 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpeed of Light Exact Greedy Decoding for RNN-T Speech Recognition Models on GPU
Jun 06, 2024



The vast majority of inference time for RNN Transducer (RNN-T) models today is spent on decoding. Current state-of-the-art RNN-T decoding implementations leave the GPU idle ~80% of the time. Leveraging a new CUDA 12.4 feature, CUDA graph conditional nodes, we present an exact GPU-based implementation of greedy decoding for RNN-T models that eliminates this idle time. Our optimizations speed up a 1.1 billion parameter RNN-T model end-to-end by a factor of 2.5x. This technique can applied to the "label looping" alternative greedy decoding algorithm as well, achieving 1.7x and 1.4x end-to-end speedups when applied to 1.1 billion parameter RNN-T and Token and Duration Transducer models respectively. This work enables a 1.1 billion parameter RNN-T model to run only 16% slower than a similarly sized CTC model, contradicting the common belief that RNN-T models are not suitable for high throughput inference. The implementation is available in NVIDIA NeMo.
GPU-Accelerated WFST Beam Search Decoder for CTC-based Speech Recognition
Nov 08, 2023



While Connectionist Temporal Classification (CTC) models deliver state-of-the-art accuracy in automated speech recognition (ASR) pipelines, their performance has been limited by CPU-based beam search decoding. We introduce a GPU-accelerated Weighted Finite State Transducer (WFST) beam search decoder compatible with current CTC models. It increases pipeline throughput and decreases latency, supports streaming inference, and also supports advanced features like utterance-specific word boosting via on-the-fly composition. We provide pre-built DLPack-based python bindings for ease of use with Python-based machine learning frameworks at https://github.com/nvidia-riva/riva-asrlib-decoder. We evaluated our decoder for offline and online scenarios, demonstrating that it is the fastest beam search decoder for CTC models. In the offline scenario it achieves up to 7 times more throughput than the current state-of-the-art CPU decoder and in the online streaming scenario, it achieves nearly 8 times lower latency, with same or better word error rate.
A Data-Centric Approach for Training Deep Neural Networks with Less Data
Oct 29, 2021

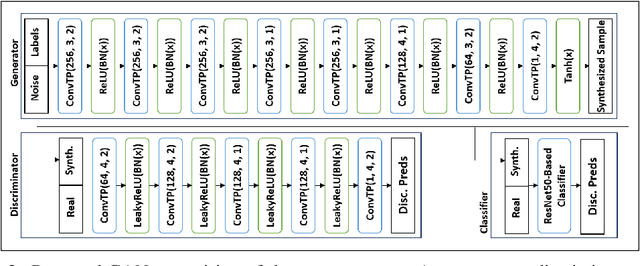
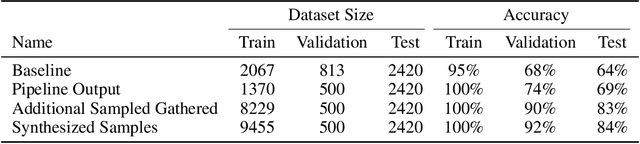
While the availability of large datasets is perceived to be a key requirement for training deep neural networks, it is possible to train such models with relatively little data. However, compensating for the absence of large datasets demands a series of actions to enhance the quality of the existing samples and to generate new ones. This paper summarizes our winning submission to the "Data-Centric AI" competition. We discuss some of the challenges that arise while training with a small dataset, offer a principled approach for systematic data quality enhancement, and propose a GAN-based solution for synthesizing new data points. Our evaluations indicate that the dataset generated by the proposed pipeline offers 5% accuracy improvement while being significantly smaller than the baseline.