 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLeast-to-Most Prompting Enables Complex Reasoning in Large Language Models
May 21, 2022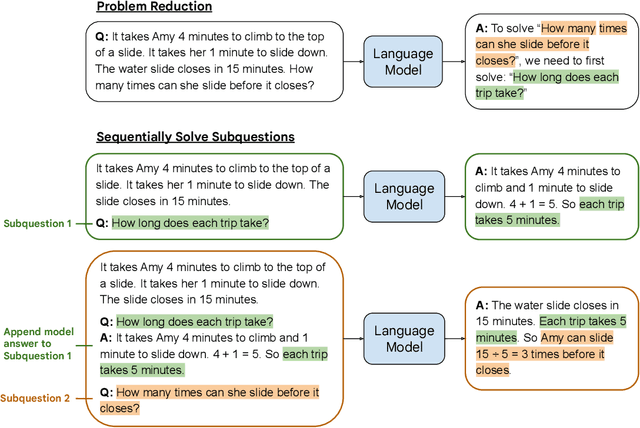



We propose a novel prompting strategy, least-to-most prompting, that enables large language models to better perform multi-step reasoning tasks. Least-to-most prompting first reduces a complex problem into a list of subproblems, and then sequentially solves the subproblems, whereby solving a given subproblem is facilitated by the model's answers to previously solved subproblems. Experiments on symbolic manipulation, compositional generalization and numerical reasoning demonstrate that least-to-most prompting can generalize to examples that are harder than those seen in the prompt context, outperforming other prompting-based approaches by a large margin. A notable empirical result is that the GPT-3 code-davinci-002 model with least-to-most-prompting can solve the SCAN benchmark with an accuracy of 99.7% using 14 examples. As a comparison, the neural-symbolic models in the literature specialized for solving SCAN are trained with the full training set of more than 15,000 examples.
Reinforcement Teaching
Apr 25, 2022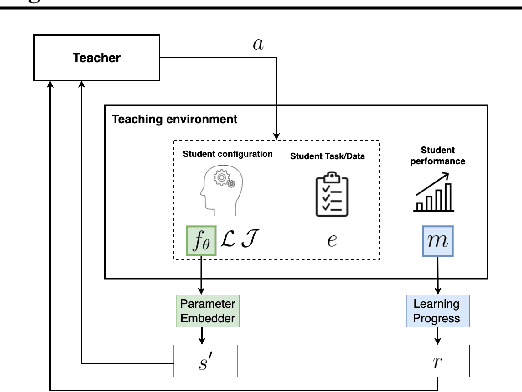

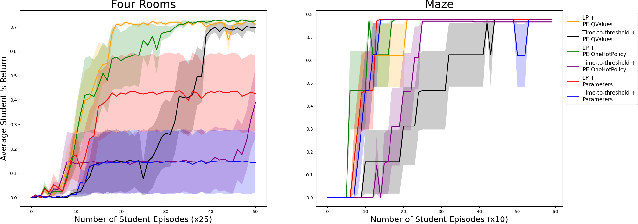
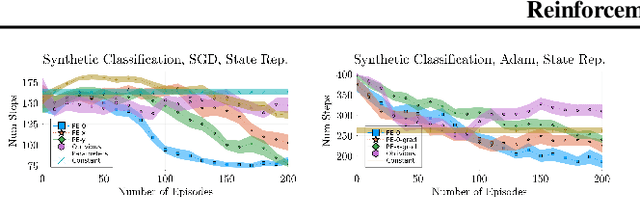
We propose Reinforcement Teaching: a framework for meta-learning in which a teaching policy is learned, through reinforcement, to control a student's learning process. The student's learning process is modelled as a Markov reward process and the teacher, with its action-space, interacts with the induced Markov decision process. We show that, for many learning processes, the student's learnable parameters form a Markov state. To avoid having the teacher learn directly from parameters, we propose the Parameter Embedder that learns a representation of a student's state from its input/output behaviour. Next, we use learning progress to shape the teacher's reward towards maximizing the student's performance. To demonstrate the generality of Reinforcement Teaching, we conducted experiments in which a teacher learns to significantly improve supervised and reinforcement learners by using a combination of learning progress reward and a Parameter Embedded state. These results show that Reinforcement Teaching is not only an expressive framework capable of unifying different approaches, but also provides meta-learning with the plethora of tools from reinforcement learning.
Self-Consistency Improves Chain of Thought Reasoning in Language Models
Apr 06, 2022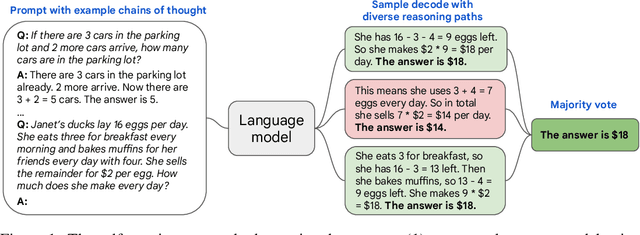
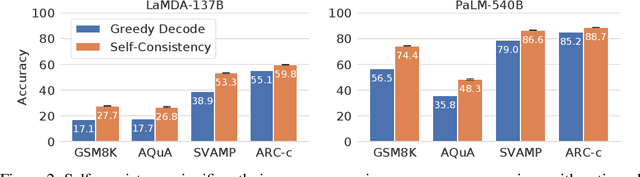
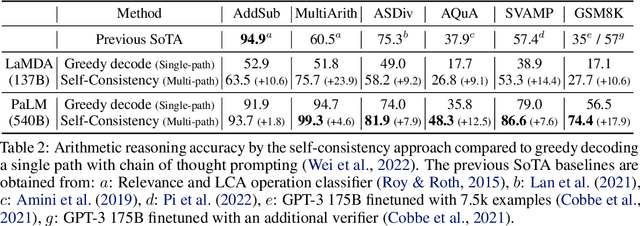
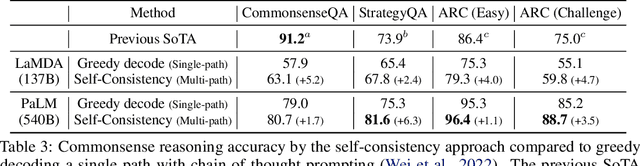
We explore a simple ensemble strategy, self-consistency, that significantly improves the reasoning accuracy of large language models. The idea is to sample a diverse set of reasoning paths from a language model via chain of thought prompting then return the most consistent final answer in the set. We evaluate self-consistency on a range of arithmetic and commonsense reasoning benchmarks, and find that it robustly improves accuracy across a variety of language models and model scales without the need for additional training or auxiliary models. When combined with a recent large language model, PaLM-540B, self-consistency increases performance to state-of-the-art levels across several benchmark reasoning tasks, including GSM8K (56.5% -> 74.4%), SVAMP (79.0% -> 86.6%), AQuA (35.8% -> 48.3%), StrategyQA (75.3% -> 81.6%) and ARC-challenge (85.2% -> 88.7%).
Chain of Thought Prompting Elicits Reasoning in Large Language Models
Jan 28, 2022



Although scaling up language model size has reliably improved performance on a range of NLP tasks, even the largest models currently struggle with certain reasoning tasks such as math word problems, symbolic manipulation, and commonsense reasoning. This paper explores the ability of language models to generate a coherent chain of thought -- a series of short sentences that mimic the reasoning process a person might have when responding to a question. Experiments show that inducing a chain of thought via prompting can enable sufficiently large language models to better perform reasoning tasks that otherwise have flat scaling curves.
Neural Stochastic Dual Dynamic Programming
Dec 01, 2021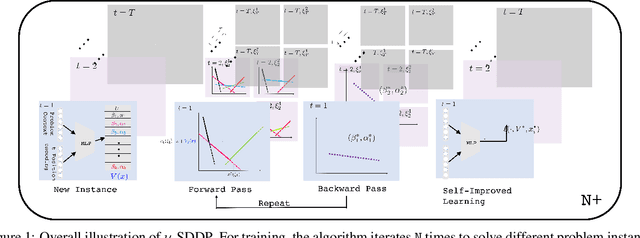

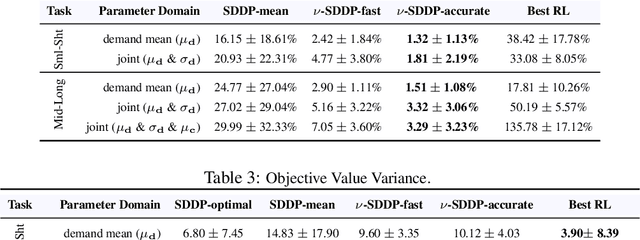

Stochastic dual dynamic programming (SDDP) is a state-of-the-art method for solving multi-stage stochastic optimization, widely used for modeling real-world process optimization tasks. Unfortunately, SDDP has a worst-case complexity that scales exponentially in the number of decision variables, which severely limits applicability to only low dimensional problems. To overcome this limitation, we extend SDDP by introducing a trainable neural model that learns to map problem instances to a piece-wise linear value function within intrinsic low-dimension space, which is architected specifically to interact with a base SDDP solver, so that can accelerate optimization performance on new instances. The proposed Neural Stochastic Dual Dynamic Programming ($\nu$-SDDP) continually self-improves by solving successive problems. An empirical investigation demonstrates that $\nu$-SDDP can significantly reduce problem solving cost without sacrificing solution quality over competitors such as SDDP and reinforcement learning algorithms, across a range of synthetic and real-world process optimization problems.
SMORE: Knowledge Graph Completion and Multi-hop Reasoning in Massive Knowledge Graphs
Nov 01, 2021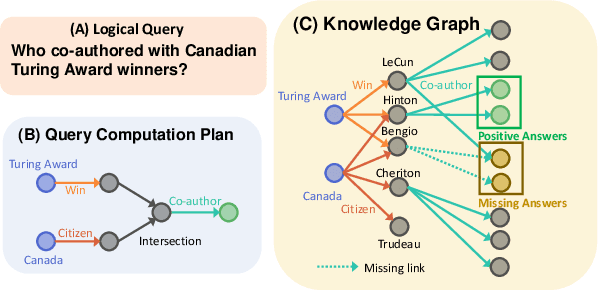

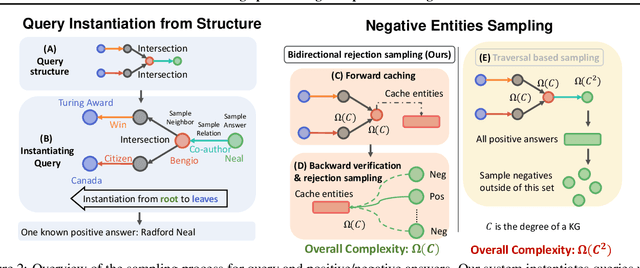
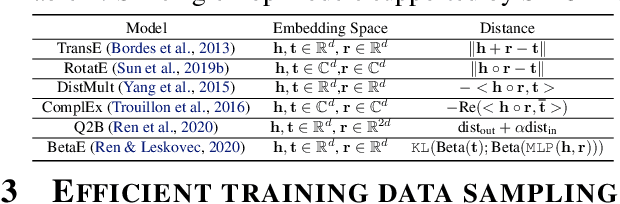
Knowledge graphs (KGs) capture knowledge in the form of head--relation--tail triples and are a crucial component in many AI systems. There are two important reasoning tasks on KGs: (1) single-hop knowledge graph completion, which involves predicting individual links in the KG; and (2), multi-hop reasoning, where the goal is to predict which KG entities satisfy a given logical query. Embedding-based methods solve both tasks by first computing an embedding for each entity and relation, then using them to form predictions. However, existing scalable KG embedding frameworks only support single-hop knowledge graph completion and cannot be applied to the more challenging multi-hop reasoning task. Here we present Scalable Multi-hOp REasoning (SMORE), the first general framework for both single-hop and multi-hop reasoning in KGs. Using a single machine SMORE can perform multi-hop reasoning in Freebase KG (86M entities, 338M edges), which is 1,500x larger than previously considered KGs. The key to SMORE's runtime performance is a novel bidirectional rejection sampling that achieves a square root reduction of the complexity of online training data generation. Furthermore, SMORE exploits asynchronous scheduling, overlapping CPU-based data sampling, GPU-based embedding computation, and frequent CPU--GPU IO. SMORE increases throughput (i.e., training speed) over prior multi-hop KG frameworks by 2.2x with minimal GPU memory requirements (2GB for training 400-dim embeddings on 86M-node Freebase) and achieves near linear speed-up with the number of GPUs. Moreover, on the simpler single-hop knowledge graph completion task SMORE achieves comparable or even better runtime performance to state-of-the-art frameworks on both single GPU and multi-GPU settings.
Understanding the Effect of Stochasticity in Policy Optimization
Oct 29, 2021

We study the effect of stochasticity in on-policy policy optimization, and make the following four contributions. First, we show that the preferability of optimization methods depends critically on whether stochastic versus exact gradients are used. In particular, unlike the true gradient setting, geometric information cannot be easily exploited in the stochastic case for accelerating policy optimization without detrimental consequences or impractical assumptions. Second, to explain these findings we introduce the concept of committal rate for stochastic policy optimization, and show that this can serve as a criterion for determining almost sure convergence to global optimality. Third, we show that in the absence of external oracle information, which allows an algorithm to determine the difference between optimal and sub-optimal actions given only on-policy samples, there is an inherent trade-off between exploiting geometry to accelerate convergence versus achieving optimality almost surely. That is, an uninformed algorithm either converges to a globally optimal policy with probability $1$ but at a rate no better than $O(1/t)$, or it achieves faster than $O(1/t)$ convergence but then must fail to converge to the globally optimal policy with some positive probability. Finally, we use the committal rate theory to explain why practical policy optimization methods are sensitive to random initialization, then develop an ensemble method that can be guaranteed to achieve near-optimal solutions with high probability.
Combiner: Full Attention Transformer with Sparse Computation Cost
Jul 12, 2021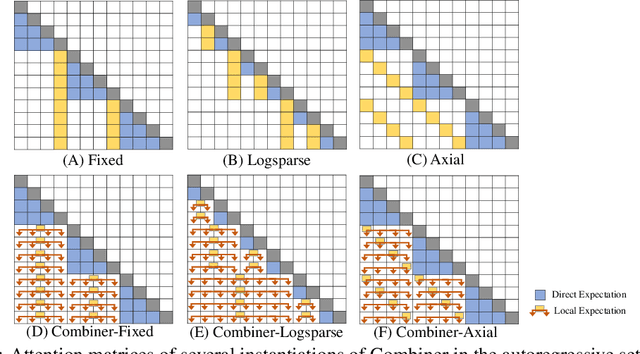
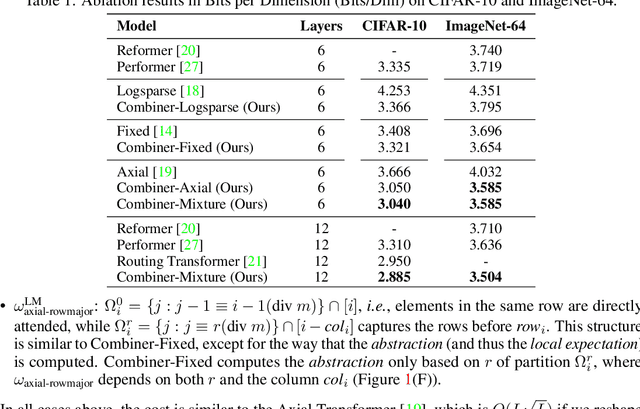
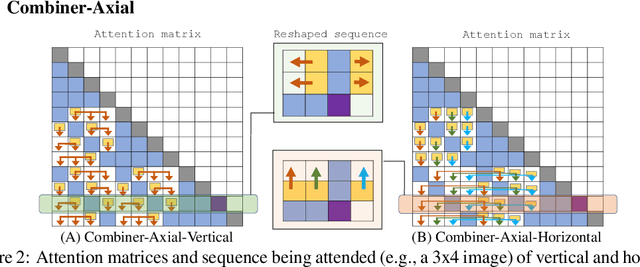

Transformers provide a class of expressive architectures that are extremely effective for sequence modeling. However, the key limitation of transformers is their quadratic memory and time complexity $\mathcal{O}(L^2)$ with respect to the sequence length in attention layers, which restricts application in extremely long sequences. Most existing approaches leverage sparsity or low-rank assumptions in the attention matrix to reduce cost, but sacrifice expressiveness. Instead, we propose Combiner, which provides full attention capability in each attention head while maintaining low computation and memory complexity. The key idea is to treat the self-attention mechanism as a conditional expectation over embeddings at each location, and approximate the conditional distribution with a structured factorization. Each location can attend to all other locations, either via direct attention, or through indirect attention to abstractions, which are again conditional expectations of embeddings from corresponding local regions. We show that most sparse attention patterns used in existing sparse transformers are able to inspire the design of such factorization for full attention, resulting in the same sub-quadratic cost ($\mathcal{O}(L\log(L))$ or $\mathcal{O}(L\sqrt{L})$). Combiner is a drop-in replacement for attention layers in existing transformers and can be easily implemented in common frameworks. An experimental evaluation on both autoregressive and bidirectional sequence tasks demonstrates the effectiveness of this approach, yielding state-of-the-art results on several image and text modeling tasks.
On the Sample Complexity of Batch Reinforcement Learning with Policy-Induced Data
Jun 18, 2021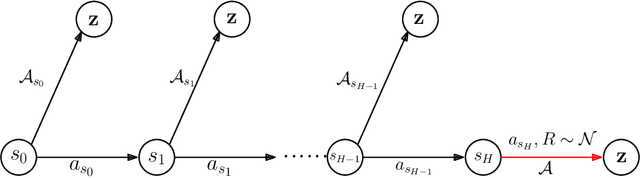
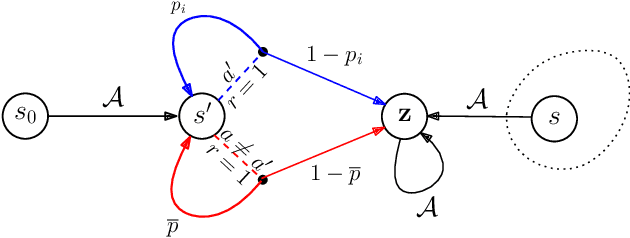
We study the fundamental question of the sample complexity of learning a good policy in finite Markov decision processes (MDPs) when the data available for learning is obtained by following a logging policy that must be chosen without knowledge of the underlying MDP. Our main results show that the sample complexity, the minimum number of transitions necessary and sufficient to obtain a good policy, is an exponential function of the relevant quantities when the planning horizon $H$ is finite. In particular, we prove that the sample complexity of obtaining $\epsilon$-optimal policies is at least $\Omega(\mathrm{A}^{\min(\mathrm{S}-1, H+1)})$ for $\gamma$-discounted problems, where $\mathrm{S}$ is the number of states, $\mathrm{A}$ is the number of actions, and $H$ is the effective horizon defined as $H=\lfloor \tfrac{\ln(1/\epsilon)}{\ln(1/\gamma)} \rfloor$; and it is at least $\Omega(\mathrm{A}^{\min(\mathrm{S}-1, H)}/\varepsilon^2)$ for finite horizon problems, where $H$ is the planning horizon of the problem. This lower bound is essentially matched by an upper bound. For the average-reward setting we show that there is no algorithm finding $\epsilon$-optimal policies with a finite amount of data.
Characterizing the Gap Between Actor-Critic and Policy Gradient
Jun 13, 2021
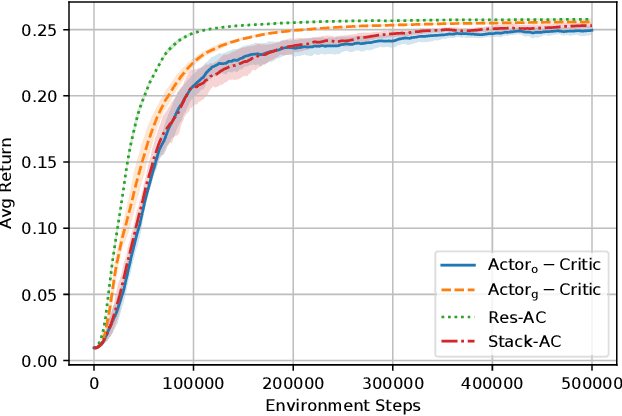
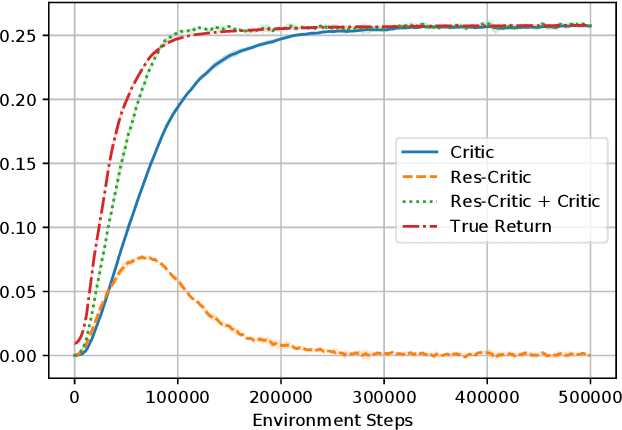
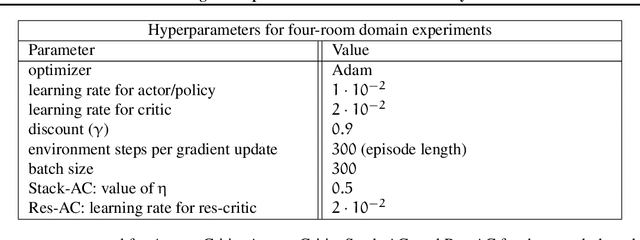
Actor-critic (AC) methods are ubiquitous in reinforcement learning. Although it is understood that AC methods are closely related to policy gradient (PG), their precise connection has not been fully characterized previously. In this paper, we explain the gap between AC and PG methods by identifying the exact adjustment to the AC objective/gradient that recovers the true policy gradient of the cumulative reward objective (PG). Furthermore, by viewing the AC method as a two-player Stackelberg game between the actor and critic, we show that the Stackelberg policy gradient can be recovered as a special case of our more general analysis. Based on these results, we develop practical algorithms, Residual Actor-Critic and Stackelberg Actor-Critic, for estimating the correction between AC and PG and use these to modify the standard AC algorithm. Experiments on popular tabular and continuous environments show the proposed corrections can improve both the sample efficiency and final performance of existing AC methods.