 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStarCoder: may the source be with you!
May 09, 2023



The BigCode community, an open-scientific collaboration working on the responsible development of Large Language Models for Code (Code LLMs), introduces StarCoder and StarCoderBase: 15.5B parameter models with 8K context length, infilling capabilities and fast large-batch inference enabled by multi-query attention. StarCoderBase is trained on 1 trillion tokens sourced from The Stack, a large collection of permissively licensed GitHub repositories with inspection tools and an opt-out process. We fine-tuned StarCoderBase on 35B Python tokens, resulting in the creation of StarCoder. We perform the most comprehensive evaluation of Code LLMs to date and show that StarCoderBase outperforms every open Code LLM that supports multiple programming languages and matches or outperforms the OpenAI code-cushman-001 model. Furthermore, StarCoder outperforms every model that is fine-tuned on Python, can be prompted to achieve 40\% pass@1 on HumanEval, and still retains its performance on other programming languages. We take several important steps towards a safe open-access model release, including an improved PII redaction pipeline and a novel attribution tracing tool, and make the StarCoder models publicly available under a more commercially viable version of the Open Responsible AI Model license.
Semi-Structured Object Sequence Encoders
Jan 10, 2023



In this paper we explore the task of modeling (semi) structured object sequences; in particular we focus our attention on the problem of developing a structure-aware input representation for such sequences. In such sequences, we assume that each structured object is represented by a set of key-value pairs which encode the attributes of the structured object. Given a universe of keys, a sequence of structured objects can then be viewed as an evolution of the values for each key, over time. We encode and construct a sequential representation using the values for a particular key (Temporal Value Modeling - TVM) and then self-attend over the set of key-conditioned value sequences to a create a representation of the structured object sequence (Key Aggregation - KA). We pre-train and fine-tune the two components independently and present an innovative training schedule that interleaves the training of both modules with shared attention heads. We find that this iterative two part-training results in better performance than a unified network with hierarchical encoding as well as over, other methods that use a {\em record-view} representation of the sequence \cite{de2021transformers4rec} or a simple {\em flattened} representation of the sequence. We conduct experiments using real-world data to demonstrate the advantage of interleaving TVM-KA on multiple tasks and detailed ablation studies motivating our modeling choices. We find that our approach performs better than flattening sequence objects and also allows us to operate on significantly larger sequences than existing methods.
SantaCoder: don't reach for the stars!
Jan 09, 2023



The BigCode project is an open-scientific collaboration working on the responsible development of large language models for code. This tech report describes the progress of the collaboration until December 2022, outlining the current state of the Personally Identifiable Information (PII) redaction pipeline, the experiments conducted to de-risk the model architecture, and the experiments investigating better preprocessing methods for the training data. We train 1.1B parameter models on the Java, JavaScript, and Python subsets of The Stack and evaluate them on the MultiPL-E text-to-code benchmark. We find that more aggressive filtering of near-duplicates can further boost performance and, surprisingly, that selecting files from repositories with 5+ GitHub stars deteriorates performance significantly. Our best model outperforms previous open-source multilingual code generation models (InCoder-6.7B and CodeGen-Multi-2.7B) in both left-to-right generation and infilling on the Java, JavaScript, and Python portions of MultiPL-E, despite being a substantially smaller model. All models are released under an OpenRAIL license at https://hf.co/bigcode.
BLOOM: A 176B-Parameter Open-Access Multilingual Language Model
Nov 09, 2022Large language models (LLMs) have been shown to be able to perform new tasks based on a few demonstrations or natural language instructions. While these capabilities have led to widespread adoption, most LLMs are developed by resource-rich organizations and are frequently kept from the public. As a step towards democratizing this powerful technology, we present BLOOM, a 176B-parameter open-access language model designed and built thanks to a collaboration of hundreds of researchers. BLOOM is a decoder-only Transformer language model that was trained on the ROOTS corpus, a dataset comprising hundreds of sources in 46 natural and 13 programming languages (59 in total). We find that BLOOM achieves competitive performance on a wide variety of benchmarks, with stronger results after undergoing multitask prompted finetuning. To facilitate future research and applications using LLMs, we publicly release our models and code under the Responsible AI License.
Joint Reasoning on Hybrid-knowledge sources for Task-Oriented Dialog
Oct 13, 2022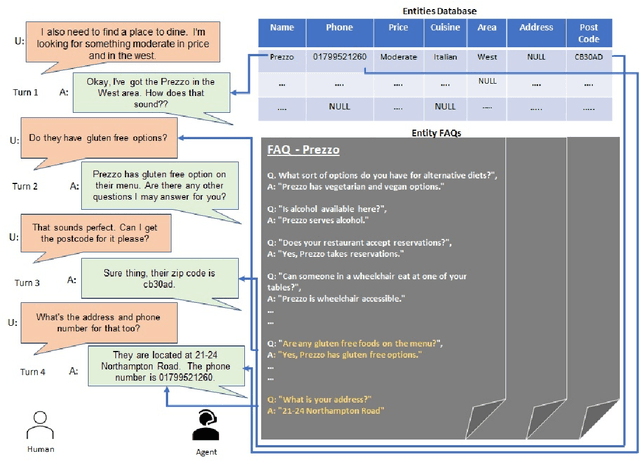

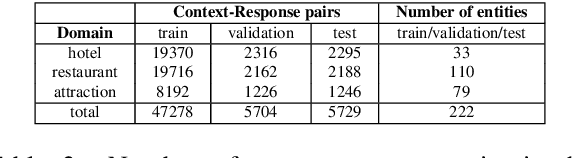
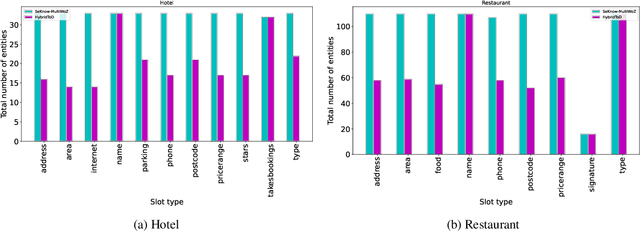
Traditional systems designed for task oriented dialog utilize knowledge present only in structured knowledge sources to generate responses. However, relevant information required to generate responses may also reside in unstructured sources, such as documents. Recent state of the art models such as HyKnow and SeKnow aimed at overcoming these challenges make limiting assumptions about the knowledge sources. For instance, these systems assume that certain types of information, such as a phone number, is always present in a structured KB while information about aspects such as entrance ticket prices would always be available in documents. In this paper, we create a modified version of the MutliWOZ based dataset prepared by SeKnow to demonstrate how current methods have significant degradation in performance when strict assumptions about the source of information are removed. Then, in line with recent work exploiting pre-trained language models, we fine-tune a BART based model using prompts for the tasks of querying knowledge sources, as well as, for response generation, without making assumptions about the information present in each knowledge source. Through a series of experiments, we demonstrate that our model is robust to perturbations to knowledge modality (source of information), and that it can fuse information from structured as well as unstructured knowledge to generate responses.
Mix-and-Match: Scalable Dialog Response Retrieval using Gaussian Mixture Embeddings
Apr 06, 2022
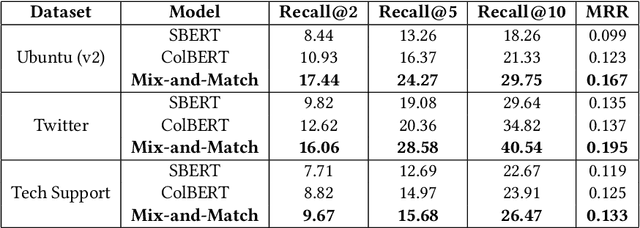
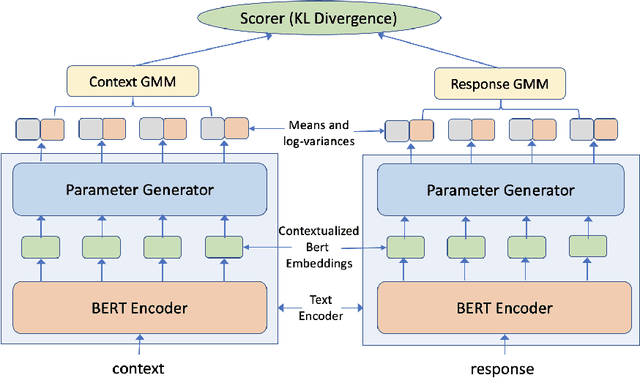
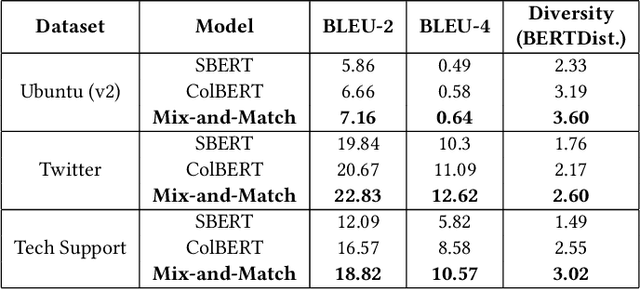
Embedding-based approaches for dialog response retrieval embed the context-response pairs as points in the embedding space. These approaches are scalable, but fail to account for the complex, many-to-many relationships that exist between context-response pairs. On the other end of the spectrum, there are approaches that feed the context-response pairs jointly through multiple layers of neural networks. These approaches can model the complex relationships between context-response pairs, but fail to scale when the set of responses is moderately large (>100). In this paper, we combine the best of both worlds by proposing a scalable model that can learn complex relationships between context-response pairs. Specifically, the model maps the contexts as well as responses to probability distributions over the embedding space. We train the models by optimizing the Kullback-Leibler divergence between the distributions induced by context-response pairs in the training data. We show that the resultant model achieves better performance as compared to other embedding-based approaches on publicly available conversation data.
Variational Learning for Unsupervised Knowledge Grounded Dialogs
Dec 06, 2021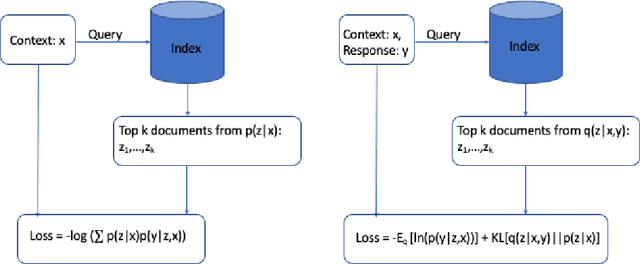
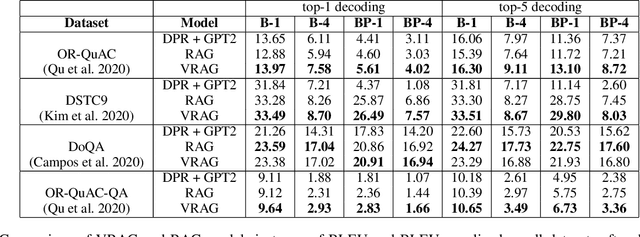
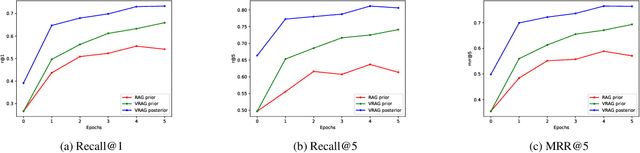
Recent methods for knowledge grounded dialogs generate responses by incorporating information from an external textual document. These methods do not require the exact document to be known during training and rely on the use of a retrieval system to fetch relevant documents from a large index. The documents used to generate the responses are modeled as latent variables whose prior probabilities need to be estimated. Models such as RAG , marginalize the document probabilities over the documents retrieved from the index to define the log likelihood loss function which is optimized end-to-end. In this paper, we develop a variational approach to the above technique wherein, we instead maximize the Evidence Lower bound (ELBO). Using a collection of three publicly available open-conversation datasets, we demonstrate how the posterior distribution, that has information from the ground-truth response, allows for a better approximation of the objective function during training. To overcome the challenges associated with sampling over a large knowledge collection, we develop an efficient approach to approximate the ELBO. To the best of our knowledge we are the first to apply variational training for open-scale unsupervised knowledge grounded dialog systems.
Simulated Chats for Task-oriented Dialog: Learning to Generate Conversations from Instructions
Oct 20, 2020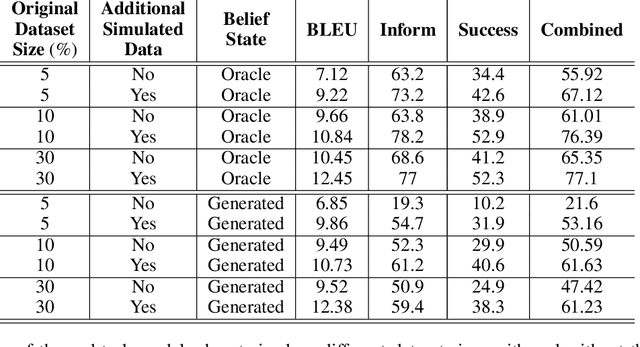
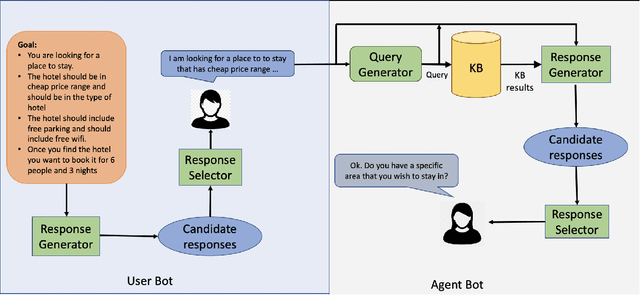
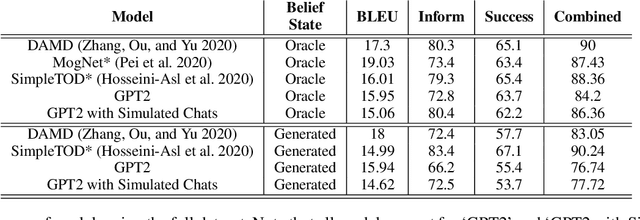

Popular task-oriented dialog data sets such as MultiWOZ (Budzianowski et al. 2018) are created by providing crowd-sourced workers a goal instruction, expressed in natural language, that describes the task to be accomplished. Crowd-sourced workers play the role of a user and an agent to generate dialogs to accomplish tasks involving booking restaurant tables, making train reservations, calling a taxi etc. However, creating large crowd-sourced datasets can be time consuming and expensive. To reduce the cost associated with generating such dialog datasets, recent work has explored methods to automatically create larger datasets from small samples.In this paper, we present a data creation strategy that uses the pre-trained language model, GPT2 (Radford et al. 2018), to simulate the interaction between crowd-sourced workers by creating a user bot and an agent bot. We train the simulators using a smaller percentage of actual crowd-generated conversations and their corresponding goal instructions. We demonstrate that by using the simulated data, we achieve significant improvements in both low-resource setting as well as in over-all task performance. To the best of our knowledge we are the first to present a model for generating entire conversations by simulating the crowd-sourced data collection process
Joint Spatio-Textual Reasoning for Answering Tourism Questions
Oct 19, 2020

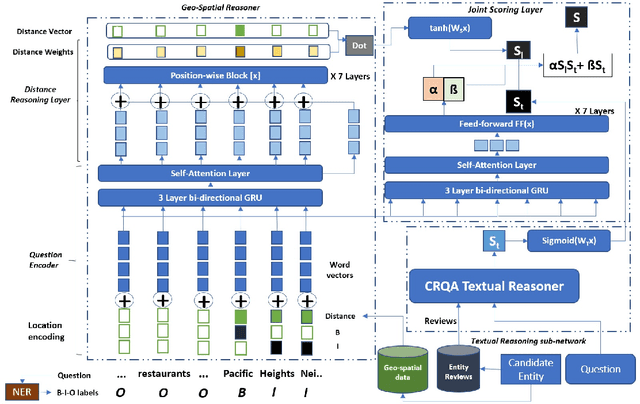
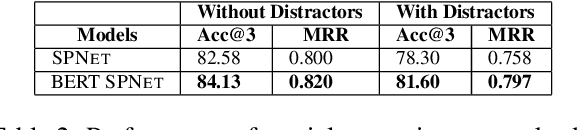
Our goal is to answer real-world tourism questions that seek Points-of-Interest (POI) recommendations. Such questions express various kinds of spatial and non-spatial constraints, necessitating a combination of textual and spatial reasoning. In response, we develop the first joint spatio-textual reasoning model, which combines geo-spatial knowledge with information in textual corpora to answer questions. We first develop a modular spatial-reasoning network that uses geo-coordinates of location names mentioned in a question, and of candidate answer POIs, to reason over only spatial constraints. We then combine our spatial-reasoner with a textual reasoner in a joint model and present experiments on a real world POI recommendation task. We report substantial improvements over existing models with-out joint spatio-textual reasoning.
Neural Conversational QA: Learning to Reason v.s. Exploiting Patterns
Sep 09, 2019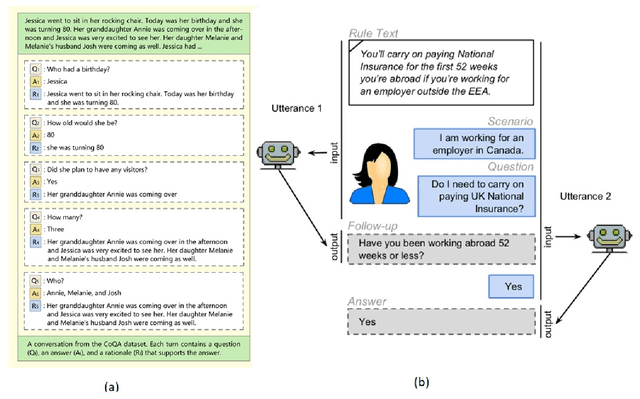

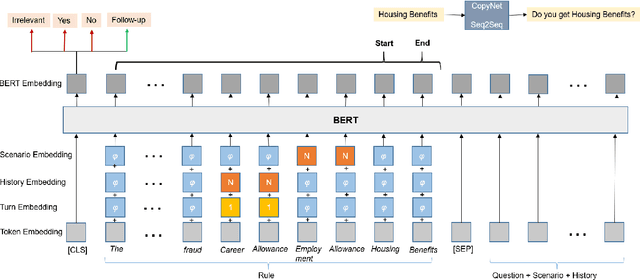
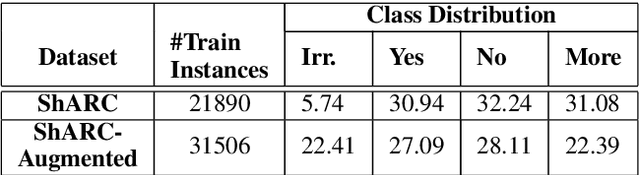
In this paper we work on the recently introduced ShARC task - a challenging form of conversational QA that requires reasoning over rules expressed in natural language. Attuned to the risk of superficial patterns in data being exploited by neural models to do well on benchmark tasks (Niven and Kao 2019), we conduct a series of probing experiments and demonstrate how current state-of-the-art models rely heavily on such patterns. To prevent models from learning based on the superficial clues, we modify the dataset by automatically generating new instances reducing the occurrences of those patterns. We also present a simple yet effective model that learns embedding representations to incorporate dialog history along with the previous answers to follow-up questions. We find that our model outperforms existing methods on all metrics, and the results show that the proposed model is more robust in dealing with spurious patterns and learns to reason meaningfully.