 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImplicit Riemannian Concave Potential Maps
Oct 04, 2021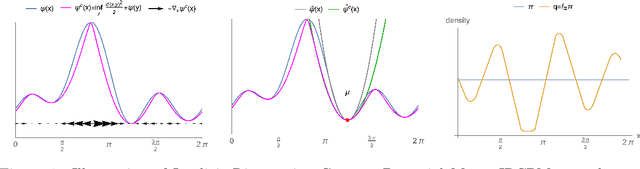

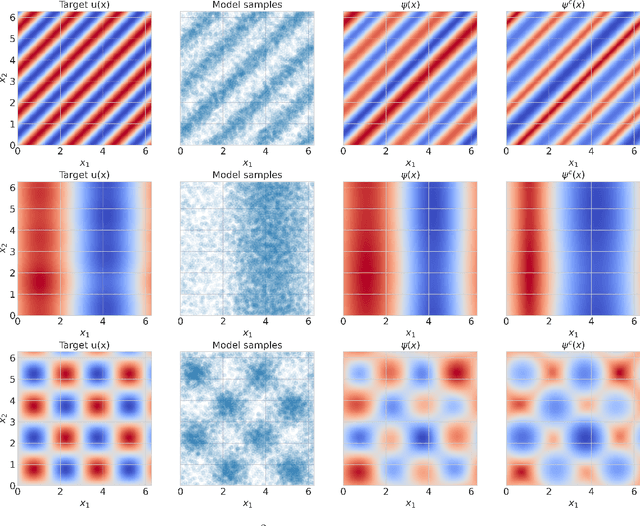
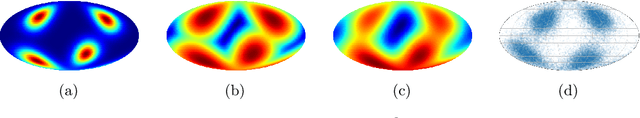
We are interested in the challenging problem of modelling densities on Riemannian manifolds with a known symmetry group using normalising flows. This has many potential applications in physical sciences such as molecular dynamics and quantum simulations. In this work we combine ideas from implicit neural layers and optimal transport theory to propose a generalisation of existing work on exponential map flows, Implicit Riemannian Concave Potential Maps, IRCPMs. IRCPMs have some nice properties such as simplicity of incorporating symmetries and are less expensive than ODE-flows. We provide an initial theoretical analysis of its properties and layout sufficient conditions for stable optimisation. Finally, we illustrate the properties of IRCPMs with density estimation experiments on tori and spheres.
Flow-based sampling for fermionic lattice field theories
Jun 10, 2021
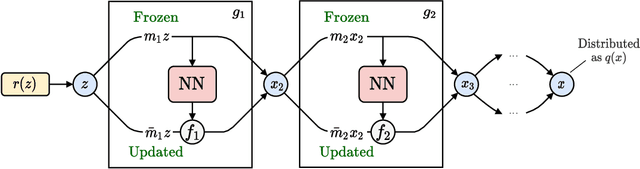

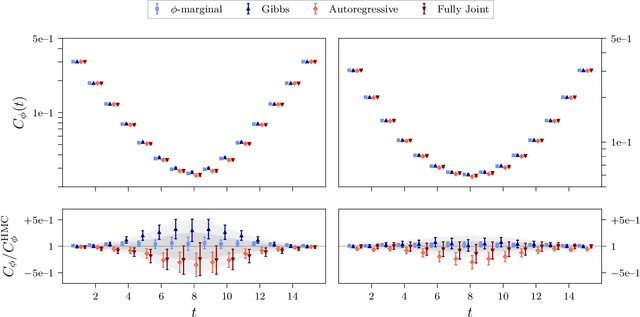
Algorithms based on normalizing flows are emerging as promising machine learning approaches to sampling complicated probability distributions in a way that can be made asymptotically exact. In the context of lattice field theory, proof-of-principle studies have demonstrated the effectiveness of this approach for scalar theories, gauge theories, and statistical systems. This work develops approaches that enable flow-based sampling of theories with dynamical fermions, which is necessary for the technique to be applied to lattice field theory studies of the Standard Model of particle physics and many condensed matter systems. As a practical demonstration, these methods are applied to the sampling of field configurations for a two-dimensional theory of massless staggered fermions coupled to a scalar field via a Yukawa interaction.
NeRF-VAE: A Geometry Aware 3D Scene Generative Model
Apr 01, 2021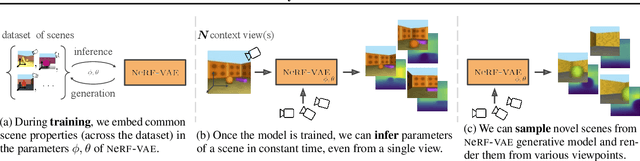

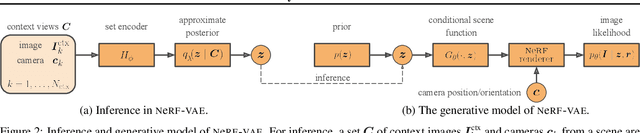
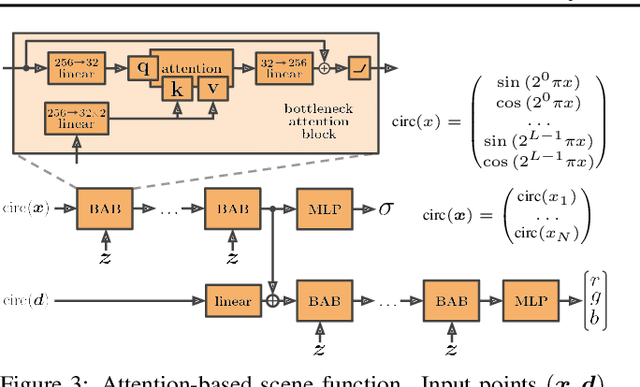
We propose NeRF-VAE, a 3D scene generative model that incorporates geometric structure via NeRF and differentiable volume rendering. In contrast to NeRF, our model takes into account shared structure across scenes, and is able to infer the structure of a novel scene -- without the need to re-train -- using amortized inference. NeRF-VAE's explicit 3D rendering process further contrasts previous generative models with convolution-based rendering which lacks geometric structure. Our model is a VAE that learns a distribution over radiance fields by conditioning them on a latent scene representation. We show that, once trained, NeRF-VAE is able to infer and render geometrically-consistent scenes from previously unseen 3D environments using very few input images. We further demonstrate that NeRF-VAE generalizes well to out-of-distribution cameras, while convolutional models do not. Finally, we introduce and study an attention-based conditioning mechanism of NeRF-VAE's decoder, which improves model performance.
Amortized learning of neural causal representations
Aug 21, 2020



Causal models can compactly and efficiently encode the data-generating process under all interventions and hence may generalize better under changes in distribution. These models are often represented as Bayesian networks and learning them scales poorly with the number of variables. Moreover, these approaches cannot leverage previously learned knowledge to help with learning new causal models. In order to tackle these challenges, we represent a novel algorithm called \textit{causal relational networks} (CRN) for learning causal models using neural networks. The CRN represent causal models using continuous representations and hence could scale much better with the number of variables. These models also take in previously learned information to facilitate learning of new causal models. Finally, we propose a decoding-based metric to evaluate causal models with continuous representations. We test our method on synthetic data achieving high accuracy and quick adaptation to previously unseen causal models.
Causally Correct Partial Models for Reinforcement Learning
Feb 07, 2020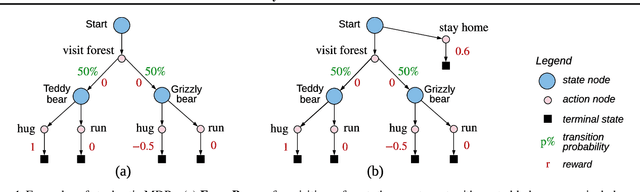


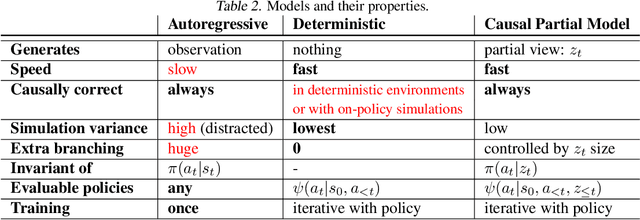
In reinforcement learning, we can learn a model of future observations and rewards, and use it to plan the agent's next actions. However, jointly modeling future observations can be computationally expensive or even intractable if the observations are high-dimensional (e.g. images). For this reason, previous works have considered partial models, which model only part of the observation. In this paper, we show that partial models can be causally incorrect: they are confounded by the observations they don't model, and can therefore lead to incorrect planning. To address this, we introduce a general family of partial models that are provably causally correct, yet remain fast because they do not need to fully model future observations.
Towards Interpretable Reinforcement Learning Using Attention Augmented Agents
Jun 06, 2019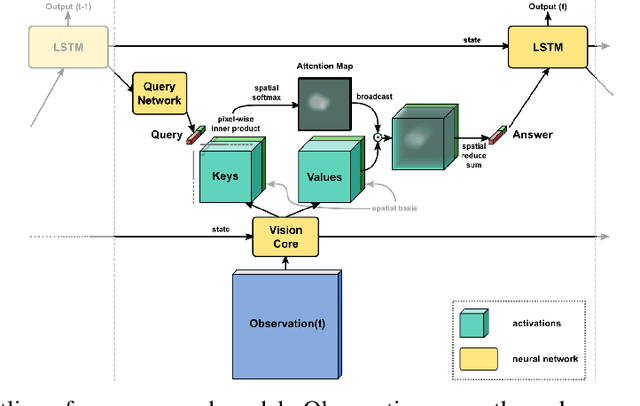
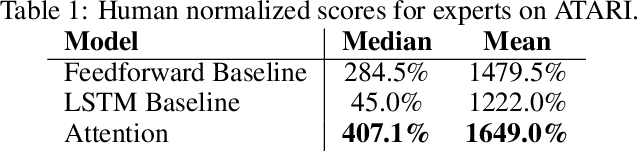

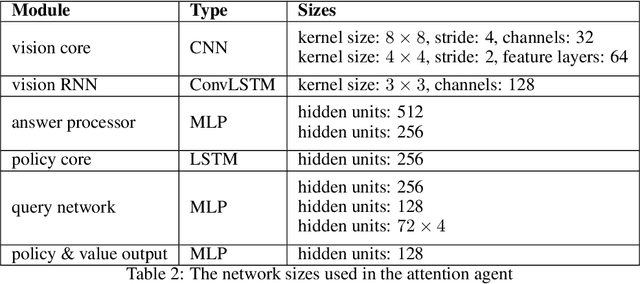
Inspired by recent work in attention models for image captioning and question answering, we present a soft attention model for the reinforcement learning domain. This model uses a soft, top-down attention mechanism to create a bottleneck in the agent, forcing it to focus on task-relevant information by sequentially querying its view of the environment. The output of the attention mechanism allows direct observation of the information used by the agent to select its actions, enabling easier interpretation of this model than of traditional models. We analyze different strategies that the agents learn and show that a handful of strategies arise repeatedly across different games. We also show that the model learns to query separately about space and content (`where' vs. `what'). We demonstrate that an agent using this mechanism can achieve performance competitive with state-of-the-art models on ATARI tasks while still being interpretable.
Consistent Jumpy Predictions for Videos and Scenes
Oct 02, 2018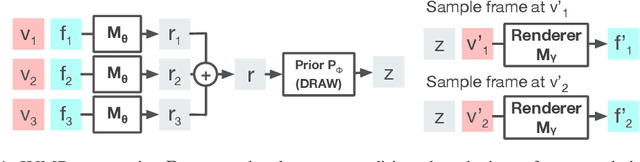
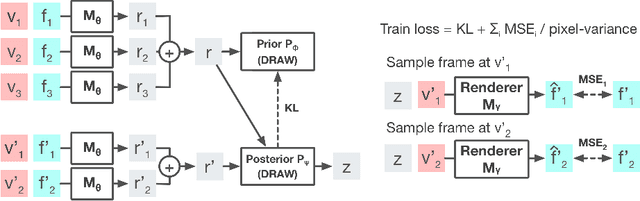


Stochastic video prediction models take in a sequence of image frames, and generate a sequence of consecutive future image frames. These models typically generate future frames in an autoregressive fashion, which is slow and requires the input and output frames to be consecutive. We introduce a model that overcomes these drawbacks by generating a latent representation from an arbitrary set of frames that can then be used to simultaneously and efficiently sample temporally consistent frames at arbitrary time-points. For example, our model can "jump" and directly sample frames at the end of the video, without sampling intermediate frames. Synthetic video evaluations confirm substantial gains in speed and functionality without loss in fidelity. We also apply our framework to a 3D scene reconstruction dataset. Here, our model is conditioned on camera location and can sample consistent sets of images for what an occluded region of a 3D scene might look like, even if there are multiple possibilities for what that region might contain. Reconstructions and videos are available at https://bit.ly/2O4Pc4R.
Learning models for visual 3D localization with implicit mapping
Jul 04, 2018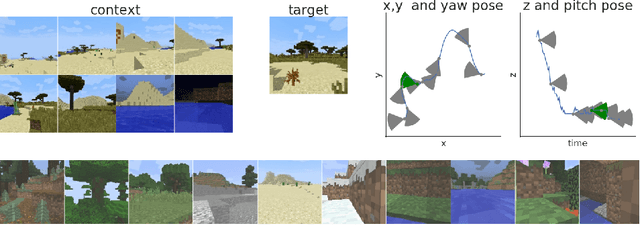
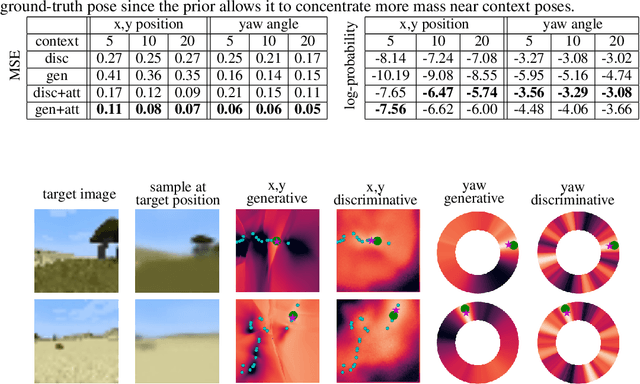
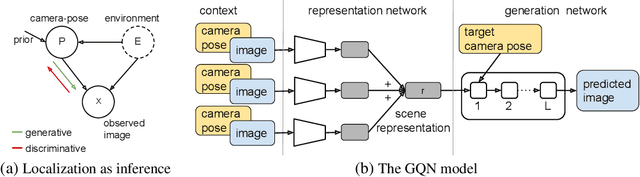
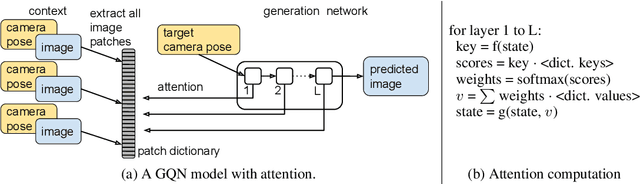
We propose a formulation of visual localization that does not require construction of explicit maps in the form of point clouds or voxels. The goal is to learn an implicit representation of the environment at a higher, more abstract level, for instance that of objects. To study this approach we consider procedurally generated Minecraft worlds, for which we can generate visually rich images along with camera pose coordinates. We first show that Generative Query Networks (GQNs) enhanced with a novel attention mechanism can capture the visual structure of 3D scenes in Minecraft, as evidenced by their samples. We then apply the models to the localization problem, investigating both generative and discriminative approaches, and compare the different ways in which they each capture task uncertainty. Our results show that models with implicit mapping are able to capture the underlying 3D structure of visually complex scenes, and use this to accurately localize new observations, paving the way towards future applications in sequential localization. Supplementary video available at https://youtu.be/iHEXX5wXbCI.
Neural Processes
Jul 04, 2018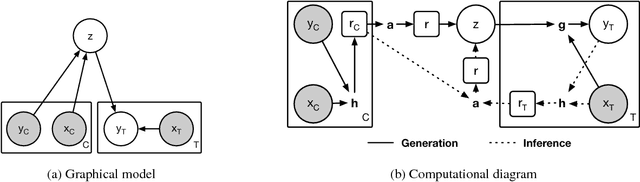

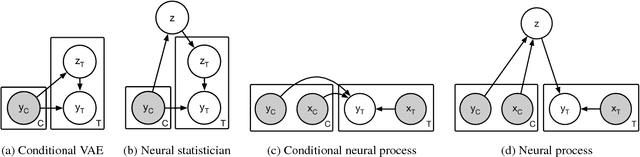
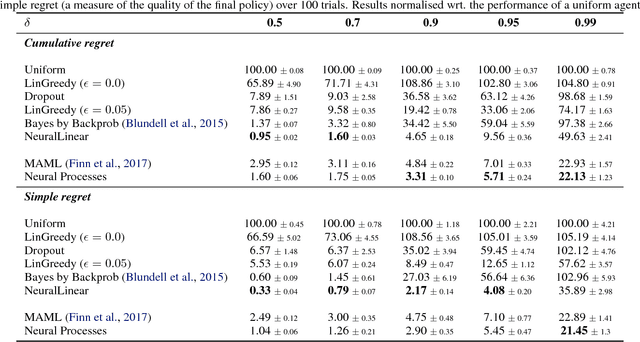
A neural network (NN) is a parameterised function that can be tuned via gradient descent to approximate a labelled collection of data with high precision. A Gaussian process (GP), on the other hand, is a probabilistic model that defines a distribution over possible functions, and is updated in light of data via the rules of probabilistic inference. GPs are probabilistic, data-efficient and flexible, however they are also computationally intensive and thus limited in their applicability. We introduce a class of neural latent variable models which we call Neural Processes (NPs), combining the best of both worlds. Like GPs, NPs define distributions over functions, are capable of rapid adaptation to new observations, and can estimate the uncertainty in their predictions. Like NNs, NPs are computationally efficient during training and evaluation but also learn to adapt their priors to data. We demonstrate the performance of NPs on a range of learning tasks, including regression and optimisation, and compare and contrast with related models in the literature.
Conditional Neural Processes
Jul 04, 2018



Deep neural networks excel at function approximation, yet they are typically trained from scratch for each new function. On the other hand, Bayesian methods, such as Gaussian Processes (GPs), exploit prior knowledge to quickly infer the shape of a new function at test time. Yet GPs are computationally expensive, and it can be hard to design appropriate priors. In this paper we propose a family of neural models, Conditional Neural Processes (CNPs), that combine the benefits of both. CNPs are inspired by the flexibility of stochastic processes such as GPs, but are structured as neural networks and trained via gradient descent. CNPs make accurate predictions after observing only a handful of training data points, yet scale to complex functions and large datasets. We demonstrate the performance and versatility of the approach on a range of canonical machine learning tasks, including regression, classification and image completion.