 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReceding Horizon Inverse Reinforcement Learning
Jun 09, 2022
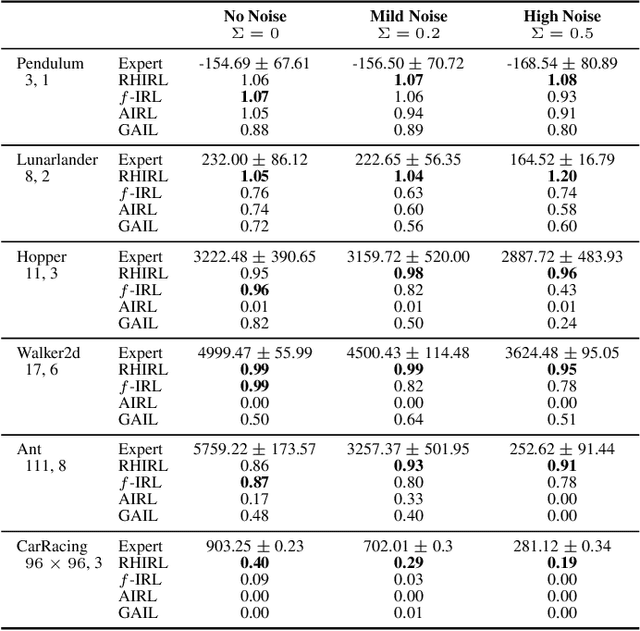
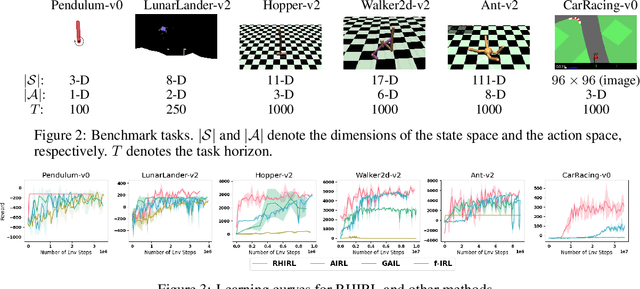
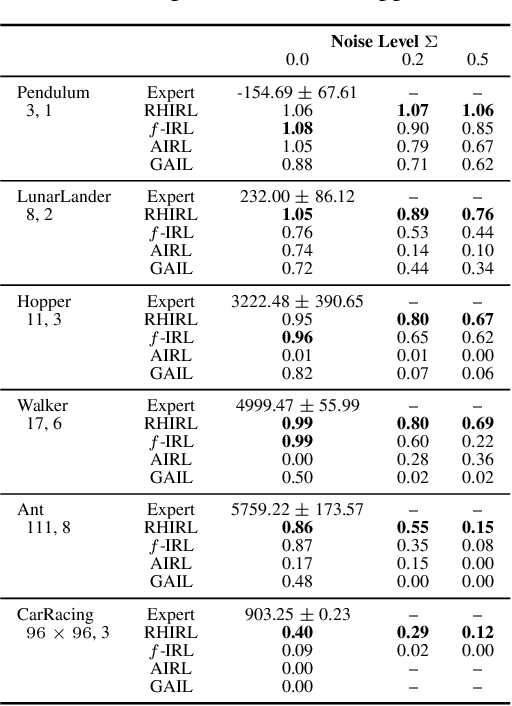
Inverse reinforcement learning (IRL) seeks to infer a cost function that explains the underlying goals and preferences of expert demonstrations. This paper presents receding horizon inverse reinforcement learning (RHIRL), a new IRL algorithm for high-dimensional, noisy, continuous systems with black-box dynamic models. RHIRL addresses two key challenges of IRL: scalability and robustness. To handle high-dimensional continuous systems, RHIRL matches the induced optimal trajectories with expert demonstrations locally in a receding horizon manner and 'stitches' together the local solutions to learn the cost; it thereby avoids the 'curse of dimensionality'. This contrasts sharply with earlier algorithms that match with expert demonstrations globally over the entire high-dimensional state space. To be robust against imperfect expert demonstrations and system control noise, RHIRL learns a state-dependent cost function 'disentangled' from system dynamics under mild conditions. Experiments on benchmark tasks show that RHIRL outperforms several leading IRL algorithms in most instances. We also prove that the cumulative error of RHIRL grows linearly with the task duration.
Context-Hierarchy Inverse Reinforcement Learning
Feb 25, 2022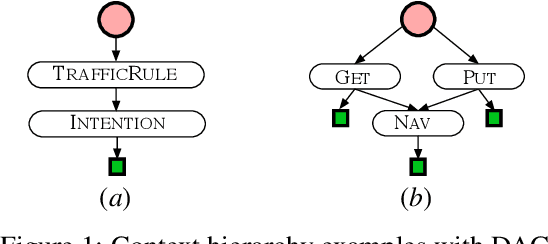
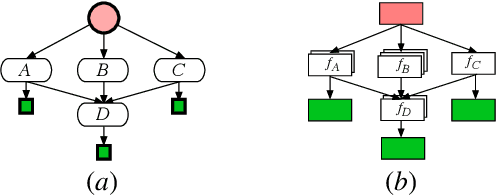
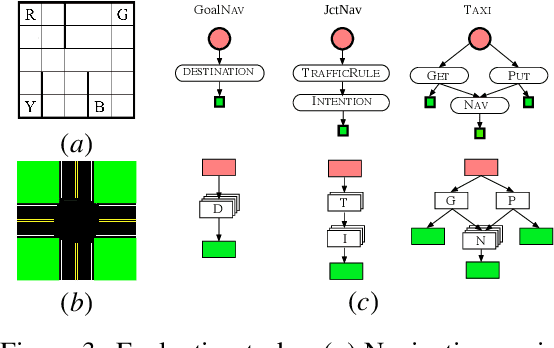
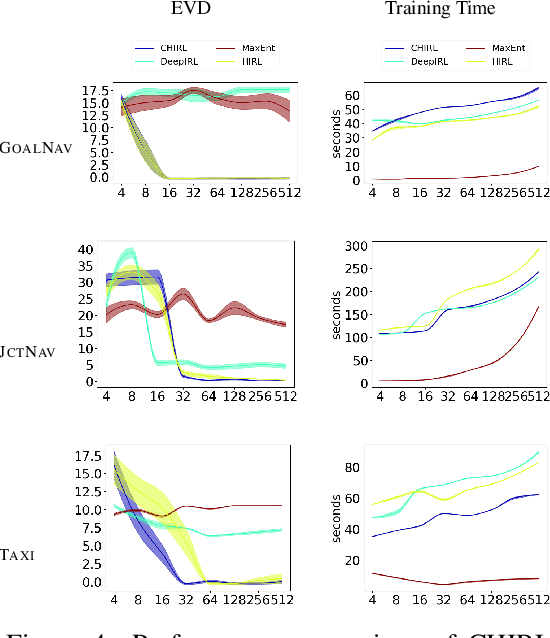
An inverse reinforcement learning (IRL) agent learns to act intelligently by observing expert demonstrations and learning the expert's underlying reward function. Although learning the reward functions from demonstrations has achieved great success in various tasks, several other challenges are mostly ignored. Firstly, existing IRL methods try to learn the reward function from scratch without relying on any prior knowledge. Secondly, traditional IRL methods assume the reward functions are homogeneous across all the demonstrations. Some existing IRL methods managed to extend to the heterogeneous demonstrations. However, they still assume one hidden variable that affects the behavior and learn the underlying hidden variable together with the reward from demonstrations. To solve these issues, we present Context Hierarchy IRL(CHIRL), a new IRL algorithm that exploits the context to scale up IRL and learn reward functions of complex behaviors. CHIRL models the context hierarchically as a directed acyclic graph; it represents the reward function as a corresponding modular deep neural network that associates each network module with a node of the context hierarchy. The context hierarchy and the modular reward representation enable data sharing across multiple contexts and state abstraction, significantly improving the learning performance. CHIRL has a natural connection with hierarchical task planning when the context hierarchy represents subtask decomposition. It enables to incorporate the prior knowledge of causal dependencies of subtasks and make it capable of solving large complex tasks by decoupling it into several subtasks and conquering each subtask to solve the original task. Experiments on benchmark tasks, including a large scale autonomous driving task in the CARLA simulator, show promising results in scaling up IRL for tasks with complex reward functions.
End-to-End Partially Observable Visual Navigation in a Diverse Environment
Sep 16, 2021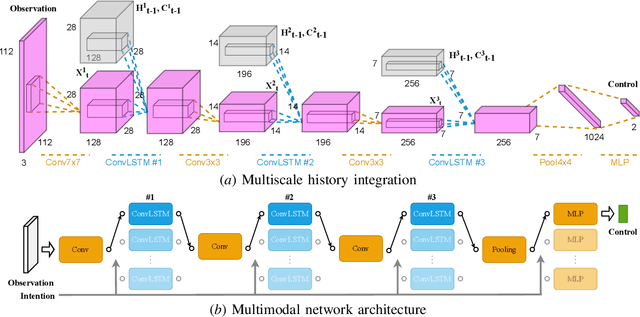


How can a robot navigate successfully in a rich and diverse environment, indoors or outdoors, along an office corridor or a trail in the park, on the flat ground, the staircase, or the elevator, etc.? To this end, this work aims at three challenges: (i) complex visual observations, (ii) partial observability of local sensing, and (iii) multimodal navigation behaviors that depend on both the local environment and the high-level goal. We propose a novel neural network (NN) architecture to represent a local controller and leverage the flexibility of the end-to-end approach to learn a powerful policy. To tackle complex visual observations, we extract multiscale spatial information through convolution layers. To deal with partial observability, we encode rich history information in LSTM-like modules. Importantly, we integrate the two into a single unified architecture that exploits convolutional memory cells to track the observation history at multiple spatial scales, which can capture the complex spatiotemporal dependencies between observations and controls. We additionally condition the network on the high-level goal in order to generate different navigation behavior modes. Specifically, we propose to use independent memory cells for different modes to prevent mode collapse in the learned policy. We implemented the NN controller on the SPOT robot and evaluate it on three challenging tasks with partial observations: adversarial pedestrian avoidance, blind-spot obstacle avoidance, and elevator riding. Our model significantly outperforms CNNs, conventional LSTMs, or the ablated versions of our model. A demo video will be publicly available, showing our SPOT robot traversing many different locations on our university campus.
INVIGORATE: Interactive Visual Grounding and Grasping in Clutter
Aug 25, 2021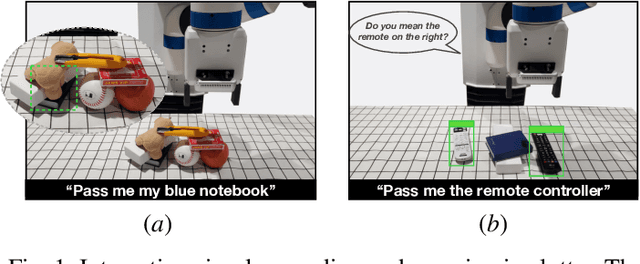
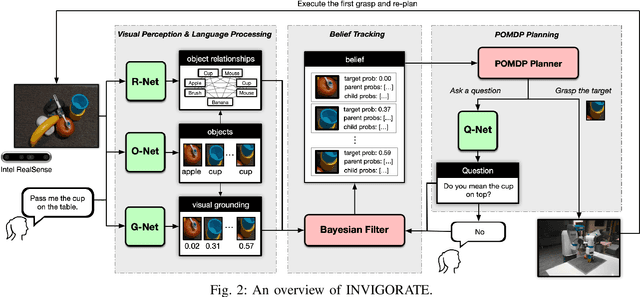
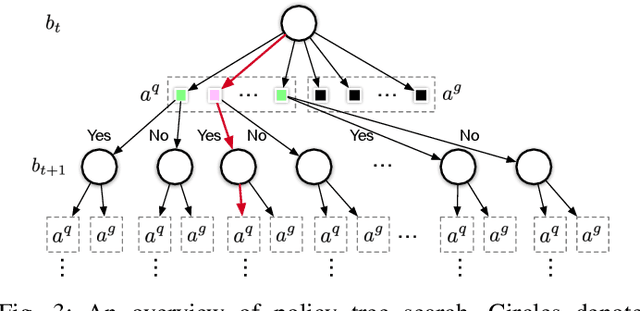

This paper presents INVIGORATE, a robot system that interacts with human through natural language and grasps a specified object in clutter. The objects may occlude, obstruct, or even stack on top of one another. INVIGORATE embodies several challenges: (i) infer the target object among other occluding objects, from input language expressions and RGB images, (ii) infer object blocking relationships (OBRs) from the images, and (iii) synthesize a multi-step plan to ask questions that disambiguate the target object and to grasp it successfully. We train separate neural networks for object detection, for visual grounding, for question generation, and for OBR detection and grasping. They allow for unrestricted object categories and language expressions, subject to the training datasets. However, errors in visual perception and ambiguity in human languages are inevitable and negatively impact the robot's performance. To overcome these uncertainties, we build a partially observable Markov decision process (POMDP) that integrates the learned neural network modules. Through approximate POMDP planning, the robot tracks the history of observations and asks disambiguation questions in order to achieve a near-optimal sequence of actions that identify and grasp the target object. INVIGORATE combines the benefits of model-based POMDP planning and data-driven deep learning. Preliminary experiments with INVIGORATE on a Fetch robot show significant benefits of this integrated approach to object grasping in clutter with natural language interactions. A demonstration video is available at https://youtu.be/zYakh80SGcU.
Ab Initio Particle-based Object Manipulation
Jul 19, 2021
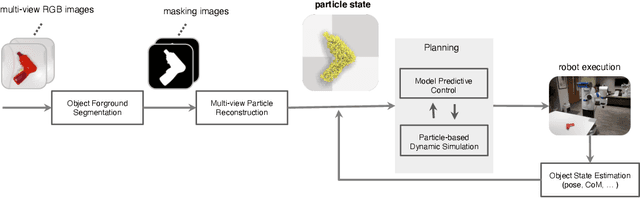

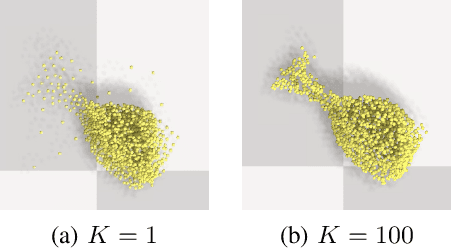
This paper presents Particle-based Object Manipulation (Prompt), a new approach to robot manipulation of novel objects ab initio, without prior object models or pre-training on a large object data set. The key element of Prompt is a particle-based object representation, in which each particle represents a point in the object, the local geometric, physical, and other features of the point, and also its relation with other particles. Like the model-based analytic approaches to manipulation, the particle representation enables the robot to reason about the object's geometry and dynamics in order to choose suitable manipulation actions. Like the data-driven approaches, the particle representation is learned online in real-time from visual sensor input, specifically, multi-view RGB images. The particle representation thus connects visual perception with robot control. Prompt combines the benefits of both model-based reasoning and data-driven learning. We show empirically that Prompt successfully handles a variety of everyday objects, some of which are transparent. It handles various manipulation tasks, including grasping, pushing, etc,. Our experiments also show that Prompt outperforms a state-of-the-art data-driven grasping method on the daily objects, even though it does not use any offline training data.
Differentiable SLAM-net: Learning Particle SLAM for Visual Navigation
May 19, 2021
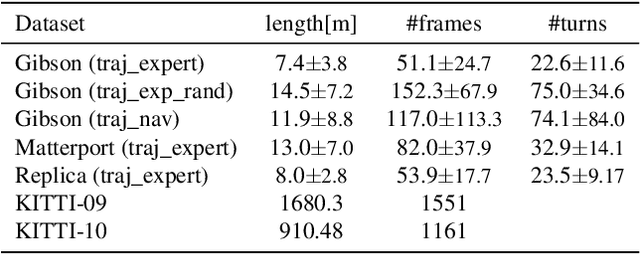
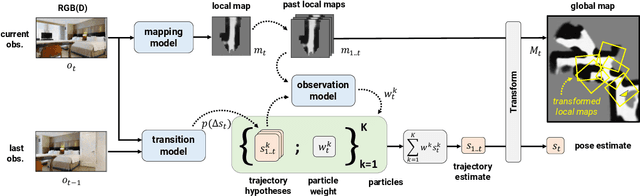
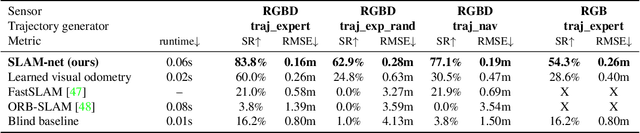
Simultaneous localization and mapping (SLAM) remains challenging for a number of downstream applications, such as visual robot navigation, because of rapid turns, featureless walls, and poor camera quality. We introduce the Differentiable SLAM Network (SLAM-net) along with a navigation architecture to enable planar robot navigation in previously unseen indoor environments. SLAM-net encodes a particle filter based SLAM algorithm in a differentiable computation graph, and learns task-oriented neural network components by backpropagating through the SLAM algorithm. Because it can optimize all model components jointly for the end-objective, SLAM-net learns to be robust in challenging conditions. We run experiments in the Habitat platform with different real-world RGB and RGB-D datasets. SLAM-net significantly outperforms the widely adapted ORB-SLAM in noisy conditions. Our navigation architecture with SLAM-net improves the state-of-the-art for the Habitat Challenge 2020 PointNav task by a large margin (37% to 64% success). Project website: http://sites.google.com/view/slamnet
Learning Latent Graph Dynamics for Deformable Object Manipulation
Apr 25, 2021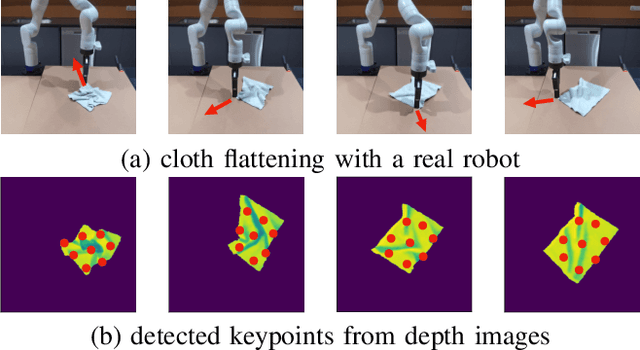



Manipulating deformable objects, such as cloth and ropes, is a long-standing challenge in robotics: their large number of degrees of freedom (DoFs) and complex non-linear dynamics make motion planning extremely difficult. This work aims to learn latent Graph dynamics for DefOrmable Object Manipulation (G-DOOM). To tackle the challenge of many DoFs and complex dynamics, G-DOOM approximates a deformable object as a sparse set of interacting keypoints and learns a graph neural network that captures abstractly the geometry and interaction dynamics of the keypoints. Further, to tackle the perceptual challenge, specifically, object self-occlusion, G-DOOM adds a recurrent neural network to track the keypoints over time and condition their interactions on the history. We then train the resulting recurrent graph dynamics model through contrastive learning in a high-fidelity simulator. For manipulation planning, G-DOOM explicitly reasons about the learned dynamics model through model-predictive control applied at each of the keypoints. We evaluate G-DOOM on a set of challenging cloth and rope manipulation tasks and show that G-DOOM outperforms a state-of-the-art method. Further, although trained entirely on simulation data, G-DOOM transfers directly to a real robot for both cloth and rope manipulation in our experiments.
Closing the Planning-Learning Loop with Application to Autonomous Driving in a Crowd
Jan 11, 2021
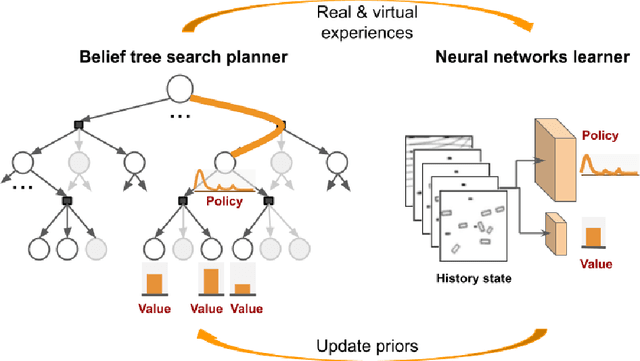
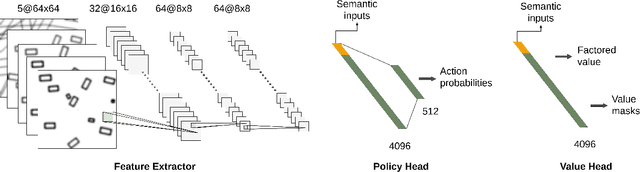

Imagine an autonomous robot vehicle driving in dense, possibly unregulated urban traffic. To contend with an uncertain, interactive environment with many traffic participants, the robot vehicle has to perform long-term planning in order to drive effectively and approach human-level performance. Planning explicitly over a long time horizon, however, incurs prohibitive computational cost and is impractical under real-time constraints. To achieve real-time performance for large-scale planning, this paper introduces Learning from Tree Search for Driving (LeTS-Drive), which integrates planning and learning in a close loop. LeTS-Drive learns a driving policy from a planner based on sparsely-sampled tree search. It then guides online planning using this learned policy for real-time vehicle control. These two steps are repeated to form a close loop so that the planner and the learner inform each other and both improve in synchrony. The entire algorithm evolves on its own in a self-supervised manner, without explicit human efforts on data labeling. We applied LeTS-Drive to autonomous driving in crowded urban environments in simulation. Experimental results clearly show that LeTS-Drive outperforms either planning or learning alone, as well as open-loop integration of planning and learning.
Simulating Autonomous Driving in Massive Mixed Urban Traffic
Nov 11, 2020
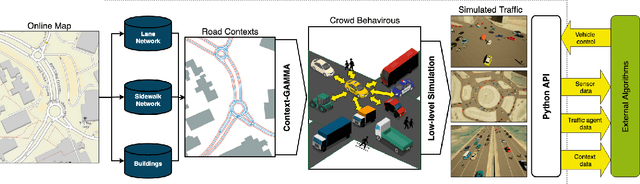
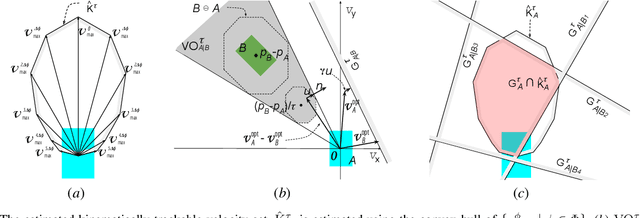
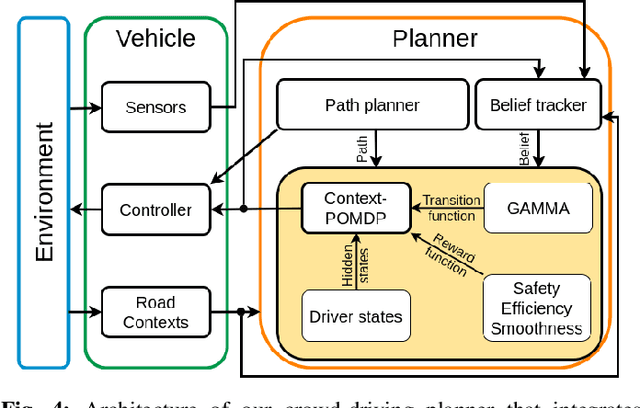
Autonomous driving in an unregulated urban crowd is an outstanding challenge, especially, in the presence of many aggressive, high-speed traffic participants. This paper presents SUMMIT, a high-fidelity simulator that facilitates the development and testing of crowd-driving algorithms. SUMMIT simulates dense, unregulated urban traffic at any worldwide locations as supported by the OpenStreetMap. The core of SUMMIT is a multi-agent motion model, GAMMA, that models the behaviours of heterogeneous traffic agents, and a real-time POMDP planner, Context-POMDP, that serves as a driving expert. SUMMIT is built as an extension of CARLA and inherits from it the physical and visual realism for autonomous driving simulation. SUMMIT supports a wide range of applications, including perception, vehicle control or planning, and end-to-end learning. We validate the realism of our motion model using its traffic motion prediction accuracy on various real-world data sets. We also provide several real-world benchmark scenarios to show that SUMMIT simulates complex, realistic traffic behaviors, and Context-POMDP drives safely and efficiently in challenging crowd-driving settings.
MAGIC: Learning Macro-Actions for Online POMDP Planning using Generator-Critic
Nov 07, 2020

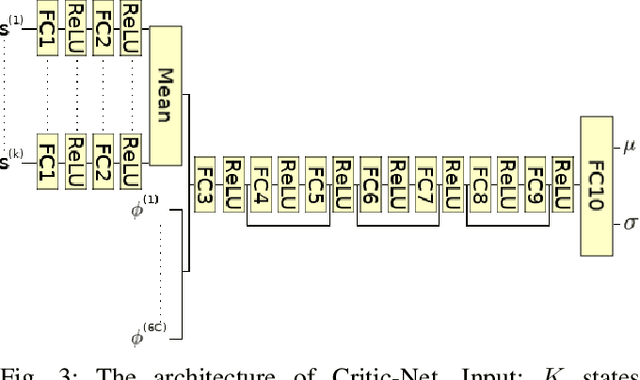

When robots operate in the real-world, they need to handle uncertainties in sensing, acting, and the environment. Many tasks also require reasoning about long-term consequences of robot decisions. The partially observable Markov decision process (POMDP) offers a principled approach for planning under uncertainty. However, its computational complexity grows exponentially with the planning horizon. We propose to use temporally-extended macro-actions to cut down the effective planning horizon and thus the exponential factor of the complexity. We propose Macro-Action Generator-Critic (MAGIC), an algorithm that learns a macro-action generator from data, and uses the learned macro-actions to perform long-horizon planning. MAGIC learns the generator using experience provided by an online planner, and in-turn conditions the planner using the generated macro-actions. We evaluate MAGIC on several long-term planning tasks, showing that it significantly outperforms planning using primitive actions, hand-crafted macro-actions, as well as naive reinforcement learning in both simulation and on a real robot.