 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving Dynamic Object Interactions in Text-to-Video Generation with AI Feedback
Dec 03, 2024



Large text-to-video models hold immense potential for a wide range of downstream applications. However, these models struggle to accurately depict dynamic object interactions, often resulting in unrealistic movements and frequent violations of real-world physics. One solution inspired by large language models is to align generated outputs with desired outcomes using external feedback. This enables the model to refine its responses autonomously, eliminating extensive manual data collection. In this work, we investigate the use of feedback to enhance the object dynamics in text-to-video models. We aim to answer a critical question: what types of feedback, paired with which specific self-improvement algorithms, can most effectively improve text-video alignment and realistic object interactions? We begin by deriving a unified probabilistic objective for offline RL finetuning of text-to-video models. This perspective highlights how design elements in existing algorithms like KL regularization and policy projection emerge as specific choices within a unified framework. We then use derived methods to optimize a set of text-video alignment metrics (e.g., CLIP scores, optical flow), but notice that they often fail to align with human perceptions of generation quality. To address this limitation, we propose leveraging vision-language models to provide more nuanced feedback specifically tailored to object dynamics in videos. Our experiments demonstrate that our method can effectively optimize a wide variety of rewards, with binary AI feedback driving the most significant improvements in video quality for dynamic interactions, as confirmed by both AI and human evaluations. Notably, we observe substantial gains when using reward signals derived from AI feedback, particularly in scenarios involving complex interactions between multiple objects and realistic depictions of objects falling.
Toward Understanding In-context vs. In-weight Learning
Oct 30, 2024



It has recently been demonstrated empirically that in-context learning emerges in transformers when certain distributional properties are present in the training data, but this ability can also diminish upon further training. We provide a new theoretical understanding of these phenomena by identifying simplified distributional properties that give rise to the emergence and eventual disappearance of in-context learning. We do so by first analyzing a simplified model that uses a gating mechanism to choose between an in-weight and an in-context predictor. Through a combination of a generalization error and regret analysis we identify conditions where in-context and in-weight learning emerge. These theoretical findings are then corroborated experimentally by comparing the behaviour of a full transformer on the simplified distributions to that of the stylized model, demonstrating aligned results. We then extend the study to a full large language model, showing how fine-tuning on various collections of natural language prompts can elicit similar in-context and in-weight learning behaviour.
Faster WIND: Accelerating Iterative Best-of-$N$ Distillation for LLM Alignment
Oct 28, 2024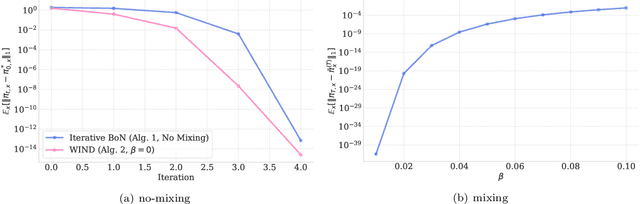
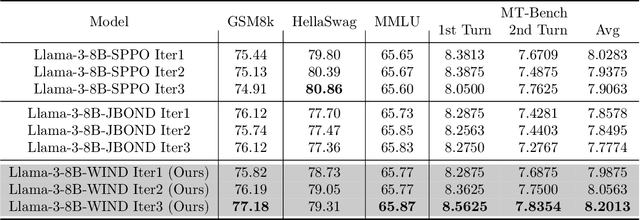
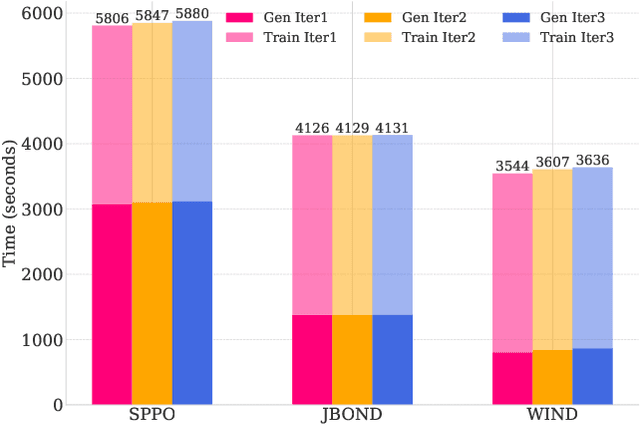
Recent advances in aligning large language models with human preferences have corroborated the growing importance of best-of-N distillation (BOND). However, the iterative BOND algorithm is prohibitively expensive in practice due to the sample and computation inefficiency. This paper addresses the problem by revealing a unified game-theoretic connection between iterative BOND and self-play alignment, which unifies seemingly disparate algorithmic paradigms. Based on the connection, we establish a novel framework, WIN rate Dominance (WIND), with a series of efficient algorithms for regularized win rate dominance optimization that approximates iterative BOND in the parameter space. We provides provable sample efficiency guarantee for one of the WIND variant with the square loss objective. The experimental results confirm that our algorithm not only accelerates the computation, but also achieves superior sample efficiency compared to existing methods.
Plastic Learning with Deep Fourier Features
Oct 27, 2024Deep neural networks can struggle to learn continually in the face of non-stationarity. This phenomenon is known as loss of plasticity. In this paper, we identify underlying principles that lead to plastic algorithms. In particular, we provide theoretical results showing that linear function approximation, as well as a special case of deep linear networks, do not suffer from loss of plasticity. We then propose deep Fourier features, which are the concatenation of a sine and cosine in every layer, and we show that this combination provides a dynamic balance between the trainability obtained through linearity and the effectiveness obtained through the nonlinearity of neural networks. Deep networks composed entirely of deep Fourier features are highly trainable and sustain their trainability over the course of learning. Our empirical results show that continual learning performance can be drastically improved by replacing ReLU activations with deep Fourier features. These results hold for different continual learning scenarios (e.g., label noise, class incremental learning, pixel permutations) on all major supervised learning datasets used for continual learning research, such as CIFAR10, CIFAR100, and tiny-ImageNet.
Autoregressive Large Language Models are Computationally Universal
Oct 04, 2024


We show that autoregressive decoding of a transformer-based language model can realize universal computation, without external intervention or modification of the model's weights. Establishing this result requires understanding how a language model can process arbitrarily long inputs using a bounded context. For this purpose, we consider a generalization of autoregressive decoding where, given a long input, emitted tokens are appended to the end of the sequence as the context window advances. We first show that the resulting system corresponds to a classical model of computation, a Lag system, that has long been known to be computationally universal. By leveraging a new proof, we show that a universal Turing machine can be simulated by a Lag system with 2027 production rules. We then investigate whether an existing large language model can simulate the behaviour of such a universal Lag system. We give an affirmative answer by showing that a single system-prompt can be developed for gemini-1.5-pro-001 that drives the model, under deterministic (greedy) decoding, to correctly apply each of the 2027 production rules. We conclude that, by the Church-Turing thesis, prompted gemini-1.5-pro-001 with extended autoregressive (greedy) decoding is a general purpose computer.
Generative Hierarchical Materials Search
Sep 10, 2024



Generative models trained at scale can now produce text, video, and more recently, scientific data such as crystal structures. In applications of generative approaches to materials science, and in particular to crystal structures, the guidance from the domain expert in the form of high-level instructions can be essential for an automated system to output candidate crystals that are viable for downstream research. In this work, we formulate end-to-end language-to-structure generation as a multi-objective optimization problem, and propose Generative Hierarchical Materials Search (GenMS) for controllable generation of crystal structures. GenMS consists of (1) a language model that takes high-level natural language as input and generates intermediate textual information about a crystal (e.g., chemical formulae), and (2) a diffusion model that takes intermediate information as input and generates low-level continuous value crystal structures. GenMS additionally uses a graph neural network to predict properties (e.g., formation energy) from the generated crystal structures. During inference, GenMS leverages all three components to conduct a forward tree search over the space of possible structures. Experiments show that GenMS outperforms other alternatives of directly using language models to generate structures both in satisfying user request and in generating low-energy structures. We confirm that GenMS is able to generate common crystal structures such as double perovskites, or spinels, solely from natural language input, and hence can form the foundation for more complex structure generation in near future.
Exploring and Benchmarking the Planning Capabilities of Large Language Models
Jun 18, 2024



We seek to elevate the planning capabilities of Large Language Models (LLMs)investigating four main directions. First, we construct a comprehensive benchmark suite encompassing both classical planning domains and natural language scenarios. This suite includes algorithms to generate instances with varying levels of difficulty, allowing for rigorous and systematic evaluation of LLM performance. Second, we investigate the use of in-context learning (ICL) to enhance LLM planning, exploring the direct relationship between increased context length and improved planning performance. Third, we demonstrate the positive impact of fine-tuning LLMs on optimal planning paths, as well as the effectiveness of incorporating model-driven search procedures. Finally, we investigate the performance of the proposed methods in out-of-distribution scenarios, assessing the ability to generalize to novel and unseen planning challenges.
Learning Continually by Spectral Regularization
Jun 10, 2024



Loss of plasticity is a phenomenon where neural networks become more difficult to train during the course of learning. Continual learning algorithms seek to mitigate this effect by sustaining good predictive performance while maintaining network trainability. We develop new techniques for improving continual learning by first reconsidering how initialization can ensure trainability during early phases of learning. From this perspective, we derive new regularization strategies for continual learning that ensure beneficial initialization properties are better maintained throughout training. In particular, we investigate two new regularization techniques for continual learning: (i) Wasserstein regularization toward the initial weight distribution, which is less restrictive than regularizing toward initial weights; and (ii) regularizing weight matrix singular values, which directly ensures gradient diversity is maintained throughout training. We present an experimental analysis that shows these alternative regularizers can improve continual learning performance across a range of supervised learning tasks and model architectures. The alternative regularizers prove to be less sensitive to hyperparameters while demonstrating better training in individual tasks, sustaining trainability as new tasks arrive, and achieving better generalization performance.
Target Networks and Over-parameterization Stabilize Off-policy Bootstrapping with Function Approximation
May 31, 2024We prove that the combination of a target network and over-parameterized linear function approximation establishes a weaker convergence condition for bootstrapped value estimation in certain cases, even with off-policy data. Our condition is naturally satisfied for expected updates over the entire state-action space or learning with a batch of complete trajectories from episodic Markov decision processes. Notably, using only a target network or an over-parameterized model does not provide such a convergence guarantee. Additionally, we extend our results to learning with truncated trajectories, showing that convergence is achievable for all tasks with minor modifications, akin to value truncation for the final states in trajectories. Our primary result focuses on temporal difference estimation for prediction, providing high-probability value estimation error bounds and empirical analysis on Baird's counterexample and a Four-room task. Furthermore, we explore the control setting, demonstrating that similar convergence conditions apply to Q-learning.
Value-Incentivized Preference Optimization: A Unified Approach to Online and Offline RLHF
May 29, 2024


Reinforcement learning from human feedback (RLHF) has demonstrated great promise in aligning large language models (LLMs) with human preference. Depending on the availability of preference data, both online and offline RLHF are active areas of investigation. A key bottleneck is understanding how to incorporate uncertainty estimation in the reward function learned from the preference data for RLHF, regardless of how the preference data is collected. While the principles of optimism or pessimism under uncertainty are well-established in standard reinforcement learning (RL), a practically-implementable and theoretically-grounded form amenable to large language models is not yet available, as standard techniques for constructing confidence intervals become intractable under arbitrary policy parameterizations. In this paper, we introduce a unified approach to online and offline RLHF -- value-incentivized preference optimization (VPO) -- which regularizes the maximum-likelihood estimate of the reward function with the corresponding value function, modulated by a $\textit{sign}$ to indicate whether the optimism or pessimism is chosen. VPO also directly optimizes the policy with implicit reward modeling, and therefore shares a simpler RLHF pipeline similar to direct preference optimization. Theoretical guarantees of VPO are provided for both online and offline settings, matching the rates of their standard RL counterparts. Moreover, experiments on text summarization and dialog verify the practicality and effectiveness of VPO.