 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKnowledge Transfer via Dense Cross-Layer Mutual-Distillation
Paper and Code
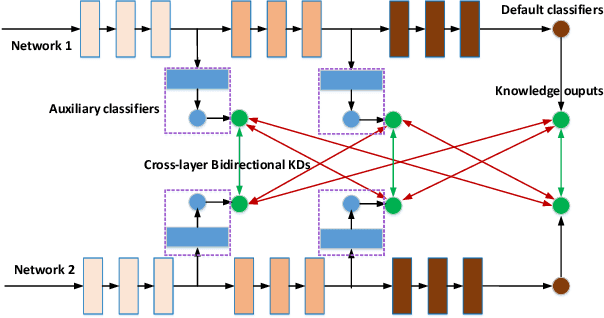
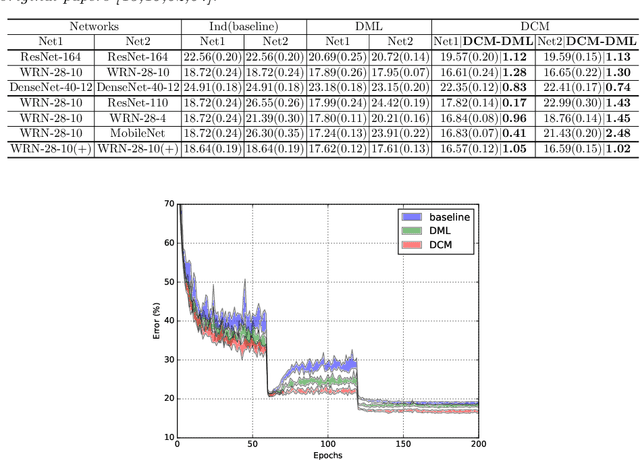

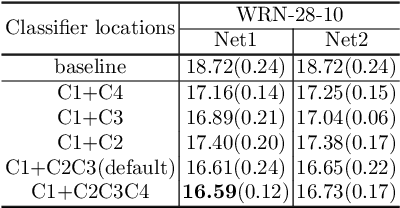
Knowledge Distillation (KD) based methods adopt the one-way Knowledge Transfer (KT) scheme in which training a lower-capacity student network is guided by a pre-trained high-capacity teacher network. Recently, Deep Mutual Learning (DML) presented a two-way KT strategy, showing that the student network can be also helpful to improve the teacher network. In this paper, we propose Dense Cross-layer Mutual-distillation (DCM), an improved two-way KT method in which the teacher and student networks are trained collaboratively from scratch. To augment knowledge representation learning, well-designed auxiliary classifiers are added to certain hidden layers of both teacher and student networks. To boost KT performance, we introduce dense bidirectional KD operations between the layers appended with classifiers. After training, all auxiliary classifiers are discarded, and thus there are no extra parameters introduced to final models. We test our method on a variety of KT tasks, showing its superiorities over related methods. Code is available at https://github.com/sundw2014/DCM