 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLatentWave: JEPA Pretraining for Wireless Foundation Models
Jun 04, 2026Wireless foundation models have emerged as a promising alternative to building separate models for each wireless task. However, existing approaches rely on masked input reconstruction, which can bias representations toward low-level signal details. In this paper, we propose LatentWave, a wireless foundation model pretrained using a Joint-Embedding Predictive Architecture (JEPA) on diverse wireless spectrograms and channel state information (CSI). By predicting masked regions in latent space, LatentWave learns representations that are more transferable out of the box across diverse downstream tasks. The proposed architecture employs per-channel patch embeddings with stochastic channel sampling during pretraining, allowing it to process variable antenna counts and improving usability across heterogeneous wireless configurations. We evaluate LatentWave on four downstream tasks: RF signal classification, 5G NR positioning, beam prediction, and LoS/NLoS classification, comparing against a masked-modeling baseline (WavesFM) pretrained on the same data. Additionally, we show that the masking geometry introduces a task-dependent inductive bias: frequency masking strongly favors channel-related tasks such as positioning and beam prediction, while region masking better preserves discriminability for signal classification.
Towards Zero-Shot Frame Semantic Parsing with Task Agnostic Ontologies and Simple Labels
May 05, 2023



Frame semantic parsing is an important component of task-oriented dialogue systems. Current models rely on a significant amount training data to successfully identify the intent and slots in the user's input utterance. This creates a significant barrier for adding new domains to virtual assistant capabilities, as creation of this data requires highly specialized NLP expertise. In this work we propose OpenFSP, a framework that allows for easy creation of new domains from a handful of simple labels that can be generated without specific NLP knowledge. Our approach relies on creating a small, but expressive, set of domain agnostic slot types that enables easy annotation of new domains. Given such annotation, a matching algorithm relying on sentence encoders predicts the intent and slots for domains defined by end-users. Extensive experiments on the TopV2 dataset shows that our model outperforms strong baselines in this simple labels setting.
Information Extraction of Clinical Trial Eligibility Criteria
Jun 16, 2020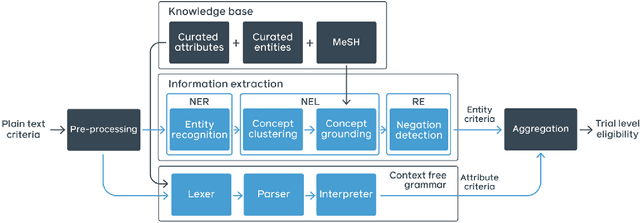
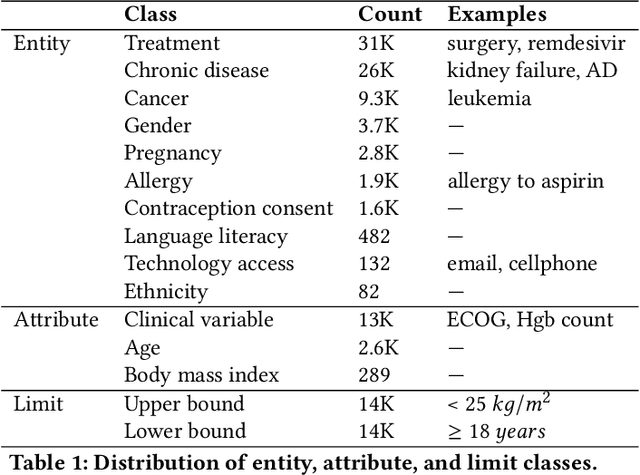
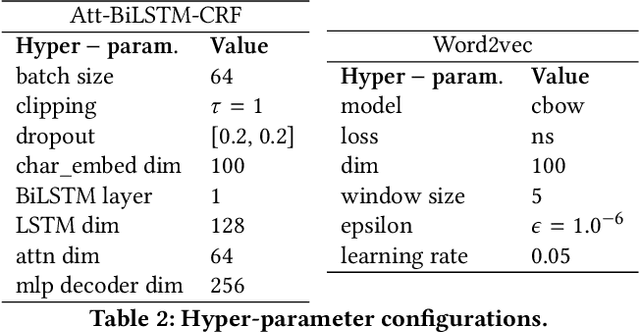
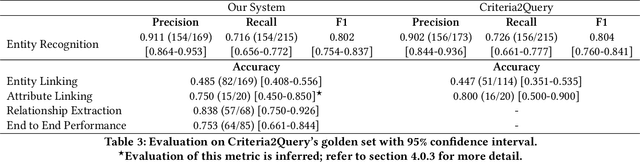
Clinical trials predicate subject eligibility on a diversity of criteria ranging from patient demographics to food allergies. Trials post their requirements as semantically complex, unstructured free-text. Formalizing trial criteria to a computer-interpretable syntax would facilitate eligibility determination. In this paper, we investigate an information extraction (IE) approach for grounding criteria from trials in ClinicalTrials(dot)gov to a shared knowledge base. We frame the problem as a novel knowledge base population task, and implement a solution combining machine learning and context free grammar. To our knowledge, this work is the first criteria extraction system to apply attention-based conditional random field architecture for named entity recognition (NER), and word2vec embedding clustering for named entity linking (NEL). We release the resources and core components of our system on GitHub at https://github.com/facebookresearch/Clinical-Trial-Parser. Finally, we report our per module and end to end performances; we conclude that our system is competitive with Criteria2Query, which we view as the current state-of-the-art in criteria extraction.