 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBad-Policy Density: A Measure of Reinforcement Learning Hardness
Oct 07, 2021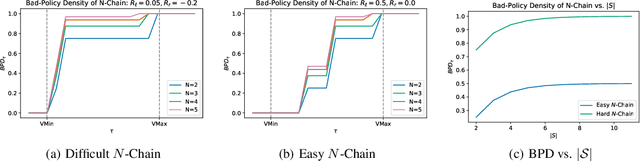
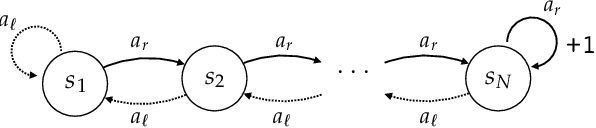
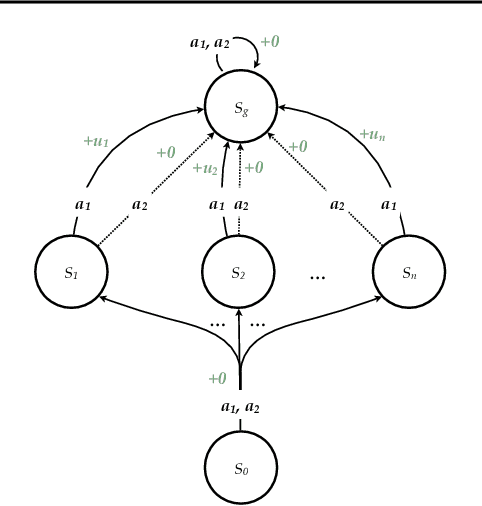
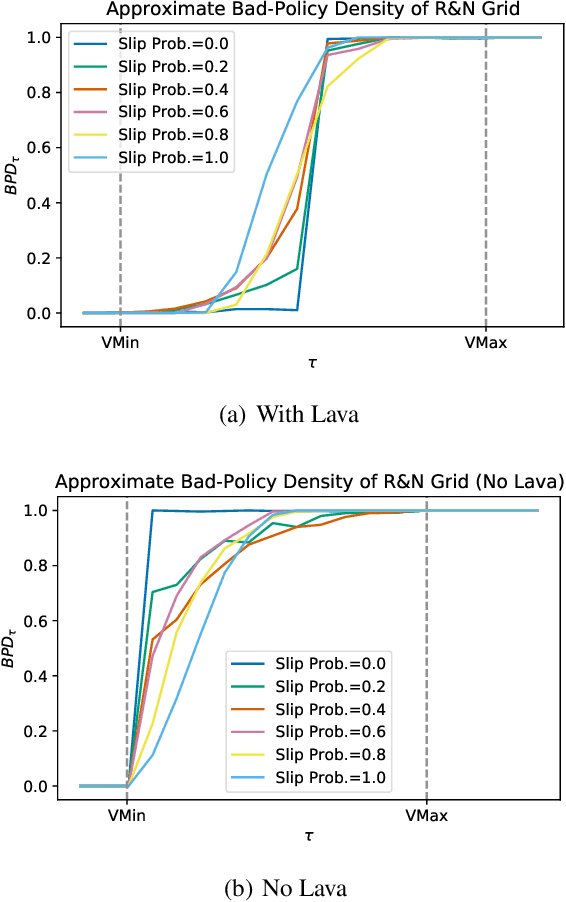
Reinforcement learning is hard in general. Yet, in many specific environments, learning is easy. What makes learning easy in one environment, but difficult in another? We address this question by proposing a simple measure of reinforcement-learning hardness called the bad-policy density. This quantity measures the fraction of the deterministic stationary policy space that is below a desired threshold in value. We prove that this simple quantity has many properties one would expect of a measure of learning hardness. Further, we prove it is NP-hard to compute the measure in general, but there are paths to polynomial-time approximation. We conclude by summarizing potential directions and uses for this measure.
Near Optimal Behavior via Approximate State Abstraction
Jan 15, 2017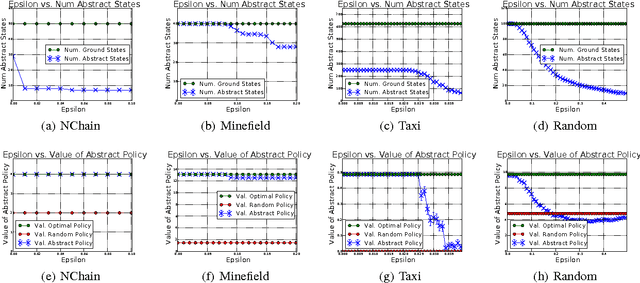
The combinatorial explosion that plagues planning and reinforcement learning (RL) algorithms can be moderated using state abstraction. Prohibitively large task representations can be condensed such that essential information is preserved, and consequently, solutions are tractably computable. However, exact abstractions, which treat only fully-identical situations as equivalent, fail to present opportunities for abstraction in environments where no two situations are exactly alike. In this work, we investigate approximate state abstractions, which treat nearly-identical situations as equivalent. We present theoretical guarantees of the quality of behaviors derived from four types of approximate abstractions. Additionally, we empirically demonstrate that approximate abstractions lead to reduction in task complexity and bounded loss of optimality of behavior in a variety of environments.