 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvent-Based Feature Tracking in Continuous Time with Sliding Window Optimization
Jul 09, 2021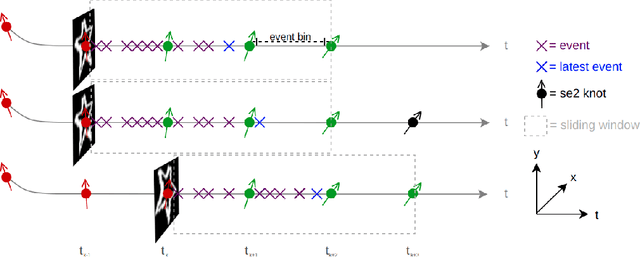
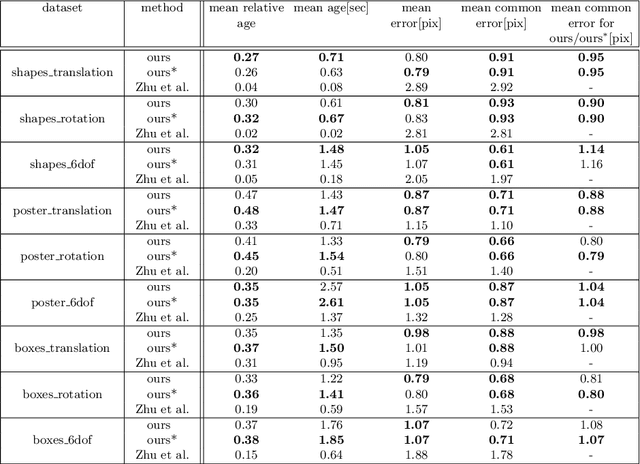
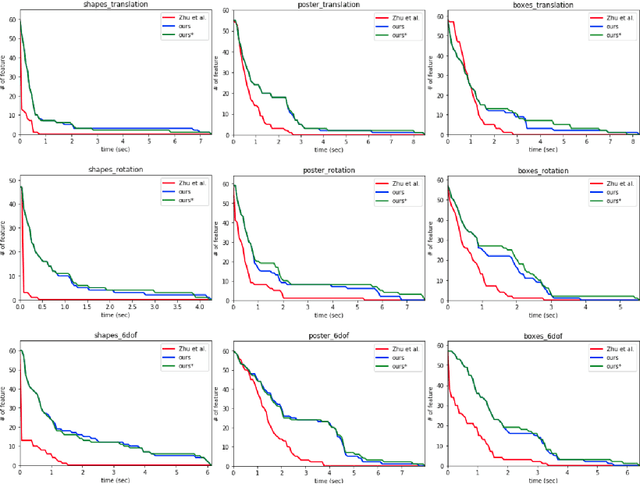

We propose a novel method for continuous-time feature tracking in event cameras. To this end, we track features by aligning events along an estimated trajectory in space-time such that the projection on the image plane results in maximally sharp event patch images. The trajectory is parameterized by $n^{th}$ order B-splines, which are continuous up to $(n-2)^{th}$ derivative. In contrast to previous work, we optimize the curve parameters in a sliding window fashion. On a public dataset we experimentally confirm that the proposed sliding-window B-spline optimization leads to longer and more accurate feature tracks than in previous work.
DeepLab2: A TensorFlow Library for Deep Labeling
Jun 17, 2021


DeepLab2 is a TensorFlow library for deep labeling, aiming to provide a state-of-the-art and easy-to-use TensorFlow codebase for general dense pixel prediction problems in computer vision. DeepLab2 includes all our recently developed DeepLab model variants with pretrained checkpoints as well as model training and evaluation code, allowing the community to reproduce and further improve upon the state-of-art systems. To showcase the effectiveness of DeepLab2, our Panoptic-DeepLab employing Axial-SWideRNet as network backbone achieves 68.0% PQ or 83.5% mIoU on Cityscaspes validation set, with only single-scale inference and ImageNet-1K pretrained checkpoints. We hope that publicly sharing our library could facilitate future research on dense pixel labeling tasks and envision new applications of this technology. Code is made publicly available at \url{https://github.com/google-research/deeplab2}.
NeuroMorph: Unsupervised Shape Interpolation and Correspondence in One Go
Jun 17, 2021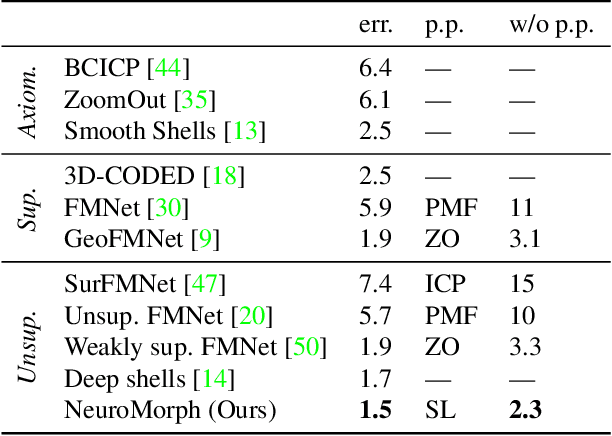
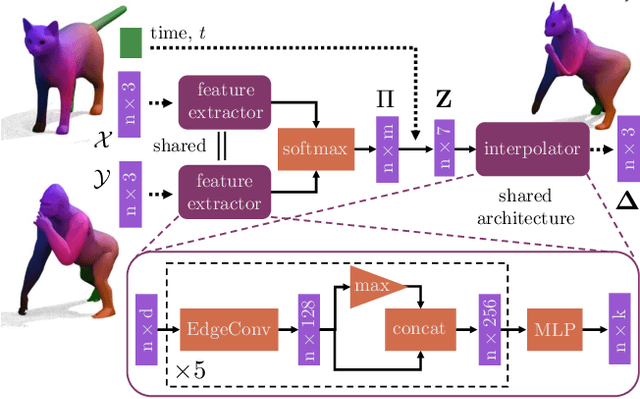
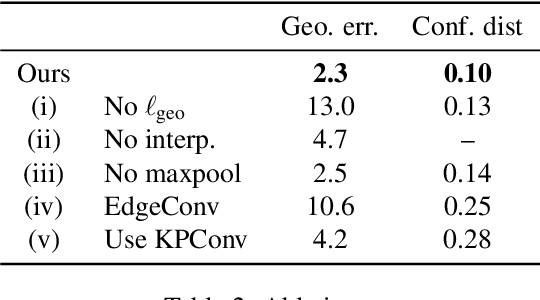
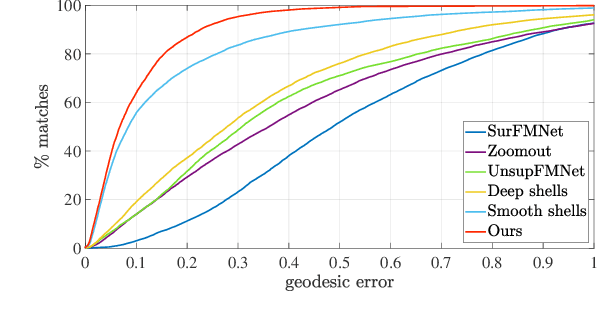
We present NeuroMorph, a new neural network architecture that takes as input two 3D shapes and produces in one go, i.e. in a single feed forward pass, a smooth interpolation and point-to-point correspondences between them. The interpolation, expressed as a deformation field, changes the pose of the source shape to resemble the target, but leaves the object identity unchanged. NeuroMorph uses an elegant architecture combining graph convolutions with global feature pooling to extract local features. During training, the model is incentivized to create realistic deformations by approximating geodesics on the underlying shape space manifold. This strong geometric prior allows to train our model end-to-end and in a fully unsupervised manner without requiring any manual correspondence annotations. NeuroMorph works well for a large variety of input shapes, including non-isometric pairs from different object categories. It obtains state-of-the-art results for both shape correspondence and interpolation tasks, matching or surpassing the performance of recent unsupervised and supervised methods on multiple benchmarks.
Joint Deep Multi-Graph Matching and 3D Geometry Learning from Inhomogeneous 2D Image Collections
Mar 31, 2021
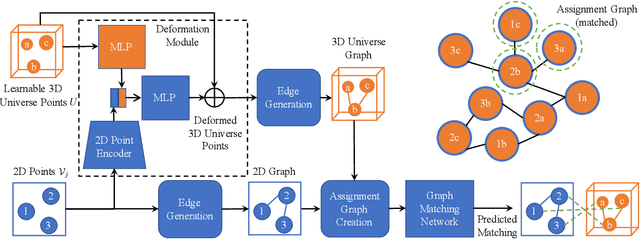
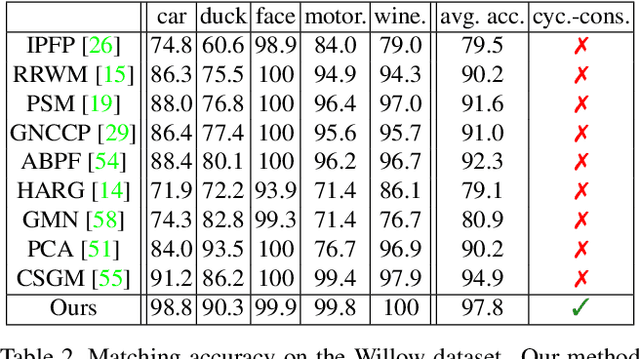

Graph matching aims to establish correspondences between vertices of graphs such that both the node and edge attributes agree. Various learning-based methods were recently proposed for finding correspondences between image key points based on deep graph matching formulations. While these approaches mainly focus on learning node and edge attributes, they completely ignore the 3D geometry of the underlying 3D objects depicted in the 2D images. We fill this gap by proposing a trainable framework that takes advantage of graph neural networks for learning a deformable 3D geometry model from inhomogeneous image collections, i.e. a set of images that depict different instances of objects from the same category. Experimentally we demonstrate that our method outperforms recent learning-based approaches for graph matching considering both accuracy and cycle-consistency error, while we in addition obtain the underlying 3D geometry of the objects depicted in the 2D images.
Square Root Bundle Adjustment for Large-Scale Reconstruction
Mar 30, 2021
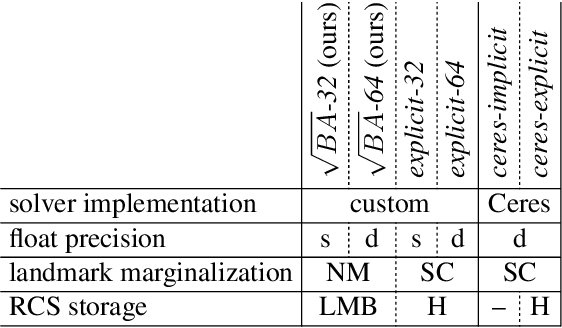
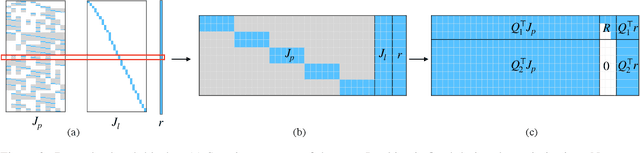

We propose a new formulation for the bundle adjustment problem which relies on nullspace marginalization of landmark variables by QR decomposition. Our approach, which we call square root bundle adjustment, is algebraically equivalent to the commonly used Schur complement trick, improves the numeric stability of computations, and allows for solving large-scale bundle adjustment problems with single-precision floating-point numbers. We show in real-world experiments with the BAL datasets that even in single precision the proposed solver achieves on average equally accurate solutions compared to Schur complement solvers using double precision. It runs significantly faster, but can require larger amounts of memory on dense problems. The proposed formulation relies on simple linear algebra operations and opens the way for efficient implementations of bundle adjustment on hardware platforms optimized for single-precision linear algebra processing.
Self-Supervised Steering Angle Prediction for Vehicle Control Using Visual Odometry
Mar 20, 2021
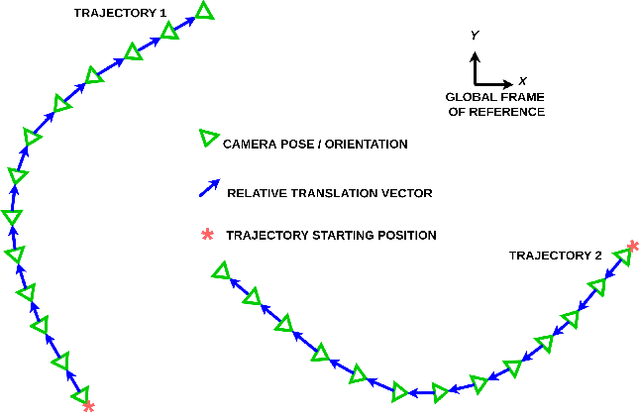
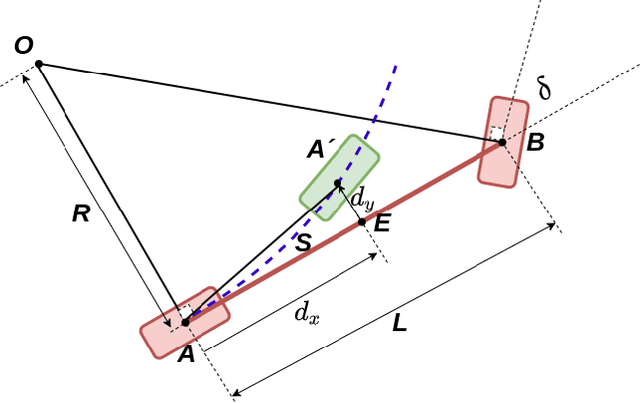
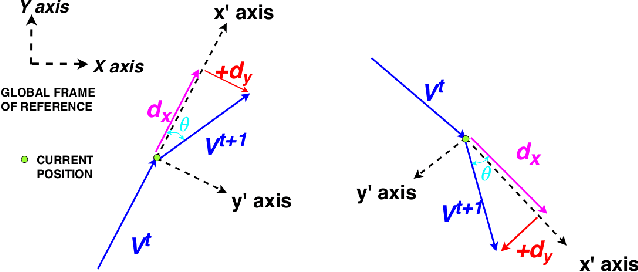
Vision-based learning methods for self-driving cars have primarily used supervised approaches that require a large number of labels for training. However, those labels are usually difficult and expensive to obtain. In this paper, we demonstrate how a model can be trained to control a vehicle's trajectory using camera poses estimated through visual odometry methods in an entirely self-supervised fashion. We propose a scalable framework that leverages trajectory information from several different runs using a camera setup placed at the front of a car. Experimental results on the CARLA simulator demonstrate that our proposed approach performs at par with the model trained with supervision.
Vision-Based Mobile Robotics Obstacle Avoidance With Deep Reinforcement Learning
Mar 08, 2021
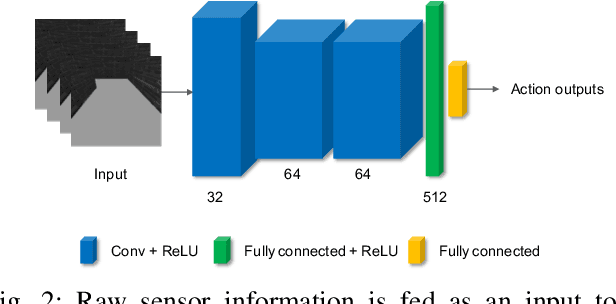

Obstacle avoidance is a fundamental and challenging problem for autonomous navigation of mobile robots. In this paper, we consider the problem of obstacle avoidance in simple 3D environments where the robot has to solely rely on a single monocular camera. In particular, we are interested in solving this problem without relying on localization, mapping, or planning techniques. Most of the existing work consider obstacle avoidance as two separate problems, namely obstacle detection, and control. Inspired by the recent advantages of deep reinforcement learning in Atari games and understanding highly complex situations in Go, we tackle the obstacle avoidance problem as a data-driven end-to-end deep learning approach. Our approach takes raw images as input and generates control commands as output. We show that discrete action spaces are outperforming continuous control commands in terms of expected average reward in maze-like environments. Furthermore, we show how to accelerate the learning and increase the robustness of the policy by incorporating predicted depth maps by a generative adversarial network.
Parameterized Temperature Scaling for Boosting the Expressive Power in Post-Hoc Uncertainty Calibration
Feb 24, 2021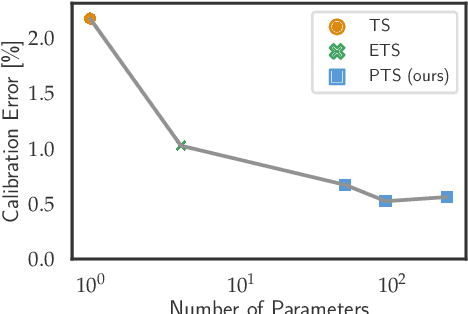
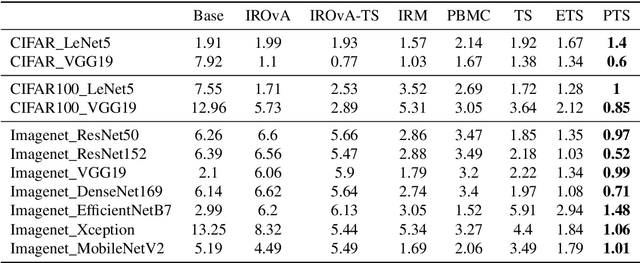
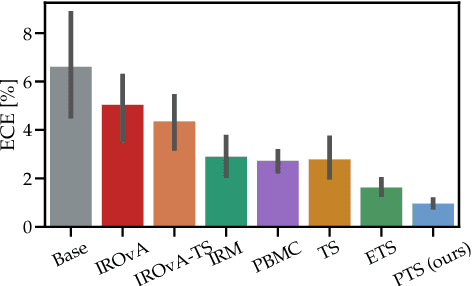
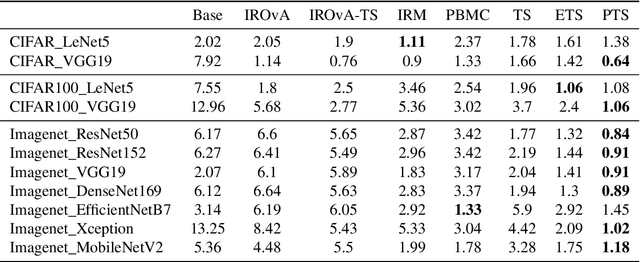
We address the problem of uncertainty calibration and introduce a novel calibration method, Parametrized Temperature Scaling (PTS). Standard deep neural networks typically yield uncalibrated predictions, which can be transformed into calibrated confidence scores using post-hoc calibration methods. In this contribution, we demonstrate that the performance of accuracy-preserving state-of-the-art post-hoc calibrators is limited by their intrinsic expressive power. We generalize temperature scaling by computing prediction-specific temperatures, parameterized by a neural network. We show with extensive experiments that our novel accuracy-preserving approach consistently outperforms existing algorithms across a large number of model architectures, datasets and metrics.
STEP: Segmenting and Tracking Every Pixel
Feb 23, 2021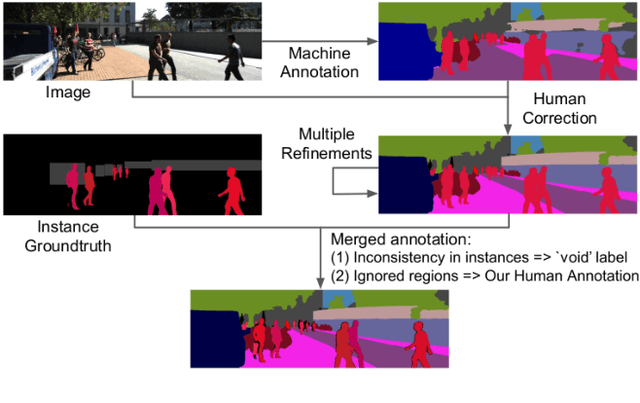
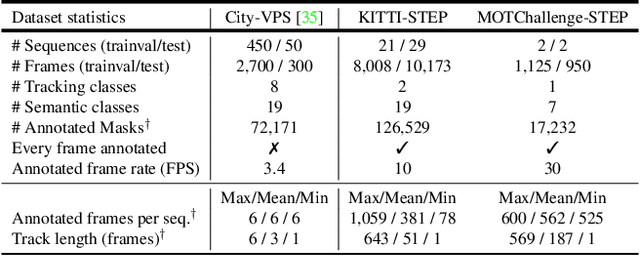


In this paper, we tackle video panoptic segmentation, a task that requires assigning semantic classes and track identities to all pixels in a video. To study this important problem in a setting that requires a continuous interpretation of sensory data, we present a new benchmark: Segmenting and Tracking Every Pixel (STEP), encompassing two datasets, KITTI-STEP, and MOTChallenge-STEP together with a new evaluation metric. Our work is the first that targets this task in a real-world setting that requires dense interpretation in both spatial and temporal domains. As the ground-truth for this task is difficult and expensive to obtain, existing datasets are either constructed synthetically or only sparsely annotated within short video clips. By contrast, our datasets contain long video sequences, providing challenging examples and a test-bed for studying long-term pixel-precise segmentation and tracking. For measuring the performance, we propose a novel evaluation metric Segmentation and Tracking Quality (STQ) that fairly balances semantic and tracking aspects of this task and is suitable for evaluating sequences of arbitrary length. We will make our datasets, metric, and baselines publicly available.
Variational Data Assimilation with a Learned Inverse Observation Operator
Feb 22, 2021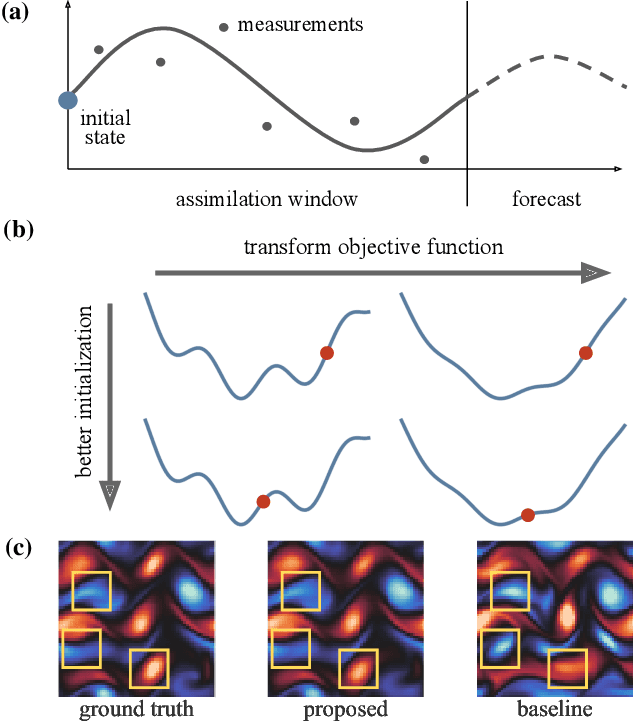
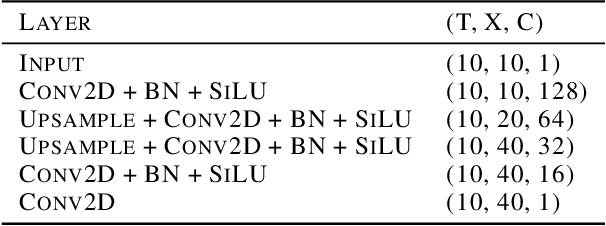
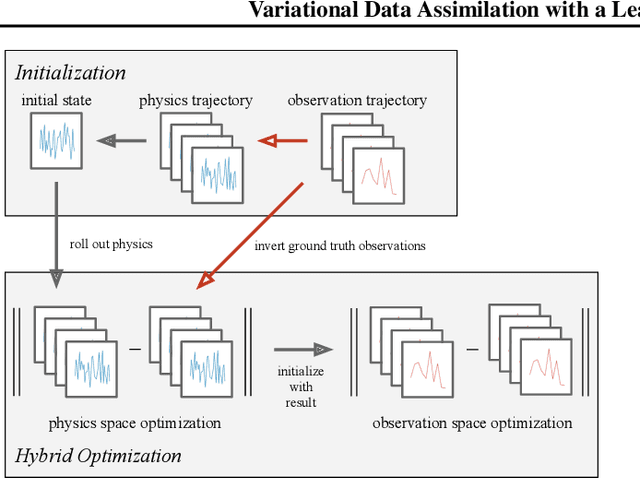

Variational data assimilation optimizes for an initial state of a dynamical system such that its evolution fits observational data. The physical model can subsequently be evolved into the future to make predictions. This principle is a cornerstone of large scale forecasting applications such as numerical weather prediction. As such, it is implemented in current operational systems of weather forecasting agencies across the globe. However, finding a good initial state poses a difficult optimization problem in part due to the non-invertible relationship between physical states and their corresponding observations. We learn a mapping from observational data to physical states and show how it can be used to improve optimizability. We employ this mapping in two ways: to better initialize the non-convex optimization problem, and to reformulate the objective function in better behaved physics space instead of observation space. Our experimental results for the Lorenz96 model and a two-dimensional turbulent fluid flow demonstrate that this procedure significantly improves forecast quality for chaotic systems.