 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhen Should Agents Coordinate in Differentiable Sequential Decision Problems?
Feb 03, 2026Multi-robot teams must coordinate to operate effectively. When a team operates in an uncoordinated manner, and agents choose actions that are only individually optimal, the team's outcome can suffer. However, in many domains, coordination requires costly communication. We explore the value of coordination in a broad class of differentiable motion-planning problems. In particular, we model coordinated behavior as a spectrum: at one extreme, agents jointly optimize a common team objective, and at the other, agents make unilaterally optimal decisions given their individual decision variables, i.e., they operate at Nash equilibria. We then demonstrate that reasoning about coordination in differentiable motion-planning problems reduces to reasoning about the second-order properties of agents' objectives, and we provide algorithms that use this second-order reasoning to determine at which times a team of agents should coordinate.
Efficiently Solving Mixed-Hierarchy Games with Quasi-Policy Approximations
Feb 02, 2026Multi-robot coordination often exhibits hierarchical structure, with some robots' decisions depending on the planned behaviors of others. While game theory provides a principled framework for such interactions, existing solvers struggle to handle mixed information structures that combine simultaneous (Nash) and hierarchical (Stackelberg) decision-making. We study N-robot forest-structured mixed-hierarchy games, in which each robot acts as a Stackelberg leader over its subtree while robots in different branches interact via Nash equilibria. We derive the Karush-Kuhn-Tucker (KKT) first-order optimality conditions for this class of games and show that they involve increasingly high-order derivatives of robots' best-response policies as the hierarchy depth grows, rendering a direct solution intractable. To overcome this challenge, we introduce a quasi-policy approximation that removes higher-order policy derivatives and develop an inexact Newton method for efficiently solving the resulting approximated KKT systems. We prove local exponential convergence of the proposed algorithm for games with non-quadratic objectives and nonlinear constraints. The approach is implemented in a highly optimized Julia library (MixedHierarchyGames.jl) and evaluated in simulated experiments, demonstrating real-time convergence for complex mixed-hierarchy information structures.
Generalized Information Gathering Under Dynamics Uncertainty
Jan 29, 2026An agent operating in an unknown dynamical system must learn its dynamics from observations. Active information gathering accelerates this learning, but existing methods derive bespoke costs for specific modeling choices: dynamics models, belief update procedures, observation models, and planners. We present a unifying framework that decouples these choices from the information-gathering cost by explicitly exposing the causal dependencies between parameters, beliefs, and controls. Using this framework, we derive a general information-gathering cost based on Massey's directed information that assumes only Markov dynamics with additive noise and is otherwise agnostic to modeling choices. We prove that the mutual information cost used in existing literature is a special case of our cost. Then, we leverage our framework to establish an explicit connection between the mutual information cost and information gain in linearized Bayesian estimation, thereby providing theoretical justification for mutual information-based active learning approaches. Finally, we illustrate the practical utility of our framework through experiments spanning linear, nonlinear, and multi-agent systems.
Game-Theoretic Autonomous Driving: A Graphs of Convex Sets Approach
Jan 27, 2026Multi-vehicle autonomous driving couples strategic interaction with hybrid (discrete-continuous) maneuver planning under shared safety constraints. We introduce IBR-GCS, an Iterative Best Response (IBR) planning approach based on the Graphs of Convex Sets (GCS) framework that models highway driving as a generalized noncooperative game. IBR-GCS integrates combinatorial maneuver reasoning, trajectory planning, and game-theoretic interaction within a unified framework. The key novelty is a vehicle-specific, strategy-dependent GCS construction. Specifically, at each best-response update, each vehicle builds its own graph conditioned on the current strategies of the other vehicles, with vertices representing lane-specific, time-varying, convex, collision-free regions and edges encoding dynamically feasible transitions. This yields a shortest-path problem in GCS for each best-response step, which admits an efficient convex relaxation that can be solved using convex optimization tools without exhaustive discrete tree search. We then apply an iterative best-response scheme in which vehicles update their trajectories sequentially and provide conditions under which the resulting inexact updates converge to an approximate generalized Nash equilibrium. Simulation results across multi-lane, multi-vehicle scenarios demonstrate that IBR-GCS produces safe trajectories and strategically consistent interactive behaviors.
Bayesian Inverse Games with High-Dimensional Multi-Modal Observations
Jan 02, 2026Many multi-agent interaction scenarios can be naturally modeled as noncooperative games, where each agent's decisions depend on others' future actions. However, deploying game-theoretic planners for autonomous decision-making requires a specification of all agents' objectives. To circumvent this practical difficulty, recent work develops maximum likelihood techniques for solving inverse games that can identify unknown agent objectives from interaction data. Unfortunately, these methods only infer point estimates and do not quantify estimator uncertainty; correspondingly, downstream planning decisions can overconfidently commit to unsafe actions. We present an approximate Bayesian inference approach for solving the inverse game problem, which can incorporate observation data from multiple modalities and be used to generate samples from the Bayesian posterior over the hidden agent objectives given limited sensor observations in real time. Concretely, the proposed Bayesian inverse game framework trains a structured variational autoencoder with an embedded differentiable Nash game solver on interaction datasets and does not require labels of agents' true objectives. Extensive experiments show that our framework successfully learns prior and posterior distributions, improves inference quality over maximum likelihood estimation-based inverse game approaches, and enables safer downstream decision-making without sacrificing efficiency. When trajectory information is uninformative or unavailable, multimodal inference further reduces uncertainty by exploiting additional observation modalities.
SCOPED: Score-Curvature Out-of-distribution Proximity Evaluator for Diffusion
Oct 01, 2025Out-of-distribution (OOD) detection is essential for reliable deployment of machine learning systems in vision, robotics, reinforcement learning, and beyond. We introduce Score-Curvature Out-of-distribution Proximity Evaluator for Diffusion (SCOPED), a fast and general-purpose OOD detection method for diffusion models that reduces the number of forward passes on the trained model by an order of magnitude compared to prior methods, outperforming most diffusion-based baselines and closely approaching the accuracy of the strongest ones. SCOPED is computed from a single diffusion model trained once on a diverse dataset, and combines the Jacobian trace and squared norm of the model's score function into a single test statistic. Rather than thresholding on a fixed value, we estimate the in-distribution density of SCOPED scores using kernel density estimation, enabling a flexible, unsupervised test that, in the simplest case, only requires a single forward pass and one Jacobian-vector product (JVP), made efficient by Hutchinson's trace estimator. On four vision benchmarks, SCOPED achieves competitive or state-of-the-art precision-recall scores despite its low computational cost. The same method generalizes to robotic control tasks with shared state and action spaces, identifying distribution shifts across reward functions and training regimes. These results position SCOPED as a practical foundation for fast and reliable OOD detection in real-world domains, including perceptual artifacts in vision, outlier detection in autoregressive models, exploration in reinforcement learning, and dataset curation for unsupervised training.
Fixing That Free Lunch: When, Where, and Why Synthetic Data Fails in Model-Based Policy Optimization
Oct 01, 2025Synthetic data is a core component of data-efficient Dyna-style model-based reinforcement learning, yet it can also degrade performance. We study when it helps, where it fails, and why, and we show that addressing the resulting failure modes enables policy improvement that was previously unattainable. We focus on Model-Based Policy Optimization (MBPO), which performs actor and critic updates using synthetic action counterfactuals. Despite reports of strong and generalizable sample-efficiency gains in OpenAI Gym, recent work shows that MBPO often underperforms its model-free counterpart, Soft Actor-Critic (SAC), in the DeepMind Control Suite (DMC). Although both suites involve continuous control with proprioceptive robots, this shift leads to sharp performance losses across seven challenging DMC tasks, with MBPO failing in cases where claims of generalization from Gym would imply success. This reveals how environment-specific assumptions can become implicitly encoded into algorithm design when evaluation is limited. We identify two coupled issues behind these failures: scale mismatches between dynamics and reward models that induce critic underestimation and hinder policy improvement during model-policy coevolution, and a poor choice of target representation that inflates model variance and produces error-prone rollouts. Addressing these failure modes enables policy improvement where none was previously possible, allowing MBPO to outperform SAC in five of seven tasks while preserving the strong performance previously reported in OpenAI Gym. Rather than aiming only for incremental average gains, we hope our findings motivate the community to develop taxonomies that tie MDP task- and environment-level structure to algorithmic failure modes, pursue unified solutions where possible, and clarify how benchmark choices ultimately shape the conditions under which algorithms generalize.
SHIELD: Safety on Humanoids via CBFs In Expectation on Learned Dynamics
May 16, 2025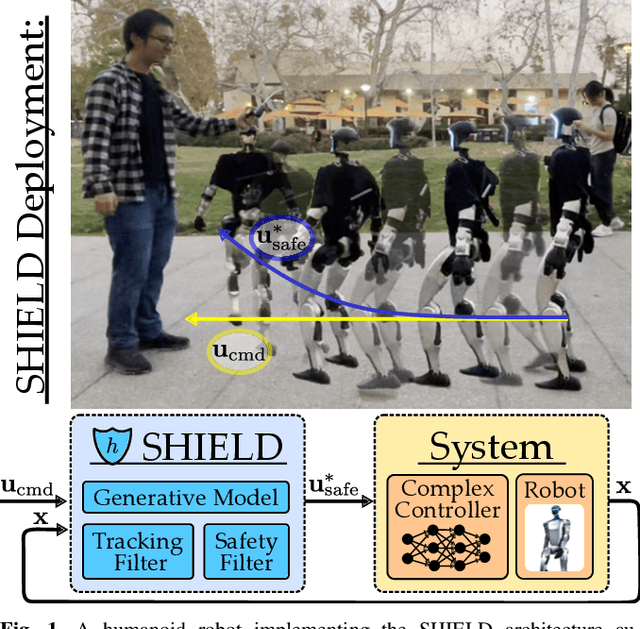

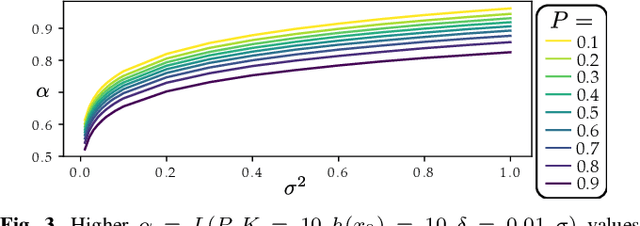
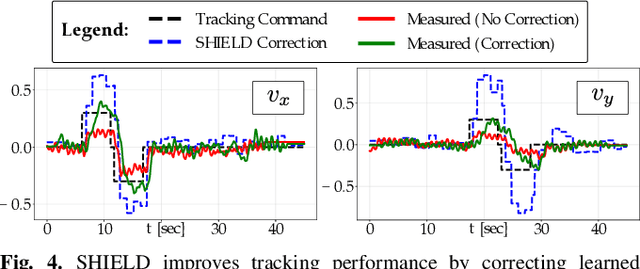
Robot learning has produced remarkably effective ``black-box'' controllers for complex tasks such as dynamic locomotion on humanoids. Yet ensuring dynamic safety, i.e., constraint satisfaction, remains challenging for such policies. Reinforcement learning (RL) embeds constraints heuristically through reward engineering, and adding or modifying constraints requires retraining. Model-based approaches, like control barrier functions (CBFs), enable runtime constraint specification with formal guarantees but require accurate dynamics models. This paper presents SHIELD, a layered safety framework that bridges this gap by: (1) training a generative, stochastic dynamics residual model using real-world data from hardware rollouts of the nominal controller, capturing system behavior and uncertainties; and (2) adding a safety layer on top of the nominal (learned locomotion) controller that leverages this model via a stochastic discrete-time CBF formulation enforcing safety constraints in probability. The result is a minimally-invasive safety layer that can be added to the existing autonomy stack to give probabilistic guarantees of safety that balance risk and performance. In hardware experiments on an Unitree G1 humanoid, SHIELD enables safe navigation (obstacle avoidance) through varied indoor and outdoor environments using a nominal (unknown) RL controller and onboard perception.
Real-Time Privacy Preservation for Robot Visual Perception
May 08, 2025Many robots (e.g., iRobot's Roomba) operate based on visual observations from live video streams, and such observations may inadvertently include privacy-sensitive objects, such as personal identifiers. Existing approaches for preserving privacy rely on deep learning models, differential privacy, or cryptography. They lack guarantees for the complete concealment of all sensitive objects. Guaranteeing concealment requires post-processing techniques and thus is inadequate for real-time video streams. We develop a method for privacy-constrained video streaming, PCVS, that conceals sensitive objects within real-time video streams. PCVS takes a logical specification constraining the existence of privacy-sensitive objects, e.g., never show faces when a person exists. It uses a detection model to evaluate the existence of these objects in each incoming frame. Then, it blurs out a subset of objects such that the existence of the remaining objects satisfies the specification. We then propose a conformal prediction approach to (i) establish a theoretical lower bound on the probability of the existence of these objects in a sequence of frames satisfying the specification and (ii) update the bound with the arrival of each subsequent frame. Quantitative evaluations show that PCVS achieves over 95 percent specification satisfaction rate in multiple datasets, significantly outperforming other methods. The satisfaction rate is consistently above the theoretical bounds across all datasets, indicating that the established bounds hold. Additionally, we deploy PCVS on robots in real-time operation and show that the robots operate normally without being compromised when PCVS conceals objects.
Act Natural! Extending Naturalistic Projection to Multimodal Behavior Scenarios
May 03, 2025Autonomous agents operating in public spaces must consider how their behaviors might affect the humans around them, even when not directly interacting with them. To this end, it is often beneficial to be predictable and appear naturalistic. Existing methods for this purpose use human actor intent modeling or imitation learning techniques, but these approaches rarely capture all possible motivations for human behavior and/or require significant amounts of data. Our work extends a technique for modeling unimodal naturalistic behaviors with an explicit convex set representation, to account for multimodal behavior by using multiple convex sets. This more flexible representation provides a higher degree of fidelity in data-driven modeling of naturalistic behavior that arises in real-world scenarios in which human behavior is, in some sense, discrete, e.g. whether or not to yield at a roundabout. Equipped with this new set representation, we develop an optimization-based filter to project arbitrary trajectories into the set so that they appear naturalistic to humans in the scene, while also satisfying vehicle dynamics, actuator limits, etc. We demonstrate our methods on real-world human driving data from the inD (intersection) and rounD (roundabout) datasets.