 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhere Do Models Find Happiness? Emotion Vectors in Open-Source LLMs
Jun 25, 2026Recent work identified emotion vectors in Claude Sonnet 4.5, which are internal representations that encode emotion concepts, causally influence behavior, and exhibit geometry mirroring human psychological structure. We test the generality of these findings in two open-weight models, Apertus-8B-Instruct-2509 and Gemma-4-E4B-it, extracting emotion contrast vectors across all layers, using two model-generated corpora. We recover valence geometry for both models, with peak PC1--valence correlations of $r = 0.76$ and $r = 0.83$, approaching the $r = 0.81$ reported for Claude.Beyond replication, we observe notable differences in how valence representations emerge across model depth. In Gemma-4-E4B-it, valence is strongly encoded in early layers but collapses towards later layers, whereas Apertus-8B-Instruct-2509 exhibits the opposite pattern, with valence representations absent in early layers, but emerging at mid depths. Arousal encoding, in contrast, is sensitive to the extraction corpus: both models show stronger PC2--arousal alignment with Gemma-generated stories ($r$ up to $0.45$) than Apertus-generated ones ($r \leq 0.21$), suggesting arousal-relevant cues are unevenly distributed across generated corpora. We open-source our experiment code and dataset for reproducible investigation of emotion representations across language model architectures.
TopoAlign: Topology-Aware Visual Representation Alignment
May 25, 2026Neural networks encode inputs as high-dimensional vectors, known as representations, that capture how models process data by encoding task-relevant structure and semantics. Representation alignment refers to the degree to which different models, layers, or training conditions produce similar representations for the same inputs, with important implications for model interpretation, selection, and robustness analysis. Existing approaches to measure alignment primarily rely on geometric properties, such as neighborhood and cluster similarity, offering limited insight into the global organization of representations. In this work, we present TopoAlign, a topology-aware framework for visually comparing model representations from a structural perspective. Leveraging mapper graphs from topological data analysis, TopoAlign jointly analyzes graphs constructed from representations of shared inputs across different models or layers. The framework supports a top-down comparative workflow: it first performs global structure alignment via joint force-directed optimization to produce coordinated graph layouts; it then identifies local correspondences through automated detection of structurally matching regions, visualized with Bubble Sets; and finally it enables fine-grained pattern inspection through motif-based queries and membrane-inspired visualizations. We demonstrate TopoAlign through case studies on language and multimodal models, complemented by expert feedback. Our results show that TopoAlign provides meaningful insights into representation structure and alignment from a topological perspective.
Cross-Cultural Simulation of Citizen Emotional Responses to Bureaucratic Red Tape Using LLM Agents
Apr 14, 2026Improving policymaking is a central concern in public administration. Prior human subject studies reveal substantial cross-cultural differences in citizens' emotional responses to red tape during policy implementation. While LLM agents offer opportunities to simulate human-like responses and reduce experimental costs, their ability to generate culturally appropriate emotional responses to red tape remains unverified. To address this gap, we propose an evaluation framework for assessing LLMs' emotional responses to red tape across diverse cultural contexts. As a pilot study, we apply this framework to a single red-tape scenario. Our results show that all models exhibit limited alignment with human emotional responses, with notably weaker performance in Eastern cultures. Cultural prompting strategies prove largely ineffective in improving alignment. We further introduce \textbf{RAMO}, an interactive interface for simulating citizens' emotional responses to red tape and for collecting human data to improve models. The interface is publicly available at https://ramo-chi.ivia.ch.
Process Supervision for Chain-of-Thought Reasoning via Monte Carlo Net Information Gain
Mar 18, 2026Multi-step reasoning improves the capabilities of large language models (LLMs) but increases the risk of errors propagating through intermediate steps. Process reward models (PRMs) mitigate this by scoring each step individually, enabling fine-grained supervision and improved reliability. Existing methods for training PRMs rely on costly human annotations or computationally intensive automatic labeling. We propose a novel approach to automatically generate step-level labels using Information Theory. Our method estimates how each reasoning step affects the likelihood of the correct answer, providing a signal of step quality. Importantly, it reduces computational complexity to $\mathcal{O}(N)$, improving over the previous $\mathcal{O}(N \log N)$ methods. We demonstrate that these labels enable effective chain-of-thought selection in best-of-$K$ evaluation settings across diverse reasoning benchmarks, including mathematics, Python programming, SQL, and scientific question answering. This work enables scalable and efficient supervision of LLM reasoning, particularly for tasks where error propagation is critical.
PleaSQLarify: Visual Pragmatic Repair for Natural Language Database Querying
Mar 02, 2026Natural language database interfaces broaden data access, yet they remain brittle under input ambiguity. Standard approaches often collapse uncertainty into a single query, offering little support for mismatches between user intent and system interpretation. We reframe this challenge through pragmatic inference: while users economize expressions, systems operate on priors over the action space that may not align with the users'. In this view, pragmatic repair -- incremental clarification through minimal interaction -- is a natural strategy for resolving underspecification. We present \textsc{PleaSQLarify}, which operationalizes pragmatic repair by structuring interaction around interpretable decision variables that enable efficient clarification. A visual interface complements this by surfacing the action space for exploration, requesting user disambiguation, and making belief updates traceable across turns. In a study with twelve participants, \textsc{PleaSQLarify} helped users recognize alternative interpretations and efficiently resolve ambiguity. Our findings highlight pragmatic repair as a design principle that fosters effective user control in natural language interfaces.
MAVRL: Learning Reward Functions from Multiple Feedback Types with Amortized Variational Inference
Feb 16, 2026Reward learning typically relies on a single feedback type or combines multiple feedback types using manually weighted loss terms. Currently, it remains unclear how to jointly learn reward functions from heterogeneous feedback types such as demonstrations, comparisons, ratings, and stops that provide qualitatively different signals. We address this challenge by formulating reward learning from multiple feedback types as Bayesian inference over a shared latent reward function, where each feedback type contributes information through an explicit likelihood. We introduce a scalable amortized variational inference approach that learns a shared reward encoder and feedback-specific likelihood decoders and is trained by optimizing a single evidence lower bound. Our approach avoids reducing feedback to a common intermediate representation and eliminates the need for manual loss balancing. Across discrete and continuous-control benchmarks, we show that jointly inferred reward posteriors outperform single-type baselines, exploit complementary information across feedback types, and yield policies that are more robust to environment perturbations. The inferred reward uncertainty further provides interpretable signals for analyzing model confidence and consistency across feedback types.
Explainable Mapper: Charting LLM Embedding Spaces Using Perturbation-Based Explanation and Verification Agents
Jul 24, 2025
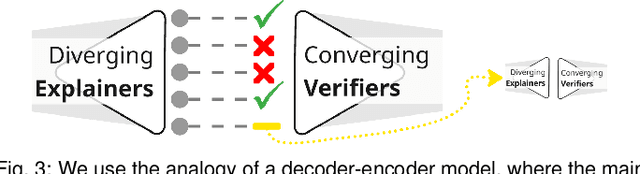
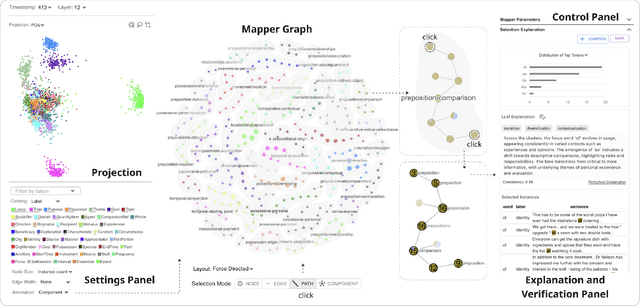
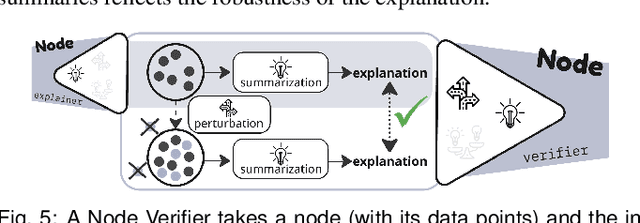
Large language models (LLMs) produce high-dimensional embeddings that capture rich semantic and syntactic relationships between words, sentences, and concepts. Investigating the topological structures of LLM embedding spaces via mapper graphs enables us to understand their underlying structures. Specifically, a mapper graph summarizes the topological structure of the embedding space, where each node represents a topological neighborhood (containing a cluster of embeddings), and an edge connects two nodes if their corresponding neighborhoods overlap. However, manually exploring these embedding spaces to uncover encoded linguistic properties requires considerable human effort. To address this challenge, we introduce a framework for semi-automatic annotation of these embedding properties. To organize the exploration process, we first define a taxonomy of explorable elements within a mapper graph such as nodes, edges, paths, components, and trajectories. The annotation of these elements is executed through two types of customizable LLM-based agents that employ perturbation techniques for scalable and automated analysis. These agents help to explore and explain the characteristics of mapper elements and verify the robustness of the generated explanations. We instantiate the framework within a visual analytics workspace and demonstrate its effectiveness through case studies. In particular, we replicate findings from prior research on BERT's embedding properties across various layers of its architecture and provide further observations into the linguistic properties of topological neighborhoods.
Concept-Level Explainability for Auditing & Steering LLM Responses
May 12, 2025As large language models (LLMs) become widely deployed, concerns about their safety and alignment grow. An approach to steer LLM behavior, such as mitigating biases or defending against jailbreaks, is to identify which parts of a prompt influence specific aspects of the model's output. Token-level attribution methods offer a promising solution, but still struggle in text generation, explaining the presence of each token in the output separately, rather than the underlying semantics of the entire LLM response. We introduce ConceptX, a model-agnostic, concept-level explainability method that identifies the concepts, i.e., semantically rich tokens in the prompt, and assigns them importance based on the outputs' semantic similarity. Unlike current token-level methods, ConceptX also offers to preserve context integrity through in-place token replacements and supports flexible explanation goals, e.g., gender bias. ConceptX enables both auditing, by uncovering sources of bias, and steering, by modifying prompts to shift the sentiment or reduce the harmfulness of LLM responses, without requiring retraining. Across three LLMs, ConceptX outperforms token-level methods like TokenSHAP in both faithfulness and human alignment. Steering tasks boost sentiment shift by 0.252 versus 0.131 for random edits and lower attack success rates from 0.463 to 0.242, outperforming attribution and paraphrasing baselines. While prompt engineering and self-explaining methods sometimes yield safer responses, ConceptX offers a transparent and faithful alternative for improving LLM safety and alignment, demonstrating the practical value of attribution-based explainability in guiding LLM behavior.
LayerFlow: Layer-wise Exploration of LLM Embeddings using Uncertainty-aware Interlinked Projections
Apr 09, 2025



Large language models (LLMs) represent words through contextual word embeddings encoding different language properties like semantics and syntax. Understanding these properties is crucial, especially for researchers investigating language model capabilities, employing embeddings for tasks related to text similarity, or evaluating the reasons behind token importance as measured through attribution methods. Applications for embedding exploration frequently involve dimensionality reduction techniques, which reduce high-dimensional vectors to two dimensions used as coordinates in a scatterplot. This data transformation step introduces uncertainty that can be propagated to the visual representation and influence users' interpretation of the data. To communicate such uncertainties, we present LayerFlow - a visual analytics workspace that displays embeddings in an interlinked projection design and communicates the transformation, representation, and interpretation uncertainty. In particular, to hint at potential data distortions and uncertainties, the workspace includes several visual components, such as convex hulls showing 2D and HD clusters, data point pairwise distances, cluster summaries, and projection quality metrics. We show the usability of the presented workspace through replication and expert case studies that highlight the need to communicate uncertainty through multiple visual components and different data perspectives.
Reward Learning from Multiple Feedback Types
Feb 28, 2025Learning rewards from preference feedback has become an important tool in the alignment of agentic models. Preference-based feedback, often implemented as a binary comparison between multiple completions, is an established method to acquire large-scale human feedback. However, human feedback in other contexts is often much more diverse. Such diverse feedback can better support the goals of a human annotator, and the simultaneous use of multiple sources might be mutually informative for the learning process or carry type-dependent biases for the reward learning process. Despite these potential benefits, learning from different feedback types has yet to be explored extensively. In this paper, we bridge this gap by enabling experimentation and evaluating multi-type feedback in a broad set of environments. We present a process to generate high-quality simulated feedback of six different types. Then, we implement reward models and downstream RL training for all six feedback types. Based on the simulated feedback, we investigate the use of types of feedback across ten RL environments and compare them to pure preference-based baselines. We show empirically that diverse types of feedback can be utilized and lead to strong reward modeling performance. This work is the first strong indicator of the potential of multi-type feedback for RLHF.