 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFaster Diffusion Cardiac MRI with Deep Learning-based breath hold reduction
Jun 21, 2022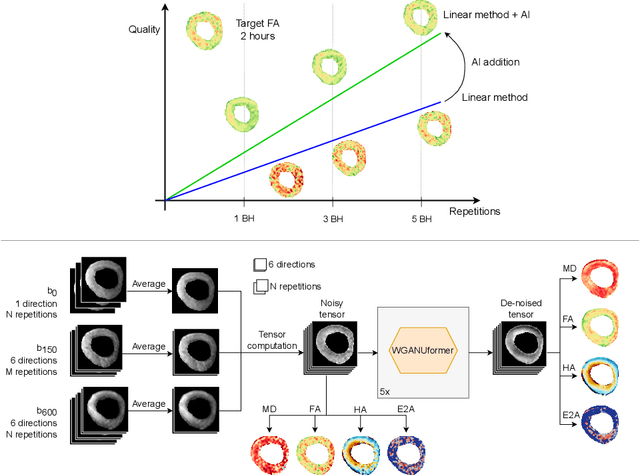
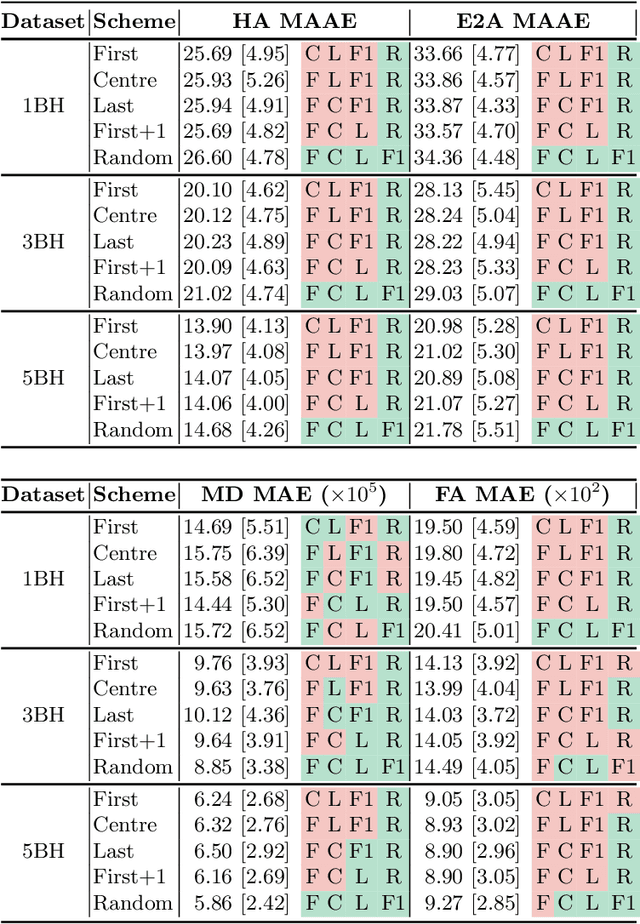
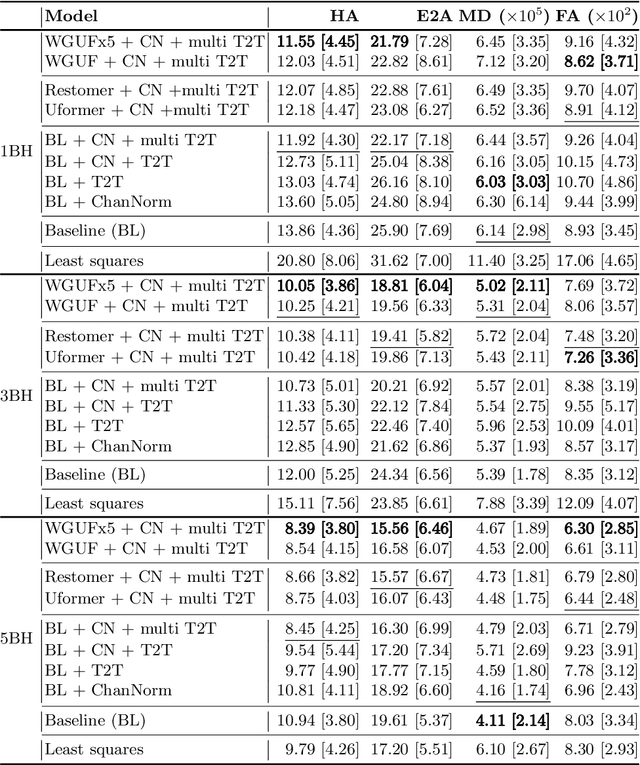
Diffusion Tensor Cardiac Magnetic Resonance (DT-CMR) enables us to probe the microstructural arrangement of cardiomyocytes within the myocardium in vivo and non-invasively, which no other imaging modality allows. This innovative technology could revolutionise the ability to perform cardiac clinical diagnosis, risk stratification, prognosis and therapy follow-up. However, DT-CMR is currently inefficient with over six minutes needed to acquire a single 2D static image. Therefore, DT-CMR is currently confined to research but not used clinically. We propose to reduce the number of repetitions needed to produce DT-CMR datasets and subsequently de-noise them, decreasing the acquisition time by a linear factor while maintaining acceptable image quality. Our proposed approach, based on Generative Adversarial Networks, Vision Transformers, and Ensemble Learning, performs significantly and considerably better than previous proposed approaches, bringing single breath-hold DT-CMR closer to reality.
A Review of Causality for Learning Algorithms in Medical Image Analysis
Jun 11, 2022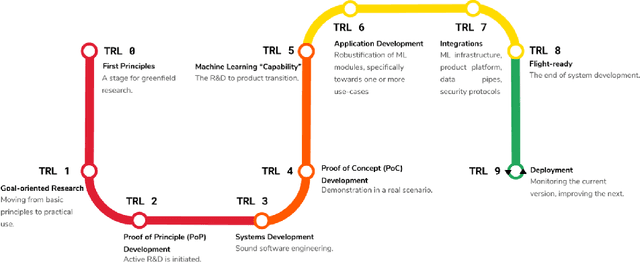

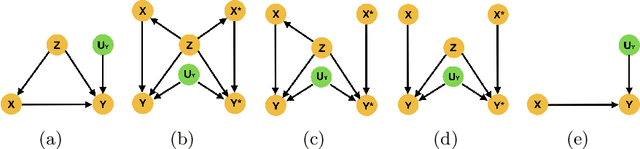
Medical image analysis is a vibrant research area that offers doctors and medical practitioners invaluable insight and the ability to accurately diagnose and monitor disease. Machine learning provides an additional boost for this area. However, machine learning for medical image analysis is particularly vulnerable to natural biases like domain shifts that affect algorithmic performance and robustness. In this paper we analyze machine learning for medical image analysis within the framework of Technology Readiness Levels and review how causal analysis methods can fill a gap when creating robust and adaptable medical image analysis algorithms. We review methods using causality in medical imaging AI/ML and find that causal analysis has the potential to mitigate critical problems for clinical translation but that uptake and clinical downstream research has been limited so far.
Generative Myocardial Motion Tracking via Latent Space Exploration with Biomechanics-informed Prior
Jun 08, 2022
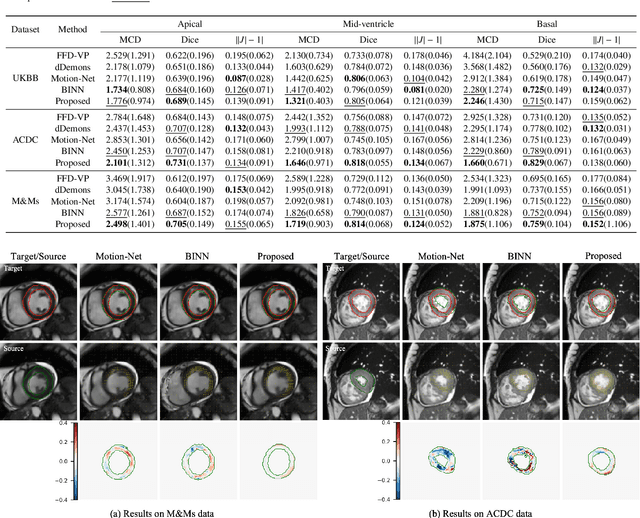
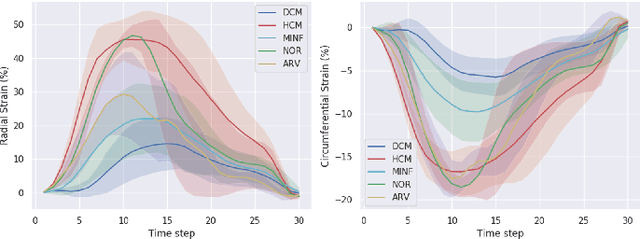
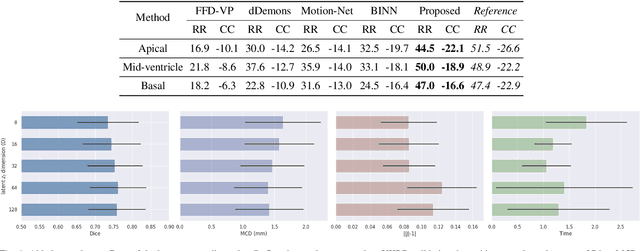
Myocardial motion and deformation are rich descriptors that characterize cardiac function. Image registration, as the most commonly used technique for myocardial motion tracking, is an ill-posed inverse problem which often requires prior assumptions on the solution space. In contrast to most existing approaches which impose explicit generic regularization such as smoothness, in this work we propose a novel method that can implicitly learn an application-specific biomechanics-informed prior and embed it into a neural network-parameterized transformation model. Particularly, the proposed method leverages a variational autoencoder-based generative model to learn a manifold for biomechanically plausible deformations. The motion tracking then can be performed via traversing the learnt manifold to search for the optimal transformations while considering the sequence information. The proposed method is validated on three public cardiac cine MRI datasets with comprehensive evaluations. The results demonstrate that the proposed method can outperform other approaches, yielding higher motion tracking accuracy with reasonable volume preservation and better generalizability to varying data distributions. It also enables better estimates of myocardial strains, which indicates the potential of the method in characterizing spatiotemporal signatures for understanding cardiovascular diseases.
What do we learn? Debunking the Myth of Unsupervised Outlier Detection
Jun 08, 2022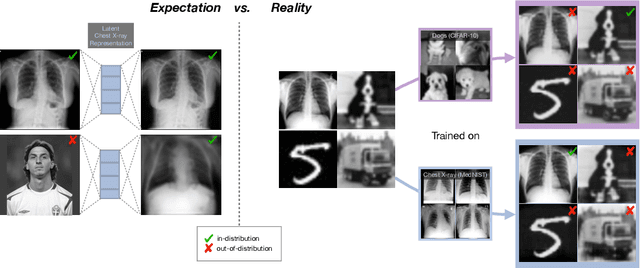
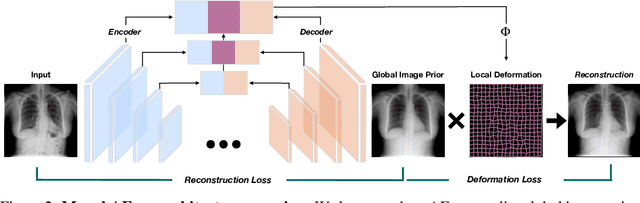
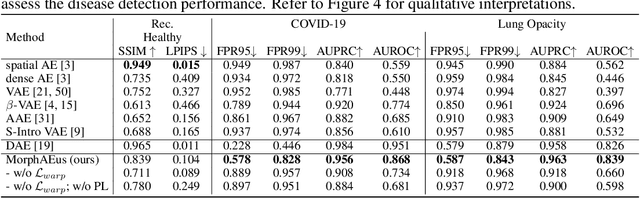
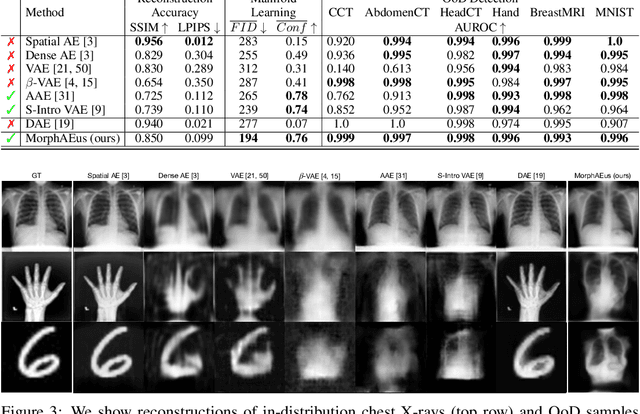
Even though auto-encoders (AEs) have the desirable property of learning compact representations without labels and have been widely applied to out-of-distribution (OoD) detection, they are generally still poorly understood and are used incorrectly in detecting outliers where the normal and abnormal distributions are strongly overlapping. In general, the learned manifold is assumed to contain key information that is only important for describing samples within the training distribution, and that the reconstruction of outliers leads to high residual errors. However, recent work suggests that AEs are likely to be even better at reconstructing some types of OoD samples. In this work, we challenge this assumption and investigate what auto-encoders actually learn when they are posed to solve two different tasks. First, we propose two metrics based on the Fr\'echet inception distance (FID) and confidence scores of a trained classifier to assess whether AEs can learn the training distribution and reliably recognize samples from other domains. Second, we investigate whether AEs are able to synthesize normal images from samples with abnormal regions, on a more challenging lung pathology detection task. We have found that state-of-the-art (SOTA) AEs are either unable to constrain the latent manifold and allow reconstruction of abnormal patterns, or they are failing to accurately restore the inputs from their latent distribution, resulting in blurred or misaligned reconstructions. We propose novel deformable auto-encoders (MorphAEus) to learn perceptually aware global image priors and locally adapt their morphometry based on estimated dense deformation fields. We demonstrate superior performance over unsupervised methods in detecting OoD and pathology.
MaxStyle: Adversarial Style Composition for Robust Medical Image Segmentation
Jun 02, 2022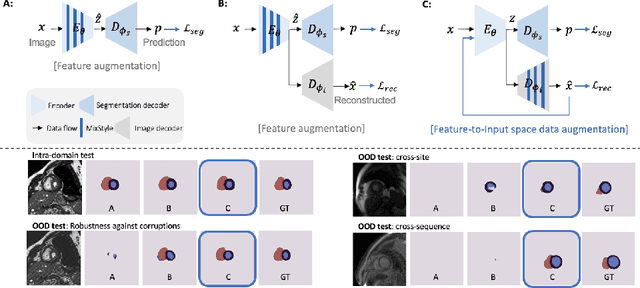

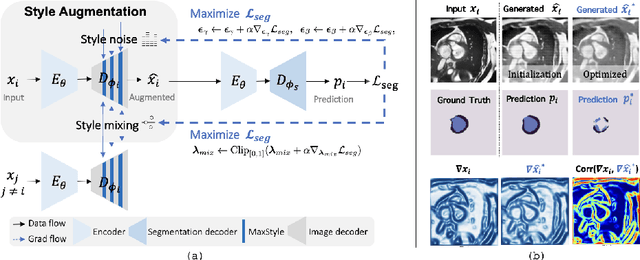
Convolutional neural networks (CNNs) have achieved remarkable segmentation accuracy on benchmark datasets where training and test sets are from the same domain, yet their performance can degrade significantly on unseen domains, which hinders the deployment of CNNs in many clinical scenarios. Most existing works improve model out-of-domain (OOD) robustness by collecting multi-domain datasets for training, which is expensive and may not always be feasible due to privacy and logistical issues. In this work, we focus on improving model robustness using a single-domain dataset only. We propose a novel data augmentation framework called MaxStyle, which maximizes the effectiveness of style augmentation for model OOD performance. It attaches an auxiliary style-augmented image decoder to a segmentation network for robust feature learning and data augmentation. Importantly, MaxStyle augments data with improved image style diversity and hardness, by expanding the style space with noise and searching for the worst-case style composition of latent features via adversarial training. With extensive experiments on multiple public cardiac and prostate MR datasets, we demonstrate that MaxStyle leads to significantly improved out-of-distribution robustness against unseen corruptions as well as common distribution shifts across multiple, different, unseen sites and unknown image sequences under both low- and high-training data settings. The code can be found at https://github.com/cherise215/MaxStyle.
Surface Analysis with Vision Transformers
May 31, 2022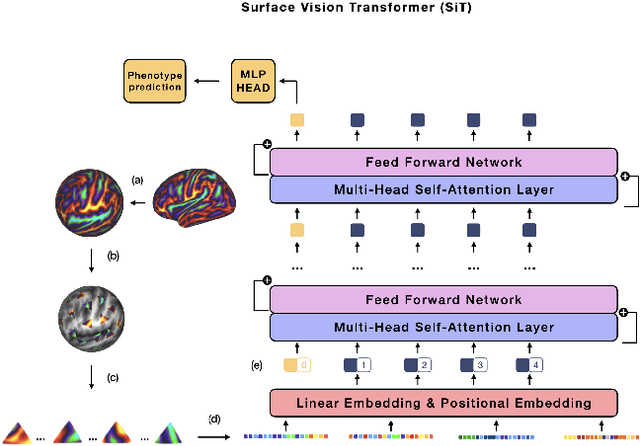

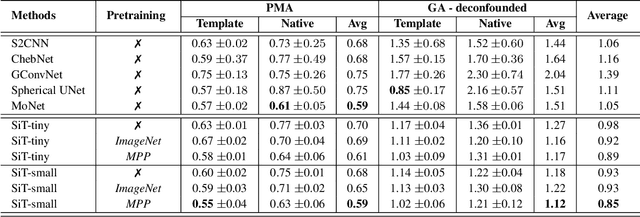
The extension of convolutional neural networks (CNNs) to non-Euclidean geometries has led to multiple frameworks for studying manifolds. Many of those methods have shown design limitations resulting in poor modelling of long-range associations, as the generalisation of convolutions to irregular surfaces is non-trivial. Recent state-of-the-art performance of Vision Transformers (ViTs) demonstrates that a general-purpose architecture, which implements self-attention, could replace the local feature learning operations of CNNs. Motivated by the success of attention-modelling in computer vision, we extend ViTs to surfaces by reformulating the task of surface learning as a sequence-to-sequence problem and propose a patching mechanism for surface meshes. We validate the performance of the proposed Surface Vision Transformer (SiT) on two brain age prediction tasks in the developing Human Connectome Project (dHCP) dataset and investigate the impact of pre-training on model performance. Experiments show that the SiT outperforms many surface CNNs, while indicating some evidence of general transformation invariance. Code available at https://github.com/metrics-lab/surface-vision-transformers
FedNorm: Modality-Based Normalization in Federated Learning for Multi-Modal Liver Segmentation
May 23, 2022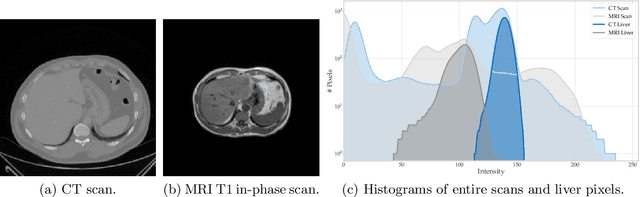

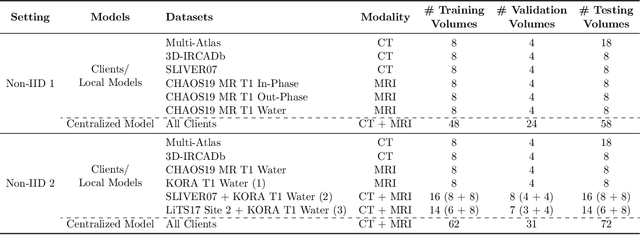
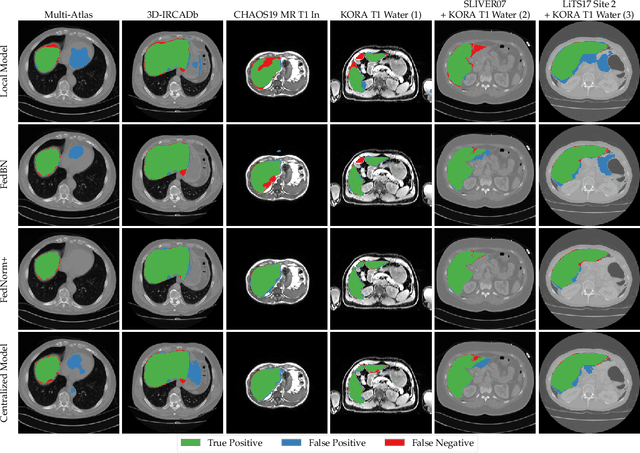
Given the high incidence and effective treatment options for liver diseases, they are of great socioeconomic importance. One of the most common methods for analyzing CT and MRI images for diagnosis and follow-up treatment is liver segmentation. Recent advances in deep learning have demonstrated encouraging results for automatic liver segmentation. Despite this, their success depends primarily on the availability of an annotated database, which is often not available because of privacy concerns. Federated Learning has been recently proposed as a solution to alleviate these challenges by training a shared global model on distributed clients without access to their local databases. Nevertheless, Federated Learning does not perform well when it is trained on a high degree of heterogeneity of image data due to multi-modal imaging, such as CT and MRI, and multiple scanner types. To this end, we propose Fednorm and its extension \fednormp, two Federated Learning algorithms that use a modality-based normalization technique. Specifically, Fednorm normalizes the features on a client-level, while Fednorm+ employs the modality information of single slices in the feature normalization. Our methods were validated using 428 patients from six publicly available databases and compared to state-of-the-art Federated Learning algorithms and baseline models in heterogeneous settings (multi-institutional, multi-modal data). The experimental results demonstrate that our methods show an overall acceptable performance, achieve Dice per patient scores up to 0.961, consistently outperform locally trained models, and are on par or slightly better than centralized models.
Kernel Normalized Convolutional Networks
May 20, 2022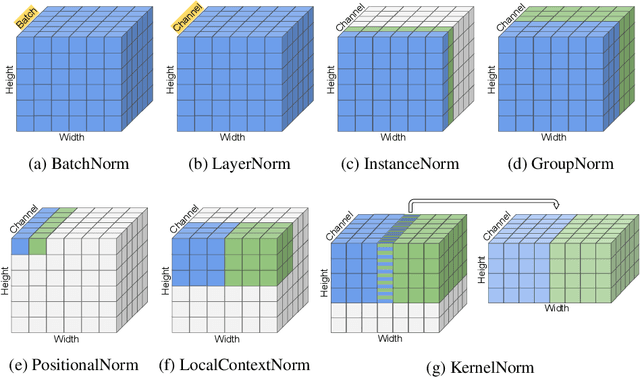
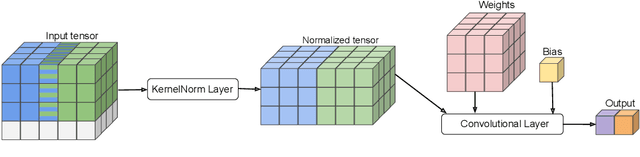

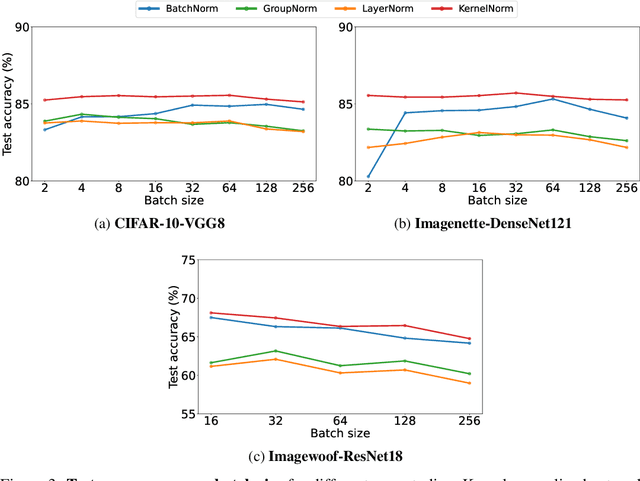
Existing deep convolutional neural network (CNN) architectures frequently rely upon batch normalization (BatchNorm) to effectively train the model. BatchNorm significantly improves model performance, but performs poorly with smaller batch sizes. To address this limitation, we propose kernel normalization and kernel normalized convolutional layers, and incorporate them into kernel normalized convolutional networks (KNConvNets) as the main building blocks. We implement KNConvNets corresponding to the state-of-the-art CNNs such as ResNet and DenseNet while forgoing BatchNorm layers. Through extensive experiments, we illustrate that KNConvNets consistently outperform their batch, group, and layer normalized counterparts in terms of both accuracy and convergence rate while maintaining competitive computational efficiency.
CAS-Net: Conditional Atlas Generation and Brain Segmentation for Fetal MRI
May 17, 2022Fetal Magnetic Resonance Imaging (MRI) is used in prenatal diagnosis and to assess early brain development. Accurate segmentation of the different brain tissues is a vital step in several brain analysis tasks, such as cortical surface reconstruction and tissue thickness measurements. Fetal MRI scans, however, are prone to motion artifacts that can affect the correctness of both manual and automatic segmentation techniques. In this paper, we propose a novel network structure that can simultaneously generate conditional atlases and predict brain tissue segmentation, called CAS-Net. The conditional atlases provide anatomical priors that can constrain the segmentation connectivity, despite the heterogeneity of intensity values caused by motion or partial volume effects. The proposed method is trained and evaluated on 253 subjects from the developing Human Connectome Project (dHCP). The results demonstrate that the proposed method can generate conditional age-specific atlas with sharp boundary and shape variance. It also segment multi-category brain tissues for fetal MRI with a high overall Dice similarity coefficient (DSC) of $85.2\%$ for the selected 9 tissue labels.
SmoothNets: Optimizing CNN architecture design for differentially private deep learning
May 09, 2022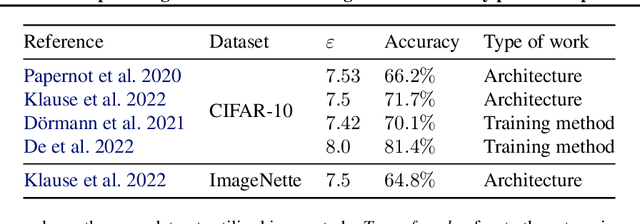
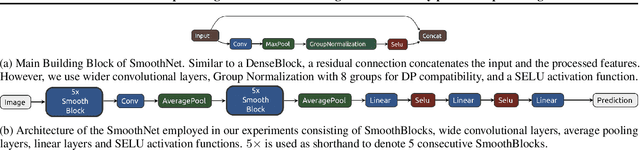
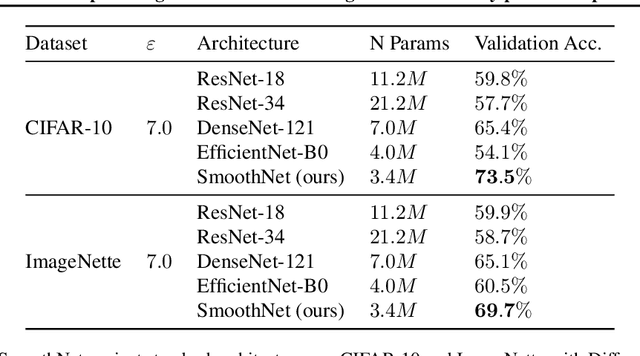
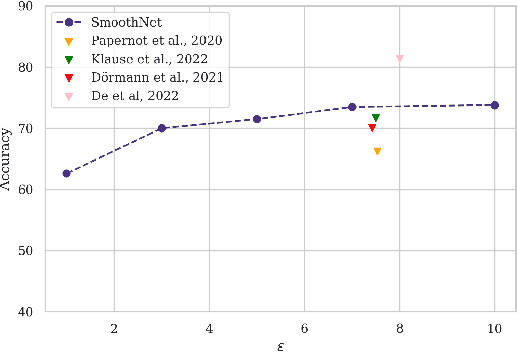
The arguably most widely employed algorithm to train deep neural networks with Differential Privacy is DPSGD, which requires clipping and noising of per-sample gradients. This introduces a reduction in model utility compared to non-private training. Empirically, it can be observed that this accuracy degradation is strongly dependent on the model architecture. We investigated this phenomenon and, by combining components which exhibit good individual performance, distilled a new model architecture termed SmoothNet, which is characterised by increased robustness to the challenges of DP-SGD training. Experimentally, we benchmark SmoothNet against standard architectures on two benchmark datasets and observe that our architecture outperforms others, reaching an accuracy of 73.5\% on CIFAR-10 at $\varepsilon=7.0$ and 69.2\% at $\varepsilon=7.0$ on ImageNette, a state-of-the-art result compared to prior architectural modifications for DP.