 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJudge Reliability Harness: Stress Testing the Reliability of LLM Judges
Mar 05, 2026We present the Judge Reliability Harness, an open source library for constructing validation suites that test the reliability of LLM judges. As LLM based scoring is widely deployed in AI benchmarks, more tooling is needed to efficiently assess the reliability of these methods. Given a benchmark dataset and an LLM judge configuration, the harness generates reliability tests that evaluate both binary judgment accuracy and ordinal grading performance for free-response and agentic task formats. We evaluate four state-of-the-art judges across four benchmarks spanning safety, persuasion, misuse, and agentic behavior, and find meaningful variation in performance across models and perturbation types, highlighting opportunities to improve the robustness of LLM judges. No judge that we evaluated is uniformly reliable across benchmarks using our harness. For example, our preliminary experiments on judges revealed consistency issues as measured by accuracy in judging another LLM's ability to complete a task due to simple text formatting changes, paraphrasing, changes in verbosity, and flipping the ground truth label in LLM-produced responses. The code for this tool is available at: https://github.com/RANDCorporation/judge-reliability-harness
Applied Federated Learning: Improving Google Keyboard Query Suggestions
Dec 07, 2018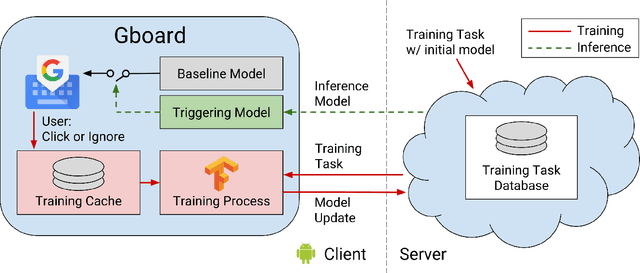

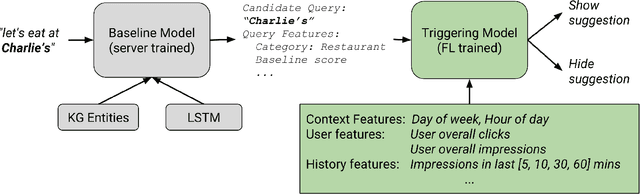

Federated learning is a distributed form of machine learning where both the training data and model training are decentralized. In this paper, we use federated learning in a commercial, global-scale setting to train, evaluate and deploy a model to improve virtual keyboard search suggestion quality without direct access to the underlying user data. We describe our observations in federated training, compare metrics to live deployments, and present resulting quality increases. In whole, we demonstrate how federated learning can be applied end-to-end to both improve user experiences and enhance user privacy.