 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Principled Design of Mixture-of-Experts Language Models under Memory and Inference Constraints
Jan 13, 2026Modern Mixture-of-Experts (MoE) language models are designed based on total parameters (memory footprint) and active parameters (inference cost). However, we find these two factors alone are insufficient to describe an optimal architecture. Through a systematic study, we demonstrate that MoE performance is primarily determined by total parameters ($N_{total}$) and expert sparsity ($s:=n_{exp}/n_{topk}$). Moreover, $n_{exp}$ and $n_{topk}$ do not "cancel out" within the sparsity ratio; instead, a larger total number of experts slightly penalizes performance by forcing a reduction in core model dimensions (depth and width) to meet memory constraints. This motivates a simple principle for MoE design which maximizes $N_{total}$ while minimizing $s$ (maximizing $n_{topk}$) and $n_{exp}$ under the given constraints. Our findings provide a robust framework for resolving architectural ambiguity and guiding MoE design.
PHALM: Building a Knowledge Graph from Scratch by Prompting Humans and a Language Model
Oct 11, 2023



Despite the remarkable progress in natural language understanding with pretrained Transformers, neural language models often do not handle commonsense knowledge well. Toward commonsense-aware models, there have been attempts to obtain knowledge, ranging from automatic acquisition to crowdsourcing. However, it is difficult to obtain a high-quality knowledge base at a low cost, especially from scratch. In this paper, we propose PHALM, a method of building a knowledge graph from scratch, by prompting both crowdworkers and a large language model (LLM). We used this method to build a Japanese event knowledge graph and trained Japanese commonsense generation models. Experimental results revealed the acceptability of the built graph and inferences generated by the trained models. We also report the difference in prompting humans and an LLM. Our code, data, and models are available at github.com/nlp-waseda/comet-atomic-ja.
Building a Personalized Dialogue System with Prompt-Tuning
Jun 11, 2022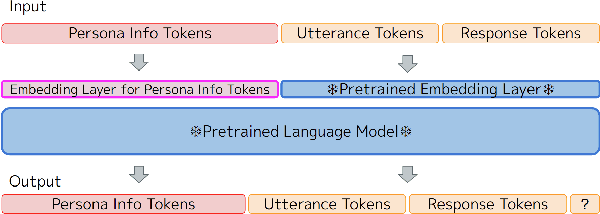

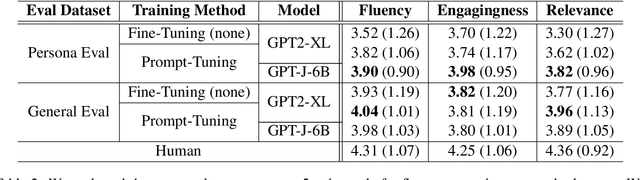
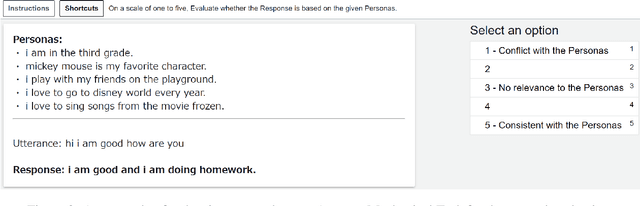
Dialogue systems without consistent responses are not fascinating. In this study, we build a dialogue system that can respond based on a given character setting (persona) to bring consistency. Considering the trend of the rapidly increasing scale of language models, we propose an approach that uses prompt-tuning, which has low learning costs, on pre-trained large-scale language models. The results of automatic and manual evaluations in English and Japanese show that it is possible to build a dialogue system with more natural and personalized responses using less computational resources than fine-tuning.