 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTiny Aya: Bridging Scale and Multilingual Depth
Mar 12, 2026Tiny Aya redefines what a small multilingual language model can achieve. Trained on 70 languages and refined through region-aware posttraining, it delivers state-of-the-art in translation quality, strong multilingual understanding, and high-quality target-language generation, all with just 3.35B parameters. The release includes a pretrained foundation model, a globally balanced instruction-tuned variant, and three region-specialized models targeting languages from Africa, South Asia, Europe, Asia-Pacific, and West Asia. This report details the training strategy, data composition, and comprehensive evaluation framework behind Tiny Aya, and presents an alternative scaling path for multilingual AI: one centered on efficiency, balanced performance across languages, and practical deployment.
When Life Gives You Samples: The Benefits of Scaling up Inference Compute for Multilingual LLMs
Jun 25, 2025



Recent advancements in large language models (LLMs) have shifted focus toward scaling inference-time compute, improving performance without retraining the model. A common approach is to sample multiple outputs in parallel, and select one of these as the final output. However, work to date has focused on English and a handful of domains such as math and code. In contrast, we are most interested in techniques that generalize across open-ended tasks, formally verifiable tasks, and across languages. In this work, we study how to robustly scale inference-time compute for open-ended generative tasks in a multilingual, multi-task setting. Our findings show that both sampling strategy based on temperature variation and selection strategy must be adapted to account for diverse domains and varied language settings. We evaluate existing selection methods, revealing that strategies effective in English often fail to generalize across languages. We propose novel sampling and selection strategies specifically adapted for multilingual and multi-task inference scenarios, and show they yield notable gains across languages and tasks. In particular, our combined sampling and selection methods lead to an average +6.8 jump in win-rates for our 8B models on m-ArenaHard-v2.0 prompts, against proprietary models such as Gemini. At larger scale, Command-A (111B model) equipped with our methods, shows +9.0 improvement in win-rates on the same benchmark with just five samples against single-sample decoding, a substantial increase at minimal cost. Our results underscore the need for language- and task-aware approaches to inference-time compute, aiming to democratize performance improvements in underrepresented languages.
Treasure Hunt: Real-time Targeting of the Long Tail using Training-Time Markers
Jun 17, 2025One of the most profound challenges of modern machine learning is performing well on the long-tail of rare and underrepresented features. Large general-purpose models are trained for many tasks, but work best on high-frequency use cases. After training, it is hard to adapt a model to perform well on specific use cases underrepresented in the training corpus. Relying on prompt engineering or few-shot examples to maximize the output quality on a particular test case can be frustrating, as models can be highly sensitive to small changes, react in unpredicted ways or rely on a fixed system prompt for maintaining performance. In this work, we ask: "Can we optimize our training protocols to both improve controllability and performance on underrepresented use cases at inference time?" We revisit the divide between training and inference techniques to improve long-tail performance while providing users with a set of control levers the model is trained to be responsive to. We create a detailed taxonomy of data characteristics and task provenance to explicitly control generation attributes and implicitly condition generations at inference time. We fine-tune a base model to infer these markers automatically, which makes them optional at inference time. This principled and flexible approach yields pronounced improvements in performance, especially on examples from the long tail of the training distribution. While we observe an average lift of 5.7% win rates in open-ended generation quality with our markers, we see over 9.1% gains in underrepresented domains. We also observe relative lifts of up to 14.1% on underrepresented tasks like CodeRepair and absolute improvements of 35.3% on length instruction following evaluations.
Command A: An Enterprise-Ready Large Language Model
Apr 01, 2025



In this report we describe the development of Command A, a powerful large language model purpose-built to excel at real-world enterprise use cases. Command A is an agent-optimised and multilingual-capable model, with support for 23 languages of global business, and a novel hybrid architecture balancing efficiency with top of the range performance. It offers best-in-class Retrieval Augmented Generation (RAG) capabilities with grounding and tool use to automate sophisticated business processes. These abilities are achieved through a decentralised training approach, including self-refinement algorithms and model merging techniques. We also include results for Command R7B which shares capability and architectural similarities to Command A. Weights for both models have been released for research purposes. This technical report details our original training pipeline and presents an extensive evaluation of our models across a suite of enterprise-relevant tasks and public benchmarks, demonstrating excellent performance and efficiency.
Aya Expanse: Combining Research Breakthroughs for a New Multilingual Frontier
Dec 05, 2024



We introduce the Aya Expanse model family, a new generation of 8B and 32B parameter multilingual language models, aiming to address the critical challenge of developing highly performant multilingual models that match or surpass the capabilities of monolingual models. By leveraging several years of research at Cohere For AI and Cohere, including advancements in data arbitrage, multilingual preference training, and model merging, Aya Expanse sets a new state-of-the-art in multilingual performance. Our evaluations on the Arena-Hard-Auto dataset, translated into 23 languages, demonstrate that Aya Expanse 8B and 32B outperform leading open-weight models in their respective parameter classes, including Gemma 2, Qwen 2.5, and Llama 3.1, achieving up to a 76.6% win-rate. Notably, Aya Expanse 32B outperforms Llama 3.1 70B, a model with twice as many parameters, achieving a 54.0% win-rate. In this short technical report, we present extended evaluation results for the Aya Expanse model family and release their open-weights, together with a new multilingual evaluation dataset m-ArenaHard.
Multilingual Arbitrage: Optimizing Data Pools to Accelerate Multilingual Progress
Aug 27, 2024



The use of synthetic data has played a critical role in recent state-of-art breakthroughs. However, overly relying on a single oracle teacher model to generate data has been shown to lead to model collapse and invite propagation of biases. These limitations are particularly evident in multilingual settings, where the absence of a universally effective teacher model that excels across all languages presents significant challenges. In this work, we address these extreme difference by introducing "multilingual arbitrage", which capitalizes on performance variations between multiple models for a given language. To do so, we strategically route samples through a diverse pool of models, each with unique strengths in different languages. Across exhaustive experiments on state-of-art models, our work suggests that arbitrage techniques allow for spectacular gains in performance that far outperform relying on a single teacher. In particular, compared to the best single teacher, we observe gains of up to 56.5% improvement in win rates averaged across all languages when switching to multilingual arbitrage. We observe the most significant gains for the least resourced languages in our pool.
Aya Model: An Instruction Finetuned Open-Access Multilingual Language Model
Feb 12, 2024



Recent breakthroughs in large language models (LLMs) have centered around a handful of data-rich languages. What does it take to broaden access to breakthroughs beyond first-class citizen languages? Our work introduces Aya, a massively multilingual generative language model that follows instructions in 101 languages of which over 50% are considered as lower-resourced. Aya outperforms mT0 and BLOOMZ on the majority of tasks while covering double the number of languages. We introduce extensive new evaluation suites that broaden the state-of-art for multilingual eval across 99 languages -- including discriminative and generative tasks, human evaluation, and simulated win rates that cover both held-out tasks and in-distribution performance. Furthermore, we conduct detailed investigations on the optimal finetuning mixture composition, data pruning, as well as the toxicity, bias, and safety of our models. We open-source our instruction datasets and our model at https://hf.co/CohereForAI/aya-101
FAIR-Ensemble: When Fairness Naturally Emerges From Deep Ensembling
Mar 01, 2023Ensembling independent deep neural networks (DNNs) is a simple and effective way to improve top-line metrics and to outperform larger single models. In this work, we go beyond top-line metrics and instead explore the impact of ensembling on subgroup performances. Surprisingly, even with a simple homogenous ensemble -- all the individual models share the same training set, architecture, and design choices -- we find compelling and powerful gains in worst-k and minority group performance, i.e. fairness naturally emerges from ensembling. We show that the gains in performance from ensembling for the minority group continue for far longer than for the majority group as more models are added. Our work establishes that simple DNN ensembles can be a powerful tool for alleviating disparate impact from DNN classifiers, thus curbing algorithmic harm. We also explore why this is the case. We find that even in homogeneous ensembles, varying the sources of stochasticity through parameter initialization, mini-batch sampling, and the data-augmentation realizations, results in different fairness outcomes.
A Tale Of Two Long Tails
Jul 27, 2021As machine learning models are increasingly employed to assist human decision-makers, it becomes critical to communicate the uncertainty associated with these model predictions. However, the majority of work on uncertainty has focused on traditional probabilistic or ranking approaches - where the model assigns low probabilities or scores to uncertain examples. While this captures what examples are challenging for the model, it does not capture the underlying source of the uncertainty. In this work, we seek to identify examples the model is uncertain about and characterize the source of said uncertainty. We explore the benefits of designing a targeted intervention - targeted data augmentation of the examples where the model is uncertain over the course of training. We investigate whether the rate of learning in the presence of additional information differs between atypical and noisy examples? Our results show that this is indeed the case, suggesting that well-designed interventions over the course of training can be an effective way to characterize and distinguish between different sources of uncertainty.
MasakhaNER: Named Entity Recognition for African Languages
Mar 22, 2021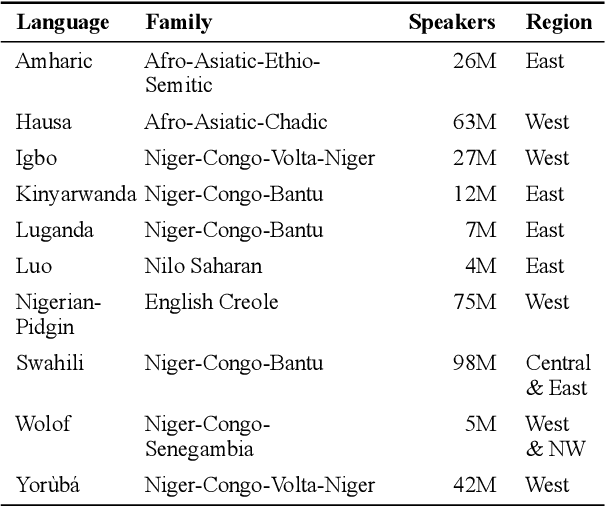

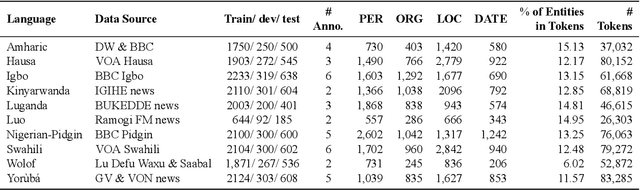
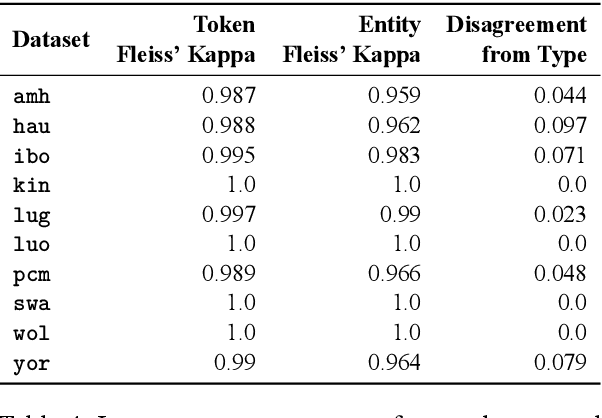
We take a step towards addressing the under-representation of the African continent in NLP research by creating the first large publicly available high-quality dataset for named entity recognition (NER) in ten African languages, bringing together a variety of stakeholders. We detail characteristics of the languages to help researchers understand the challenges that these languages pose for NER. We analyze our datasets and conduct an extensive empirical evaluation of state-of-the-art methods across both supervised and transfer learning settings. We release the data, code, and models in order to inspire future research on African NLP.