 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLeveraging supplementary text data to kick-start automatic speech recognition system development with limited transcriptions
Feb 09, 2023
Recent research using pre-trained transformer models suggests that just 10 minutes of transcribed speech may be enough to fine-tune such a model for automatic speech recognition (ASR) -- at least if we can also leverage vast amounts of text data (803 million tokens). But is that much text data necessary? We study the use of different amounts of text data, both for creating a lexicon that constrains ASR decoding to possible words (e.g. *dogz vs. dogs), and for training larger language models that bias the system toward probable word sequences (e.g. too dogs vs. two dogs). We perform experiments using 10 minutes of transcribed speech from English (for replicating prior work) and two additional pairs of languages differing in the availability of supplemental text data: Gronings and Frisian (~7.5M token corpora available), and Besemah and Nasal (only small lexica available). For all languages, we found that using only a lexicon did not appreciably improve ASR performance. For Gronings and Frisian, we found that lexica and language models derived from 'novel-length' 80k token subcorpora reduced the word error rate (WER) to 39% on average. Our findings suggest that where a text corpus in the upper tens of thousands of tokens or more is available, fine-tuning a transformer model with just tens of minutes of transcribed speech holds some promise towards obtaining human-correctable transcriptions near the 30% WER rule-of-thumb.
Self-Destructing Models: Increasing the Costs of Harmful Dual Uses in Foundation Models
Nov 27, 2022A growing ecosystem of large, open-source foundation models has reduced the labeled data and technical expertise necessary to apply machine learning to many new problems. Yet foundation models pose a clear dual-use risk, indiscriminately reducing the costs of building both harmful and beneficial machine learning systems. To mitigate this risk, we propose the task blocking paradigm, in which foundation models are trained with an additional mechanism to impede adaptation to harmful tasks while retaining good performance on desired tasks. We call the resulting models self-destructing models, inspired by mechanisms that prevent adversaries from using tools for harmful purposes. We present an algorithm for training self-destructing models leveraging techniques from meta-learning and adversarial learning, showing that it can largely prevent a BERT-based model from learning to perform gender identification without harming the model's ability to perform profession classification. We conclude with a discussion of future directions.
Picking on the Same Person: Does Algorithmic Monoculture lead to Outcome Homogenization?
Nov 25, 2022As the scope of machine learning broadens, we observe a recurring theme of algorithmic monoculture: the same systems, or systems that share components (e.g. training data), are deployed by multiple decision-makers. While sharing offers clear advantages (e.g. amortizing costs), does it bear risks? We introduce and formalize one such risk, outcome homogenization: the extent to which particular individuals or groups experience negative outcomes from all decision-makers. If the same individuals or groups exclusively experience undesirable outcomes, this may institutionalize systemic exclusion and reinscribe social hierarchy. To relate algorithmic monoculture and outcome homogenization, we propose the component-sharing hypothesis: if decision-makers share components like training data or specific models, then they will produce more homogeneous outcomes. We test this hypothesis on algorithmic fairness benchmarks, demonstrating that sharing training data reliably exacerbates homogenization, with individual-level effects generally exceeding group-level effects. Further, given the dominant paradigm in AI of foundation models, i.e. models that can be adapted for myriad downstream tasks, we test whether model sharing homogenizes outcomes across tasks. We observe mixed results: we find that for both vision and language settings, the specific methods for adapting a foundation model significantly influence the degree of outcome homogenization. We conclude with philosophical analyses of and societal challenges for outcome homogenization, with an eye towards implications for deployed machine learning systems.
Follow the Wisdom of the Crowd: Effective Text Generation via Minimum Bayes Risk Decoding
Nov 14, 2022In open-ended natural-language generation, existing text decoding methods typically struggle to produce text which is both diverse and high-quality. Greedy and beam search are known to suffer from text degeneration and linguistic diversity issues, while temperature, top-k, and nucleus sampling often yield diverse but low-quality outputs. In this work, we present crowd sampling, a family of decoding methods based on Bayesian risk minimization, to address this diversity-quality trade-off. Inspired by the principle of "the wisdom of the crowd," crowd sampling seeks to select a candidate from a pool of candidates that has the least expected risk (i.e., highest expected reward) under a generative model according to a given utility function. Crowd sampling can be seen as a generalization of numerous existing methods, including majority voting, and in practice, it can be used as a drop-in replacement for existing sampling methods. Extensive experiments show that crowd sampling delivers improvements of 3-7 ROUGE and BLEU points across a wide range of tasks, including summarization, data-to-text, translation, and textual style transfer, while achieving new state-of-the-art results on WebNLG and WMT'16.
Easily Accessible Text-to-Image Generation Amplifies Demographic Stereotypes at Large Scale
Nov 07, 2022



Machine learning models are now able to convert user-written text descriptions into naturalistic images. These models are available to anyone online and are being used to generate millions of images a day. We investigate these models and find that they amplify dangerous and complex stereotypes. Moreover, we find that the amplified stereotypes are difficult to predict and not easily mitigated by users or model owners. The extent to which these image-generation models perpetuate and amplify stereotypes and their mass deployment is cause for serious concern.
Multilingual BERT has an accent: Evaluating English influences on fluency in multilingual models
Oct 11, 2022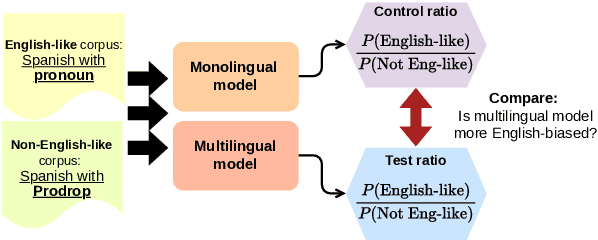

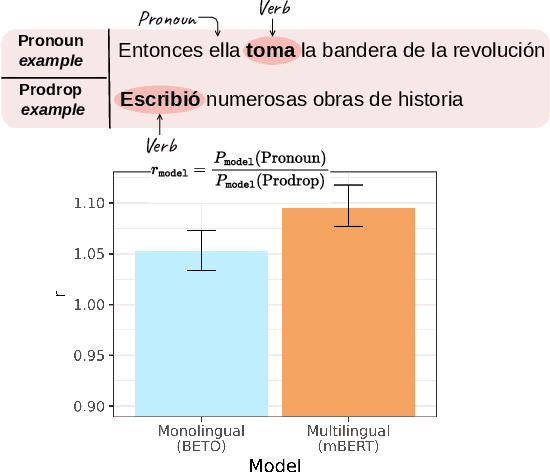
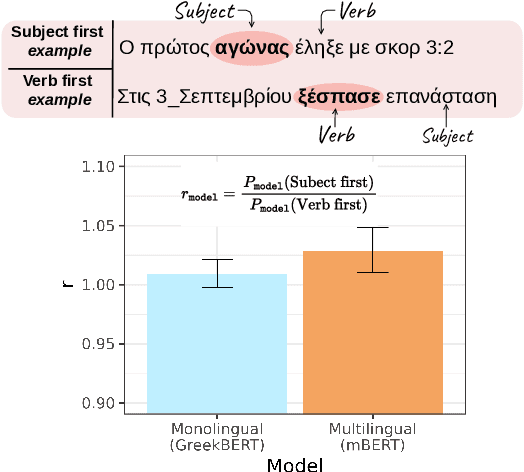
While multilingual language models can improve NLP performance on low-resource languages by leveraging higher-resource languages, they also reduce average performance on all languages (the 'curse of multilinguality'). Here we show another problem with multilingual models: grammatical structures in higher-resource languages bleed into lower-resource languages, a phenomenon we call grammatical structure bias. We show this bias via a novel method for comparing the fluency of multilingual models to the fluency of monolingual Spanish and Greek models: testing their preference for two carefully-chosen variable grammatical structures (optional pronoun-drop in Spanish and optional Subject-Verb ordering in Greek). We find that multilingual BERT is biased toward the English-like setting (explicit pronouns and Subject-Verb-Object ordering) as compared to our monolingual control. With our case studies, we hope to bring to light the fine-grained ways in which dominant languages can affect and bias multilingual performance, and encourage more linguistically-aware fluency evaluation.
When and why vision-language models behave like bags-of-words, and what to do about it?
Oct 06, 2022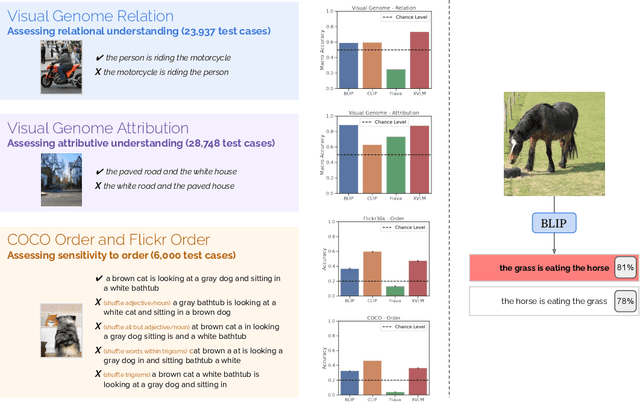

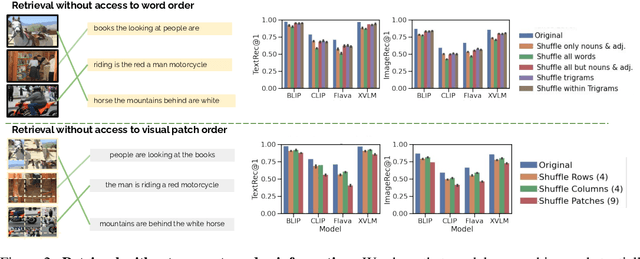
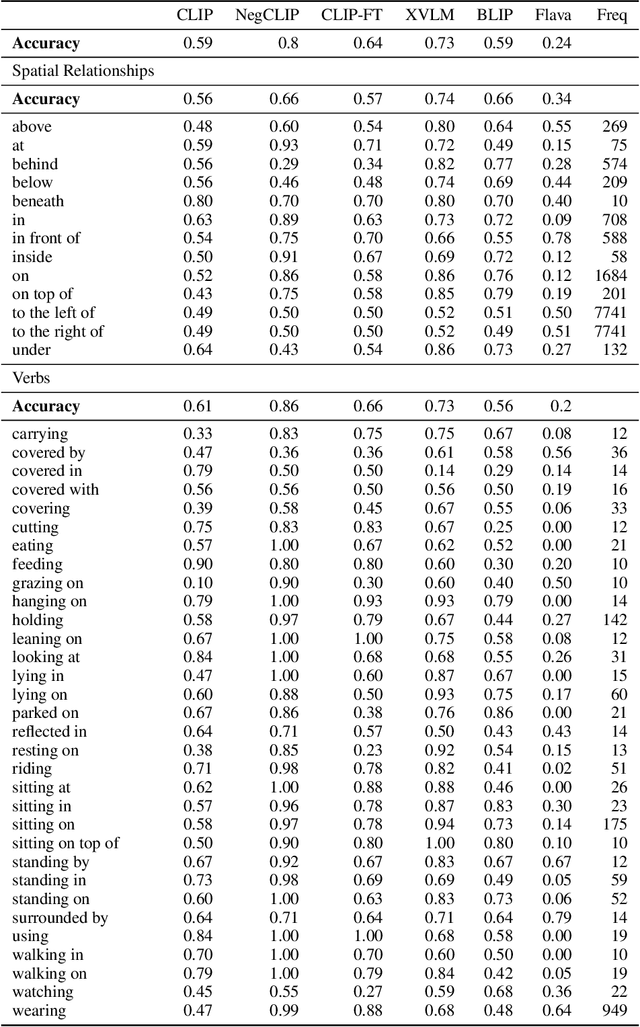
Despite the success of large vision and language models (VLMs) in many downstream applications, it is unclear how well they encode compositional information. Here, we create the Attribution, Relation, and Order (ARO) benchmark to systematically evaluate the ability of VLMs to understand different types of relationships, attributes, and order. ARO consists of Visual Genome Attribution, to test the understanding of objects' properties; Visual Genome Relation, to test for relational understanding; and COCO & Flickr30k-Order, to test for order sensitivity. ARO is orders of magnitude larger than previous benchmarks of compositionality, with more than 50,000 test cases. We show where state-of-the-art VLMs have poor relational understanding, can blunder when linking objects to their attributes, and demonstrate a severe lack of order sensitivity. VLMs are predominantly trained and evaluated on large datasets with rich compositional structure in the images and captions. Yet, training on these datasets has not been enough to address the lack of compositional understanding, and evaluating on these datasets has failed to surface this deficiency. To understand why these limitations emerge and are not represented in the standard tests, we zoom into the evaluation and training procedures. We demonstrate that it is possible to perform well on retrieval over existing datasets without using the composition and order information. Given that contrastive pretraining optimizes for retrieval on datasets with similar shortcuts, we hypothesize that this can explain why the models do not need to learn to represent compositional information. This finding suggests a natural solution: composition-aware hard negative mining. We show that a simple-to-implement modification of contrastive learning significantly improves the performance on tasks requiring understanding of order and compositionality.
Pile of Law: Learning Responsible Data Filtering from the Law and a 256GB Open-Source Legal Dataset
Jul 01, 2022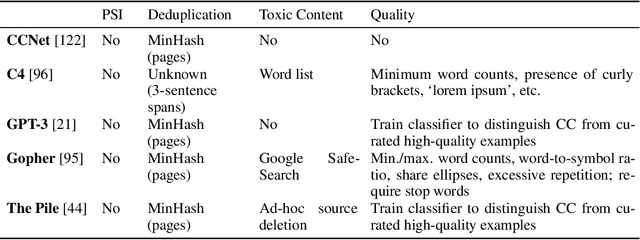
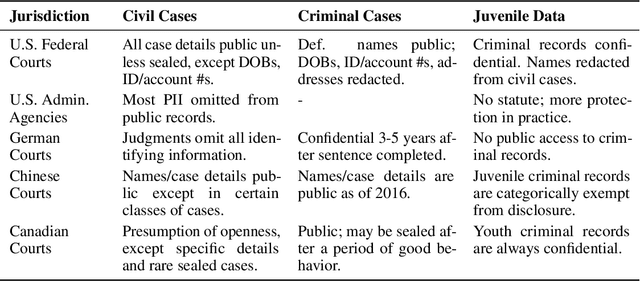
One concern with the rise of large language models lies with their potential for significant harm, particularly from pretraining on biased, obscene, copyrighted, and private information. Emerging ethical approaches have attempted to filter pretraining material, but such approaches have been ad hoc and failed to take into account context. We offer an approach to filtering grounded in law, which has directly addressed the tradeoffs in filtering material. First, we gather and make available the Pile of Law, a 256GB (and growing) dataset of open-source English-language legal and administrative data, covering court opinions, contracts, administrative rules, and legislative records. Pretraining on the Pile of Law may potentially help with legal tasks that have the promise to improve access to justice. Second, we distill the legal norms that governments have developed to constrain the inclusion of toxic or private content into actionable lessons for researchers and discuss how our dataset reflects these norms. Third, we show how the Pile of Law offers researchers the opportunity to learn such filtering rules directly from the data, providing an exciting new research direction in model-based processing.
How Human is Human Evaluation? Improving the Gold Standard for NLG with Utility Theory
May 24, 2022
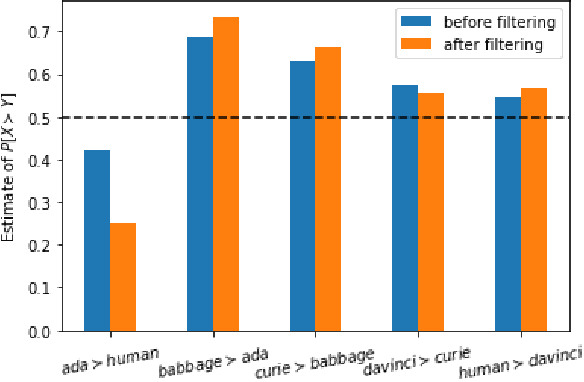

Human ratings are treated as the gold standard in NLG evaluation. The standard protocol is to collect ratings of generated text, average across annotators, and then rank NLG systems by their average scores. However, little consideration has been given as to whether this approach faithfully captures human preferences. In this work, we analyze this standard protocol through the lens of utility theory in economics. We first identify the implicit assumptions it makes about annotators and find that these assumptions are often violated in practice, in which case annotator ratings become an unfaithful reflection of their preferences. The most egregious violations come from using Likert scales, which provably reverse the direction of the true preference in certain cases. We suggest improvements to the standard protocol to make it more theoretically sound, but even in its improved form, it cannot be used to evaluate open-ended tasks like story generation. For the latter, we propose a new evaluation protocol called $\textit{system-level probabilistic assessment}$ (SPA). In our experiments, we find that according to SPA, annotators prefer larger GPT-3 variants to smaller ones -- as expected -- with all comparisons being statistically significant. In contrast, the standard protocol only yields significant results half the time.
Prompt-and-Rerank: A Method for Zero-Shot and Few-Shot Arbitrary Textual Style Transfer with Small Language Models
May 23, 2022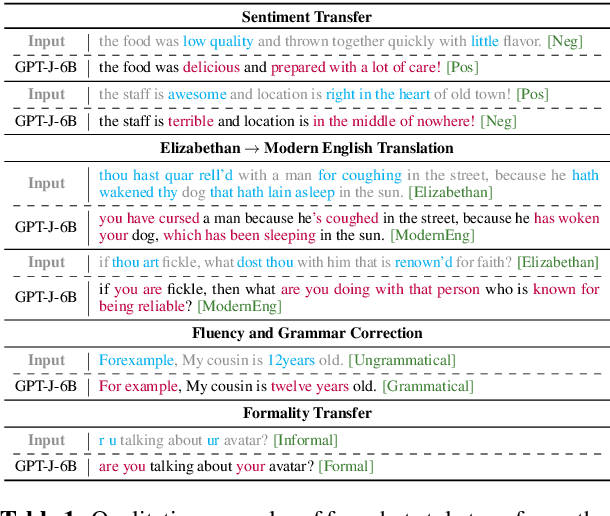
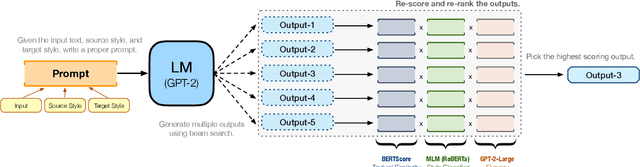
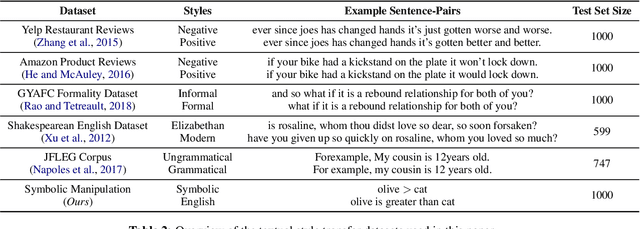
We propose a method for arbitrary textual style transfer (TST)--the task of transforming a text into any given style--utilizing general-purpose pre-trained language models. Our method, Prompt-and-Rerank, is based on a mathematical formulation of the TST task, decomposing it into three constituent components: textual similarity, target style strength, and fluency. Specifically, our method first uses zero-shot or few-shot prompting to obtain a set of candidate generations in the target style, and then re-ranks these candidates according to a combination of the three components above. Empirically, our method enables small pre-trained language models to perform on par with state-of-the-art large-scale models while consuming two orders of magnitude less compute and memory. Finally, we conduct a systematic investigation of the effect of model size and prompt design (e.g., prompt paraphrasing and delimiter-pair choice) on style transfer quality across seven diverse textual style transfer datasets.