 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGrasp success prediction with quality metrics
Sep 10, 2018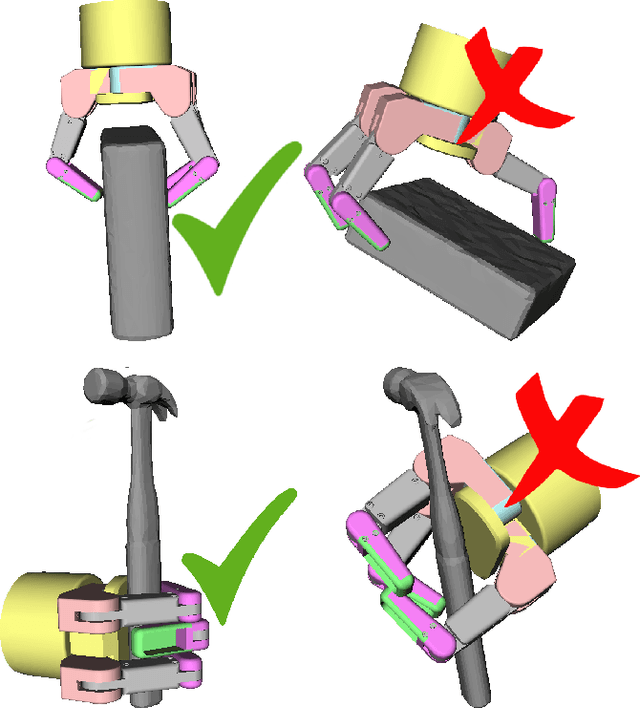
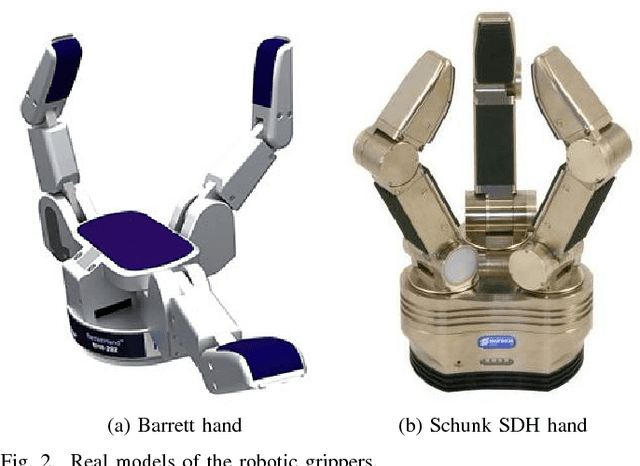


Current robotic manipulation requires reliable methods to predict whether a certain grasp on an object will be successful or not prior to its execution. Different methods and metrics have been developed for this purpose but there is still work to do to provide a robust solution. In this article we combine different metrics to evaluate real grasp executions. We use different machine learning algorithms to train a classifier able to predict the success of candidate grasps. Our experiments are performed with two different robotic grippers and different objects. Grasp candidates are evaluated in both simulation and real world. We consider 3 different categories to label grasp executions: robust, fragile and futile. Our results shows the proposed prediction model has success rate of 76\%.
Riemannian Motion Policies
Jul 25, 2018

We introduce the Riemannian Motion Policy (RMP), a new mathematical object for modular motion generation. An RMP is a second-order dynamical system (acceleration field or motion policy) coupled with a corresponding Riemannian metric. The motion policy maps positions and velocities to accelerations, while the metric captures the directions in the space important to the policy. We show that RMPs provide a straightforward and convenient method for combining multiple motion policies and transforming such policies from one space (such as the task space) to another (such as the configuration space) in geometrically consistent ways. The operators we derive for these combinations and transformations are provably optimal, have linearity properties making them agnostic to the order of application, and are strongly analogous to the covariant transformations of natural gradients popular in the machine learning literature. The RMP framework enables the fusion of motion policies from different motion generation paradigms, such as dynamical systems, dynamic movement primitives (DMPs), optimal control, operational space control, nonlinear reactive controllers, motion optimization, and model predictive control (MPC), thus unifying these disparate techniques from the literature. RMPs are easy to implement and manipulate, facilitate controller design, simplify handling of joint limits, and clarify a number of open questions regarding the proper fusion of motion generation methods (such as incorporating local reactive policies into long-horizon optimizers). We demonstrate the effectiveness of RMPs on both simulation and real robots, including their ability to naturally and efficiently solve complicated collision avoidance problems previously handled by more complex planners.
Online Learning of a Memory for Learning Rates
Mar 23, 2018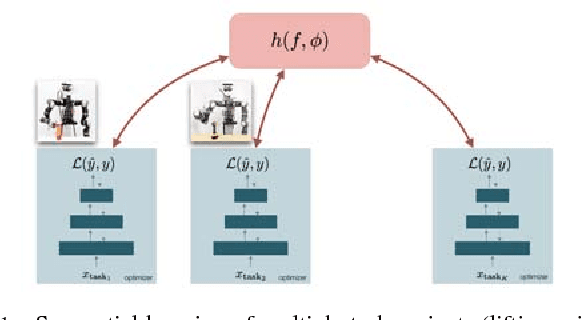
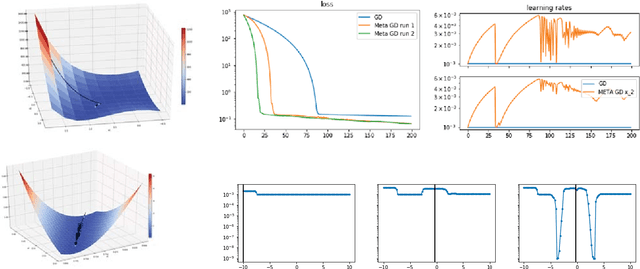

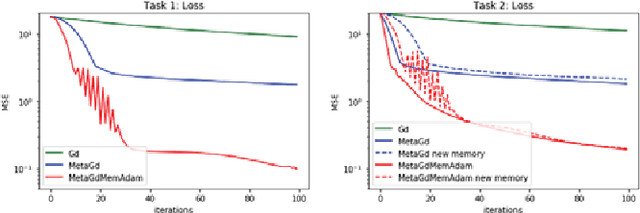
The promise of learning to learn for robotics rests on the hope that by extracting some information about the learning process itself we can speed up subsequent similar learning tasks. Here, we introduce a computationally efficient online meta-learning algorithm that builds and optimizes a memory model of the optimal learning rate landscape from previously observed gradient behaviors. While performing task specific optimization, this memory of learning rates predicts how to scale currently observed gradients. After applying the gradient scaling our meta-learner updates its internal memory based on the observed effect its prediction had. Our meta-learner can be combined with any gradient-based optimizer, learns on the fly and can be transferred to new optimization tasks. In our evaluations we show that our meta-learning algorithm speeds up learning of MNIST classification and a variety of learning control tasks, either in batch or online learning settings.
A New Data Source for Inverse Dynamics Learning
Oct 06, 2017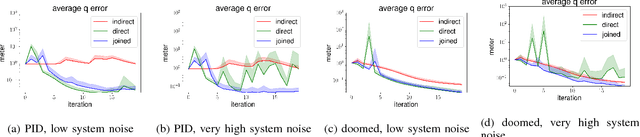
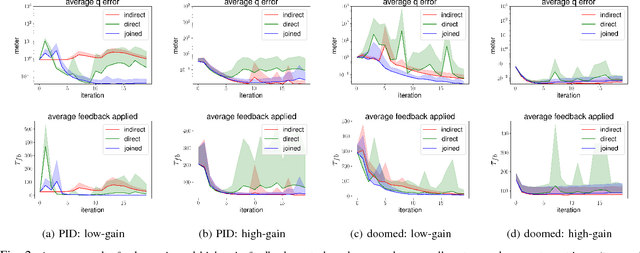

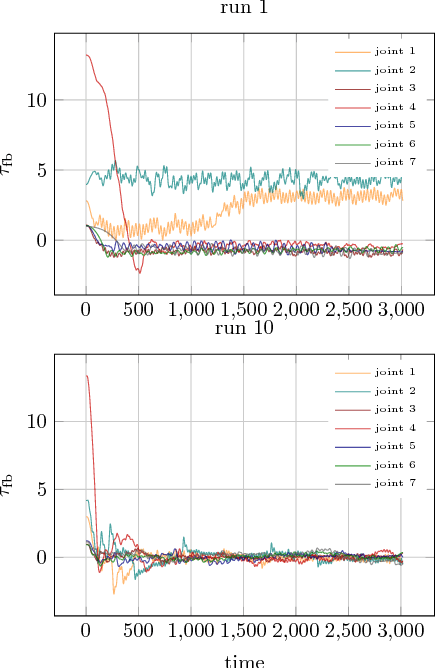
Modern robotics is gravitating toward increasingly collaborative human robot interaction. Tools such as acceleration policies can naturally support the realization of reactive, adaptive, and compliant robots. These tools require us to model the system dynamics accurately -- a difficult task. The fundamental problem remains that simulation and reality diverge--we do not know how to accurately change a robot's state. Thus, recent research on improving inverse dynamics models has been focused on making use of machine learning techniques. Traditional learning techniques train on the actual realized accelerations, instead of the policy's desired accelerations, which is an indirect data source. Here we show how an additional training signal -- measured at the desired accelerations -- can be derived from a feedback control signal. This effectively creates a second data source for learning inverse dynamics models. Furthermore, we show how both the traditional and this new data source, can be used to train task-specific models of the inverse dynamics, when used independently or combined. We analyze the use of both data sources in simulation and demonstrate its effectiveness on a real-world robotic platform. We show that our system incrementally improves the learned inverse dynamics model, and when using both data sources combined converges more consistently and faster.
Real-time Perception meets Reactive Motion Generation
Oct 06, 2017



We address the challenging problem of robotic grasping and manipulation in the presence of uncertainty. This uncertainty is due to noisy sensing, inaccurate models and hard-to-predict environment dynamics. We quantify the importance of continuous, real-time perception and its tight integration with reactive motion generation methods in dynamic manipulation scenarios. We compare three different systems that are instantiations of the most common architectures in the field: (i) a traditional sense-plan-act approach that is still widely used, (ii) a myopic controller that only reacts to local environment dynamics and (iii) a reactive planner that integrates feedback control and motion optimization. All architectures rely on the same components for real-time perception and reactive motion generation to allow a quantitative evaluation. We extensively evaluate the systems on a real robotic platform in four scenarios that exhibit either a challenging workspace geometry or a dynamic environment. In 333 experiments, we quantify the robustness and accuracy that is due to integrating real-time feedback at different time scales in a reactive motion generation system. We also report on the lessons learned for system building.
DOOMED: Direct Online Optimization of Modeling Errors in Dynamics
Aug 09, 2016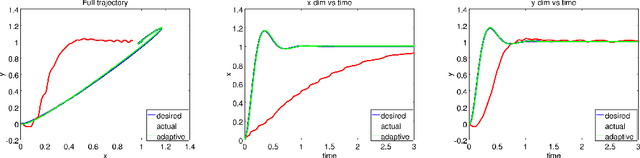
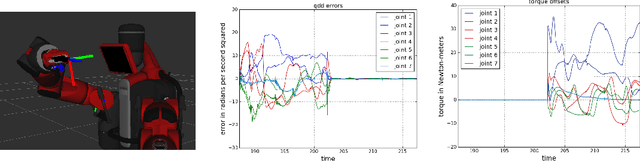

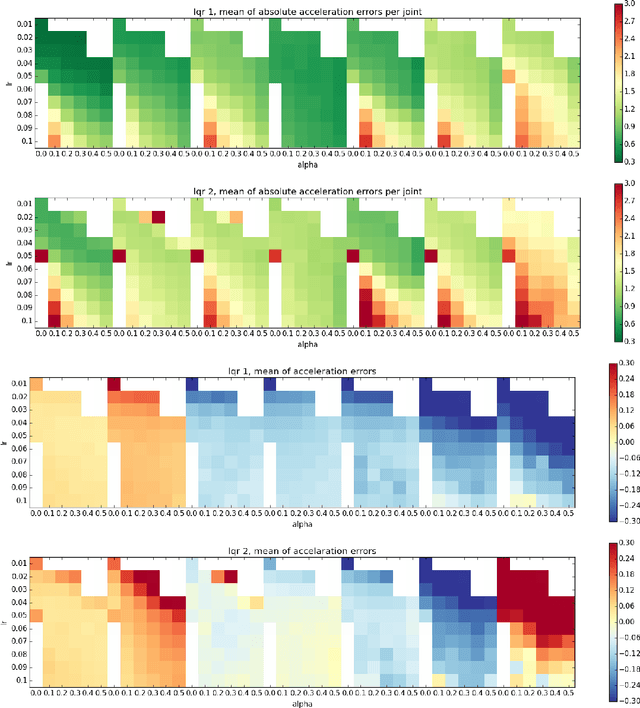
It has long been hoped that model-based control will improve tracking performance while maintaining or increasing compliance. This hope hinges on having or being able to estimate an accurate inverse dynamics model. As a result, substantial effort has gone into modeling and estimating dynamics (error) models. Most recent research has focused on learning the true inverse dynamics using data points mapping observed accelerations to the torques used to generate them. Unfortunately, if the initial tracking error is bad, such learning processes may train substantially off-distribution to predict well on actual observed acceleration rather then the desired accelerations. This work takes a different approach. We define a class of gradient-based online learning algorithms we term Direct Online Optimization for Modeling Errors in Dynamics (DOOMED) that directly minimize an objective measuring the divergence between actual and desired accelerations. Our objective is defined in terms of the true system's unknown dynamics and is therefore impossible to evaluate. However, we show that its gradient is measurable online from system data. We develop a novel adaptive control approach based on running online learning to directly correct (inverse) dynamics errors in real time using the data stream from the robot to accurately achieve desired accelerations during execution.
Superpixel Convolutional Networks using Bilateral Inceptions
Aug 08, 2016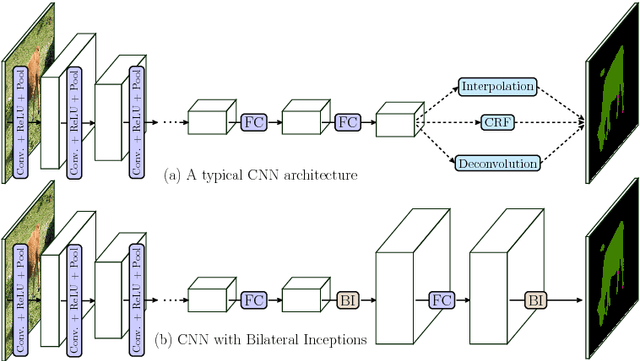
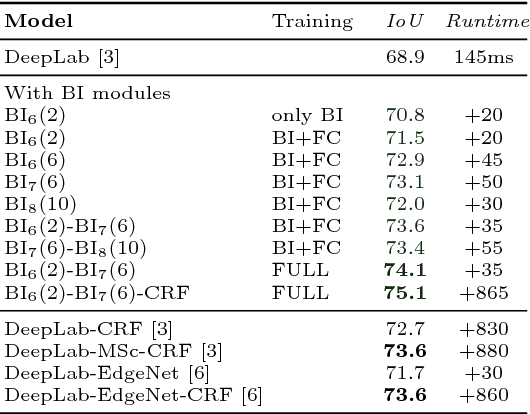
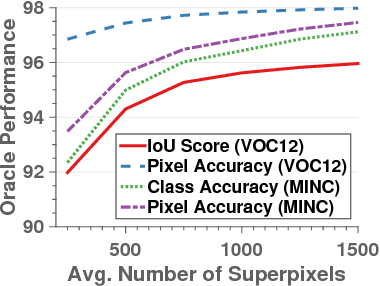

In this paper we propose a CNN architecture for semantic image segmentation. We introduce a new 'bilateral inception' module that can be inserted in existing CNN architectures and performs bilateral filtering, at multiple feature-scales, between superpixels in an image. The feature spaces for bilateral filtering and other parameters of the module are learned end-to-end using standard backpropagation techniques. The bilateral inception module addresses two issues that arise with general CNN segmentation architectures. First, this module propagates information between (super) pixels while respecting image edges, thus using the structured information of the problem for improved results. Second, the layer recovers a full resolution segmentation result from the lower resolution solution of a CNN. In the experiments, we modify several existing CNN architectures by inserting our inception module between the last CNN (1x1 convolution) layers. Empirical results on three different datasets show reliable improvements not only in comparison to the baseline networks, but also in comparison to several dense-pixel prediction techniques such as CRFs, while being competitive in time.
A New Perspective and Extension of the Gaussian Filter
Jun 05, 2015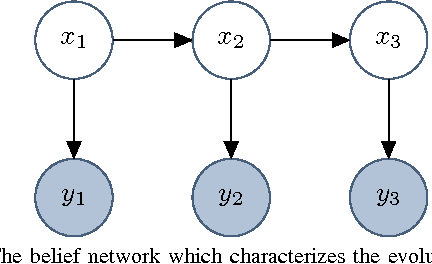
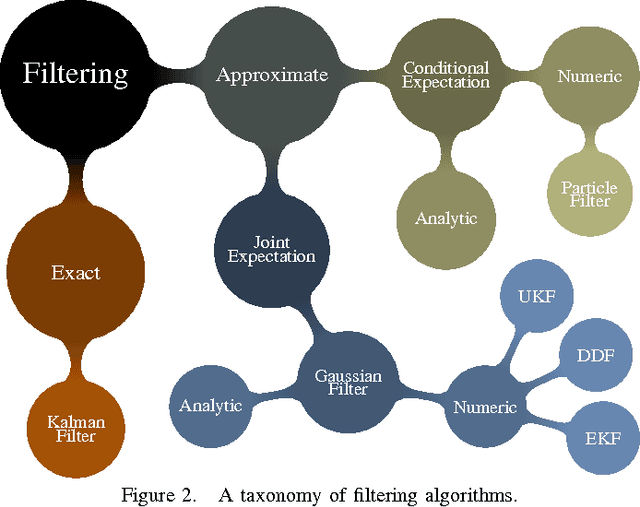
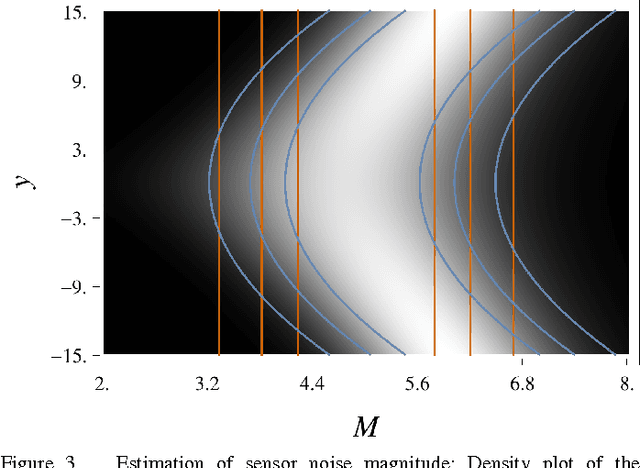
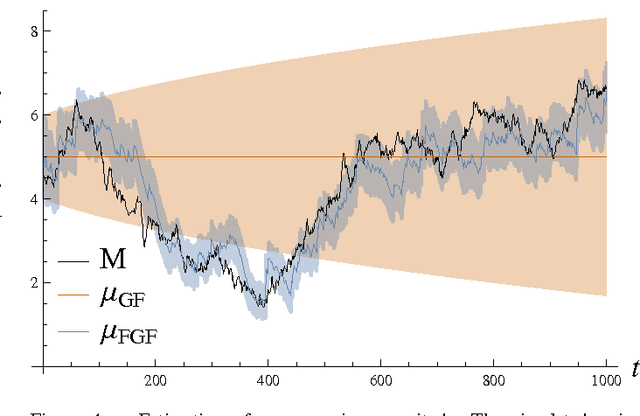
The Gaussian Filter (GF) is one of the most widely used filtering algorithms; instances are the Extended Kalman Filter, the Unscented Kalman Filter and the Divided Difference Filter. GFs represent the belief of the current state by a Gaussian with the mean being an affine function of the measurement. We show that this representation can be too restrictive to accurately capture the dependences in systems with nonlinear observation models, and we investigate how the GF can be generalized to alleviate this problem. To this end, we view the GF from a variational-inference perspective. We analyse how restrictions on the form of the belief can be relaxed while maintaining simplicity and efficiency. This analysis provides a basis for generalizations of the GF. We propose one such generalization which coincides with a GF using a virtual measurement, obtained by applying a nonlinear function to the actual measurement. Numerical experiments show that the proposed Feature Gaussian Filter (FGF) can have a substantial performance advantage over the standard GF for systems with nonlinear observation models.
The Coordinate Particle Filter - A novel Particle Filter for High Dimensional Systems
May 01, 2015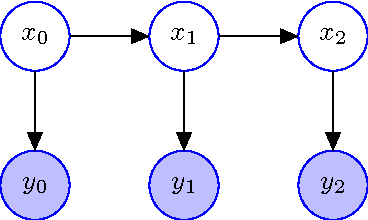
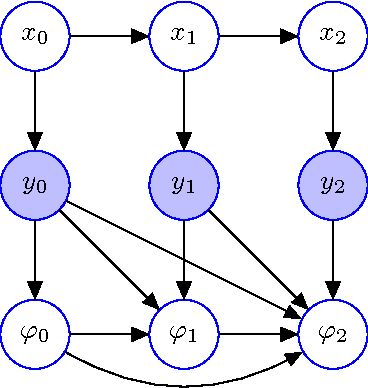
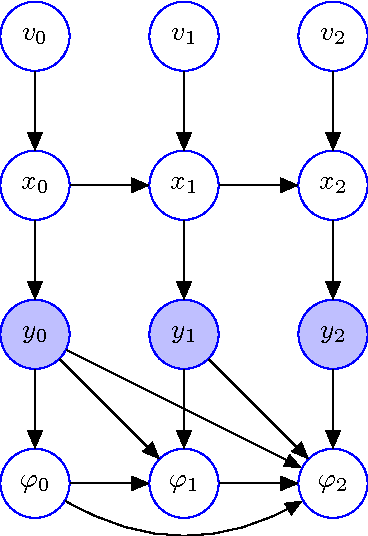
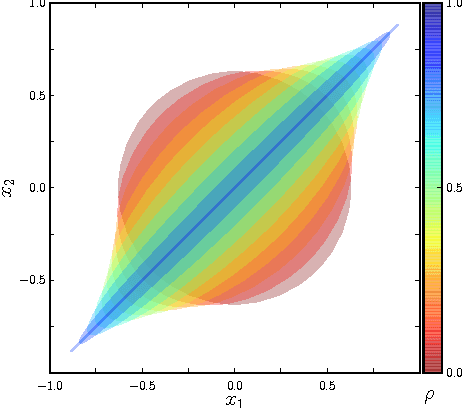
Parametric filters, such as the Extended Kalman Filter and the Unscented Kalman Filter, typically scale well with the dimensionality of the problem, but they are known to fail if the posterior state distribution cannot be closely approximated by a density of the assumed parametric form. For nonparametric filters, such as the Particle Filter, the converse holds. Such methods are able to approximate any posterior, but the computational requirements scale exponentially with the number of dimensions of the state space. In this paper, we present the Coordinate Particle Filter which alleviates this problem. We propose to compute the particle weights recursively, dimension by dimension. This allows us to explore one dimension at a time, and resample after each dimension if necessary. Experimental results on simulated as well as real data confirm that the proposed method has a substantial performance advantage over the Particle Filter in high-dimensional systems where not all dimensions are highly correlated. We demonstrate the benefits of the proposed method for the problem of multi-object and robotic manipulator tracking.