 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRobust Reinforcement Learning for Continuous Control with Model Misspecification
Jun 18, 2019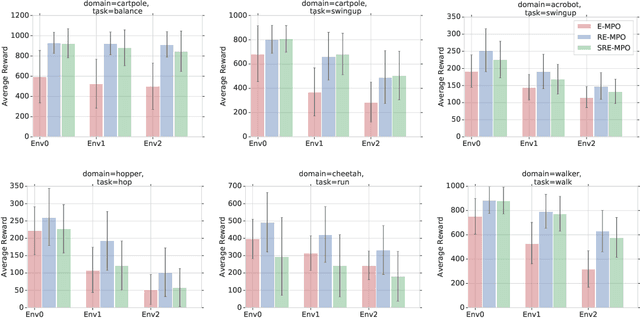

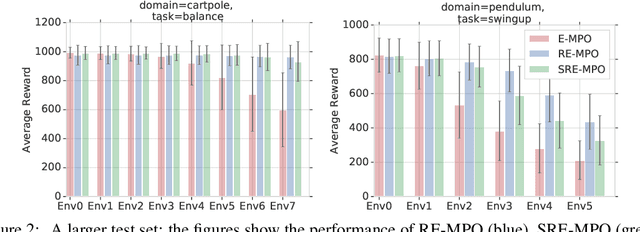
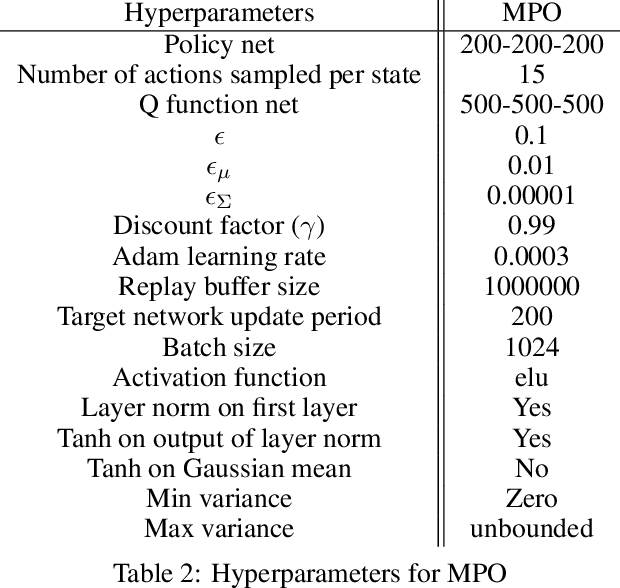
We provide a framework for incorporating robustness -- to perturbations in the transition dynamics which we refer to as model misspecification -- into continuous control Reinforcement Learning (RL) algorithms. We specifically focus on incorporating robustness into a state-of-the-art continuous control RL algorithm called Maximum a-posteriori Policy Optimization (MPO). We achieve this by learning a policy that optimizes for a worst case, entropy-regularized, expected return objective and derive a corresponding robust entropy-regularized Bellman contraction operator. In addition, we introduce a less conservative, soft-robust, entropy-regularized objective with a corresponding Bellman operator. We show that both, robust and soft-robust policies, outperform their non-robust counterparts in nine Mujoco domains with environment perturbations. Finally, we present multiple investigative experiments that provide a deeper insight into the robustness framework; including an adaptation to another continuous control RL algorithm as well as comparing this approach to domain randomization. Performance videos can be found online at https://sites.google.com/view/robust-rl.
Action Assembly: Sparse Imitation Learning for Text Based Games with Combinatorial Action Spaces
May 23, 2019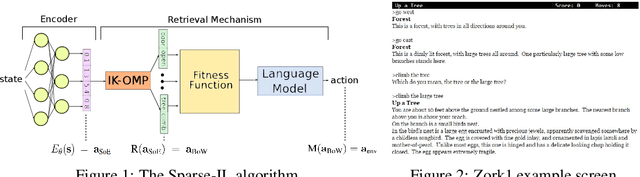
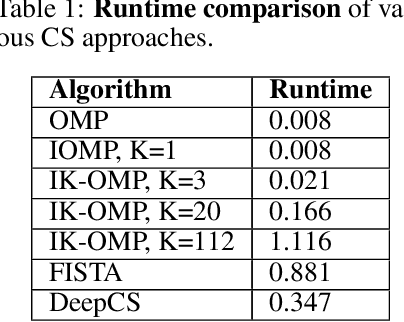
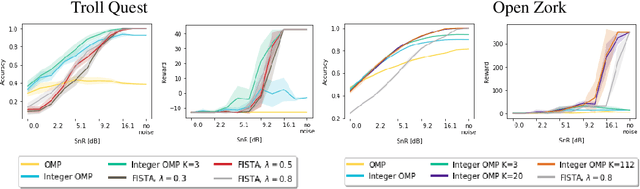
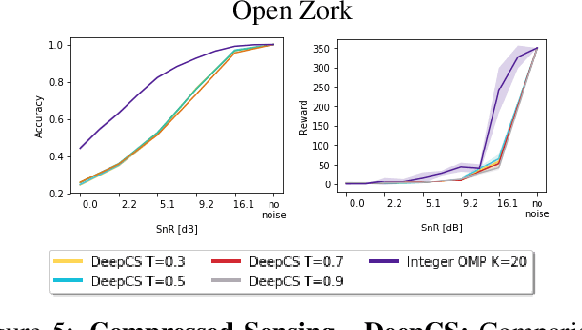
We propose a computationally efficient algorithm that combines compressed sensing with imitation learning to solve sequential decision making text-based games with combinatorial action spaces. We propose a variation of the compressed sensing algorithm Orthogonal Matching Pursuit (OMP), that we call IK-OMP, and show that it can recover a bag-of-words from a sum of the individual word embeddings, even in the presence of noise. We incorporate IK-OMP into a supervised imitation learning setting and show that this algorithm, called Sparse Imitation Learning (Sparse-IL), solves the entire text-based game of Zork1 with an action space of approximately 10 million actions using imperfect, noisy demonstrations.
Soft-Robust Actor-Critic Policy-Gradient
Oct 24, 2018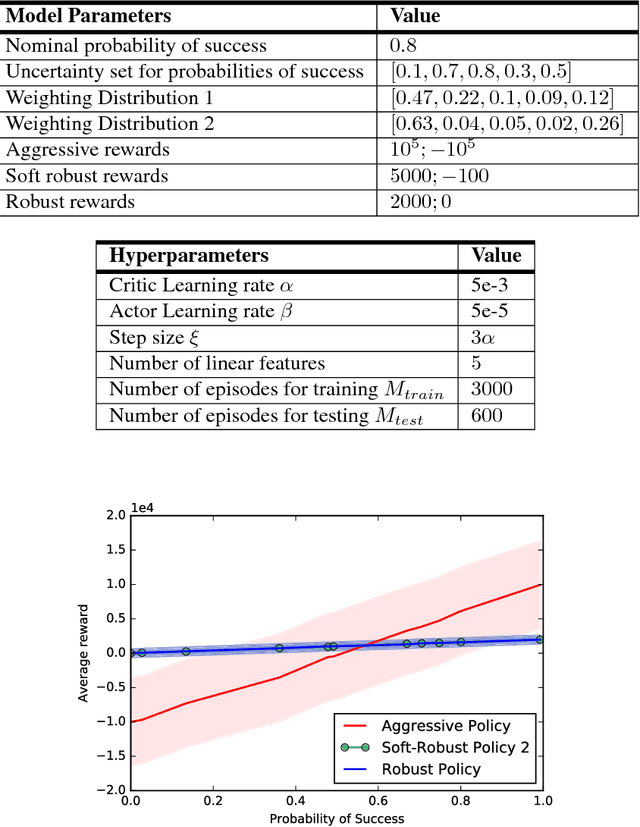
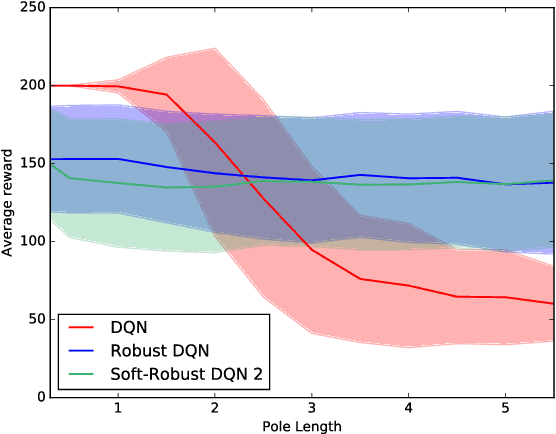
Robust Reinforcement Learning aims to derive optimal behavior that accounts for model uncertainty in dynamical systems. However, previous studies have shown that by considering the worst case scenario, robust policies can be overly conservative. Our soft-robust framework is an attempt to overcome this issue. In this paper, we present a novel Soft-Robust Actor-Critic algorithm (SR-AC). It learns an optimal policy with respect to a distribution over an uncertainty set and stays robust to model uncertainty but avoids the conservativeness of robust strategies. We show the convergence of SR-AC and test the efficiency of our approach on different domains by comparing it against regular learning methods and their robust formulations.
Learn What Not to Learn: Action Elimination with Deep Reinforcement Learning
Sep 06, 2018
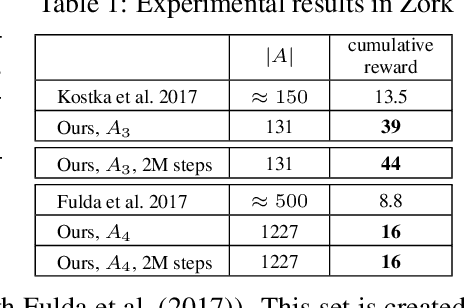
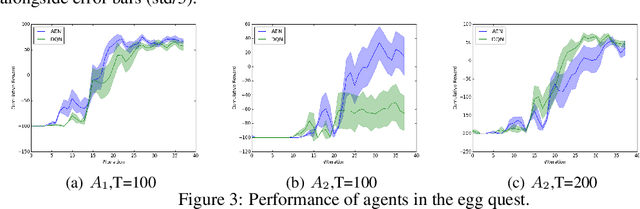
Learning how to act when there are many available actions in each state is a challenging task for Reinforcement Learning (RL) agents, especially when many of the actions are redundant or irrelevant. In such cases, it is sometimes easier to learn which actions not to take. In this work, we propose the Action-Elimination Deep Q-Network (AE-DQN) architecture that combines a Deep RL algorithm with an Action Elimination Network (AEN) that eliminates sub-optimal actions. The AEN is trained to predict invalid actions, supervised by an external elimination signal provided by the environment. Simulations demonstrate a considerable speedup and added robustness over vanilla DQN in text-based games with over a thousand discrete actions.
Unicorn: Continual Learning with a Universal, Off-policy Agent
Jul 03, 2018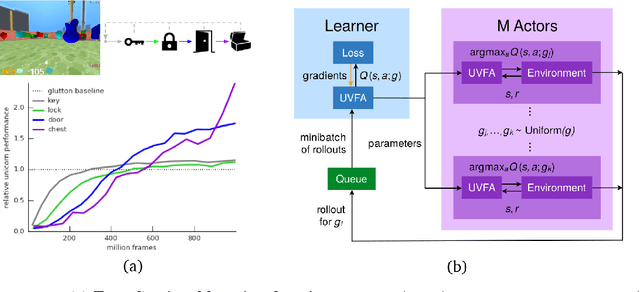
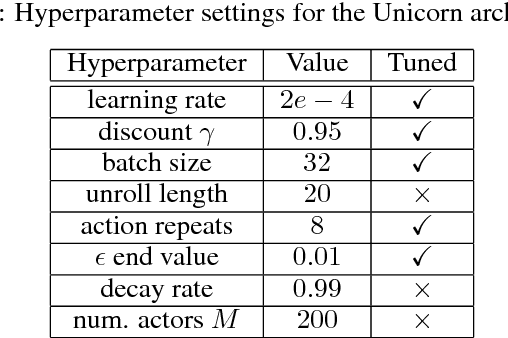
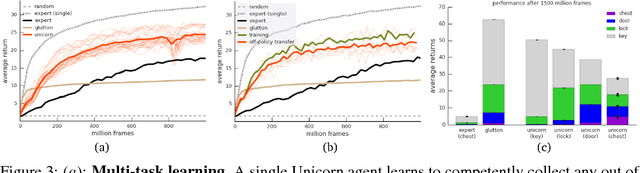
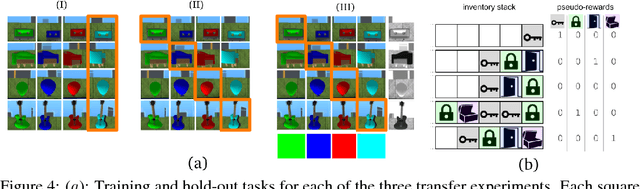
Some real-world domains are best characterized as a single task, but for others this perspective is limiting. Instead, some tasks continually grow in complexity, in tandem with the agent's competence. In continual learning, also referred to as lifelong learning, there are no explicit task boundaries or curricula. As learning agents have become more powerful, continual learning remains one of the frontiers that has resisted quick progress. To test continual learning capabilities we consider a challenging 3D domain with an implicit sequence of tasks and sparse rewards. We propose a novel agent architecture called Unicorn, which demonstrates strong continual learning and outperforms several baseline agents on the proposed domain. The agent achieves this by jointly representing and learning multiple policies efficiently, using a parallel off-policy learning setup.
Reward Constrained Policy Optimization
May 28, 2018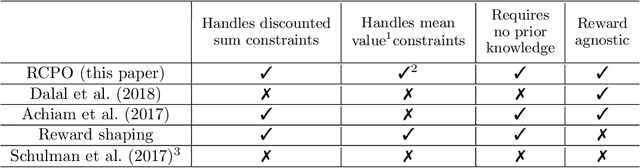
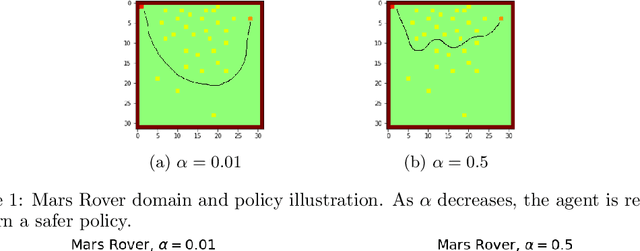
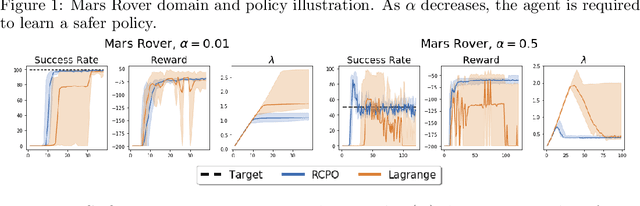
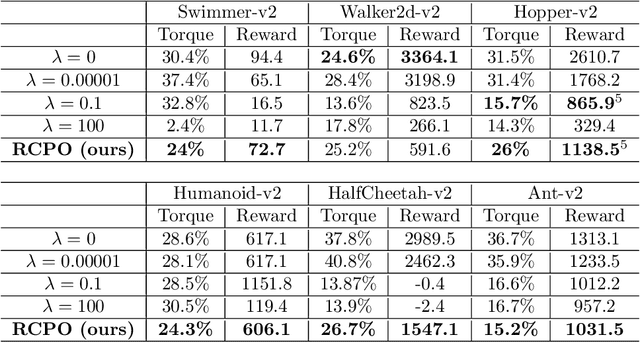
Teaching agents to perform tasks using Reinforcement Learning is no easy feat. As the goal of reinforcement learning agents is to maximize the accumulated reward, they often find loopholes and misspecifications in the reward signal which lead to unwanted behavior. To overcome this, often, regularization is employed through the technique of reward shaping - the agent is provided an additional weighted reward signal, meant to lead it towards a desired behavior. The weight is considered as a hyper-parameter and is selected through trial and error, a time consuming and computationally intensive task. In this work, we present a novel multi-timescale approach for constrained policy optimization, called, 'Reward Constrained Policy Optimization' (RCPO), which enables policy regularization without the use of reward shaping. We prove the convergence of our approach and provide empirical evidence of its ability to train constraint satisfying policies.
Learning Robust Options
Feb 09, 2018
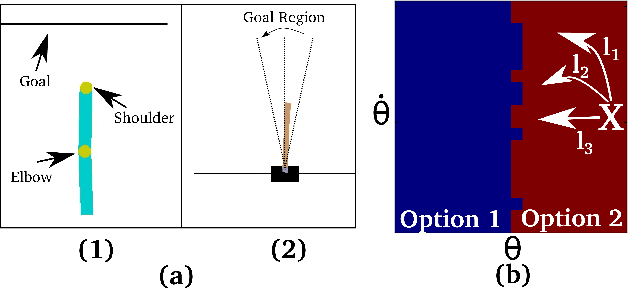
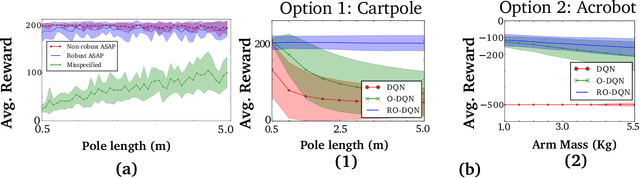
Robust reinforcement learning aims to produce policies that have strong guarantees even in the face of environments/transition models whose parameters have strong uncertainty. Existing work uses value-based methods and the usual primitive action setting. In this paper, we propose robust methods for learning temporally abstract actions, in the framework of options. We present a Robust Options Policy Iteration (ROPI) algorithm with convergence guarantees, which learns options that are robust to model uncertainty. We utilize ROPI to learn robust options with the Robust Options Deep Q Network (RO-DQN) that solves multiple tasks and mitigates model misspecification due to model uncertainty. We present experimental results which suggest that policy iteration with linear features may have an inherent form of robustness when using coarse feature representations. In addition, we present experimental results which demonstrate that robustness helps policy iteration implemented on top of deep neural networks to generalize over a much broader range of dynamics than non-robust policy iteration.
Situationally Aware Options
Nov 20, 2017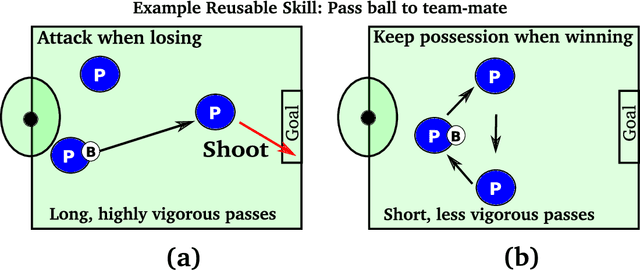
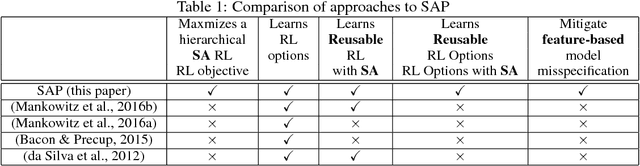
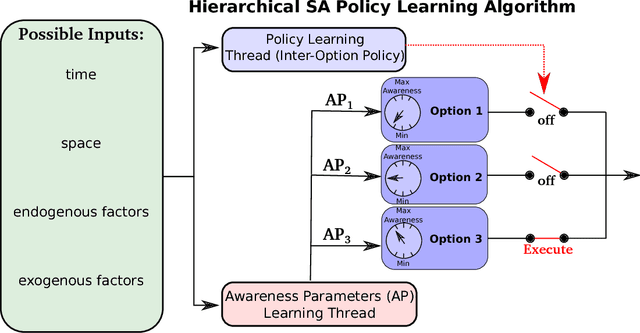
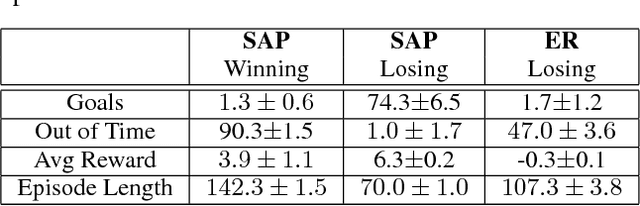
Hierarchical abstractions, also known as options -- a type of temporally extended action (Sutton et. al. 1999) that enables a reinforcement learning agent to plan at a higher level, abstracting away from the lower-level details. In this work, we learn reusable options whose parameters can vary, encouraging different behaviors, based on the current situation. In principle, these behaviors can include vigor, defence or even risk-averseness. These are some examples of what we refer to in the broader context as Situational Awareness (SA). We incorporate SA, in the form of vigor, into hierarchical RL by defining and learning situationally aware options in a Probabilistic Goal Semi-Markov Decision Process (PG-SMDP). This is achieved using our Situationally Aware oPtions (SAP) policy gradient algorithm which comes with a theoretical convergence guarantee. We learn reusable options in different scenarios in a RoboCup soccer domain (i.e., winning/losing). These options learn to execute with different levels of vigor resulting in human-like behaviours such as `time-wasting' in the winning scenario. We show the potential of the agent to exit bad local optima using reusable options in RoboCup. Finally, using SAP, the agent mitigates feature-based model misspecification in a Bottomless Pit of Death domain.
Shallow Updates for Deep Reinforcement Learning
Nov 02, 2017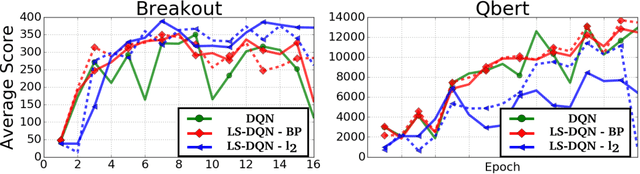


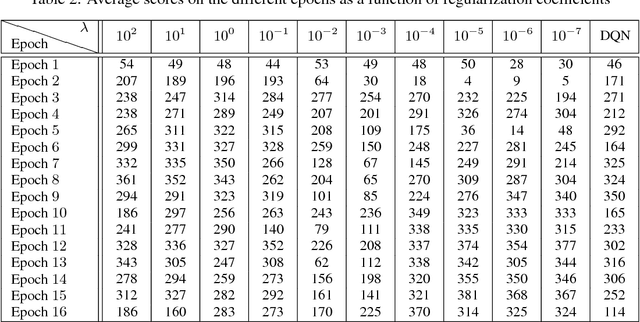
Deep reinforcement learning (DRL) methods such as the Deep Q-Network (DQN) have achieved state-of-the-art results in a variety of challenging, high-dimensional domains. This success is mainly attributed to the power of deep neural networks to learn rich domain representations for approximating the value function or policy. Batch reinforcement learning methods with linear representations, on the other hand, are more stable and require less hyper parameter tuning. Yet, substantial feature engineering is necessary to achieve good results. In this work we propose a hybrid approach -- the Least Squares Deep Q-Network (LS-DQN), which combines rich feature representations learned by a DRL algorithm with the stability of a linear least squares method. We do this by periodically re-training the last hidden layer of a DRL network with a batch least squares update. Key to our approach is a Bayesian regularization term for the least squares update, which prevents over-fitting to the more recent data. We tested LS-DQN on five Atari games and demonstrate significant improvement over vanilla DQN and Double-DQN. We also investigated the reasons for the superior performance of our method. Interestingly, we found that the performance improvement can be attributed to the large batch size used by the LS method when optimizing the last layer.
A Deep Hierarchical Approach to Lifelong Learning in Minecraft
Nov 30, 2016
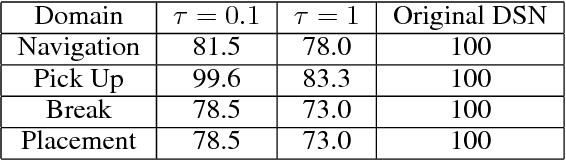
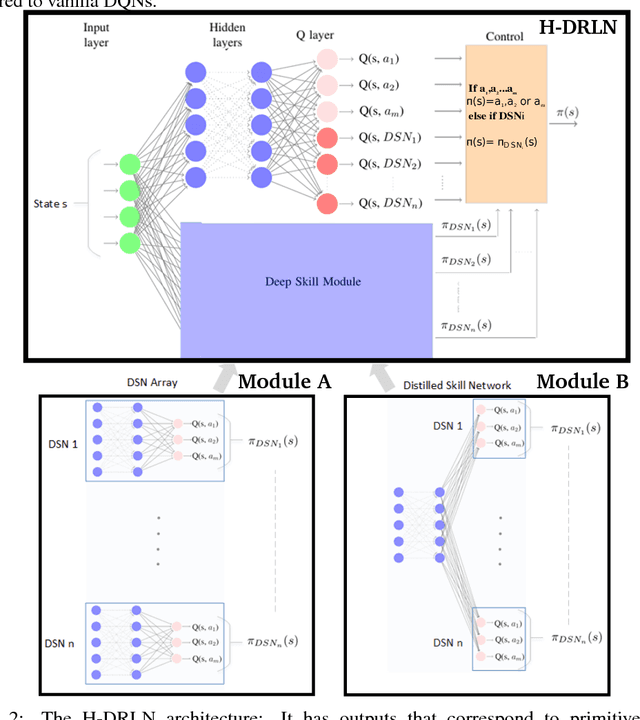
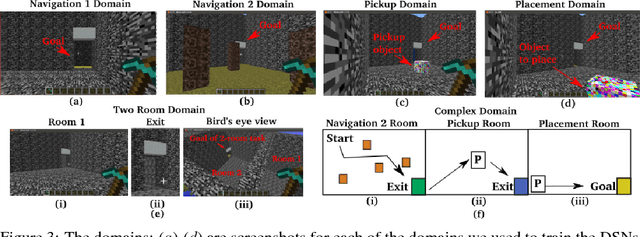
We propose a lifelong learning system that has the ability to reuse and transfer knowledge from one task to another while efficiently retaining the previously learned knowledge-base. Knowledge is transferred by learning reusable skills to solve tasks in Minecraft, a popular video game which is an unsolved and high-dimensional lifelong learning problem. These reusable skills, which we refer to as Deep Skill Networks, are then incorporated into our novel Hierarchical Deep Reinforcement Learning Network (H-DRLN) architecture using two techniques: (1) a deep skill array and (2) skill distillation, our novel variation of policy distillation (Rusu et. al. 2015) for learning skills. Skill distillation enables the HDRLN to efficiently retain knowledge and therefore scale in lifelong learning, by accumulating knowledge and encapsulating multiple reusable skills into a single distilled network. The H-DRLN exhibits superior performance and lower learning sample complexity compared to the regular Deep Q Network (Mnih et. al. 2015) in sub-domains of Minecraft.