 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFederated Evaluation of On-device Personalization
Oct 22, 2019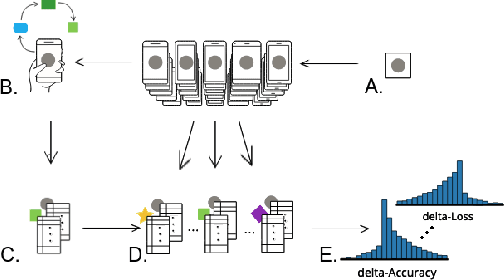
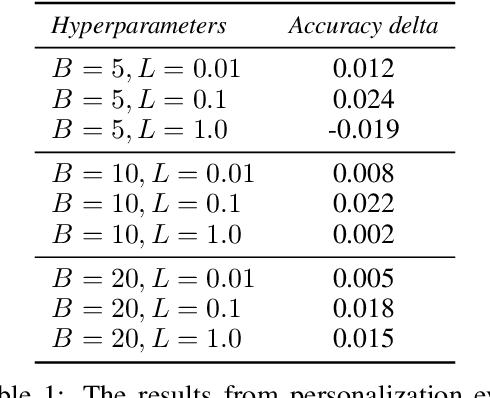
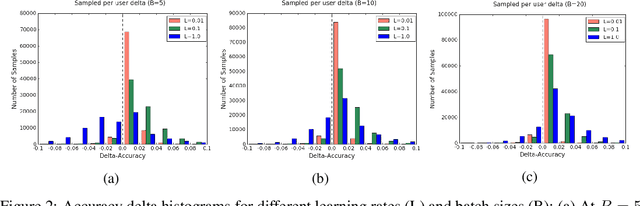
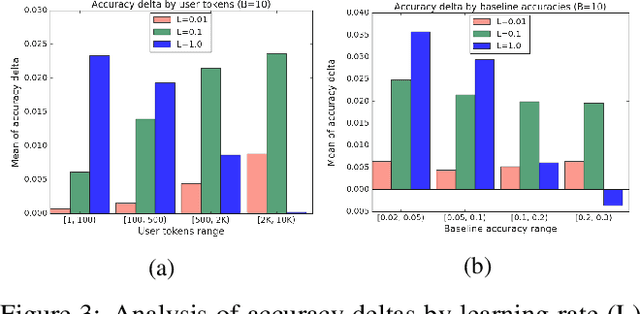
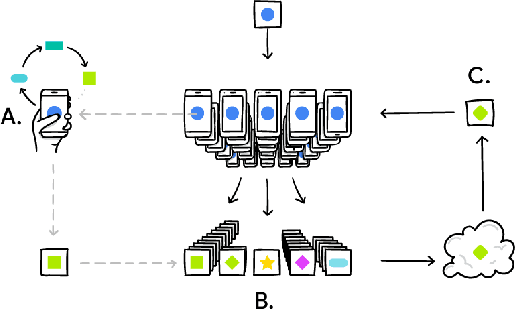
Federated learning is a distributed, on-device computation framework that enables training global models without exporting sensitive user data to servers. In this work, we describe methods to extend the federation framework to evaluate strategies for personalization of global models. We present tools to analyze the effects of personalization and evaluate conditions under which personalization yields desirable models. We report on our experiments personalizing a language model for a virtual keyboard for smartphones with a population of tens of millions of users. We show that a significant fraction of users benefit from personalization.
Towards Federated Learning at Scale: System Design
Mar 22, 2019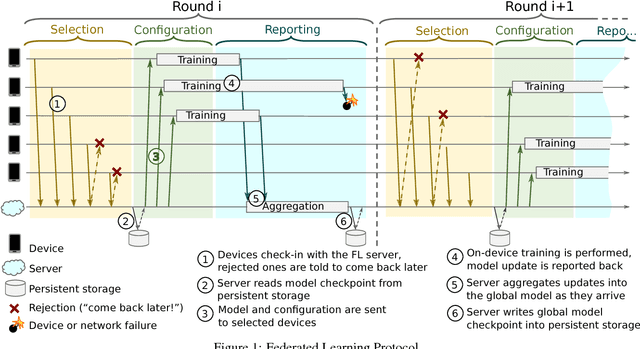
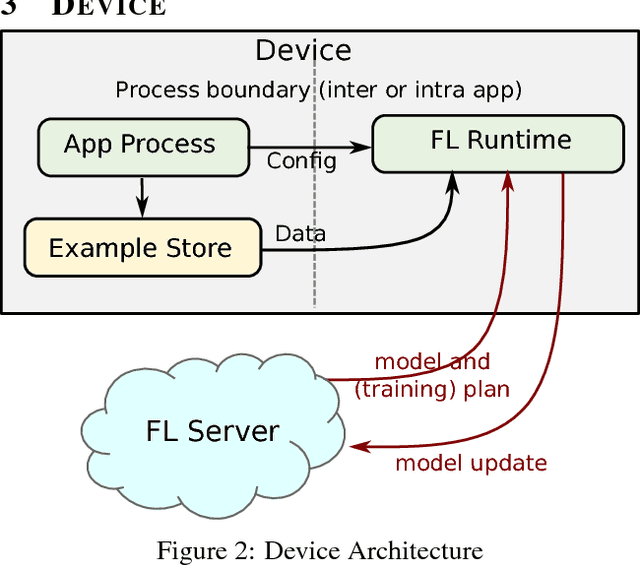
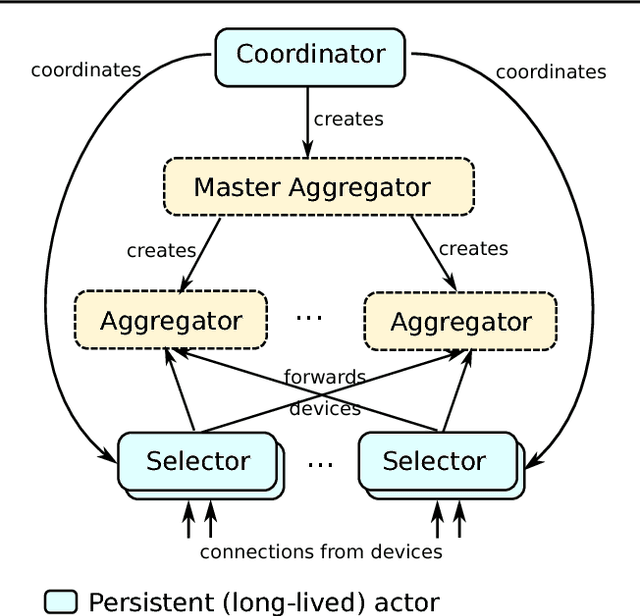
Federated Learning is a distributed machine learning approach which enables model training on a large corpus of decentralized data. We have built a scalable production system for Federated Learning in the domain of mobile devices, based on TensorFlow. In this paper, we describe the resulting high-level design, sketch some of the challenges and their solutions, and touch upon the open problems and future directions.
Applied Federated Learning: Improving Google Keyboard Query Suggestions
Dec 07, 2018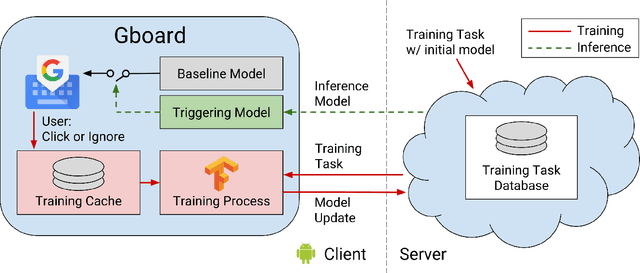

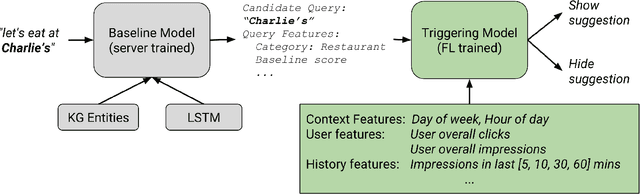

Federated learning is a distributed form of machine learning where both the training data and model training are decentralized. In this paper, we use federated learning in a commercial, global-scale setting to train, evaluate and deploy a model to improve virtual keyboard search suggestion quality without direct access to the underlying user data. We describe our observations in federated training, compare metrics to live deployments, and present resulting quality increases. In whole, we demonstrate how federated learning can be applied end-to-end to both improve user experiences and enhance user privacy.
Federated Learning for Mobile Keyboard Prediction
Nov 08, 2018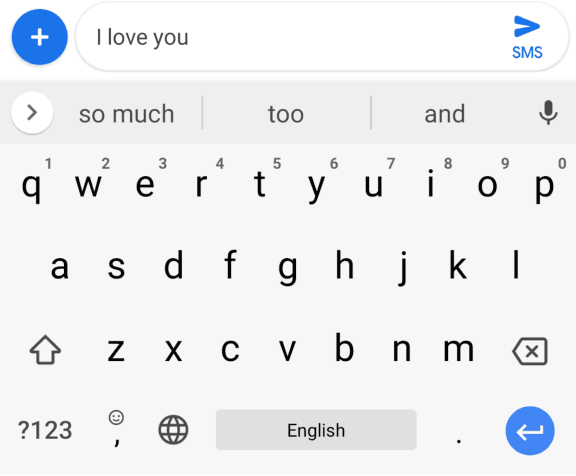


We train a recurrent neural network language model using a distributed, on-device learning framework called federated learning for the purpose of next-word prediction in a virtual keyboard for smartphones. Server-based training using stochastic gradient descent is compared with training on client devices using the Federated Averaging algorithm. The federated algorithm, which enables training on a higher-quality dataset for this use case, is shown to achieve better prediction recall. This work demonstrates the feasibility and benefit of training language models on client devices without exporting sensitive user data to servers. The federated learning environment gives users greater control over their data and simplifies the task of incorporating privacy by default with distributed training and aggregation across a population of client devices.
Learning Differentially Private Recurrent Language Models
Feb 24, 2018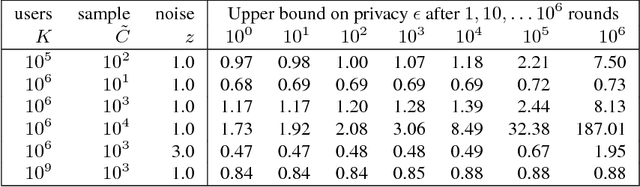
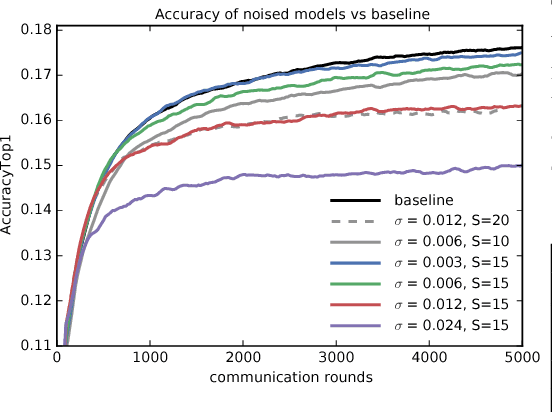
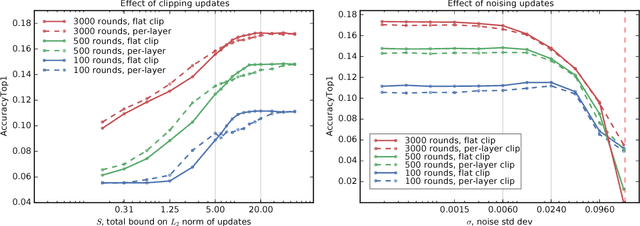
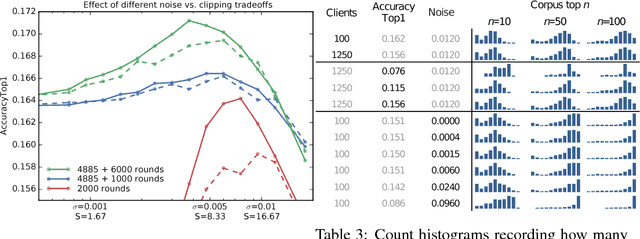
We demonstrate that it is possible to train large recurrent language models with user-level differential privacy guarantees with only a negligible cost in predictive accuracy. Our work builds on recent advances in the training of deep networks on user-partitioned data and privacy accounting for stochastic gradient descent. In particular, we add user-level privacy protection to the federated averaging algorithm, which makes "large step" updates from user-level data. Our work demonstrates that given a dataset with a sufficiently large number of users (a requirement easily met by even small internet-scale datasets), achieving differential privacy comes at the cost of increased computation, rather than in decreased utility as in most prior work. We find that our private LSTM language models are quantitatively and qualitatively similar to un-noised models when trained on a large dataset.
Communication-Efficient Learning of Deep Networks from Decentralized Data
Feb 28, 2017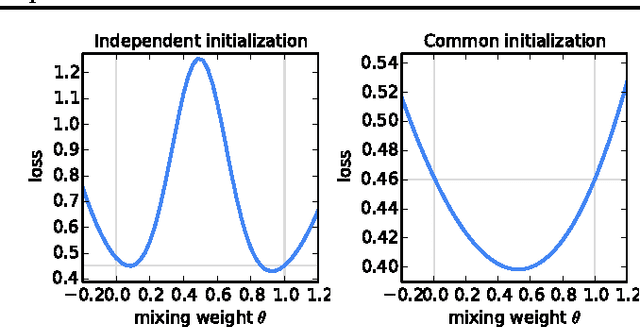

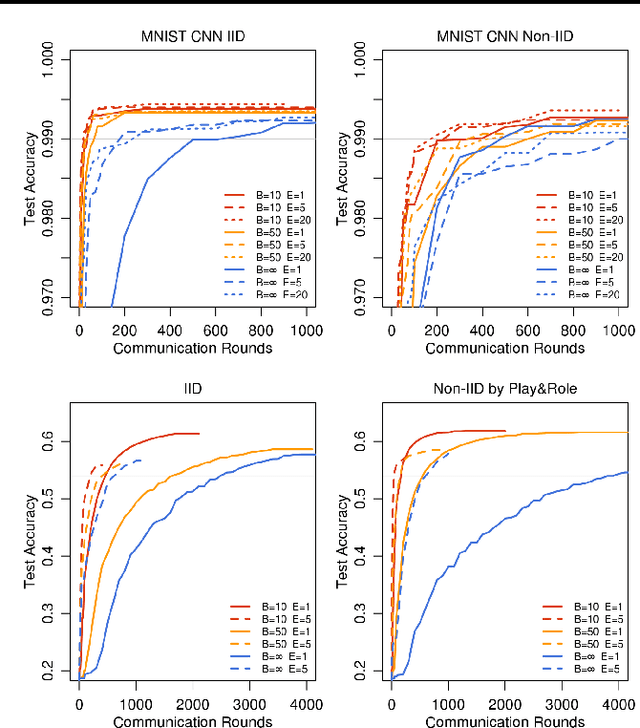
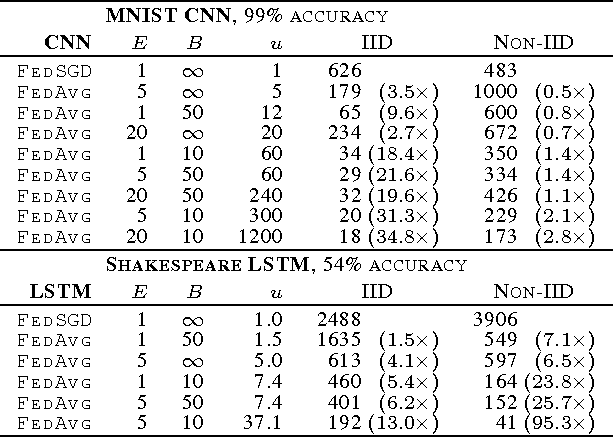
Modern mobile devices have access to a wealth of data suitable for learning models, which in turn can greatly improve the user experience on the device. For example, language models can improve speech recognition and text entry, and image models can automatically select good photos. However, this rich data is often privacy sensitive, large in quantity, or both, which may preclude logging to the data center and training there using conventional approaches. We advocate an alternative that leaves the training data distributed on the mobile devices, and learns a shared model by aggregating locally-computed updates. We term this decentralized approach Federated Learning. We present a practical method for the federated learning of deep networks based on iterative model averaging, and conduct an extensive empirical evaluation, considering five different model architectures and four datasets. These experiments demonstrate the approach is robust to the unbalanced and non-IID data distributions that are a defining characteristic of this setting. Communication costs are the principal constraint, and we show a reduction in required communication rounds by 10-100x as compared to synchronized stochastic gradient descent.
* This version updates the large-scale LSTM experiments, along with other minor changes. In earlier versions, an inconsistency in our implementation of FedSGD caused us to report much lower learning rates for the large-scale LSTM. We reran these experiments, and also found that fewer local epochs offers better performance, leading to slightly better results for FedAvg than previously reported
Practical Secure Aggregation for Federated Learning on User-Held Data
Nov 14, 2016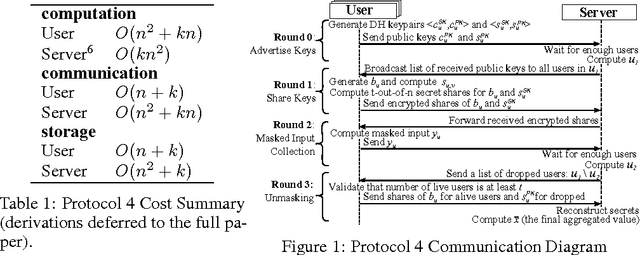
Secure Aggregation protocols allow a collection of mutually distrust parties, each holding a private value, to collaboratively compute the sum of those values without revealing the values themselves. We consider training a deep neural network in the Federated Learning model, using distributed stochastic gradient descent across user-held training data on mobile devices, wherein Secure Aggregation protects each user's model gradient. We design a novel, communication-efficient Secure Aggregation protocol for high-dimensional data that tolerates up to 1/3 users failing to complete the protocol. For 16-bit input values, our protocol offers 1.73x communication expansion for $2^{10}$ users and $2^{20}$-dimensional vectors, and 1.98x expansion for $2^{14}$ users and $2^{24}$ dimensional vectors.
Federated Optimization: Distributed Machine Learning for On-Device Intelligence
Oct 08, 2016
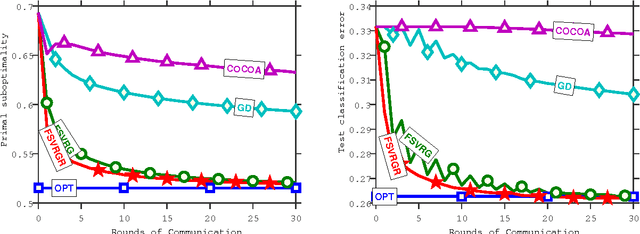

We introduce a new and increasingly relevant setting for distributed optimization in machine learning, where the data defining the optimization are unevenly distributed over an extremely large number of nodes. The goal is to train a high-quality centralized model. We refer to this setting as Federated Optimization. In this setting, communication efficiency is of the utmost importance and minimizing the number of rounds of communication is the principal goal. A motivating example arises when we keep the training data locally on users' mobile devices instead of logging it to a data center for training. In federated optimziation, the devices are used as compute nodes performing computation on their local data in order to update a global model. We suppose that we have extremely large number of devices in the network --- as many as the number of users of a given service, each of which has only a tiny fraction of the total data available. In particular, we expect the number of data points available locally to be much smaller than the number of devices. Additionally, since different users generate data with different patterns, it is reasonable to assume that no device has a representative sample of the overall distribution. We show that existing algorithms are not suitable for this setting, and propose a new algorithm which shows encouraging experimental results for sparse convex problems. This work also sets a path for future research needed in the context of \federated optimization.
Discrete Distribution Estimation under Local Privacy
Jun 15, 2016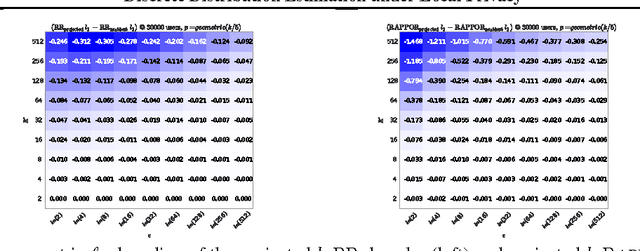
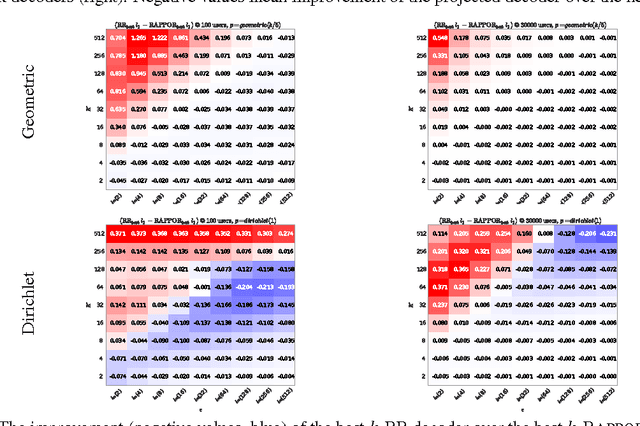
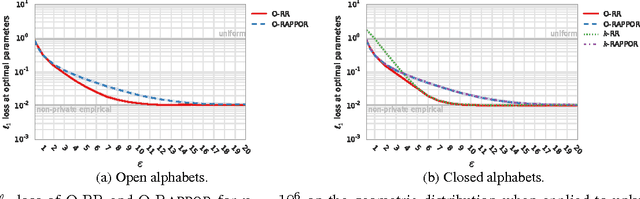
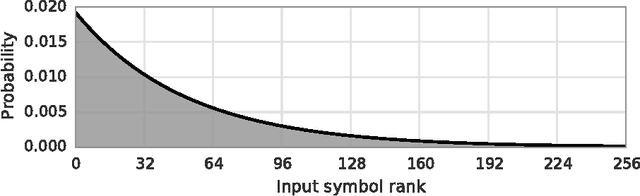
The collection and analysis of user data drives improvements in the app and web ecosystems, but comes with risks to privacy. This paper examines discrete distribution estimation under local privacy, a setting wherein service providers can learn the distribution of a categorical statistic of interest without collecting the underlying data. We present new mechanisms, including hashed K-ary Randomized Response (KRR), that empirically meet or exceed the utility of existing mechanisms at all privacy levels. New theoretical results demonstrate the order-optimality of KRR and the existing RAPPOR mechanism at different privacy regimes.
Federated Optimization:Distributed Optimization Beyond the Datacenter
Nov 11, 2015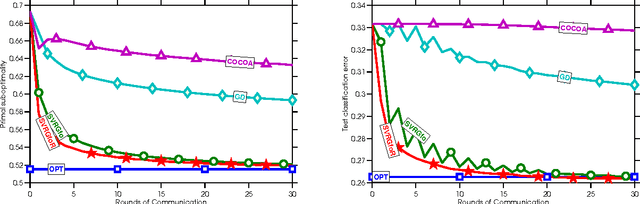
We introduce a new and increasingly relevant setting for distributed optimization in machine learning, where the data defining the optimization are distributed (unevenly) over an extremely large number of \nodes, but the goal remains to train a high-quality centralized model. We refer to this setting as Federated Optimization. In this setting, communication efficiency is of utmost importance. A motivating example for federated optimization arises when we keep the training data locally on users' mobile devices rather than logging it to a data center for training. Instead, the mobile devices are used as nodes performing computation on their local data in order to update a global model. We suppose that we have an extremely large number of devices in our network, each of which has only a tiny fraction of data available totally; in particular, we expect the number of data points available locally to be much smaller than the number of devices. Additionally, since different users generate data with different patterns, we assume that no device has a representative sample of the overall distribution. We show that existing algorithms are not suitable for this setting, and propose a new algorithm which shows encouraging experimental results. This work also sets a path for future research needed in the context of federated optimization.