 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCAS-Net: Conditional Atlas Generation and Brain Segmentation for Fetal MRI
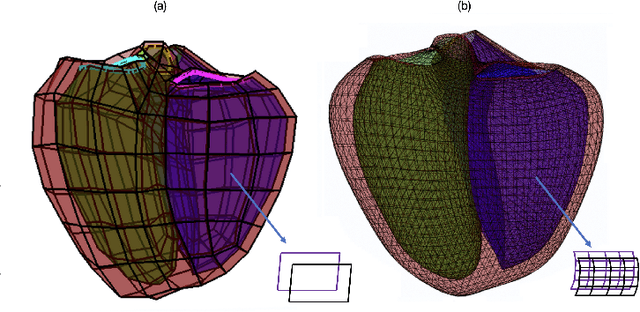
May 17, 2022Fetal Magnetic Resonance Imaging (MRI) is used in prenatal diagnosis and to assess early brain development. Accurate segmentation of the different brain tissues is a vital step in several brain analysis tasks, such as cortical surface reconstruction and tissue thickness measurements. Fetal MRI scans, however, are prone to motion artifacts that can affect the correctness of both manual and automatic segmentation techniques. In this paper, we propose a novel network structure that can simultaneously generate conditional atlases and predict brain tissue segmentation, called CAS-Net. The conditional atlases provide anatomical priors that can constrain the segmentation connectivity, despite the heterogeneity of intensity values caused by motion or partial volume effects. The proposed method is trained and evaluated on 253 subjects from the developing Human Connectome Project (dHCP). The results demonstrate that the proposed method can generate conditional age-specific atlas with sharp boundary and shape variance. It also segment multi-category brain tissues for fetal MRI with a high overall Dice similarity coefficient (DSC) of $85.2\%$ for the selected 9 tissue labels.
SmoothNets: Optimizing CNN architecture design for differentially private deep learning
May 09, 2022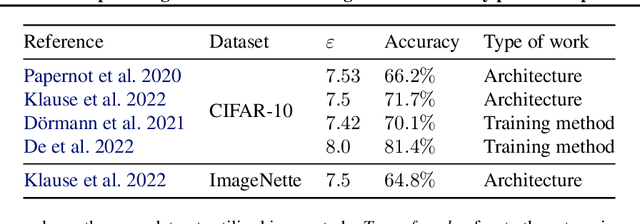
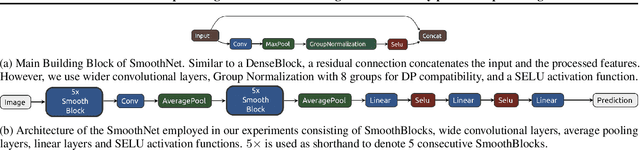
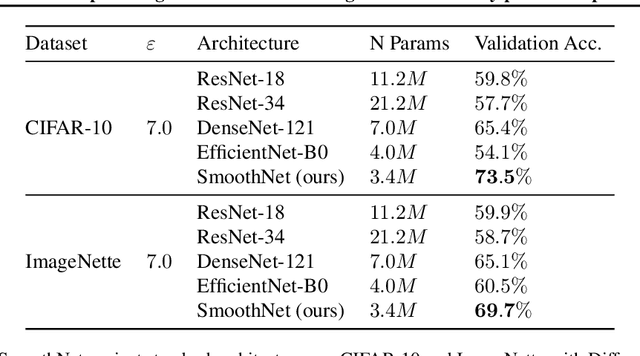
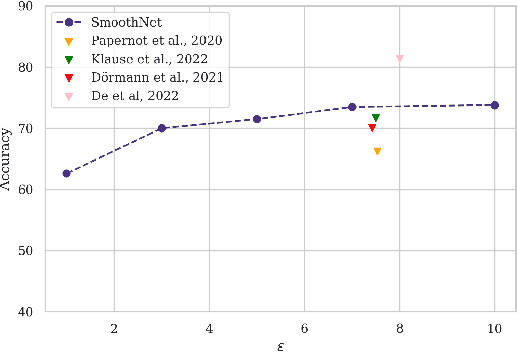
The arguably most widely employed algorithm to train deep neural networks with Differential Privacy is DPSGD, which requires clipping and noising of per-sample gradients. This introduces a reduction in model utility compared to non-private training. Empirically, it can be observed that this accuracy degradation is strongly dependent on the model architecture. We investigated this phenomenon and, by combining components which exhibit good individual performance, distilled a new model architecture termed SmoothNet, which is characterised by increased robustness to the challenges of DP-SGD training. Experimentally, we benchmark SmoothNet against standard architectures on two benchmark datasets and observe that our architecture outperforms others, reaching an accuracy of 73.5\% on CIFAR-10 at $\varepsilon=7.0$ and 69.2\% at $\varepsilon=7.0$ on ImageNette, a state-of-the-art result compared to prior architectural modifications for DP.
Can collaborative learning be private, robust and scalable?
May 05, 2022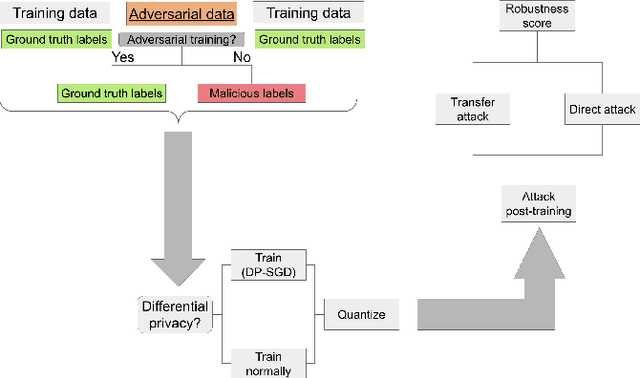

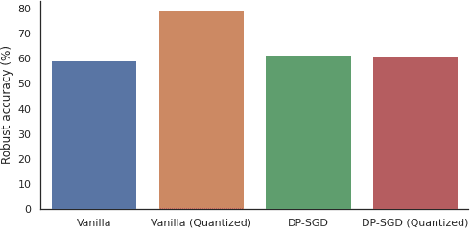
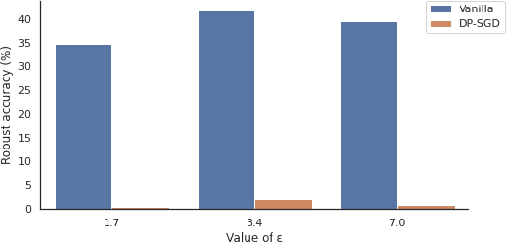
We investigate the effectiveness of combining differential privacy, model compression and adversarial training to improve the robustness of models against adversarial samples in train- and inference-time attacks. We explore the applications of these techniques as well as their combinations to determine which method performs best, without a significant utility trade-off. Our investigation provides a practical overview of various methods that allow one to achieve a competitive model performance, a significant reduction in model's size and an improved empirical adversarial robustness without a severe performance degradation.
Surface Vision Transformers: Flexible Attention-Based Modelling of Biomedical Surfaces
Apr 07, 2022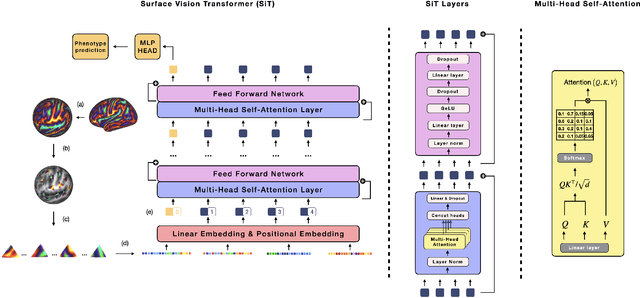
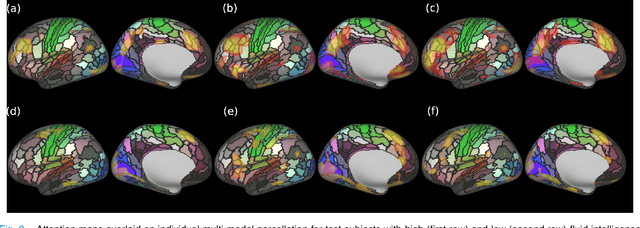
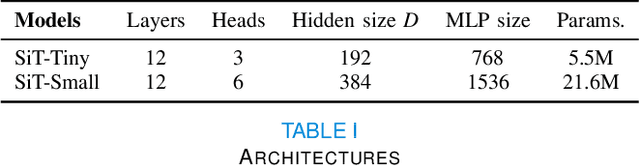
Recent state-of-the-art performances of Vision Transformers (ViT) in computer vision tasks demonstrate that a general-purpose architecture, which implements long-range self-attention, could replace the local feature learning operations of convolutional neural networks. In this paper, we extend ViTs to surfaces by reformulating the task of surface learning as a sequence-to-sequence learning problem, by proposing patching mechanisms for general surface meshes. Sequences of patches are then processed by a transformer encoder and used for classification or regression. We validate our method on a range of different biomedical surface domains and tasks: brain age prediction in the developing Human Connectome Project (dHCP), fluid intelligence prediction in the Human Connectome Project (HCP), and coronary artery calcium score classification using surfaces from the Scottish Computed Tomography of the Heart (SCOT-HEART) dataset, and investigate the impact of pretraining and data augmentation on model performance. Results suggest that Surface Vision Transformers (SiT) demonstrate consistent improvement over geometric deep learning methods for brain age and fluid intelligence prediction and achieve comparable performance on calcium score classification to standard metrics used in clinical practice. Furthermore, analysis of transformer attention maps offers clear and individualised predictions of the features driving each task. Code is available on Github: https://github.com/metrics-lab/surface-vision-transformers
Data and Physics Driven Learning Models for Fast MRI -- Fundamentals and Methodologies from CNN, GAN to Attention and Transformers
Apr 01, 2022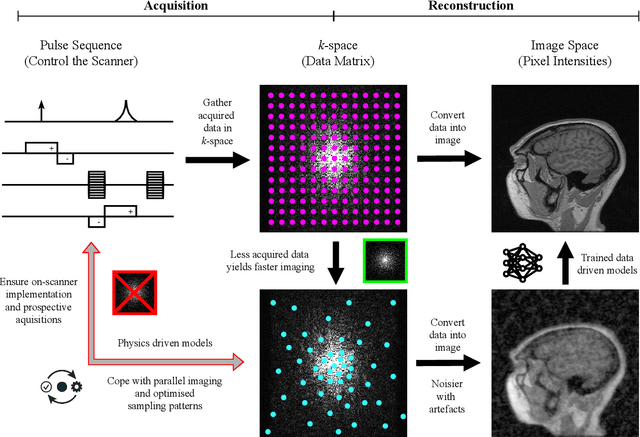
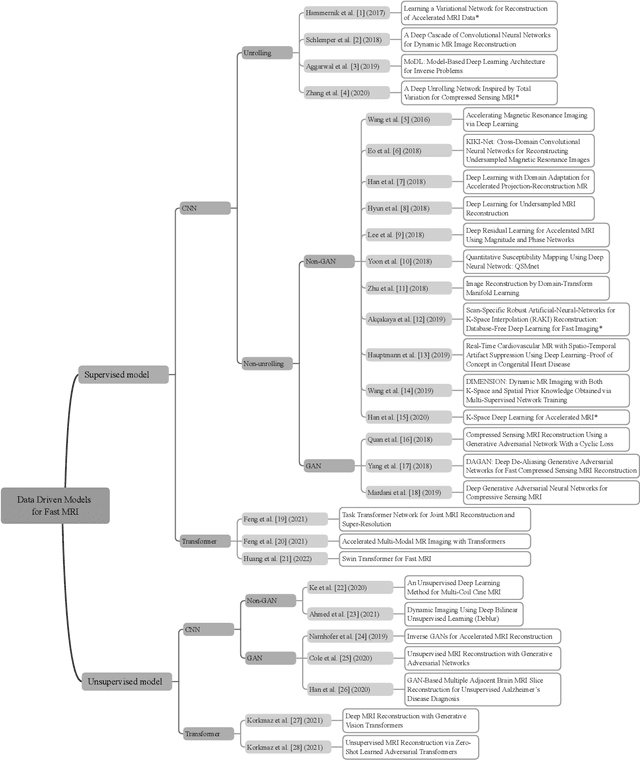
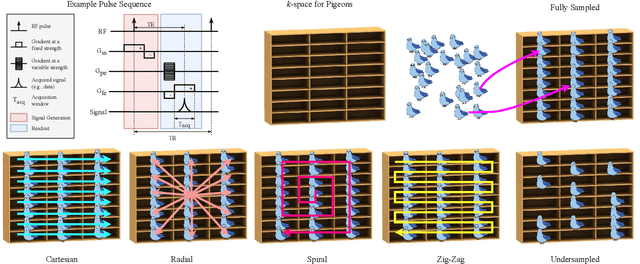
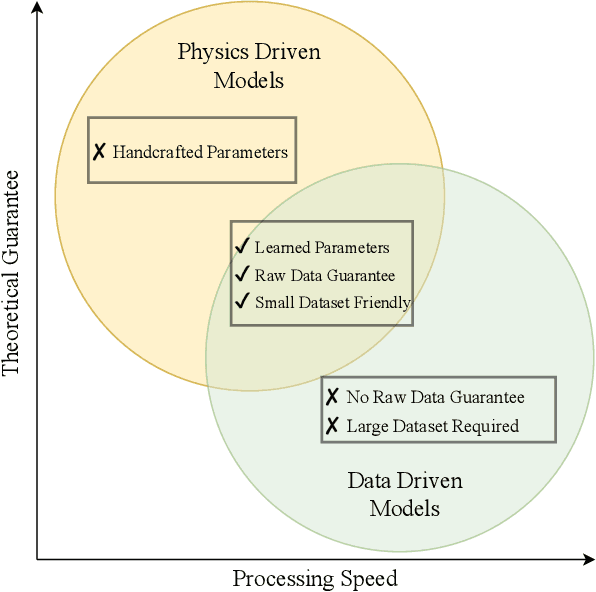
Research studies have shown no qualms about using data driven deep learning models for downstream tasks in medical image analysis, e.g., anatomy segmentation and lesion detection, disease diagnosis and prognosis, and treatment planning. However, deep learning models are not the sovereign remedy for medical image analysis when the upstream imaging is not being conducted properly (with artefacts). This has been manifested in MRI studies, where the scanning is typically slow, prone to motion artefacts, with a relatively low signal to noise ratio, and poor spatial and/or temporal resolution. Recent studies have witnessed substantial growth in the development of deep learning techniques for propelling fast MRI. This article aims to (1) introduce the deep learning based data driven techniques for fast MRI including convolutional neural network and generative adversarial network based methods, (2) survey the attention and transformer based models for speeding up MRI reconstruction, and (3) detail the research in coupling physics and data driven models for MRI acceleration. Finally, we will demonstrate through a few clinical applications, explain the importance of data harmonisation and explainable models for such fast MRI techniques in multicentre and multi-scanner studies, and discuss common pitfalls in current research and recommendations for future research directions.
Surface Vision Transformers: Attention-Based Modelling applied to Cortical Analysis
Mar 30, 2022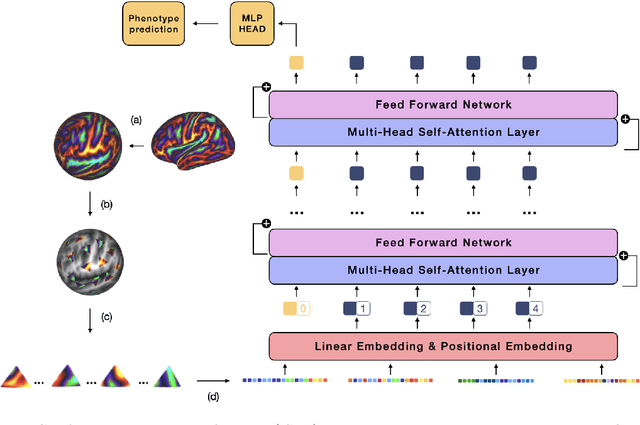

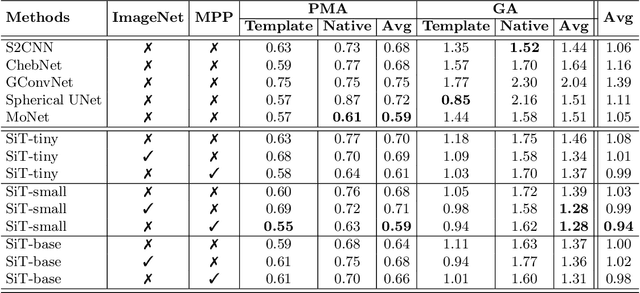
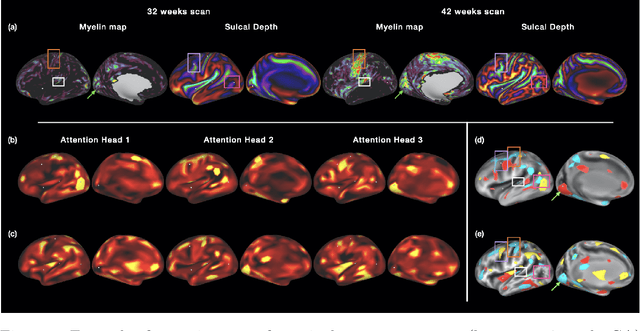
The extension of convolutional neural networks (CNNs) to non-Euclidean geometries has led to multiple frameworks for studying manifolds. Many of those methods have shown design limitations resulting in poor modelling of long-range associations, as the generalisation of convolutions to irregular surfaces is non-trivial. Motivated by the success of attention-modelling in computer vision, we translate convolution-free vision transformer approaches to surface data, to introduce a domain-agnostic architecture to study any surface data projected onto a spherical manifold. Here, surface patching is achieved by representing spherical data as a sequence of triangular patches, extracted from a subdivided icosphere. A transformer model encodes the sequence of patches via successive multi-head self-attention layers while preserving the sequence resolution. We validate the performance of the proposed Surface Vision Transformer (SiT) on the task of phenotype regression from cortical surface metrics derived from the Developing Human Connectome Project (dHCP). Experiments show that the SiT generally outperforms surface CNNs, while performing comparably on registered and unregistered data. Analysis of transformer attention maps offers strong potential to characterise subtle cognitive developmental patterns.
Physics-Driven Deep Learning for Computational Magnetic Resonance Imaging
Mar 23, 2022
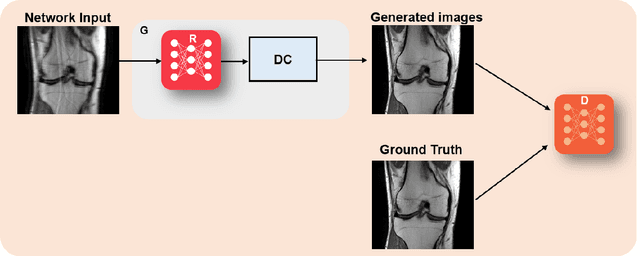
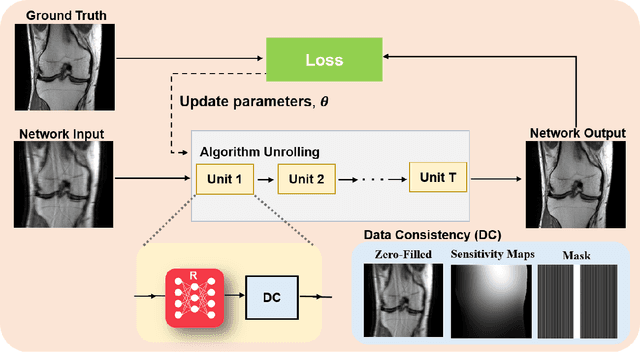
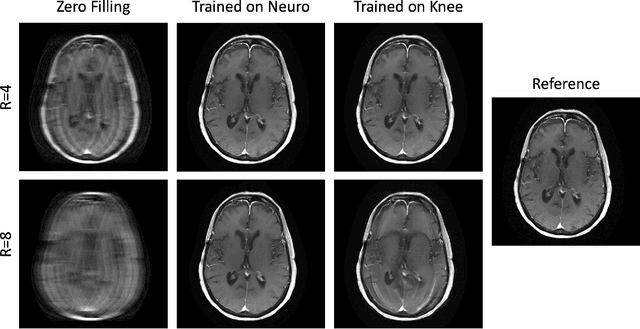
Physics-driven deep learning methods have emerged as a powerful tool for computational magnetic resonance imaging (MRI) problems, pushing reconstruction performance to new limits. This article provides an overview of the recent developments in incorporating physics information into learning-based MRI reconstruction. We consider inverse problems with both linear and non-linear forward models for computational MRI, and review the classical approaches for solving these. We then focus on physics-driven deep learning approaches, covering physics-driven loss functions, plug-and-play methods, generative models, and unrolled networks. We highlight domain-specific challenges such as real- and complex-valued building blocks of neural networks, and translational applications in MRI with linear and non-linear forward models. Finally, we discuss common issues and open challenges, and draw connections to the importance of physics-driven learning when combined with other downstream tasks in the medical imaging pipeline.
SoK: Differential Privacy on Graph-Structured Data
Mar 17, 2022
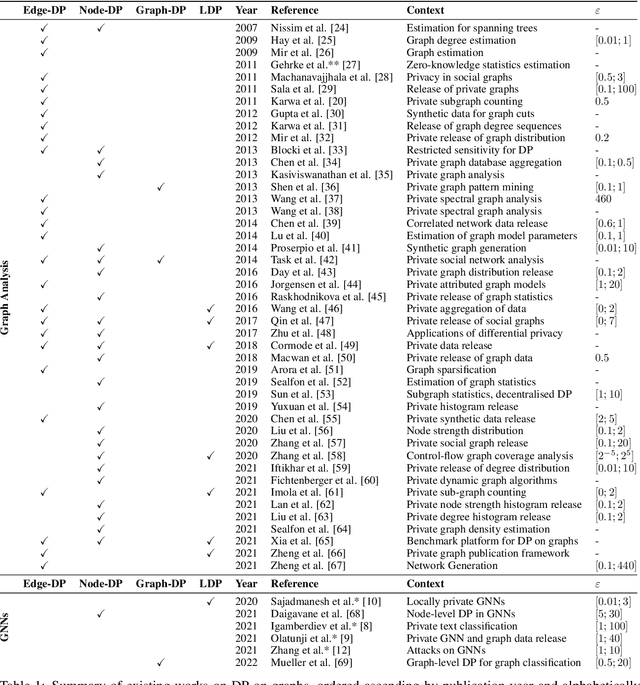
In this work, we study the applications of differential privacy (DP) in the context of graph-structured data. We discuss the formulations of DP applicable to the publication of graphs and their associated statistics as well as machine learning on graph-based data, including graph neural networks (GNNs). The formulation of DP in the context of graph-structured data is difficult, as individual data points are interconnected (often non-linearly or sparsely). This connectivity complicates the computation of individual privacy loss in differentially private learning. The problem is exacerbated by an absence of a single, well-established formulation of DP in graph settings. This issue extends to the domain of GNNs, rendering private machine learning on graph-structured data a challenging task. A lack of prior systematisation work motivated us to study graph-based learning from a privacy perspective. In this work, we systematise different formulations of DP on graphs, discuss challenges and promising applications, including the GNN domain. We compare and separate works into graph analysis tasks and graph learning tasks with GNNs. Finally, we conclude our work with a discussion of open questions and potential directions for further research in this area.
Beyond Gradients: Exploiting Adversarial Priors in Model Inversion Attacks
Mar 01, 2022
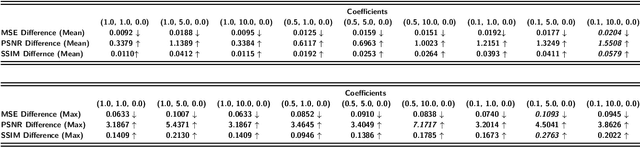
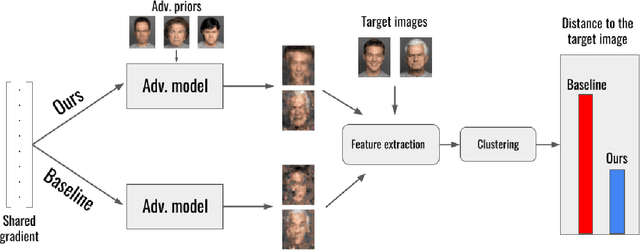
Collaborative machine learning settings like federated learning can be susceptible to adversarial interference and attacks. One class of such attacks is termed model inversion attacks, characterised by the adversary reverse-engineering the model to extract representations and thus disclose the training data. Prior implementations of this attack typically only rely on the captured data (i.e. the shared gradients) and do not exploit the data the adversary themselves control as part of the training consortium. In this work, we propose a novel model inversion framework that builds on the foundations of gradient-based model inversion attacks, but additionally relies on matching the features and the style of the reconstructed image to data that is controlled by an adversary. Our technique outperforms existing gradient-based approaches both qualitatively and quantitatively, while still maintaining the same honest-but-curious threat model, allowing the adversary to obtain enhanced reconstructions while remaining concealed.
Differentially private training of residual networks with scale normalisation
Mar 01, 2022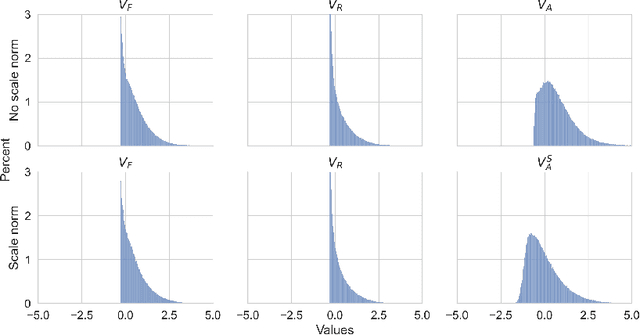
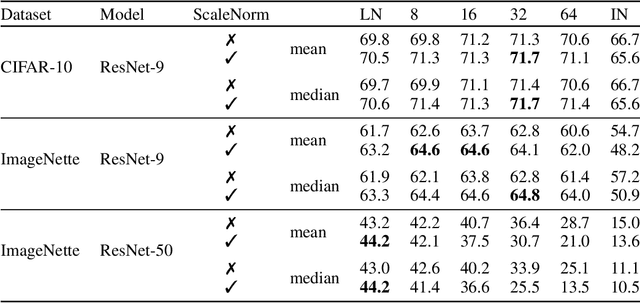
We investigate the optimal choice of replacement layer for Batch Normalisation (BN) in residual networks (ResNets) for training with Differentially Private Stochastic Gradient Descent (DP-SGD) and study the phenomenon of scale mixing in residual blocks, whereby the activations on the two branches are scaled differently. Our experimental evaluation indicates that a hyperparameter search over 1-64 Group Normalisation (GN) groups improves the accuracy of ResNet-9 and ResNet-50 considerably in both benchmark (CIFAR-10) and large-image (ImageNette) tasks. Moreover, Scale Normalisation, a simple modification to the model architecture by which an additional normalisation layer is introduced after the residual block's addition operation further improves the utility of ResNets allowing us to achieve state-of-the-art results on CIFAR-10.