 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMHPR: Multidimensional Human Perception and Reasoning Benchmark for Large Vision-Languate Models
May 05, 2026Multidimensional human understanding is essential for real-world applications such as film analysis and virtual digital humans, yet current LVLM benchmarks largely focus on single-task settings and lack fine-grained, human-centric evaluation. In this work, we introduce MHPR, a comprehensive benchmark for joint perception-reasoning over human-centric scenes spanning individual, multi-person, and human-object interaction dimensions. MHPR comprises a multi-level data design-Captioned Raw Data (C-RD), Supervised Fine-Tuning Data (SFT-D), Reinforcement Learning Data (RL-D), and Test Data (T-D)-together with an automated caption/VQA generation pipeline (ACVG) that performs category-wise attribute decomposition, attribute-specific rewriting, and multi-model voting to ensure high-quality, scalable annotations. We evaluate state-of-the-art vision-language models on fine-grained attributes (appearance, clothing, pose, parts) and high-level semantics (social relations, action semantics, spatial relations, intent and functionality). Our findings show that: 1) format-aligned SFT data substantially improves instruction following and stability; 2) challenge-focused RL data derived from bad-case analysis further enhances perception and reasoning on difficult instances; and 3) training Qwen2.5-VL-7B with MHPR yields significant gains, achieving near-parity with considerably larger models. We release ACVG and MHPR to facilitate reproducible, extensible research on human-centric perception and reasoning.
Lipschitz Regularized CycleGAN for Improving Semantic Robustness in Unpaired Image-to-image Translation
Dec 09, 2020
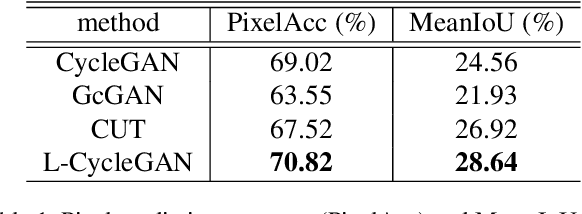

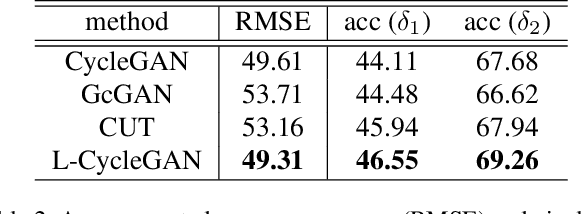
For unpaired image-to-image translation tasks, GAN-based approaches are susceptible to semantic flipping, i.e., contents are not preserved consistently. We argue that this is due to (1) the difference in semantic statistics between source and target domains and (2) the learned generators being non-robust. In this paper, we proposed a novel approach, Lipschitz regularized CycleGAN, for improving semantic robustness and thus alleviating the semantic flipping issue. During training, we add a gradient penalty loss to the generators, which encourages semantically consistent transformations. We evaluate our approach on multiple common datasets and compare with several existing GAN-based methods. Both quantitative and visual results suggest the effectiveness and advantage of our approach in producing robust transformations with fewer semantic flipping.
Federated Evaluation of On-device Personalization
Oct 22, 2019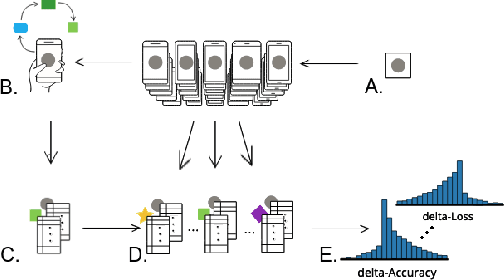
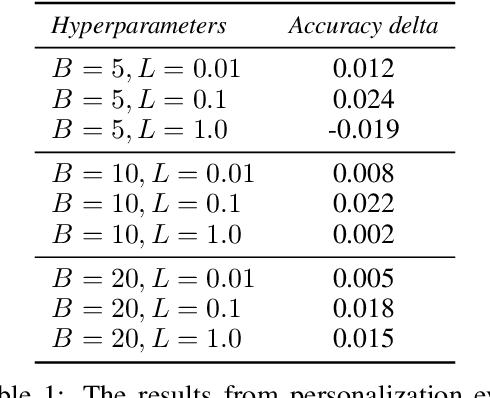
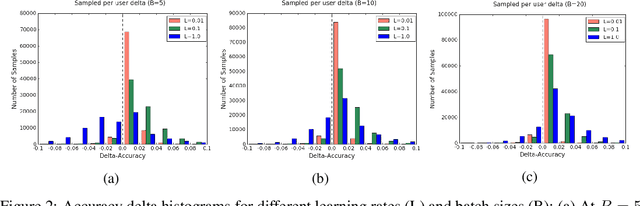
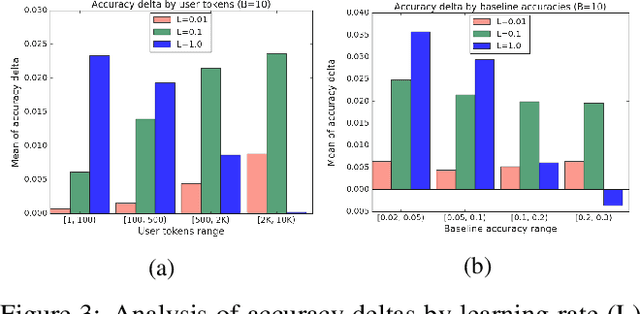
Federated learning is a distributed, on-device computation framework that enables training global models without exporting sensitive user data to servers. In this work, we describe methods to extend the federation framework to evaluate strategies for personalization of global models. We present tools to analyze the effects of personalization and evaluate conditions under which personalization yields desirable models. We report on our experiments personalizing a language model for a virtual keyboard for smartphones with a population of tens of millions of users. We show that a significant fraction of users benefit from personalization.