 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTaskNPoint: How to Teach Your Humanoid to Hit a Backhand in Minutes
Jun 24, 2026How do we learn to hit a tennis backhand? Not from a thousand hours of tennis tournaments on TV - we work with a coach and practice. We argue this is also the right recipe for teaching dynamic skills to humanoid robots. This follows from a structural property of dynamic skills: the outcome is decided by a short, crucial portion of the trajectory - for a backhand, the ~20cm of racket travel around ball contact. Getting this interaction window right requires coordinating the whole motion, so that control, physics, and morphology act in concert. Learning thus reduces to mastering a handful of distinct actions and, for each, practicing until the window comes out right. To this end, we introduce TaskNPoint, a training protocol which makes the coach-learner division of labor explicit. The human coach contributes four inputs: a discrete set of skills (e.g. different shots), one demonstration per skill, identification of the interaction window, and the goal. Learning in a physically realistic simulation environment fills in each action trajectory and provides robustness to unmodeled events. Crucially, randomized target sampling during training lets a single demonstration generalize zero-shot to unseen goal locations. We test this approach on a Unitree G1 humanoid that hits forehands and backhands against balls thrown by a human, kicks incoming soccer balls, and picks and places boxes from novel locations. We find that learning is successful from short human video demonstrations and under an hour of training on a single GPU, with no per-task reward tuning.
CalTennis: Large Multi-View Tennis Video Dataset and Benchmark of Monocular-to-3D Pose Estimation
Jun 18, 2026The Caltech Tennis Dataset (CalTennis) is a large-scale video benchmark for evaluating monocular-to-3D pose estimation in the wild. CalTennis comprises over 11 million frames (51 hours) of tennis practice and match play from 40 players, captured with 2-6 synchronized cameras at 60 Hz. It is 10 times larger than existing in-the-wild human motion video datasets and 3 times larger than existing MOCAP-ground-truthed datasets, and it is the first large-scale benchmark to provide synchronized multi-view recordings of expert athletic motion. The multi-view setup enables inexpensive, label-free evaluation of monocular-to-3D pose estimation algorithms. We describe a simple, standardized protocol that enables data collection without specialized equipment or expertise, along with fully automated video calibration and synchronization. Benchmarking state-of-the-art monocular-to-3D pose methods on CalTennis, we find that while 3D joint angle recovery is now quite accurate, all models struggle to estimate depth and foot contact consistently. We further propose two novel performance metrics, footwork and stability, as well as qualitatively study body shape inconsistency. These metrics expose previously underexplored failure modes and point to concrete opportunities for improvement in pose estimation and action analysis.
HALO: Hybrid Auto-encoded Locomotion with Learned Latent Dynamics, Poincaré Maps, and Regions of Attraction
Apr 20, 2026Reduced-order models are powerful for analyzing and controlling high-dimensional dynamical systems. Yet constructing these models for complex hybrid systems such as legged robots remains challenging. Classical approaches rely on hand-designed template models (e.g., LIP, SLIP), which, though insightful, only approximate the underlying dynamics. In contrast, data-driven methods can extract more accurate low-dimensional representations, but it remains unclear when stability and safety properties observed in the latent space meaningfully transfer back to the full-order system. To bridge this gap, we introduce HALO (Hybrid Auto-encoded Locomotion), a framework for learning latent reduced-order models of periodic hybrid dynamics directly from trajectory data. HALO employs an autoencoder to identify a low-dimensional latent state together with a learned latent Poincaré map that captures step-to-step locomotion dynamics. This enables Lyapunov analysis and the construction of an associated region of attraction in the latent space, both of which can be lifted back to the full-order state space through the decoder. Experiments on a simulated hopping robot and full-body humanoid locomotion demonstrate that HALO yields low-dimensional models that retain meaningful stability structure and predict full-order region-of-attraction boundaries.
CBF-RL: Safety Filtering Reinforcement Learning in Training with Control Barrier Functions
Oct 16, 2025Reinforcement learning (RL), while powerful and expressive, can often prioritize performance at the expense of safety. Yet safety violations can lead to catastrophic outcomes in real-world deployments. Control Barrier Functions (CBFs) offer a principled method to enforce dynamic safety -- traditionally deployed \emph{online} via safety filters. While the result is safe behavior, the fact that the RL policy does not have knowledge of the CBF can lead to conservative behaviors. This paper proposes CBF-RL, a framework for generating safe behaviors with RL by enforcing CBFs \emph{in training}. CBF-RL has two key attributes: (1) minimally modifying a nominal RL policy to encode safety constraints via a CBF term, (2) and safety filtering of the policy rollouts in training. Theoretically, we prove that continuous-time safety filters can be deployed via closed-form expressions on discrete-time roll-outs. Practically, we demonstrate that CBF-RL internalizes the safety constraints in the learned policy -- both enforcing safer actions and biasing towards safer rewards -- enabling safe deployment without the need for an online safety filter. We validate our framework through ablation studies on navigation tasks and on the Unitree G1 humanoid robot, where CBF-RL enables safer exploration, faster convergence, and robust performance under uncertainty, enabling the humanoid robot to avoid obstacles and climb stairs safely in real-world settings without a runtime safety filter.
Bracing for Impact: Robust Humanoid Push Recovery and Locomotion with Reduced Order Models
May 16, 2025



Push recovery during locomotion will facilitate the deployment of humanoid robots in human-centered environments. In this paper, we present a unified framework for walking control and push recovery for humanoid robots, leveraging the arms for push recovery while dynamically walking. The key innovation is to use the environment, such as walls, to facilitate push recovery by combining Single Rigid Body model predictive control (SRB-MPC) with Hybrid Linear Inverted Pendulum (HLIP) dynamics to enable robust locomotion, push detection, and recovery by utilizing the robot's arms to brace against such walls and dynamically adjusting the desired contact forces and stepping patterns. Extensive simulation results on a humanoid robot demonstrate improved perturbation rejection and tracking performance compared to HLIP alone, with the robot able to recover from pushes up to 100N for 0.2s while walking at commanded speeds up to 0.5m/s. Robustness is further validated in scenarios with angled walls and multi-directional pushes.
SHIELD: Safety on Humanoids via CBFs In Expectation on Learned Dynamics
May 16, 2025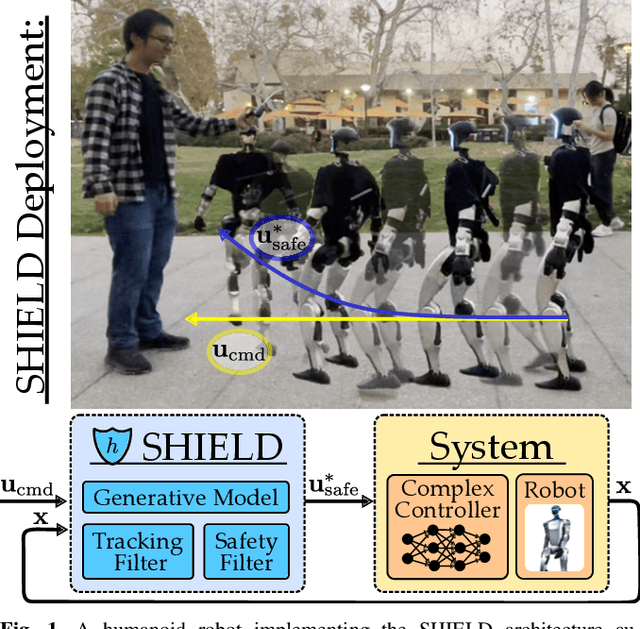

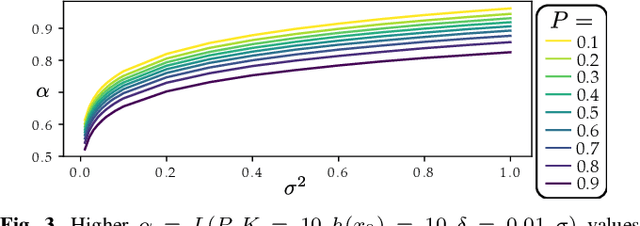
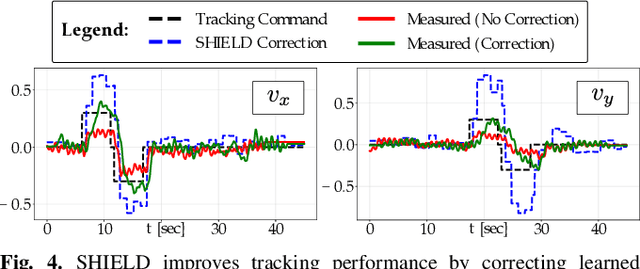
Robot learning has produced remarkably effective ``black-box'' controllers for complex tasks such as dynamic locomotion on humanoids. Yet ensuring dynamic safety, i.e., constraint satisfaction, remains challenging for such policies. Reinforcement learning (RL) embeds constraints heuristically through reward engineering, and adding or modifying constraints requires retraining. Model-based approaches, like control barrier functions (CBFs), enable runtime constraint specification with formal guarantees but require accurate dynamics models. This paper presents SHIELD, a layered safety framework that bridges this gap by: (1) training a generative, stochastic dynamics residual model using real-world data from hardware rollouts of the nominal controller, capturing system behavior and uncertainties; and (2) adding a safety layer on top of the nominal (learned locomotion) controller that leverages this model via a stochastic discrete-time CBF formulation enforcing safety constraints in probability. The result is a minimally-invasive safety layer that can be added to the existing autonomy stack to give probabilistic guarantees of safety that balance risk and performance. In hardware experiments on an Unitree G1 humanoid, SHIELD enables safe navigation (obstacle avoidance) through varied indoor and outdoor environments using a nominal (unknown) RL controller and onboard perception.