 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeManifold Criterion Guided Transfer Learning via Intermediate Domain Generation
Mar 25, 2019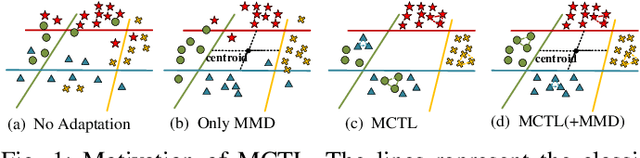
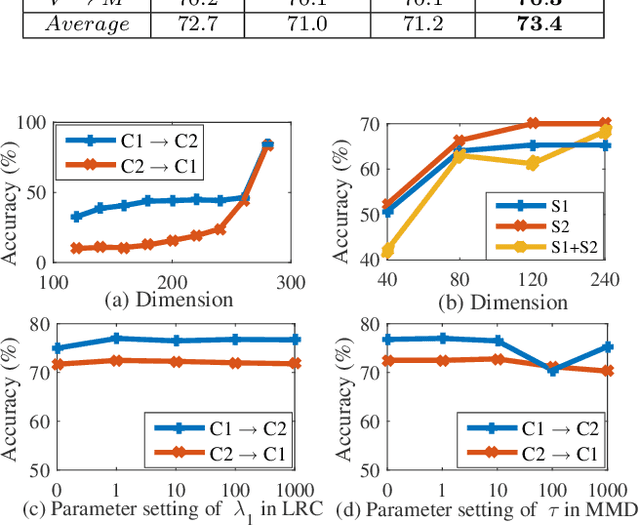
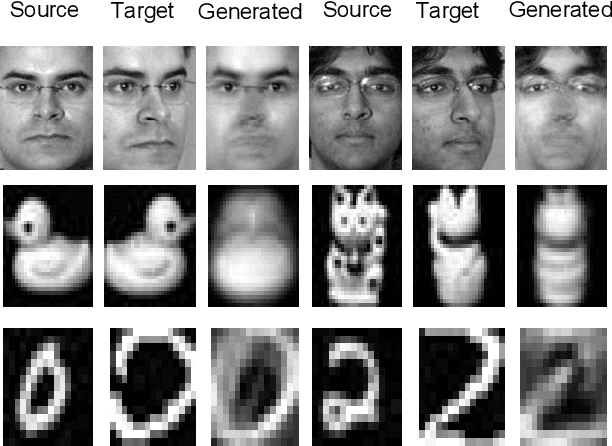
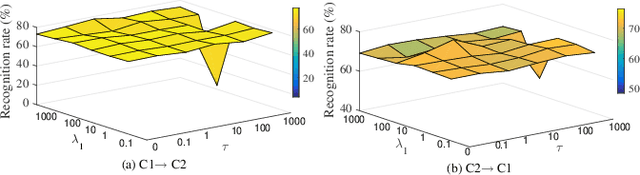
In many practical transfer learning scenarios, the feature distribution is different across the source and target domains (i.e. non-i.i.d.). Maximum mean discrepancy (MMD), as a domain discrepancy metric, has achieved promising performance in unsupervised domain adaptation (DA). We argue that MMD-based DA methods ignore the data locality structure, which, to some extent, would cause the negative transfer effect. The locality plays an important role in minimizing the nonlinear local domain discrepancy underlying the marginal distributions. For better exploiting the domain locality, a novel local generative discrepancy metric (LGDM) based intermediate domain generation learning called Manifold Criterion guided Transfer Learning (MCTL) is proposed in this paper. The merits of the proposed MCTL are four-fold: 1) the concept of manifold criterion (MC) is first proposed as a measure validating the distribution matching across domains, and domain adaptation is achieved if the MC is satisfied; 2) the proposed MC can well guide the generation of the intermediate domain sharing similar distribution with the target domain, by minimizing the local domain discrepancy; 3) a global generative discrepancy metric (GGDM) is presented, such that both the global and local discrepancy can be effectively and positively reduced; 4) a simplified version of MCTL called MCTL-S is presented under a perfect domain generation assumption for more generic learning scenario. Experiments on a number of benchmark visual transfer tasks demonstrate the superiority of the proposed manifold criterion guided generative transfer method, by comparing with other state-of-the-art methods. The source code is available in https://github.com/wangshanshanCQU/MCTL.
Simultaneous Fidelity and Regularization Learning for Image Restoration
Oct 16, 2018



Most existing non-blind restoration methods are based on the assumption that a precise degradation model is known. As the degradation process can only partially known or inaccurately modeled, images may not be well restored. Rain streak removal and image deconvolution with inaccurate blur kernels are two representative examples of such tasks. For rain streak removal, although an input image can be decomposed into a scene layer and a rain streak layer, there exists no explicit formulation for modeling rain streaks and the composition with scene layer. For blind deconvolution, as estimation error of blur kernel is usually introduced, the subsequent non-blind deconvolution process does not restore the latent image well. In this paper, we propose a principled algorithm within the maximum a posterior framework to tackle image restoration with a partially known or inaccurate degradation model. Specifically, the residual caused by a partially known or inaccurate degradation model is spatially dependent and complexly distributed. With a training set of degraded and ground-truth image pairs, we parameterize and learn the fidelity term for a degradation model in a task-driven manner. Furthermore, the regularization term can also be learned along with the fidelity term, thereby forming a simultaneous fidelity and regularization learning model. Extensive experimental results demonstrate the effectiveness of the proposed model for image deconvolution with inaccurate blur kernels and rain streak removal. Furthermore, for image restoration with precise degradation process, e.g., Gaussian denoising, the proposed model can be applied to learn the proper fidelity term for optimal performance based on visual perception metrics.
External Prior Guided Internal Prior Learning for Real-World Noisy Image Denoising
Oct 15, 2018



Most of existing image denoising methods learn image priors from either external data or the noisy image itself to remove noise. However, priors learned from external data may not be adaptive to the image to be denoised, while priors learned from the given noisy image may not be accurate due to the interference of corrupted noise. Meanwhile, the noise in real-world noisy images is very complex, which is hard to be described by simple distributions such as Gaussian distribution, making real-world noisy image denoising a very challenging problem. We propose to exploit the information in both external data and the given noisy image, and develop an external prior guided internal prior learning method for real-world noisy image denoising. We first learn external priors from an independent set of clean natural images. With the aid of learned external priors, we then learn internal priors from the given noisy image to refine the prior model. The external and internal priors are formulated as a set of orthogonal dictionaries to efficiently reconstruct the desired image. Extensive experiments are performed on several real-world noisy image datasets. The proposed method demonstrates highly competitive denoising performance, outperforming state-of-the-art denoising methods including those designed for real-world noisy images.
A Trilateral Weighted Sparse Coding Scheme for Real-World Image Denoising
Jul 11, 2018
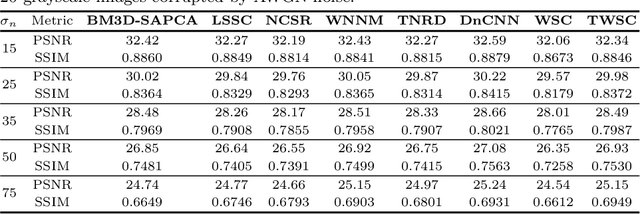


Most of existing image denoising methods assume the corrupted noise to be additive white Gaussian noise (AWGN). However, the realistic noise in real-world noisy images is much more complex than AWGN, and is hard to be modelled by simple analytical distributions. As a result, many state-of-the-art denoising methods in literature become much less effective when applied to real-world noisy images captured by CCD or CMOS cameras. In this paper, we develop a trilateral weighted sparse coding (TWSC) scheme for robust real-world image denoising. Specifically, we introduce three weight matrices into the data and regularisation terms of the sparse coding framework to characterise the statistics of realistic noise and image priors. TWSC can be reformulated as a linear equality-constrained problem and can be solved by the alternating direction method of multipliers. The existence and uniqueness of the solution and convergence of the proposed algorithm are analysed. Extensive experiments demonstrate that the proposed TWSC scheme outperforms state-of-the-art denoising methods on removing realistic noise.
Enlarging Context with Low Cost: Efficient Arithmetic Coding with Trimmed Convolution
Jul 03, 2018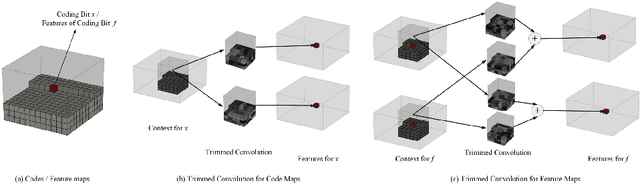
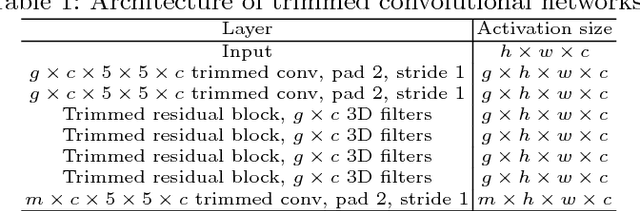
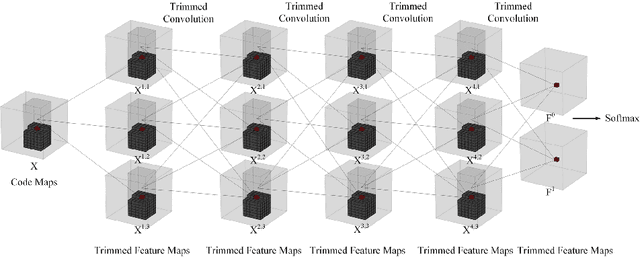
Arithmetic coding is an essential class of coding techniques. One key issue of arithmetic encoding method is to predict the probability of the current coding symbol from its context, i.e., the preceding encoded symbols, which usually can be executed by building a look-up table (LUT). However, the complexity of LUT increases exponentially with the length of context. Thus, such solutions are limited to modeling large context, which inevitably restricts the compression performance. Several recent deep neural network-based solutions have been developed to account for large context, but are still costly in computation. The inefficiency of the existing methods are mainly attributed to that probability prediction is performed independently for the neighboring symbols, which actually can be efficiently conducted by shared computation. To this end, we propose a trimmed convolutional network for arithmetic encoding (TCAE) to model large context while maintaining computational efficiency. As for trimmed convolution, the convolutional kernels are specially trimmed to respect the compression order and context dependency of the input symbols. Benefited from trimmed convolution, the probability prediction of all symbols can be efficiently performed in one single forward pass via a fully convolutional network. Furthermore, to speed up the decoding process, a slope TCAE model is presented to divide the codes from a 3D code map into several blocks and remove the dependency between the codes inner one block for parallel decoding, which can 60x speed up the decoding process. Experiments show that our TCAE and slope TCAE attain better compression ratio in lossless gray image compression, and can be adopted in CNN-based lossy image compression to achieve state-of-the-art rate-distortion performance with real-time encoding speed.
Real-world Noisy Image Denoising: A New Benchmark
Apr 07, 2018



Most of previous image denoising methods focus on additive white Gaussian noise (AWGN). However,the real-world noisy image denoising problem with the advancing of the computer vision techiniques. In order to promote the study on this problem while implementing the concurrent real-world image denoising datasets, we construct a new benchmark dataset which contains comprehensive real-world noisy images of different natural scenes. These images are captured by different cameras under different camera settings. We evaluate the different denoising methods on our new dataset as well as previous datasets. Extensive experimental results demonstrate that the recently proposed methods designed specifically for realistic noise removal based on sparse or low rank theories achieve better denoising performance and are more robust than other competing methods, and the newly proposed dataset is more challenging. The constructed dataset of real photographs is publicly available at \url{https://github.com/csjunxu/PolyUDataset} for researchers to investigate new real-world image denoising methods. We will add more analysis on the noise statistics in the real photographs of our new dataset in the next version of this article.
Dual Asymmetric Deep Hashing Learning
Jan 25, 2018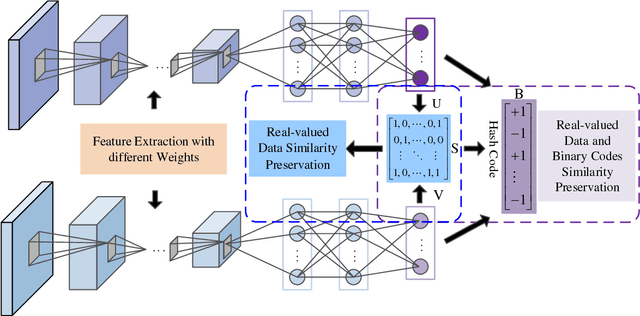
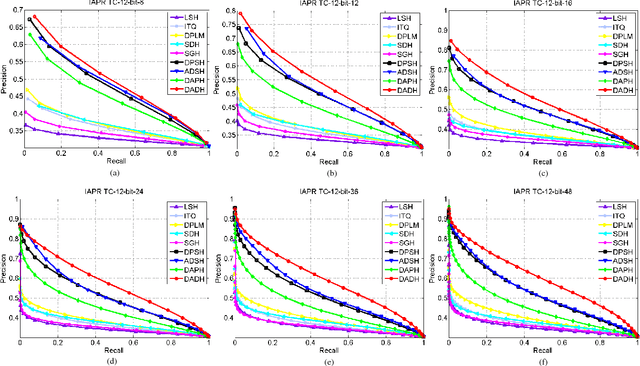
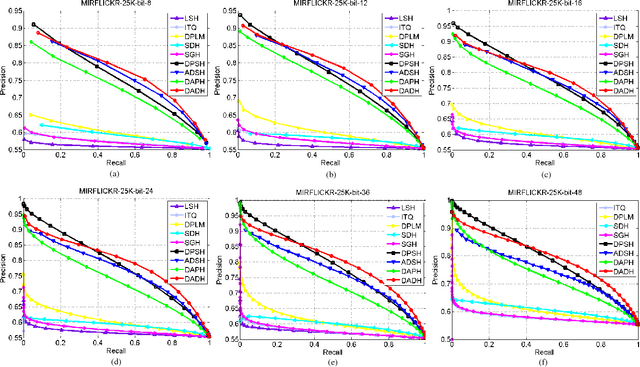
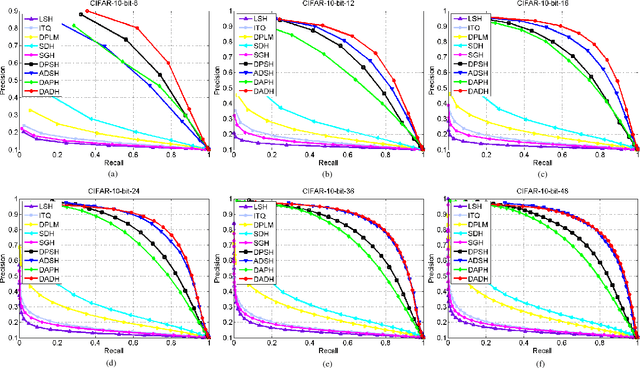
Due to the impressive learning power, deep learning has achieved a remarkable performance in supervised hash function learning. In this paper, we propose a novel asymmetric supervised deep hashing method to preserve the semantic structure among different categories and generate the binary codes simultaneously. Specifically, two asymmetric deep networks are constructed to reveal the similarity between each pair of images according to their semantic labels. The deep hash functions are then learned through two networks by minimizing the gap between the learned features and discrete codes. Furthermore, since the binary codes in the Hamming space also should keep the semantic affinity existing in the original space, another asymmetric pairwise loss is introduced to capture the similarity between the binary codes and real-value features. This asymmetric loss not only improves the retrieval performance, but also contributes to a quick convergence at the training phase. By taking advantage of the two-stream deep structures and two types of asymmetric pairwise functions, an alternating algorithm is designed to optimize the deep features and high-quality binary codes efficiently. Experimental results on three real-world datasets substantiate the effectiveness and superiority of our approach as compared with state-of-the-art.
Integrating Boundary and Center Correlation Filters for Visual Tracking with Aspect Ratio Variation
Oct 05, 2017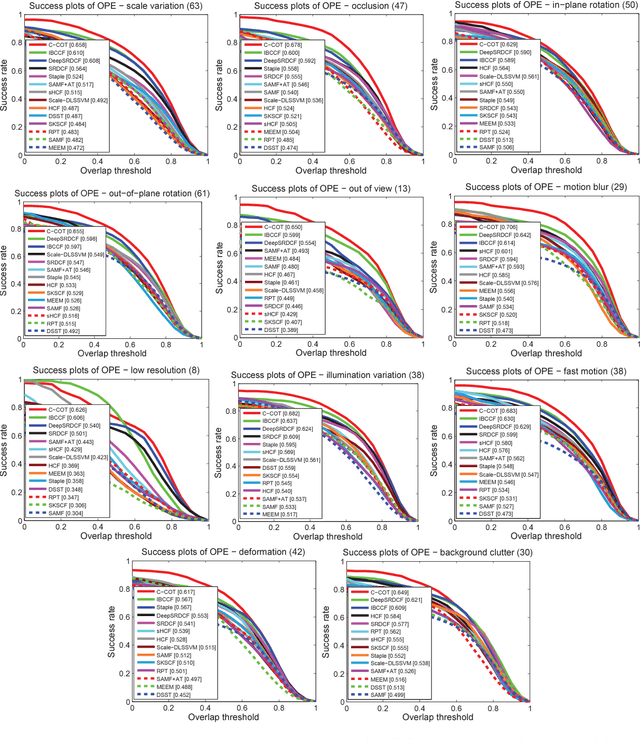
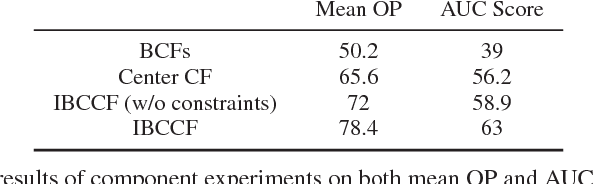
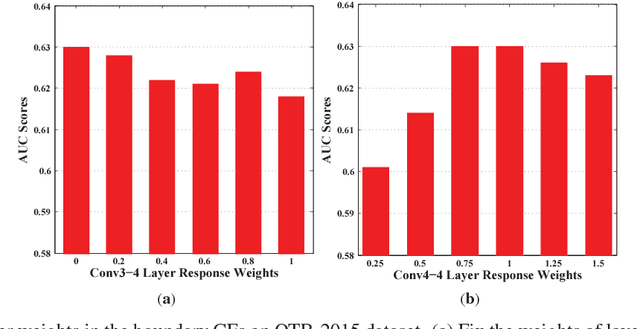
The aspect ratio variation frequently appears in visual tracking and has a severe influence on performance. Although many correlation filter (CF)-based trackers have also been suggested for scale adaptive tracking, few studies have been given to handle the aspect ratio variation for CF trackers. In this paper, we make the first attempt to address this issue by introducing a family of 1D boundary CFs to localize the left, right, top, and bottom boundaries in videos. This allows us cope with the aspect ratio variation flexibly during tracking. Specifically, we present a novel tracking model to integrate 1D Boundary and 2D Center CFs (IBCCF) where boundary and center filters are enforced by a near-orthogonality regularization term. To optimize our IBCCF model, we develop an alternating direction method of multipliers. Experiments on several datasets show that IBCCF can effectively handle aspect ratio variation, and achieves state-of-the-art performance in terms of accuracy and robustness.
Learning Convolutional Networks for Content-weighted Image Compression
Sep 19, 2017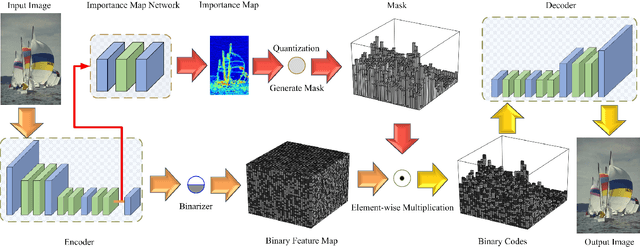
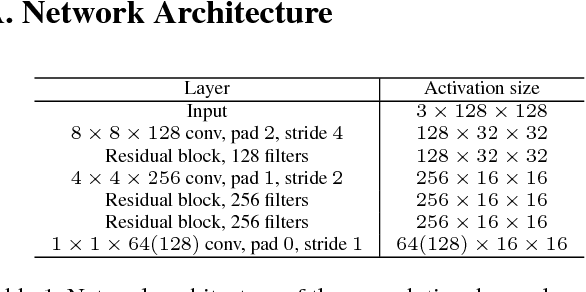

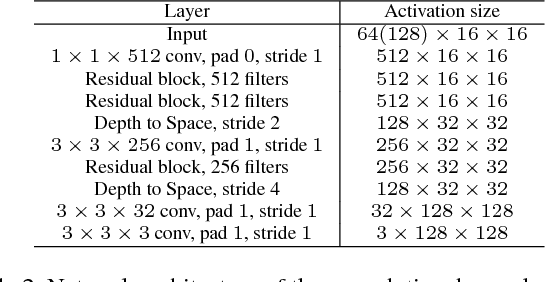
Lossy image compression is generally formulated as a joint rate-distortion optimization to learn encoder, quantizer, and decoder. However, the quantizer is non-differentiable, and discrete entropy estimation usually is required for rate control. These make it very challenging to develop a convolutional network (CNN)-based image compression system. In this paper, motivated by that the local information content is spatially variant in an image, we suggest that the bit rate of the different parts of the image should be adapted to local content. And the content aware bit rate is allocated under the guidance of a content-weighted importance map. Thus, the sum of the importance map can serve as a continuous alternative of discrete entropy estimation to control compression rate. And binarizer is adopted to quantize the output of encoder due to the binarization scheme is also directly defined by the importance map. Furthermore, a proxy function is introduced for binary operation in backward propagation to make it differentiable. Therefore, the encoder, decoder, binarizer and importance map can be jointly optimized in an end-to-end manner by using a subset of the ImageNet database. In low bit rate image compression, experiments show that our system significantly outperforms JPEG and JPEG 2000 by structural similarity (SSIM) index, and can produce the much better visual result with sharp edges, rich textures, and fewer artifacts.
Learning Domain-Invariant Subspace using Domain Features and Independence Maximization
Jun 22, 2017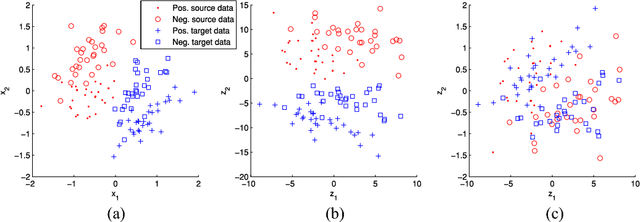
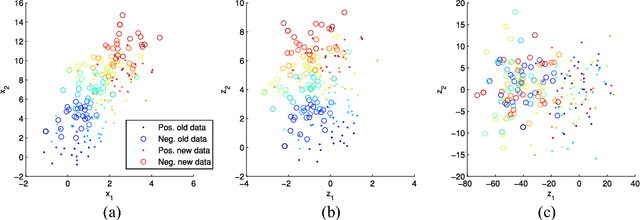
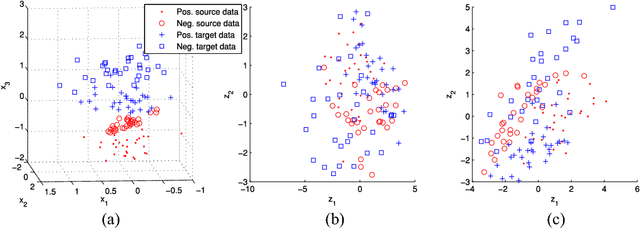
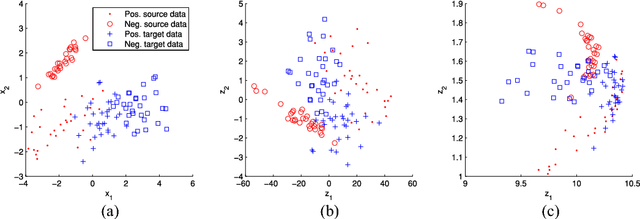
Domain adaptation algorithms are useful when the distributions of the training and the test data are different. In this paper, we focus on the problem of instrumental variation and time-varying drift in the field of sensors and measurement, which can be viewed as discrete and continuous distributional change in the feature space. We propose maximum independence domain adaptation (MIDA) and semi-supervised MIDA (SMIDA) to address this problem. Domain features are first defined to describe the background information of a sample, such as the device label and acquisition time. Then, MIDA learns a subspace which has maximum independence with the domain features, so as to reduce the inter-domain discrepancy in distributions. A feature augmentation strategy is also designed to project samples according to their backgrounds so as to improve the adaptation. The proposed algorithms are flexible and fast. Their effectiveness is verified by experiments on synthetic datasets and four real-world ones on sensors, measurement, and computer vision. They can greatly enhance the practicability of sensor systems, as well as extend the application scope of existing domain adaptation algorithms by uniformly handling different kinds of distributional change.