 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGrounding in social media: An approach to building a chit-chat dialogue model
Jun 12, 2022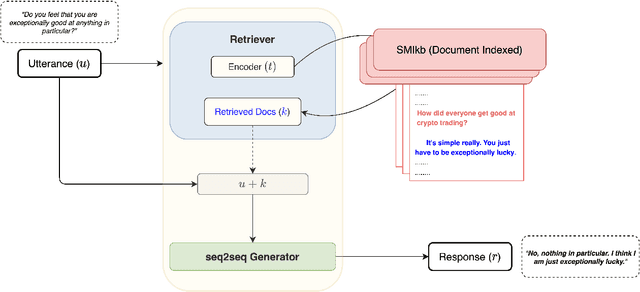
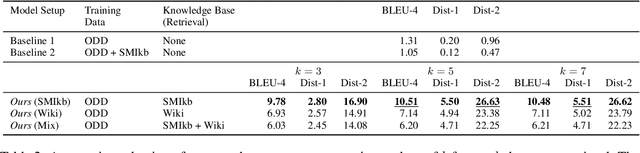
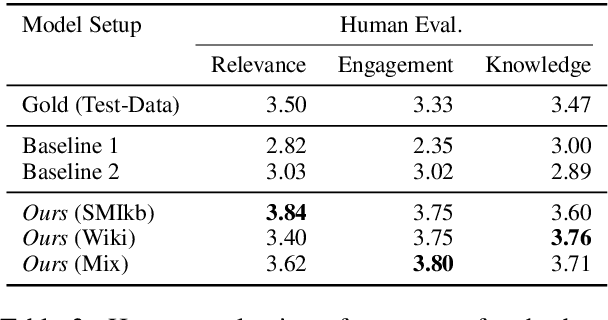
Building open-domain dialogue systems capable of rich human-like conversational ability is one of the fundamental challenges in language generation. However, even with recent advancements in the field, existing open-domain generative models fail to capture and utilize external knowledge, leading to repetitive or generic responses to unseen utterances. Current work on knowledge-grounded dialogue generation primarily focuses on persona incorporation or searching a fact-based structured knowledge source such as Wikipedia. Our method takes a broader and simpler approach, which aims to improve the raw conversation ability of the system by mimicking the human response behavior through casual interactions found on social media. Utilizing a joint retriever-generator setup, the model queries a large set of filtered comment data from Reddit to act as additional context for the seq2seq generator. Automatic and human evaluations on open-domain dialogue datasets demonstrate the effectiveness of our approach.
Building a Personalized Dialogue System with Prompt-Tuning
Jun 11, 2022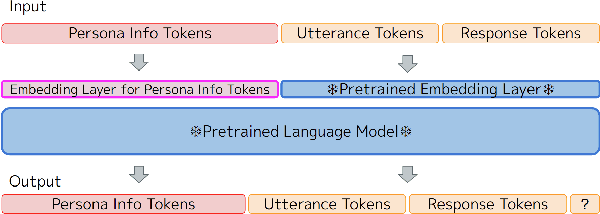

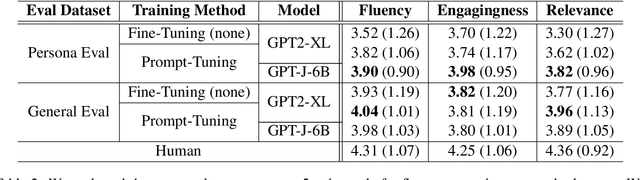
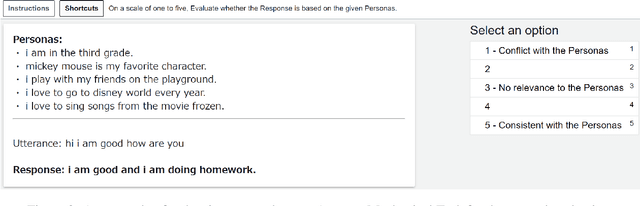
Dialogue systems without consistent responses are not fascinating. In this study, we build a dialogue system that can respond based on a given character setting (persona) to bring consistency. Considering the trend of the rapidly increasing scale of language models, we propose an approach that uses prompt-tuning, which has low learning costs, on pre-trained large-scale language models. The results of automatic and manual evaluations in English and Japanese show that it is possible to build a dialogue system with more natural and personalized responses using less computational resources than fine-tuning.
Generate, Evaluate, and Select: A Dialogue System with a Response Evaluator for Diversity-Aware Response Generation
Jun 10, 2022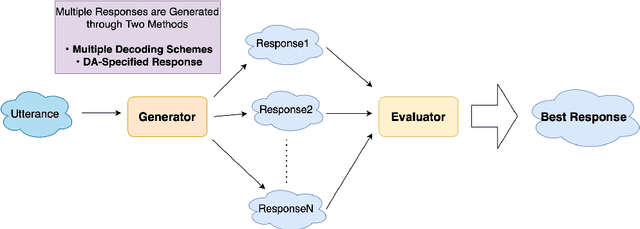


We aim to overcome the lack of diversity in responses of current dialogue systems and to develop a dialogue system that is engaging as a conversational partner. We propose a generator-evaluator model that evaluates multiple responses generated by a response generator and selects the best response by an evaluator. By generating multiple responses, we obtain diverse responses. We conduct human evaluations to compare the output of the proposed system with that of a baseline system. The results of the human evaluations showed that the proposed system's responses were often judged to be better than the baseline system's, and indicated the effectiveness of the proposed method.
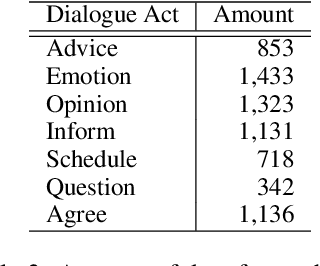
Building a Dialogue Corpus Annotated with Expressed and Experienced Emotions
May 24, 2022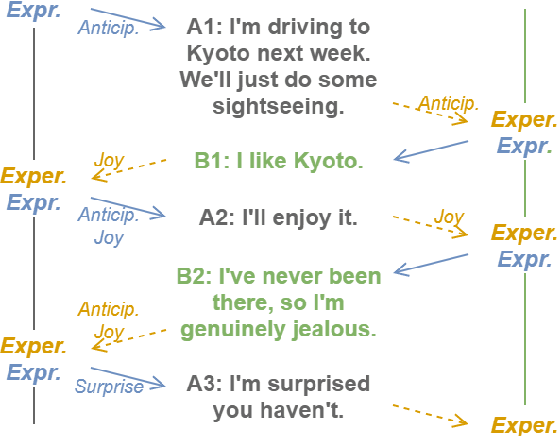
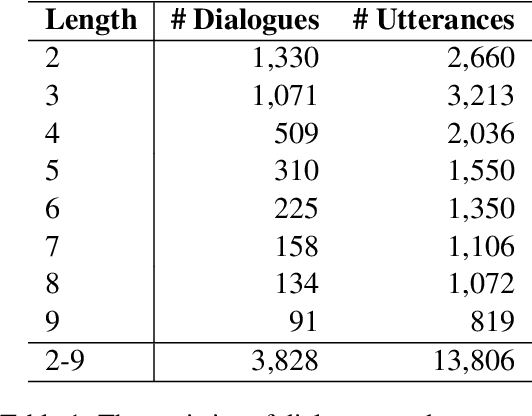

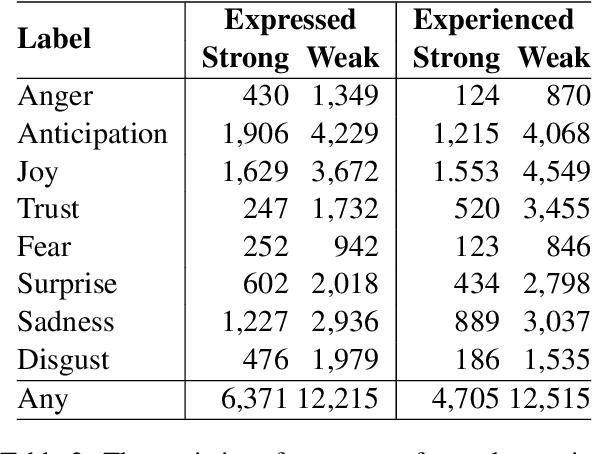
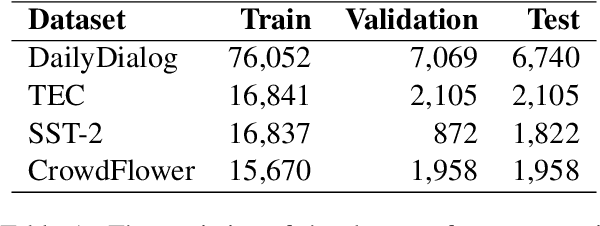
In communication, a human would recognize the emotion of an interlocutor and respond with an appropriate emotion, such as empathy and comfort. Toward developing a dialogue system with such a human-like ability, we propose a method to build a dialogue corpus annotated with two kinds of emotions. We collect dialogues from Twitter and annotate each utterance with the emotion that a speaker put into the utterance (expressed emotion) and the emotion that a listener felt after listening to the utterance (experienced emotion). We built a dialogue corpus in Japanese using this method, and its statistical analysis revealed the differences between expressed and experienced emotions. We conducted experiments on recognition of the two kinds of emotions. The experimental results indicated the difficulty in recognizing experienced emotions and the effectiveness of multi-task learning of the two kinds of emotions. We hope that the constructed corpus will facilitate the study on emotion recognition in a dialogue and emotion-aware dialogue response generation.
Multi-Task Learning of Generation and Classification for Emotion-Aware Dialogue Response Generation
May 25, 2021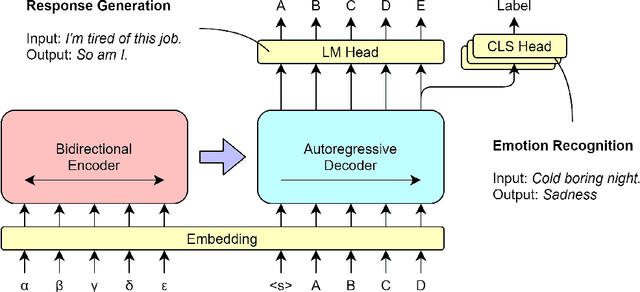
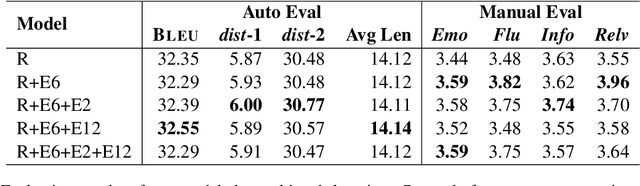
For a computer to naturally interact with a human, it needs to be human-like. In this paper, we propose a neural response generation model with multi-task learning of generation and classification, focusing on emotion. Our model based on BART (Lewis et al., 2020), a pre-trained transformer encoder-decoder model, is trained to generate responses and recognize emotions simultaneously. Furthermore, we weight the losses for the tasks to control the update of parameters. Automatic evaluations and crowdsourced manual evaluations show that the proposed model makes generated responses more emotionally aware.
Minimize Exposure Bias of Seq2Seq Models in Joint Entity and Relation Extraction
Oct 06, 2020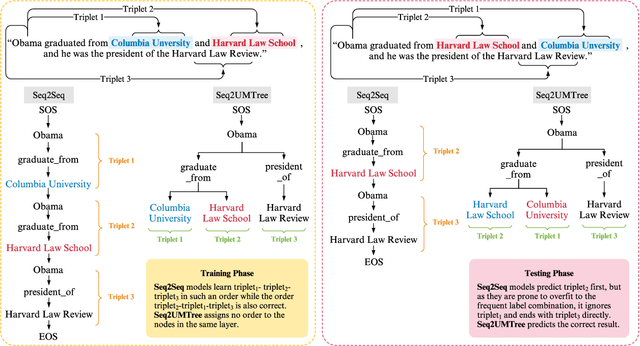
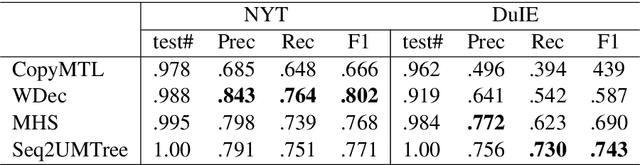
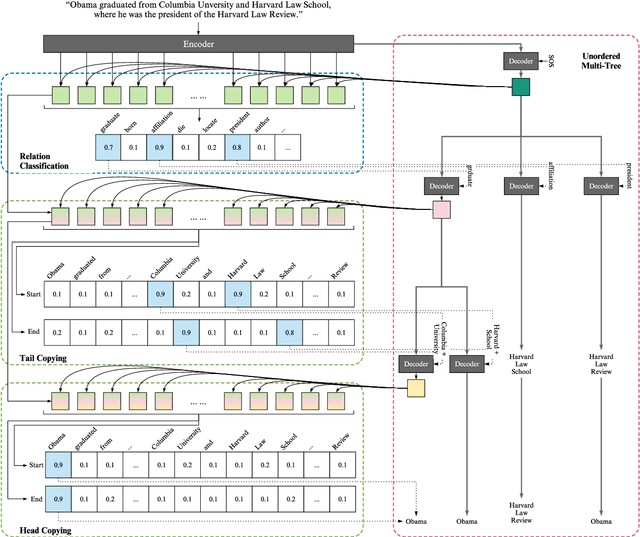
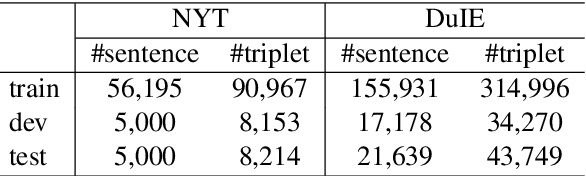
Joint entity and relation extraction aims to extract relation triplets from plain text directly. Prior work leverages Sequence-to-Sequence (Seq2Seq) models for triplet sequence generation. However, Seq2Seq enforces an unnecessary order on the unordered triplets and involves a large decoding length associated with error accumulation. These introduce exposure bias, which may cause the models overfit to the frequent label combination, thus deteriorating the generalization. We propose a novel Sequence-to-Unordered-Multi-Tree (Seq2UMTree) model to minimize the effects of exposure bias by limiting the decoding length to three within a triplet and removing the order among triplets. We evaluate our model on two datasets, DuIE and NYT, and systematically study how exposure bias alters the performance of Seq2Seq models. Experiments show that the state-of-the-art Seq2Seq model overfits to both datasets while Seq2UMTree shows significantly better generalization. Our code is available at https://github.com/WindChimeRan/OpenJERE .
Reverse Operation based Data Augmentation for Solving Math Word Problems
Oct 04, 2020

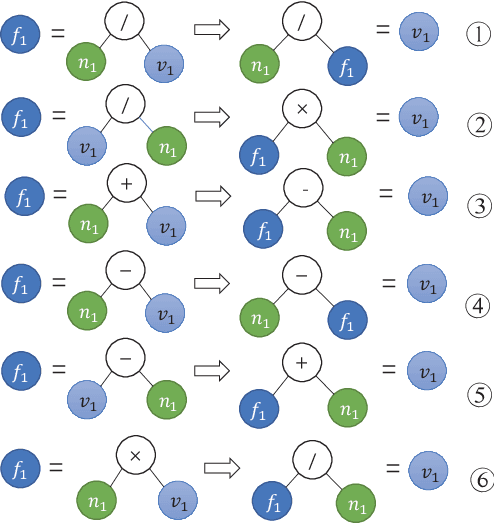
Automatically solving math word problems is a critical task in the field of natural language processing. Recent models have reached their performance bottleneck and require more high-quality data for training. Inspired by human double-checking mechanism, we propose a reverse operation based data augmentation method that makes use of mathematical logic to produce new high-quality math problems and introduce new knowledge points that can give supervision for new mathematical reasoning logic. We apply the augmented data on two SOTA math word problem solving models. Experimental results show the effectiveness of our approach\footnote{We will release our code and data after the paper is accepted.}.
A System for Worldwide COVID-19 Information Aggregation
Jul 28, 2020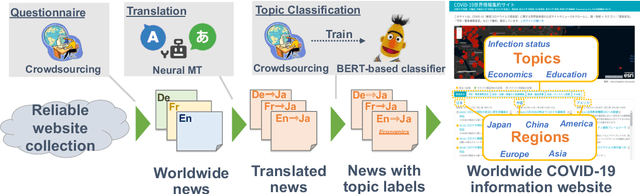

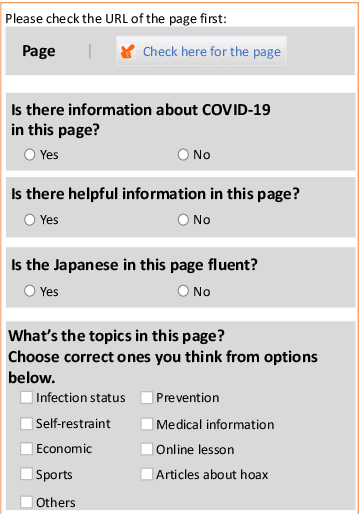
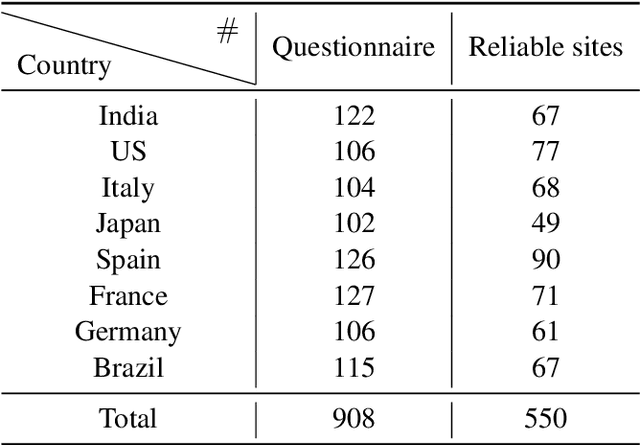
The global pandemic of COVID-19 has made the public pay close attention to related news, covering various domains, such as sanitation, treatment, and effects on education. Meanwhile, the COVID-19 condition is very different among the countries (e.g., policies and development of the epidemic), and thus citizens would be interested in news in foreign countries. We build a system for worldwide COVID-19 information aggregation (http://lotus.kuee.kyoto-u.ac.jp/NLPforCOVID-19 ) containing reliable articles from 10 regions in 7 languages sorted by topics for Japanese citizens. Our reliable COVID-19 related website dataset collected through crowdsourcing ensures the quality of the articles. A neural machine translation module translates articles in other languages into Japanese. A BERT-based topic-classifier trained on an article-topic pair dataset helps users find their interested information efficiently by putting articles into different categories.
Knowledge-enriched Two-layered Attention Network for Sentiment Analysis
Jun 16, 2018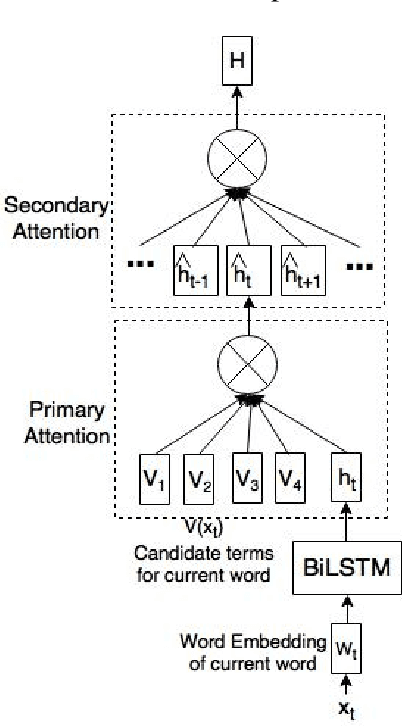
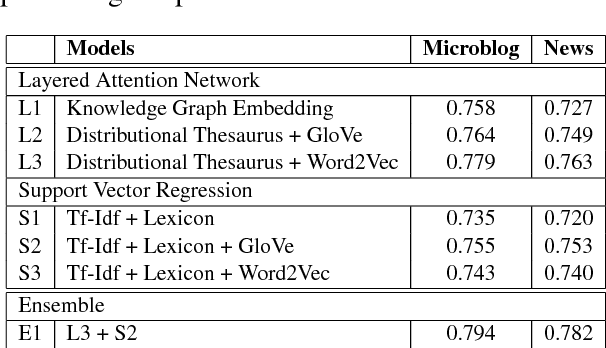
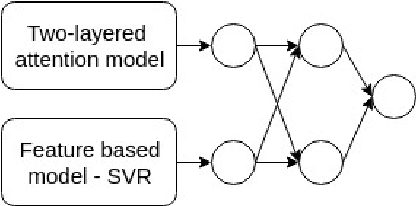
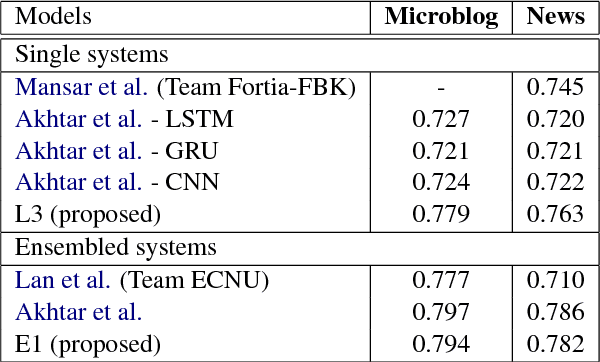
We propose a novel two-layered attention network based on Bidirectional Long Short-Term Memory for sentiment analysis. The novel two-layered attention network takes advantage of the external knowledge bases to improve the sentiment prediction. It uses the Knowledge Graph Embedding generated using the WordNet. We build our model by combining the two-layered attention network with the supervised model based on Support Vector Regression using a Multilayer Perceptron network for sentiment analysis. We evaluate our model on the benchmark dataset of SemEval 2017 Task 5. Experimental results show that the proposed model surpasses the top system of SemEval 2017 Task 5. The model performs significantly better by improving the state-of-the-art system at SemEval 2017 Task 5 by 1.7 and 3.7 points for sub-tracks 1 and 2 respectively.
Neural Adversarial Training for Semi-supervised Japanese Predicate-argument Structure Analysis
Jun 05, 2018
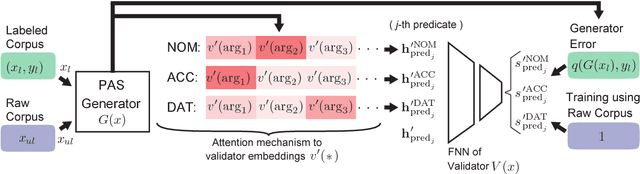
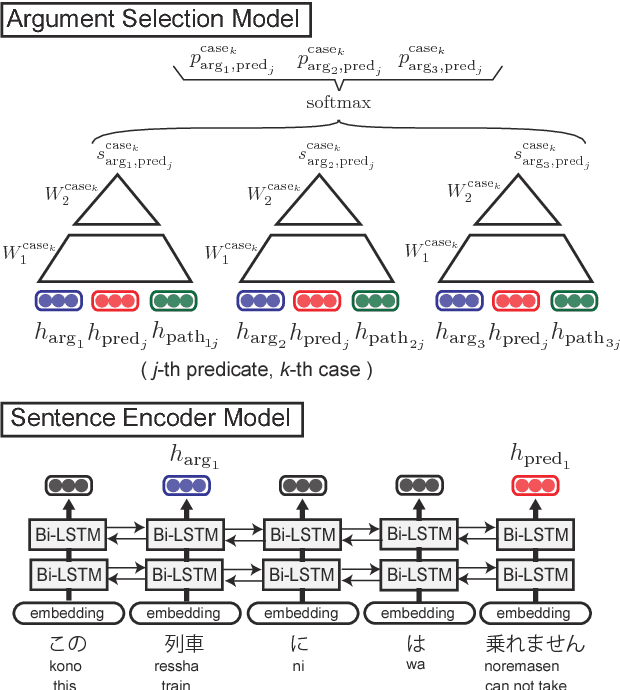

Japanese predicate-argument structure (PAS) analysis involves zero anaphora resolution, which is notoriously difficult. To improve the performance of Japanese PAS analysis, it is straightforward to increase the size of corpora annotated with PAS. However, since it is prohibitively expensive, it is promising to take advantage of a large amount of raw corpora. In this paper, we propose a novel Japanese PAS analysis model based on semi-supervised adversarial training with a raw corpus. In our experiments, our model outperforms existing state-of-the-art models for Japanese PAS analysis.