initialized to a set of states. We observe that model checking problems requiring maximization of probabilities of sets of execution over all choices of the initial states, can be formulated as a multi-armed bandit problem, for appropriate costs and rewards. Therefore, the problem can be solved using multi-fidelity hierarchical optimistic optimization (MFHOO). Bandit algorithms, and MFHOO in particular, give (regret) bounds on the sample efficiency which rely on the smoothness and the near-optimality dimension of the objective function, and are a new addition to the existing types of bounds in the SMC literature. We present a new SMC tool---HooVer---built on these principles and our experiments suggest that: Compared with exact probabilistic model checking tools like Storm, HooVer scales better; compared with the statistical model checking tool PlasmaLab, HooVer can require much less data to achieve comparable results.
Learning Two-View Correspondences and Geometry Using Order-Aware Network
Aug 14, 2019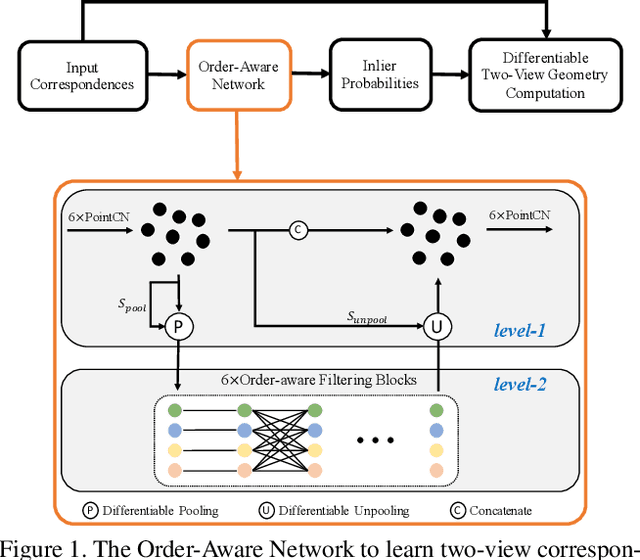
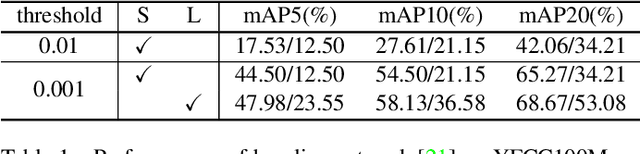
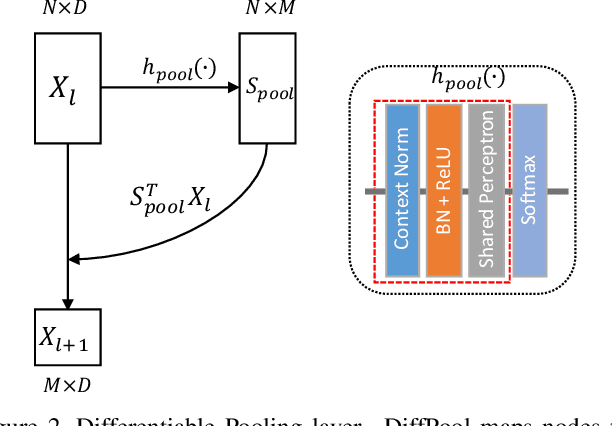
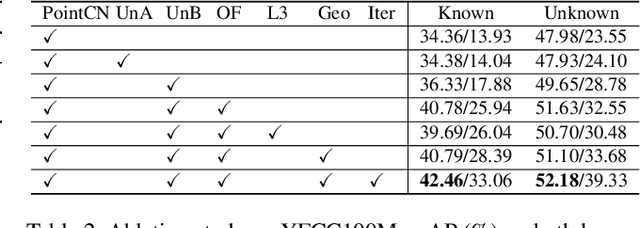
Establishing correspondences between two images requires both local and global spatial context. Given putative correspondences of feature points in two views, in this paper, we propose Order-Aware Network, which infers the probabilities of correspondences being inliers and regresses the relative pose encoded by the essential matrix. Specifically, this proposed network is built hierarchically and comprises three novel operations. First, to capture the local context of sparse correspondences, the network clusters unordered input correspondences by learning a soft assignment matrix. These clusters are in a canonical order and invariant to input permutations. Next, the clusters are spatially correlated to form the global context of correspondences. After that, the context-encoded clusters are recovered back to the original size through a proposed upsampling operator. We intensively experiment on both outdoor and indoor datasets. The accuracy of the two-view geometry and correspondences are significantly improved over the state-of-the-arts. Code will be available at https://github.com/zjhthu/OANet.git.
Deeply-supervised Knowledge Synergy
Jun 04, 2019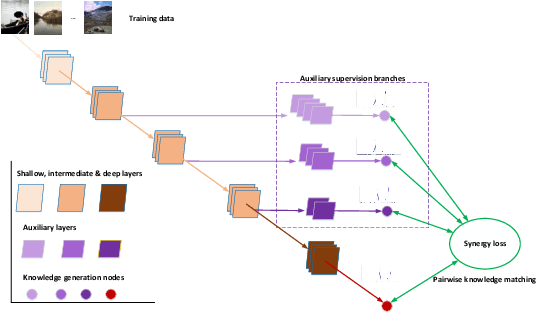
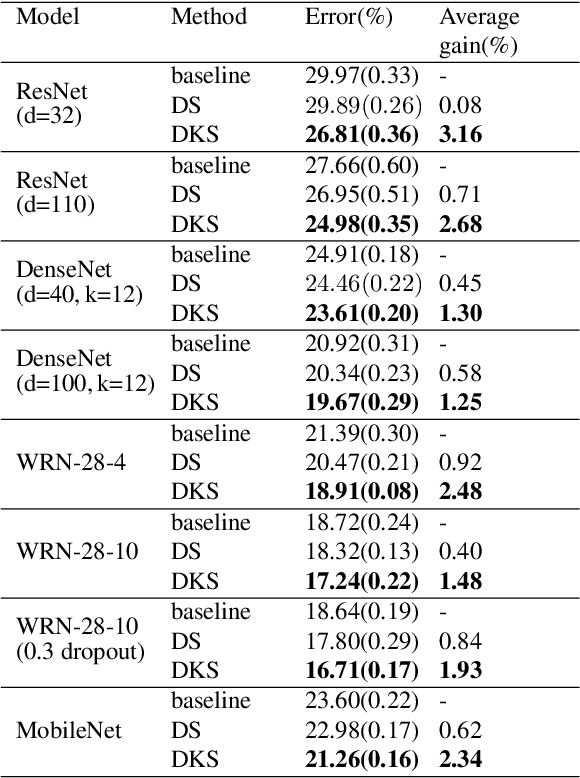
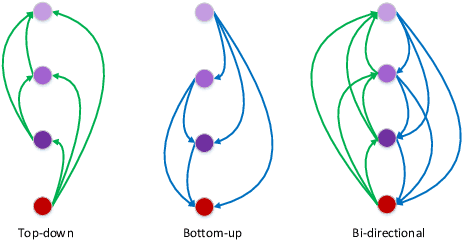
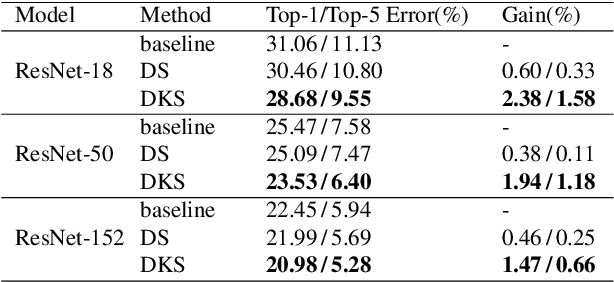
Convolutional Neural Networks (CNNs) have become deeper and more complicated compared with the pioneering AlexNet. However, current prevailing training scheme follows the previous way of adding supervision to the last layer of the network only and propagating error information up layer-by-layer. In this paper, we propose Deeply-supervised Knowledge Synergy (DKS), a new method aiming to train CNNs with improved generalization ability for image classification tasks without introducing extra computational cost during inference. Inspired by the deeply-supervised learning scheme, we first append auxiliary supervision branches on top of certain intermediate network layers. While properly using auxiliary supervision can improve model accuracy to some degree, we go one step further to explore the possibility of utilizing the probabilistic knowledge dynamically learnt by the classifiers connected to the backbone network as a new regularization to improve the training. A novel synergy loss, which considers pairwise knowledge matching among all supervision branches, is presented. Intriguingly, it enables dense pairwise knowledge matching operations in both top-down and bottom-up directions at each training iteration, resembling a dynamic synergy process for the same task. We evaluate DKS on image classification datasets using state-of-the-art CNN architectures, and show that the models trained with it are consistently better than the corresponding counterparts. For instance, on the ImageNet classification benchmark, our ResNet-152 model outperforms the baseline model with a 1.47% margin in Top-1 accuracy. Code is available at https://github.com/sundw2014/DKS.
Learn-Memorize-Recall-Reduce A Robotic Cloud Computing Paradigm
Apr 18, 2017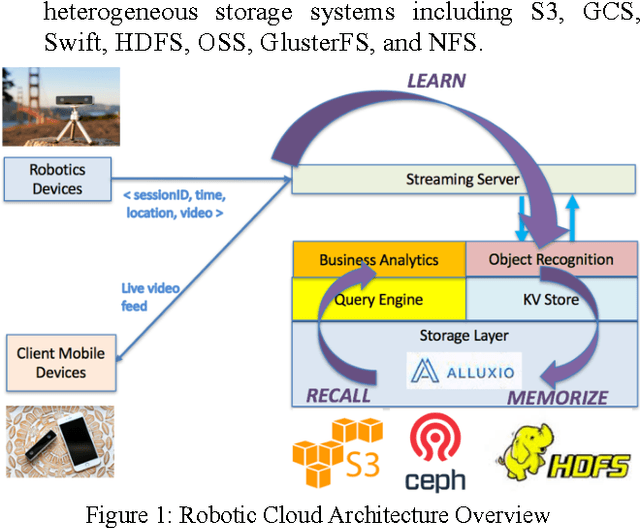
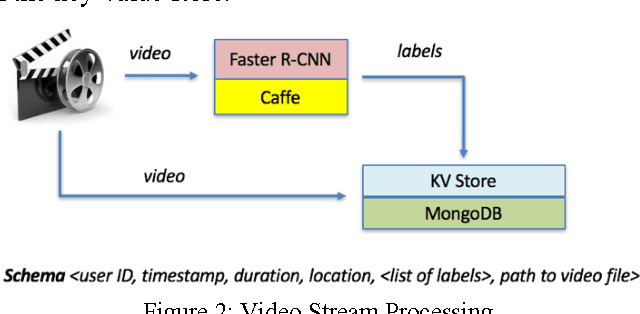
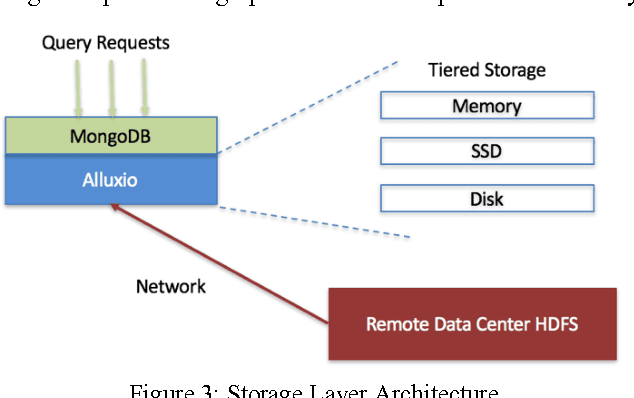
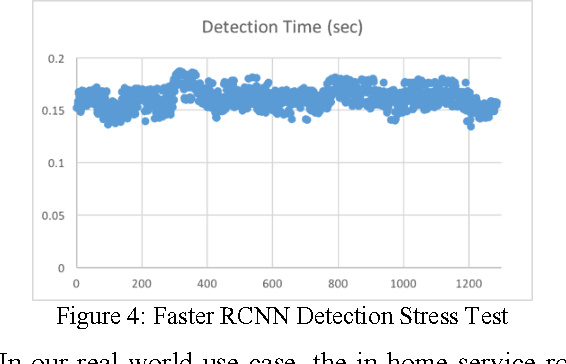
The rise of robotic applications has led to the generation of a huge volume of unstructured data, whereas the current cloud infrastructure was designed to process limited amounts of structured data. To address this problem, we propose a learn-memorize-recall-reduce paradigm for robotic cloud computing. The learning stage converts incoming unstructured data into structured data; the memorization stage provides effective storage for the massive amount of data; the recall stage provides efficient means to retrieve the raw data; while the reduction stage provides means to make sense of this massive amount of unstructured data with limited computing resources.
Enabling Embedded Inference Engine with ARM Compute Library: A Case Study
Apr 14, 2017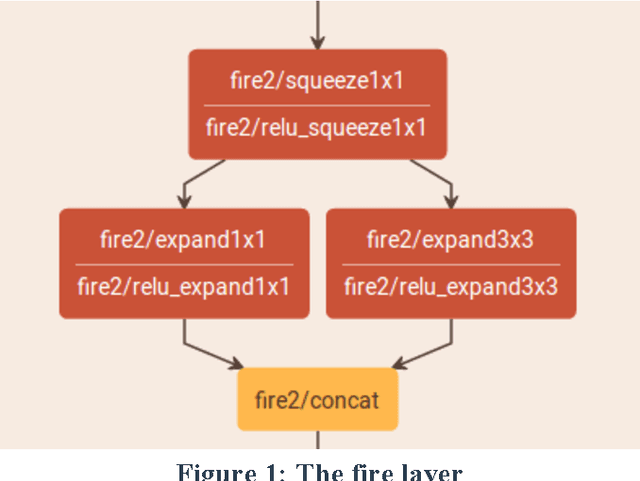
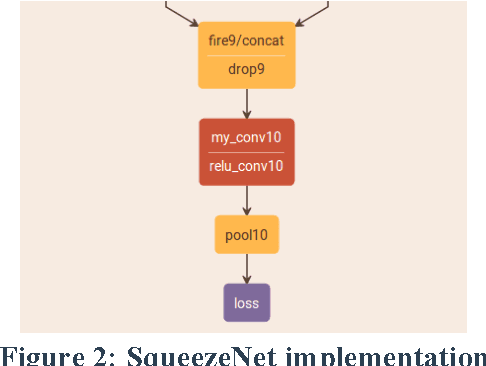
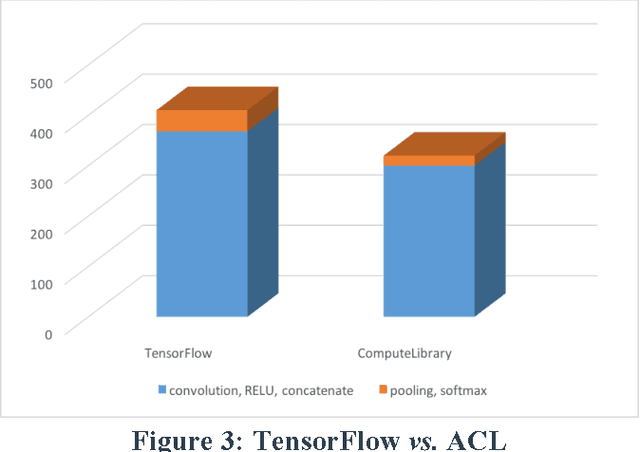
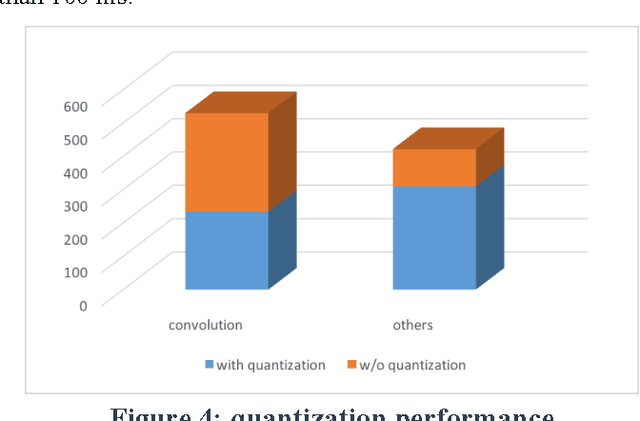
When you need to enable deep learning on low-cost embedded SoCs, is it better to port an existing deep learning framework or should you build one from scratch? In this paper, we share our practical experiences of building an embedded inference engine using ARM Compute Library (ACL). The results show that, contradictory to conventional wisdoms, for simple models, it takes much less development time to build an inference engine from scratch compared to porting existing frameworks. In addition, by utilizing ACL, we managed to build an inference engine that outperforms TensorFlow by 25%. Our conclusion is that, on embedded devices, we most likely will use very simple deep learning models for inference, and with well-developed building blocks such as ACL, it may be better in both performance and development time to build the engine from scratch.