 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePragmatic Feature Preferences: Learning Reward-Relevant Preferences from Human Input
May 23, 2024



Humans use social context to specify preferences over behaviors, i.e. their reward functions. Yet, algorithms for inferring reward models from preference data do not take this social learning view into account. Inspired by pragmatic human communication, we study how to extract fine-grained data regarding why an example is preferred that is useful for learning more accurate reward models. We propose to enrich binary preference queries to ask both (1) which features of a given example are preferable in addition to (2) comparisons between examples themselves. We derive an approach for learning from these feature-level preferences, both for cases where users specify which features are reward-relevant, and when users do not. We evaluate our approach on linear bandit settings in both vision- and language-based domains. Results support the efficiency of our approach in quickly converging to accurate rewards with fewer comparisons vs. example-only labels. Finally, we validate the real-world applicability with a behavioral experiment on a mushroom foraging task. Our findings suggest that incorporating pragmatic feature preferences is a promising approach for more efficient user-aligned reward learning.
A Definition of Continual Reinforcement Learning
Jul 20, 2023In this paper we develop a foundation for continual reinforcement learning.
On the Convergence of Bounded Agents
Jul 20, 2023When has an agent converged? Standard models of the reinforcement learning problem give rise to a straightforward definition of convergence: An agent converges when its behavior or performance in each environment state stops changing. However, as we shift the focus of our learning problem from the environment's state to the agent's state, the concept of an agent's convergence becomes significantly less clear. In this paper, we propose two complementary accounts of agent convergence in a framing of the reinforcement learning problem that centers around bounded agents. The first view says that a bounded agent has converged when the minimal number of states needed to describe the agent's future behavior cannot decrease. The second view says that a bounded agent has converged just when the agent's performance only changes if the agent's internal state changes. We establish basic properties of these two definitions, show that they accommodate typical views of convergence in standard settings, and prove several facts about their nature and relationship. We take these perspectives, definitions, and analysis to bring clarity to a central idea of the field.
Settling the Reward Hypothesis
Dec 20, 2022

The reward hypothesis posits that, "all of what we mean by goals and purposes can be well thought of as maximization of the expected value of the cumulative sum of a received scalar signal (reward)." We aim to fully settle this hypothesis. This will not conclude with a simple affirmation or refutation, but rather specify completely the implicit requirements on goals and purposes under which the hypothesis holds.
Meta-Gradients in Non-Stationary Environments
Sep 13, 2022
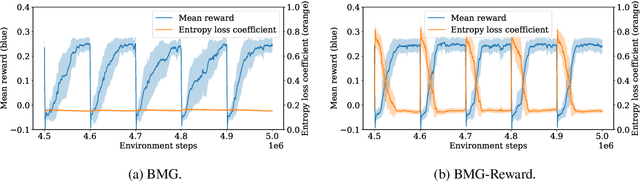
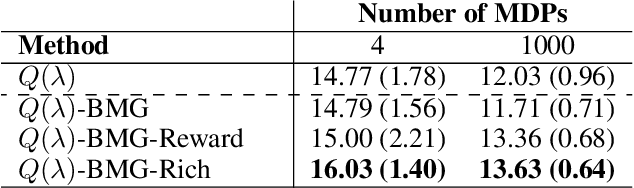
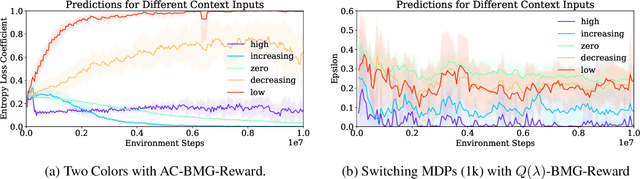
Meta-gradient methods (Xu et al., 2018; Zahavy et al., 2020) offer a promising solution to the problem of hyperparameter selection and adaptation in non-stationary reinforcement learning problems. However, the properties of meta-gradients in such environments have not been systematically studied. In this work, we bring new clarity to meta-gradients in non-stationary environments. Concretely, we ask: (i) how much information should be given to the learned optimizers, so as to enable faster adaptation and generalization over a lifetime, (ii) what meta-optimizer functions are learned in this process, and (iii) whether meta-gradient methods provide a bigger advantage in highly non-stationary environments. To study the effect of information provided to the meta-optimizer, as in recent works (Flennerhag et al., 2021; Almeida et al., 2021), we replace the tuned meta-parameters of fixed update rules with learned meta-parameter functions of selected context features. The context features carry information about agent performance and changes in the environment and hence can inform learned meta-parameter schedules. We find that adding more contextual information is generally beneficial, leading to faster adaptation of meta-parameter values and increased performance over a lifetime. We support these results with a qualitative analysis of resulting meta-parameter schedules and learned functions of context features. Lastly, we find that without context, meta-gradients do not provide a consistent advantage over the baseline in highly non-stationary environments. Our findings suggest that contextualizing meta-gradients can play a pivotal role in extracting high performance from meta-gradients in non-stationary settings.
A Theory of Abstraction in Reinforcement Learning
Mar 01, 2022
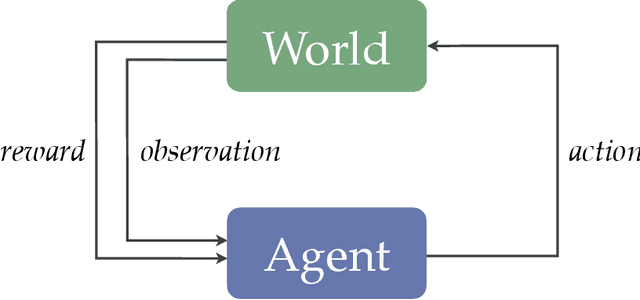
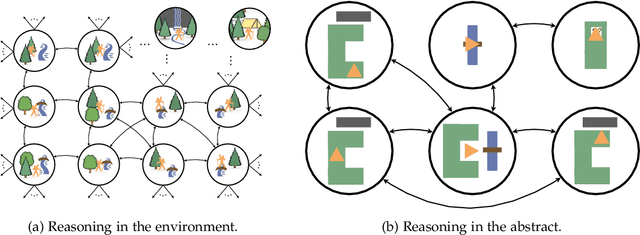
Reinforcement learning defines the problem facing agents that learn to make good decisions through action and observation alone. To be effective problem solvers, such agents must efficiently explore vast worlds, assign credit from delayed feedback, and generalize to new experiences, all while making use of limited data, computational resources, and perceptual bandwidth. Abstraction is essential to all of these endeavors. Through abstraction, agents can form concise models of their environment that support the many practices required of a rational, adaptive decision maker. In this dissertation, I present a theory of abstraction in reinforcement learning. I first offer three desiderata for functions that carry out the process of abstraction: they should 1) preserve representation of near-optimal behavior, 2) be learned and constructed efficiently, and 3) lower planning or learning time. I then present a suite of new algorithms and analysis that clarify how agents can learn to abstract according to these desiderata. Collectively, these results provide a partial path toward the discovery and use of abstraction that minimizes the complexity of effective reinforcement learning.
On the Expressivity of Markov Reward
Nov 01, 2021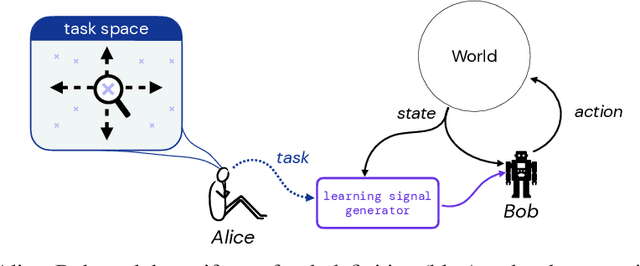


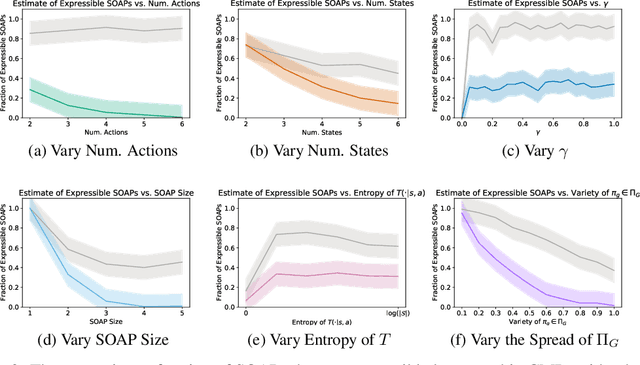
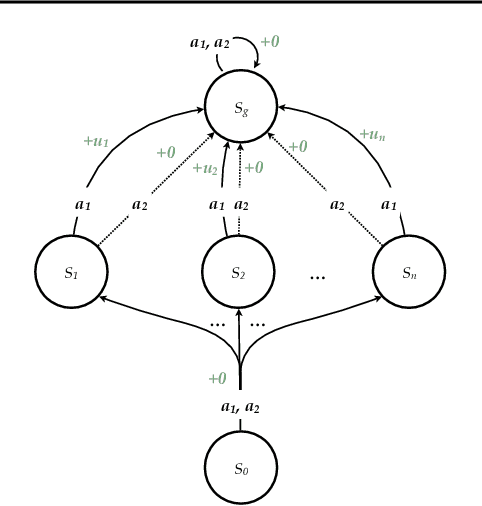
Reward is the driving force for reinforcement-learning agents. This paper is dedicated to understanding the expressivity of reward as a way to capture tasks that we would want an agent to perform. We frame this study around three new abstract notions of "task" that might be desirable: (1) a set of acceptable behaviors, (2) a partial ordering over behaviors, or (3) a partial ordering over trajectories. Our main results prove that while reward can express many of these tasks, there exist instances of each task type that no Markov reward function can capture. We then provide a set of polynomial-time algorithms that construct a Markov reward function that allows an agent to optimize tasks of each of these three types, and correctly determine when no such reward function exists. We conclude with an empirical study that corroborates and illustrates our theoretical findings.
Bad-Policy Density: A Measure of Reinforcement Learning Hardness
Oct 07, 2021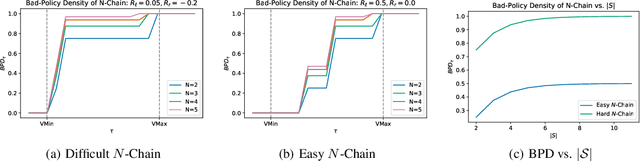
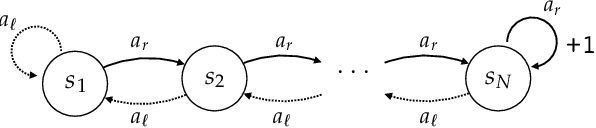
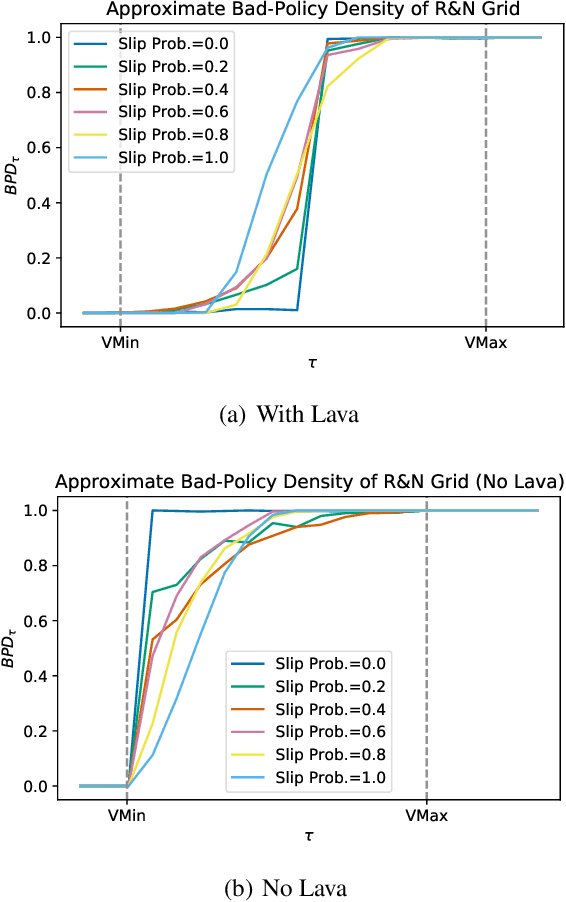
Reinforcement learning is hard in general. Yet, in many specific environments, learning is easy. What makes learning easy in one environment, but difficult in another? We address this question by proposing a simple measure of reinforcement-learning hardness called the bad-policy density. This quantity measures the fraction of the deterministic stationary policy space that is below a desired threshold in value. We prove that this simple quantity has many properties one would expect of a measure of learning hardness. Further, we prove it is NP-hard to compute the measure in general, but there are paths to polynomial-time approximation. We conclude by summarizing potential directions and uses for this measure.
Control of mental representations in human planning
May 14, 2021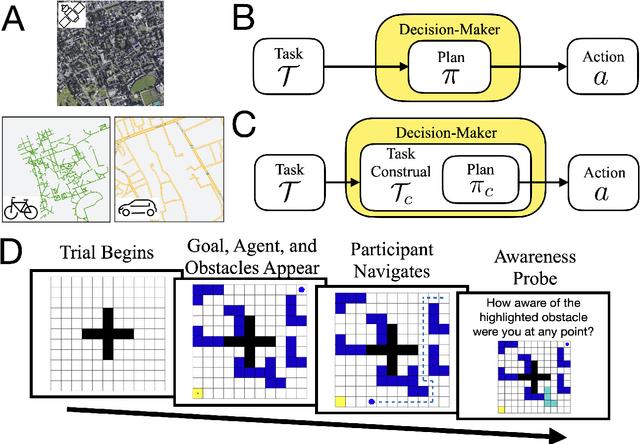
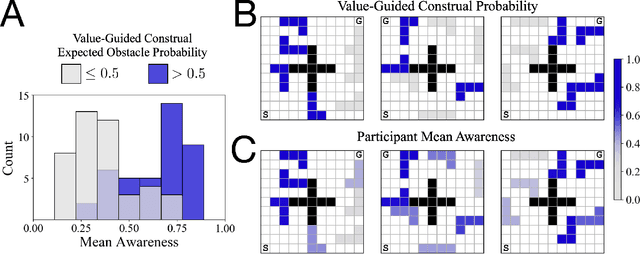
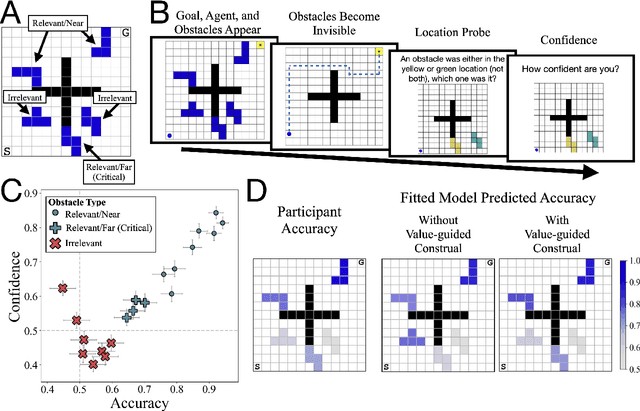
One of the most striking features of human cognition is the capacity to plan. Two aspects of human planning stand out: its efficiency, even in complex environments, and its flexibility, even in changing environments. Efficiency is especially impressive because directly computing an optimal plan is intractable, even for modestly complex tasks, and yet people successfully solve myriad everyday problems despite limited cognitive resources. Standard accounts in psychology, economics, and artificial intelligence have suggested this is because people have a mental representation of a task and then use heuristics to plan in that representation. However, this approach generally assumes that mental representations are fixed. Here, we propose that mental representations can be controlled and that this provides opportunities to adaptively simplify problems so they can be more easily reasoned about -- a process we refer to as construal. We construct a formal model of this process and, in a series of large, pre-registered behavioral experiments, show both that construal is subject to online cognitive control and that people form value-guided construals that optimally balance the complexity of a representation and its utility for planning and acting. These results demonstrate how strategically perceiving and conceiving problems facilitates the effective use of limited cognitive resources.
Revisiting Peng's Q for Modern Reinforcement Learning
Feb 27, 2021
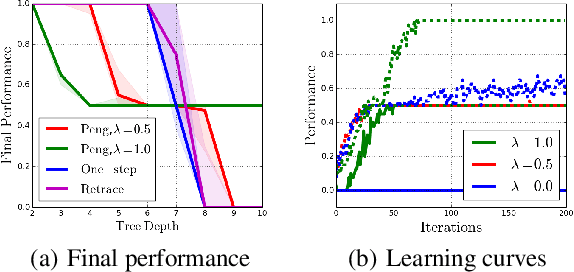

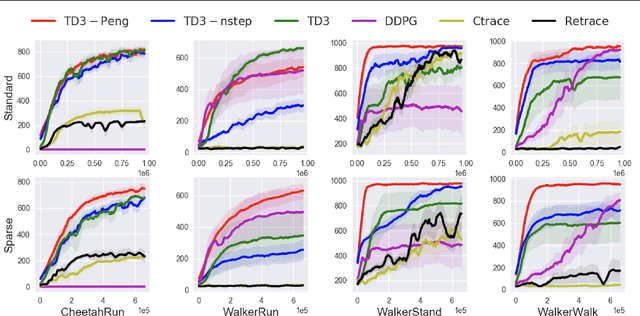
Off-policy multi-step reinforcement learning algorithms consist of conservative and non-conservative algorithms: the former actively cut traces, whereas the latter do not. Recently, Munos et al. (2016) proved the convergence of conservative algorithms to an optimal Q-function. In contrast, non-conservative algorithms are thought to be unsafe and have a limited or no theoretical guarantee. Nonetheless, recent studies have shown that non-conservative algorithms empirically outperform conservative ones. Motivated by the empirical results and the lack of theory, we carry out theoretical analyses of Peng's Q($\lambda$), a representative example of non-conservative algorithms. We prove that it also converges to an optimal policy provided that the behavior policy slowly tracks a greedy policy in a way similar to conservative policy iteration. Such a result has been conjectured to be true but has not been proven. We also experiment with Peng's Q($\lambda$) in complex continuous control tasks, confirming that Peng's Q($\lambda$) often outperforms conservative algorithms despite its simplicity. These results indicate that Peng's Q($\lambda$), which was thought to be unsafe, is a theoretically-sound and practically effective algorithm.