 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn scalable oversight with weak LLMs judging strong LLMs
Jul 05, 2024



Scalable oversight protocols aim to enable humans to accurately supervise superhuman AI. In this paper we study debate, where two AI's compete to convince a judge; consultancy, where a single AI tries to convince a judge that asks questions; and compare to a baseline of direct question-answering, where the judge just answers outright without the AI. We use large language models (LLMs) as both AI agents and as stand-ins for human judges, taking the judge models to be weaker than agent models. We benchmark on a diverse range of asymmetries between judges and agents, extending previous work on a single extractive QA task with information asymmetry, to also include mathematics, coding, logic and multimodal reasoning asymmetries. We find that debate outperforms consultancy across all tasks when the consultant is randomly assigned to argue for the correct/incorrect answer. Comparing debate to direct question answering, the results depend on the type of task: in extractive QA tasks with information asymmetry debate outperforms direct question answering, but in other tasks without information asymmetry the results are mixed. Previous work assigned debaters/consultants an answer to argue for. When we allow them to instead choose which answer to argue for, we find judges are less frequently convinced by the wrong answer in debate than in consultancy. Further, we find that stronger debater models increase judge accuracy, though more modestly than in previous studies.
Evaluating Frontier Models for Dangerous Capabilities
Mar 20, 2024



To understand the risks posed by a new AI system, we must understand what it can and cannot do. Building on prior work, we introduce a programme of new "dangerous capability" evaluations and pilot them on Gemini 1.0 models. Our evaluations cover four areas: (1) persuasion and deception; (2) cyber-security; (3) self-proliferation; and (4) self-reasoning. We do not find evidence of strong dangerous capabilities in the models we evaluated, but we flag early warning signs. Our goal is to help advance a rigorous science of dangerous capability evaluation, in preparation for future models.
Vision-Language Models are Zero-Shot Reward Models for Reinforcement Learning
Oct 19, 2023



Reinforcement learning (RL) requires either manually specifying a reward function, which is often infeasible, or learning a reward model from a large amount of human feedback, which is often very expensive. We study a more sample-efficient alternative: using pretrained vision-language models (VLMs) as zero-shot reward models (RMs) to specify tasks via natural language. We propose a natural and general approach to using VLMs as reward models, which we call VLM-RMs. We use VLM-RMs based on CLIP to train a MuJoCo humanoid to learn complex tasks without a manually specified reward function, such as kneeling, doing the splits, and sitting in a lotus position. For each of these tasks, we only provide a single sentence text prompt describing the desired task with minimal prompt engineering. We provide videos of the trained agents at: https://sites.google.com/view/vlm-rm. We can improve performance by providing a second ``baseline'' prompt and projecting out parts of the CLIP embedding space irrelevant to distinguish between goal and baseline. Further, we find a strong scaling effect for VLM-RMs: larger VLMs trained with more compute and data are better reward models. The failure modes of VLM-RMs we encountered are all related to known capability limitations of current VLMs, such as limited spatial reasoning ability or visually unrealistic environments that are far off-distribution for the VLM. We find that VLM-RMs are remarkably robust as long as the VLM is large enough. This suggests that future VLMs will become more and more useful reward models for a wide range of RL applications.
RLHF-Blender: A Configurable Interactive Interface for Learning from Diverse Human Feedback
Aug 08, 2023

To use reinforcement learning from human feedback (RLHF) in practical applications, it is crucial to learn reward models from diverse sources of human feedback and to consider human factors involved in providing feedback of different types. However, the systematic study of learning from diverse types of feedback is held back by limited standardized tooling available to researchers. To bridge this gap, we propose RLHF-Blender, a configurable, interactive interface for learning from human feedback. RLHF-Blender provides a modular experimentation framework and implementation that enables researchers to systematically investigate the properties and qualities of human feedback for reward learning. The system facilitates the exploration of various feedback types, including demonstrations, rankings, comparisons, and natural language instructions, as well as studies considering the impact of human factors on their effectiveness. We discuss a set of concrete research opportunities enabled by RLHF-Blender. More information is available at https://rlhfblender.info/.
* 14 pages, 3 figures
Open Problems and Fundamental Limitations of Reinforcement Learning from Human Feedback
Jul 27, 2023



Reinforcement learning from human feedback (RLHF) is a technique for training AI systems to align with human goals. RLHF has emerged as the central method used to finetune state-of-the-art large language models (LLMs). Despite this popularity, there has been relatively little public work systematizing its flaws. In this paper, we (1) survey open problems and fundamental limitations of RLHF and related methods; (2) overview techniques to understand, improve, and complement RLHF in practice; and (3) propose auditing and disclosure standards to improve societal oversight of RLHF systems. Our work emphasizes the limitations of RLHF and highlights the importance of a multi-faceted approach to the development of safer AI systems.
Learning Safety Constraints from Demonstrations with Unknown Rewards
May 25, 2023We propose Convex Constraint Learning for Reinforcement Learning (CoCoRL), a novel approach for inferring shared constraints in a Constrained Markov Decision Process (CMDP) from a set of safe demonstrations with possibly different reward functions. While previous work is limited to demonstrations with known rewards or fully known environment dynamics, CoCoRL can learn constraints from demonstrations with different unknown rewards without knowledge of the environment dynamics. CoCoRL constructs a convex safe set based on demonstrations, which provably guarantees safety even for potentially sub-optimal (but safe) demonstrations. For near-optimal demonstrations, CoCoRL converges to the true safe set with no policy regret. We evaluate CoCoRL in tabular environments and a continuous driving simulation with multiple constraints. CoCoRL learns constraints that lead to safe driving behavior and that can be transferred to different tasks and environments. In contrast, alternative methods based on Inverse Reinforcement Learning (IRL) often exhibit poor performance and learn unsafe policies.
Tracr: Compiled Transformers as a Laboratory for Interpretability
Jan 12, 2023Interpretability research aims to build tools for understanding machine learning (ML) models. However, such tools are inherently hard to evaluate because we do not have ground truth information about how ML models actually work. In this work, we propose to build transformer models manually as a testbed for interpretability research. We introduce Tracr, a "compiler" for translating human-readable programs into weights of a transformer model. Tracr takes code written in RASP, a domain-specific language (Weiss et al. 2021), and translates it into weights for a standard, decoder-only, GPT-like transformer architecture. We use Tracr to create a range of ground truth transformers that implement programs including computing token frequencies, sorting, and Dyck-n parenthesis checking, among others. To enable the broader research community to explore and use compiled models, we provide an open-source implementation of Tracr at https://github.com/deepmind/tracr.
Red-Teaming the Stable Diffusion Safety Filter
Oct 11, 2022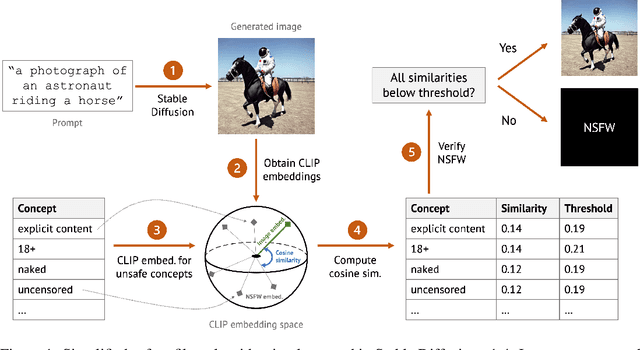
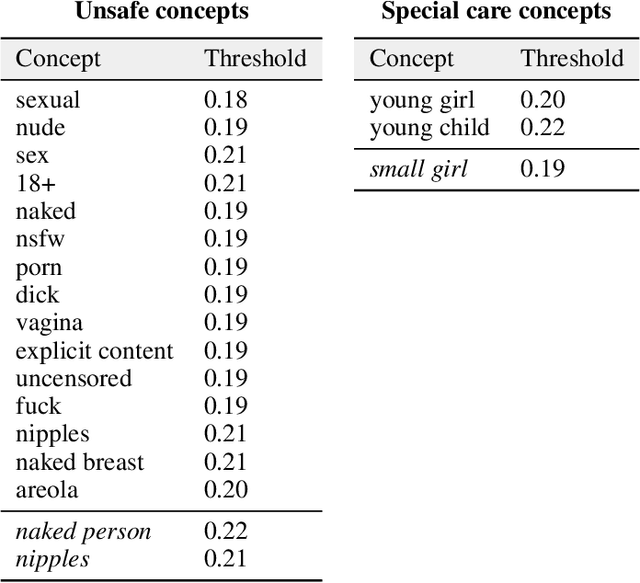


Stable Diffusion is a recent open-source image generation model comparable to proprietary models such as DALLE, Imagen, or Parti. Stable Diffusion comes with a safety filter that aims to prevent generating explicit images. Unfortunately, the filter is obfuscated and poorly documented. This makes it hard for users to prevent misuse in their applications, and to understand the filter's limitations and improve it. We first show that it is easy to generate disturbing content that bypasses the safety filter. We then reverse-engineer the filter and find that while it aims to prevent sexual content, it ignores violence, gore, and other similarly disturbing content. Based on our analysis, we argue safety measures in future model releases should strive to be fully open and properly documented to stimulate security contributions from the community.
Active Exploration for Inverse Reinforcement Learning
Jul 18, 2022



Inverse Reinforcement Learning (IRL) is a powerful paradigm for inferring a reward function from expert demonstrations. Many IRL algorithms require a known transition model and sometimes even a known expert policy, or they at least require access to a generative model. However, these assumptions are too strong for many real-world applications, where the environment can be accessed only through sequential interaction. We propose a novel IRL algorithm: Active exploration for Inverse Reinforcement Learning (AceIRL), which actively explores an unknown environment and expert policy to quickly learn the expert's reward function and identify a good policy. AceIRL uses previous observations to construct confidence intervals that capture plausible reward functions and find exploration policies that focus on the most informative regions of the environment. AceIRL is the first approach to active IRL with sample-complexity bounds that does not require a generative model of the environment. AceIRL matches the sample complexity of active IRL with a generative model in the worst case. Additionally, we establish a problem-dependent bound that relates the sample complexity of AceIRL to the suboptimality gap of a given IRL problem. We empirically evaluate AceIRL in simulations and find that it significantly outperforms more naive exploration strategies.
Humans are not Boltzmann Distributions: Challenges and Opportunities for Modelling Human Feedback and Interaction in Reinforcement Learning
Jun 27, 2022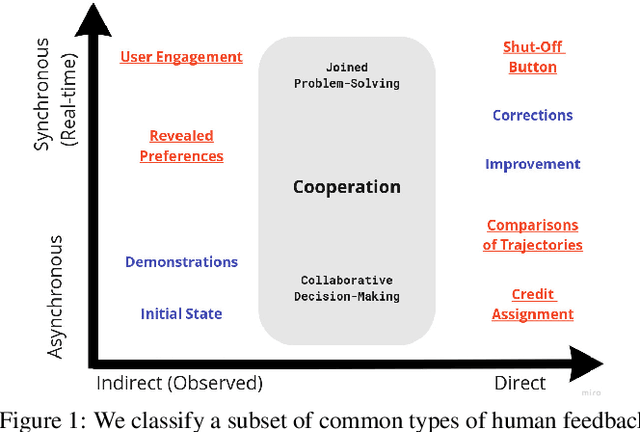
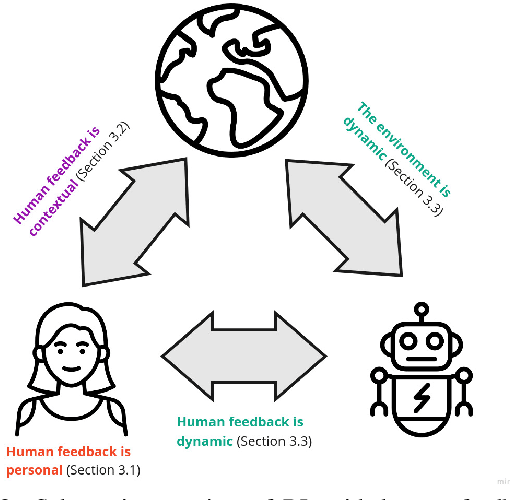
Reinforcement learning (RL) commonly assumes access to well-specified reward functions, which many practical applications do not provide. Instead, recently, more work has explored learning what to do from interacting with humans. So far, most of these approaches model humans as being (nosily) rational and, in particular, giving unbiased feedback. We argue that these models are too simplistic and that RL researchers need to develop more realistic human models to design and evaluate their algorithms. In particular, we argue that human models have to be personal, contextual, and dynamic. This paper calls for research from different disciplines to address key questions about how humans provide feedback to AIs and how we can build more robust human-in-the-loop RL systems.